Automatic test generation: Excel, XML, XSLT, hereinafter - everywhere
Problem
There is a certain functional area of the application: a certain expert system that analyzes the state of the data and the outstanding result is a set of recommendations based on a set of rules. Components of the system are covered with a certain set of unit tests, but the main “magic” is to follow the rules. The rule set is determined by the customer at the project stage, the configuration is completed.
Moreover, since after the initial acceptance (it was long and difficult - because "manually"), changes are regularly made to the rules of the expert system upon the customer's request. It is obviously not bad if the system should be regressed to ensure that the rest the rules still work correctly and the last changes have not made any side effects.
The main difficulty is not even in the preparation of scenarios - they are, but in their implementation. When executing scenarios “manually", approximately 99% of the time and effort is spent on preparing test data in the application. The execution time of the rules by the expert system and the subsequent analysis of the output result is insignificant compared to the preparatory part. causing distrust on the part of the customer, and affecting the development of the system ("Change something, and then test it will have to ... Well, it ...").
An obvious technical solution would be to turn all scripts into automated ones and run them regularly as part of testing releases or as needed. However, we will be lazy, and we will try to find a way in which the data for test scenarios are prepared quite simply (ideally by the customer), and automatic tests are generated on their basis, also automatically.
')
Under the cat will be told about one approach that implements this idea - using MS Excel, XML and XSLT transformations.
A test is first of all data.
And where is the easiest way to prepare data, especially for an unprepared user? In the tables. So, first of all - in MS Excel.
I, personally, do not like spreadsheets very much. But not as such (as a rule, it is a usability standard), but because they implant and cultivate in the heads of non-professional users the concept of “mixing data and presentation” (and now programmers should pick out data from endless multi-level sheets), where It has everything - both the color of the cell and the font). But in this case, we know about the problem and will try to eliminate it.
So, setting the problem
- provide data preparation in MS Excel. The format should be reasonable from the point of view of ease of data preparation, simple for further processing, accessible for transfer to business users (the latter is optional, for a start we will make a tool for ourselves);
- accept the prepared data and convert it to the test code.
Decision
A couple of additional introductory:
- The specific format for presenting data in Excel is still unclear and, apparently, will change slightly in search of an optimal presentation;
- The test script code may change over time (debugging, fixing defects, optimization).
Both points lead to the idea that the initial data for the test must be extremely detailed both on the format in which the input will be carried out and on the processing and transformation into the auto-test code, since both parties will change.
The well-known technology of transforming data into an arbitrary textual representation is templating, and XSLT transformations, in particular, are flexible, simple, convenient, extensible. As an additional bonus, the use of transformations opens the way to the generation of the tests themselves (no matter what programming language) and the generation of test documentation.
So, the solution architecture:
- Convert data from Excel to XML in a specific format.
- Convert XML using XSLT to final test script code in an arbitrary programming language
The concrete implementation at both stages can be specific to the task. But some general principles that I think will be useful in any case are listed below:
Stage 1. Maintaining data in Excel
Here, to be honest, I limited myself to maintaining data in the form of tabular blocks. Fragment of the file - in the picture.
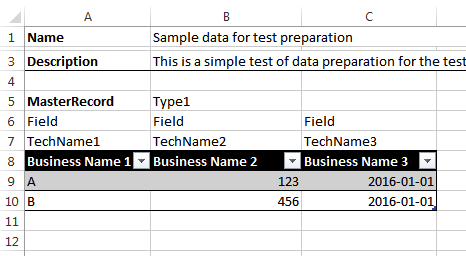
- The block starts with a line containing the block name (cell “A5"). It will be used as the name of the xml element, so the content must meet the requirements. The optional “type” (cell “B5") may be present in the same order will be used as an attribute value, so it also has limitations.
- Each column of the table contains, in addition to the “official” name representing business terms (line 8), two more fields for “type” (line 6) and “technical name” (line 7). In the process of data preparation, technical fields can be hidden, but they will be used during code generation.
- Columns in the table can be any number. The script ends processing the columns as soon as it encounters a column with an empty “type” value (column D).
- Columns with a “type” starting with an underscore are skipped.
- The table is processed until it encounters a row with an empty value in the first column (cell “A11”)
- The script stops after 3 blank lines.
Stage 2. Excel -> XML
Converting data from Excel sheets to XML is an easy task. Conversion is done using VBA code. There may be options, but it seemed to me the easiest and fastest.
Below are just a few considerations - how to make the final tool easier to maintain and use.
