Web Alerts in Loaded Projects
In modern WEB Design, problems often arise when it is necessary to notify a user about an event: a new message has arrived, the exchange rate has changed or the order status has changed, video content has been converted or the temperature of a sick grandmother has jumped.
There are several options for solving this class of problems. The most optimal and common solution is to subscribe to events. How is this implemented in loaded projects?
Suppose we are developing a brokerage service in which thousands of clients are served. In order to find out the status of stock prices on the stock exchange or to find out the number of available places in hotels, we need to apply to one or several external services. Since the external service responds with a delay, and we have thousands of customers, if we make requests directly from the WEB application and wait for a response from the service, everything will hang as a result.
Therefore, we have to do the so-called pending request. Our WEB application immediately returns the generated HTML page to the user with no result, which shows the splash screen that the request is being executed, and the result comes a little later, as it is executed. How does this happen?
')
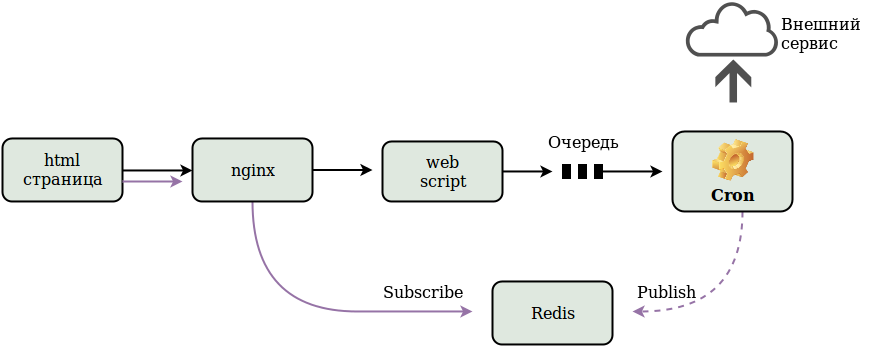
Before starting the formation of the HTML page, our WEB application puts the data into the queue. The daemon, or the task called on the crown, scans the queue and takes data from it. Further, on the basis of this data, it forms a request and sends it to an external service (picture 1).

It seems that everything in this scheme is good - it works without delay. But we need feedback. The end user needs the information he requested. And so, we received this information in our cron script. Now it is necessary to forward it to the user.
Here the Publisher-Subscriber pattern will help us. Many who use JavaScript know this scheme:
The subscriber (Subscriber) subscribes to a channel, and when a certain event occurs, the Publisher (Producer) sends a message to this channel. As such a notification mechanism, you can use many different solutions: Redis, RabbitMQ, Tarantool, MsMQ, ZMQ, Kafka (message broker). Since we have a number of services already tied to Redis, we decided not to introduce new entities.
How would you use it? There are several options here, but experts at once in three throats will say “To connect the WEB page and the server, use websockets”. I will not argue, yes, today is the most advanced technology of instant communication between the WEB client and the server. Consider the server side.
I’m not going to reveal to anyone that already, like a few years, how nginx can proxy websockets. If we use php-fpm as a backend, then for every running WEB client, we need to have a PHP process running. There is a 10K problem when 10K processes will hang on 10K requests. Tritely not enough memory. As one of the options, you can use node.js. This is just his class of problems where long-playing non-blocking connections are used.
And you can do without him? After all, I would not like to introduce a new entity, especially as we assign it a very simple task. The more complex the architecture, the more points of failure and the less likelihood of failure-free operation. We already had a positive experience with the implementation of the nginx-lua module (You can read more about nginx-lua here and here ). And can he perform these functions? In general, the result was this picture (picture 2):
It turns out it is not so difficult. In addition to lua-nginx-module, we connect lua-resty-redis and lua-resty-websocket . To do this, unlike lua-nginx-module, you don’t need to compile anything, just copy all source codes of the modules in the lib directory into the folder: / usr / share / nginx / lua / lib and connect with the http ( configuration file nginx.conf):
Next, in the nginx.conf configuration file (or the plugin config for our virtual host), we define location / ws:
The websocket_server.lua file itself is not so complicated, I don’t see the point here in parts. Its full version can be found on github .
