Saga about the cluster. Everything you wanted to know about Postgres horizontal scaling

Oleg Bartunov (@zen), Alexander Korotkov (@smagen), Fedor Sigaev
Ilya Kosmodemyansky: Now there will be the most burning topic on PostgreSQL. All the years that we have been engaged in consulting, the first thing people ask is: “How to make multimaster replication, how to achieve magic?”. Many professional wizards will talk about how this is now well and great implemented in PostgreSQL - the guys from Postgres Professional will tell everything about the cluster in this report. The name is appropriate - “Saga” - something epic and monumental. Now the guys from Postgres Professional will start their saga, and it will be interesting and good.
So, Oleg Bartunov, Alexander Korotkov and Fedor Sigaev.
Oleg Bartunov: Ilya said that we will talk about how Postgres has everything well with the cluster, but in fact we will tell you about what is happening in the Postgres community with this topic. In fact, the topic is ambiguous, and we will try to show it, why all this is not so difficult, and what prospects await us.
')
First I want to introduce myself - the three of us are the leading developers from Russia in the Postgres community.

Everything that we did in Postgres, we tried to list in this small table (on the slide), you probably know our work.
We decided to first make some play and show how difficult and painful it is to work with distributed things. The first slide we have is called "Distributed misfortunes."

Fedor Sigaev: I will continue.
When they talk about a cluster, as a rule, they are either people who understand what it is about, and then we immediately delve into the details: "how you have done this and how it is implemented as a single commit, and how you interact with the nodes, and as a recovery? ”, or these are people who come and say that a cluster is“ we will put several wheelbarrows one under the other, they will all work and we will be happy ”.
I wanted to show in the sketch that it is not so simple, and any cluster requires some solutions. First, I will ask Ivan Panchenko and Kolya Shaplov to leave - we will appoint them as servers. Server A and Server B. We will act in the hope that they are honest servers, i.e. honest databases. Sasha, I will ask to be a client. The client is not in the sense of who came to the bank and broke up with the money, but in the sense that this is some kind of application that serves external clients of our bank. We will not keep in mind those customers directly. Actually, the client is our application.
Here our application begins a transaction and distributes on the begin command. After that, the client comrade departs from the databases, shakes hands with them and says that they need to be done in some abstract manner: “change something here, insert it, delete here, it’s absolutely not a matter of principle”.
Now, as everyone likes to say, a two-phase commit solves our problems. The client distributes them to the prepare command. What does the database actually do? It performs all the triggers, it checks constraint, etc. After that, if these commands have passed, the database promises that the commit will always take place, i.e. whatever happens even when power is lost.
Here, our client issues one commit, goes to one database. Vanya we have commited. But during the second Sasha goes, goes, and then the light turns off - all three of them fall. Fell. Light turned on. They rise, but the commit did not come. The client is not a dream at all, because everything is gone. The database named after Vanya Panchenko read her WAL logs, read that she was in a happy state — I did everything. The database provided by Kolya, server B, reads its WAL-log, finds what is written “prepared to commit”, and then hangs up with a question - there was no commit. What should she do? And she has absolutely nowhere to go. The client does not know anything about this, Vanya, too - he has his commit. Question: what to do, how to get out of this situation?

One database all successfully zakommitila, the second hangs in the question. There are not many outputs. Call the DBA or someone else, for example, a system administrator. He tries to understand from the logs what has happened, that in one database it is committed, and in the other - not. At this time, if you are not afraid of losing money, then your cluster works with inconsistent data, or you completely stop the service, say that we are doing technical work, we find out who owes how much to whom.
Or you enter into the work of the arbitrator. The client will go to the arbitrator, not to our databases, it is the arbitrator who will distribute the tasks, write himself in the log that we are “prepared to commit”, or “we have done this”. After that, it distributes commits and logs itself to the log that the first base is recorded by the commit, and the second is not. Next, we wake up, read the logs and the unfortunate Kolya, we say: “commute what you have found.”
The trouble here is such that writing this arbiter from scratch is also a very, very difficult task. And still, you have a moment when you told the commit to the base, but you didn’t have time to write yourself to the log. So, this is one of the problems. One of the many problems faced by any cluster solution that wants to be / seem reliable.