- The code is presented in the form of Excel add-in (.xlam) - to simplify the support of the code, when the number of files with test data is more than 1 and these files are created / supported by more than one person. In addition, this corresponds to the approach of code and data separation;
- XSLT templates are placed in the same directory as the add-in file - to simplify support;
- Generated files: intermediate XML and the resulting code file - it is desirable to place in the same directory as the Excel file with the original data. People creating test scripts will be more comfortable and faster to work with the results;
- An Excel file can contain several data sheets for tests - they are used to organize the variability of data for a test (for example, if a process is being tested, in which it is necessary to check the system response at each step): copied the sheet, changed part of the input data and expected results - that's it. All in one file;
- Since all sheets in an Excel workbook must have a unique name, this uniqueness can be used as part of the name of the test script. This approach provides a guaranteed uniqueness of the names of various sub-scenarios within the script. And if you include the file name in the name of the test script, then it becomes even easier to achieve the uniqueness of the script names - which is especially important if several people prepare the test data independently. In addition, the standard approach to naming will help in the future when analyzing test results - from the results of execution to the source data it will be very easy to get;
- Data from all sheets of the book is stored in a single XML file. For us, this seemed appropriate in the case of generating test documentation, and in some cases generating test scripts;
- When generating a file with data for a test, it turned out to be convenient to be able not to include separate sheets with source data in the generation (for various reasons; for example, the data for one of the five scenarios are not yet ready - and it is time to run the tests). To do this, we use the agreement: sheets, where the name starts with the underscore character are excluded from the generation;
- It is convenient to keep a sheet in the file with the details of the script for which test data is created (“Documentation”) - you can copy information from the customer, make comments, keep basic data and constants referenced by the other data sheets, and so on. Of course, this sheet does not participate in the generation;
- In order to be able to influence some aspects of the generation of the final code of test scripts, it turned out to be convenient to include in the final XML additional information “generation options” that are not test data, but can be used by the template to include or exclude code segments (by analogy with pragma, define, etc.) To do this, we use named cells that are located on the non-generated “Options” sheet;
- Each line of test data must have a unique identifier at the XML level - this will help a lot when generating code and processing cross-references between lines of test data, which in this case must be formulated in terms of just these unique identifiers.
An XML fragment that is obtained from Excel data from the image above
<MasterRecord type="Type1"> <columns> <column> <type>Field</type> <name>TechName1</name> <caption>Business Name 1</caption> </column> <column> <type>Field</type> <name>TechName2</name> <caption>Business Name 2</caption> </column> <column> <type>Field</type> <name>TechName3</name> <caption>Business Name 3</caption> </column> </columns> <row id="Type1_1"> <Field name="TechName1">A</Field> <Field name="TechName2">123</Field> <Field name="TechName3">2016-01-01</Field> </row> <row id="Type1_2"> <Field name="TechName1">B</Field> <Field name="TechName2">456</Field> <Field name="TechName3">2016-01-01</Field> </row> </MasterRecord> Stage 3. XML -> Code
This part is extremely specific to the tasks that are solved, therefore I will limit myself to general remarks.
- The initial iteration begins with the elements representing the sheets (various test scenarios). Here you can place the setup / teardown blocks, utilities;
- Iteration over data elements within a script element must begin with expected result elements. So you can logically organize the generated tests on the principle of "one test - one test";
- It is desirable to explicitly divide at the template level the area where the data is generated, the action being checked is performed, and the result obtained is controlled. This is possible by using patterns with modes. Such a structure of the template will allow you to make other generation options in the future - simply by importing this template and overlapping the required area in the new template;
- Along with the code, it will be convenient to include help on running the tests in the same file;
- It is very convenient to select the data generation code into a separately called block (procedure) - so that it can be used both within the test and independently, for debugging or simply creating a set of test data.
Final comment
After some time, there will be a lot of files with test data, and debugging and "polishing" of test script generation templates will continue. Therefore, it will be necessary to envisage the possibility of a “mass” generation of autotests from the set of Excel source files.
Conclusion
Using the described approach, you can get a very flexible tool for the preparation of test data or fully functional autotests.
In our project, we managed to quickly create a set of test scenarios for integration testing of a complex functional area - there are only about 60 files currently generated in approximately 180 tSQLt test classes (a framework for testing logic on the side of MS SQL Server). The plans are to use an approach to extend testing of this and other functional areas of the project.
The format of user input remains as before, and the generation of final autotests can be changed according to needs.
VBA code for converting Excel files to XML and running the conversion (along with an example of Excel and XML) can be found at GitHub github.com/serhit/TestDataGenerator .
XSLT transformation is not included in the repository, since it generates code for a specific task - you will still have your own. I will be glad to comments and pull requests.
Happy testing!
Source: https://habr.com/ru/post/312520/
All Articles