For verification, there is a test console client that can be modified and run into several thousand instances with different time-outs and verified in practice. This version of the client is interactive, the name of the channel is entered from the console, and if a publication is sent to the channel, it is instantly sent to the client. The client has a timeout of 5 minutes.
I hope this feature will be useful to someone.
There are several options for solving this class of problems. The most optimal and common solution is to subscribe to events. How is this implemented in loaded projects?
Suppose we are developing a brokerage service in which thousands of clients are served. In order to find out the status of stock prices on the stock exchange or to find out the number of available places in hotels, we need to apply to one or several external services. Since the external service responds with a delay, and we have thousands of customers, if we make requests directly from the WEB application and wait for a response from the service, everything will hang as a result.
Therefore, we have to do the so-called pending request. Our WEB application immediately returns the generated HTML page to the user with no result, which shows the splash screen that the request is being executed, and the result comes a little later, as it is executed. How does this happen?
')
Before starting the formation of the HTML page, our WEB application puts the data into the queue. The daemon, or the task called on the crown, scans the queue and takes data from it. Further, on the basis of this data, it forms a request and sends it to an external service (picture 1).
It seems that everything in this scheme is good - it works without delay. But we need feedback. The end user needs the information he requested. And so, we received this information in our cron script. Now it is necessary to forward it to the user.
Here the Publisher-Subscriber pattern will help us. Many who use JavaScript know this scheme:
The subscriber (Subscriber) subscribes to a channel, and when a certain event occurs, the Publisher (Producer) sends a message to this channel. As such a notification mechanism, you can use many different solutions: Redis, RabbitMQ, Tarantool, MsMQ, ZMQ, Kafka (message broker). Since we have a number of services already tied to Redis, we decided not to introduce new entities.
How would you use it? There are several options here, but experts at once in three throats will say “To connect the WEB page and the server, use websockets”. I will not argue, yes, today is the most advanced technology of instant communication between the WEB client and the server. Consider the server side.
I’m not going to reveal to anyone that already, like a few years, how nginx can proxy websockets. If we use php-fpm as a backend, then for every running WEB client, we need to have a PHP process running. There is a 10K problem when 10K processes will hang on 10K requests. Tritely not enough memory. As one of the options, you can use node.js. This is just his class of problems where long-playing non-blocking connections are used.
And you can do without him? After all, I would not like to introduce a new entity, especially as we assign it a very simple task. The more complex the architecture, the more points of failure and the less likelihood of failure-free operation. We already had a positive experience with the implementation of the nginx-lua module (You can read more about nginx-lua here and here ). And can he perform these functions? In general, the result was this picture (picture 2):
It turns out it is not so difficult. In addition to lua-nginx-module, we connect lua-resty-redis and lua-resty-websocket . To do this, unlike lua-nginx-module, you don’t need to compile anything, just copy all source codes of the modules in the lib directory into the folder: / usr / share / nginx / lua / lib and connect with the http ( configuration file nginx.conf):
http { lua_package_path "/usr/share/nginx/lua/lib/?.lua;;"; ... } Next, in the nginx.conf configuration file (or the plugin config for our virtual host), we define location / ws:
location /ws { content_by_lua_file /path/to/file/websocket_server.lua; } The websocket_server.lua file itself is not so complicated, I don’t see the point here in parts. Its full version can be found on github .
For verification, there is a test console client that can be modified and run into several thousand instances with different time-outs and verified in practice. This version of the client is interactive, the name of the channel is entered from the console, and if a publication is sent to the channel, it is instantly sent to the client. The client has a timeout of 5 minutes.
I hope this feature will be useful to someone.
Source: https://habr.com/ru/post/312504/
All Articles