For the next scene, let's imagine a bank that has 2 accounts, we have 1000 credit cards in each account. We have one account with Vanya, one - with Kolya. Client 1 (Sasha) polls the amount of bills. What does he see? He sees 1000 credit cards, 1000 credit cards, in the amount of 2000 credit cards. Then Sasha starts a transaction - he gives “-500 credit cards” to one base, the second “+500 credit cards”. And after that he asks: “what do you have in total?”. In total, he has: Vanya, he sees the result of 1500, and Kolya has 500 credit cards taken away - he has 500. Everything is good. Client 1 sees 2000 again.
Then Sasha starts this commit. He starts kommitit with Kolya. At this moment, client number 2 wakes up (a girl from the audience) and comes up with the question: “show how much money you have”. Vanya's transaction is not yet committed, and what does the first client see? He sees 1000. And Kolya’s commit has already come - he already has 500. What does the unhappy second client see as a result? That money has gone somewhere. He sees a total of 1500!
These are the problems of inconsistency - you cannot commit to two different databases at the same time. Those. you always need to deal with it somehow. Loki expose, and outside the database, or to prohibit access to databases. Here is a staged misfortune right in the faces, what problems can be encountered.
Oleg Bartunov: The conclusion from this view is that you cannot have a complete read with a two-phase commit, i.e. even reading cannot be complete.
Fedor Sigaev: Here we were not even very attracted to the two-phase commit, i.e. a two-phase commit complicates the situation with running around, but in fact you still leave a “hole”, during which you have already made one commit and the second does not. Therefore, you will always have that moment when your state of the two bases is inconsistent.
Oleg Bartunov: After we have shown you that everything is not so simple, we will move on to some political games.
Why political games? This is a conditional name. Postgres is developed by the community, and in the community we have a kind of democracy, and in order to achieve any one decision, you have to use a lot of any gestures, conversations, etc. I call all this political games.
Until recently, we never thought about it at all. And literally 2-3 years ago, this situation arose in open source, since open source is becoming the dominant software development model. On this graph you can see the global trends:
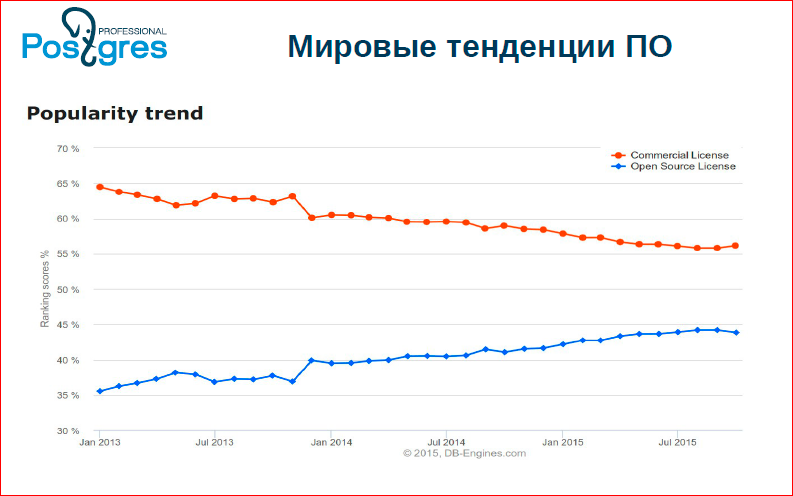
We see that open source databases are growing, and proprietary databases are falling.
Just a solution model. Here, the Gartner's Magic Quadrant shows: on the left - for the last year, and on the right - this year.
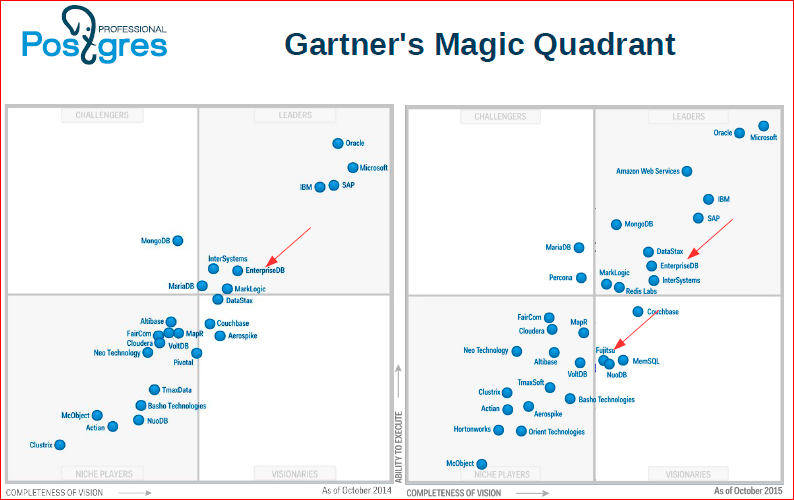
We see that Postgres in the face of EnterpriseDB and Fujitsu has already become a leader in databases. This is a rather remarkable event that, for the first time in 2014, the open source database entered the list of database leaders. Those. the market is heating up.
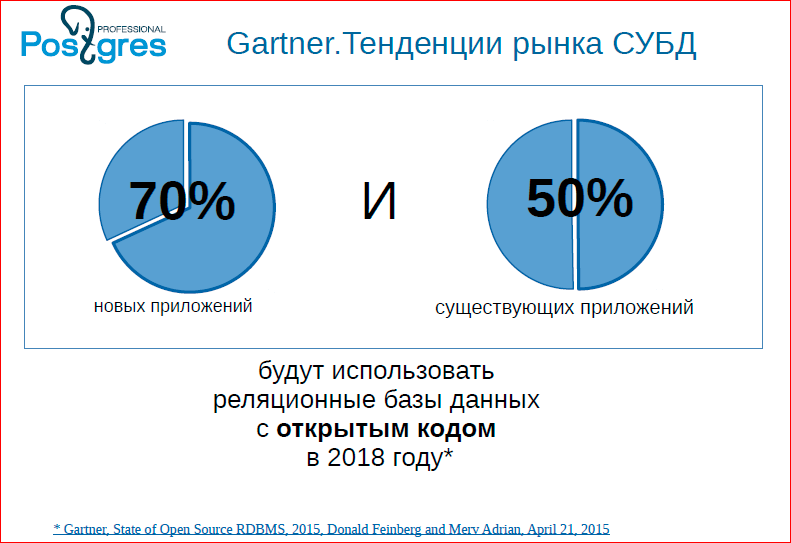
It can be seen that 70% of databases will already be open source in 2018. This is a prediction, you can believe in it and not believe it, but the tendency is that now people are more and more eager to start using databases. And the open source database leader is Postgres. There is also MySQL - this is also a very good database, but Postgres is a serious database, which is now at a very good take-off. And this is felt in our community, because all the clients we come to start asking questions, start to demand some features from Postgres.
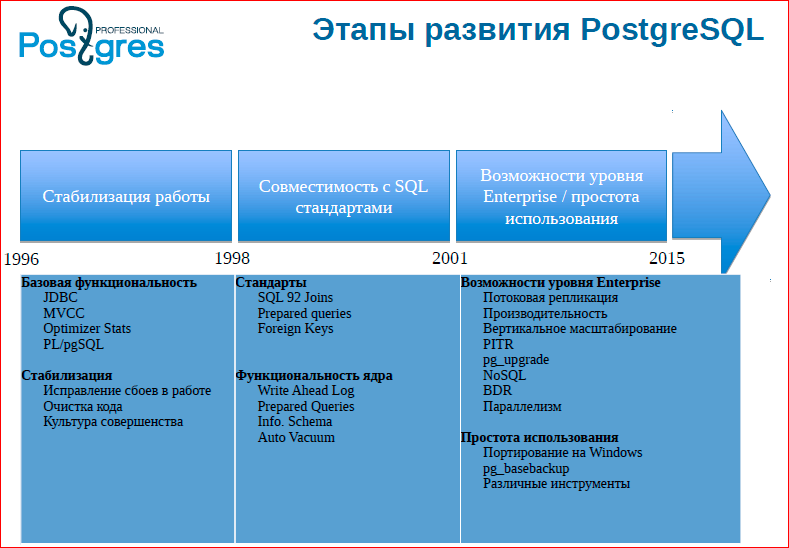
I’ve stolen this slide from the EnterpriseDB presentation, it shows Postgres development stages. They have designated: now there is an Enterprise stage. Pay attention to the features that are written there, what they call Enterprise. Everything is good, but we do not see the word "cluster" there. Those. it really is, really. We still have no opinion in the community that we need a cluster solution.
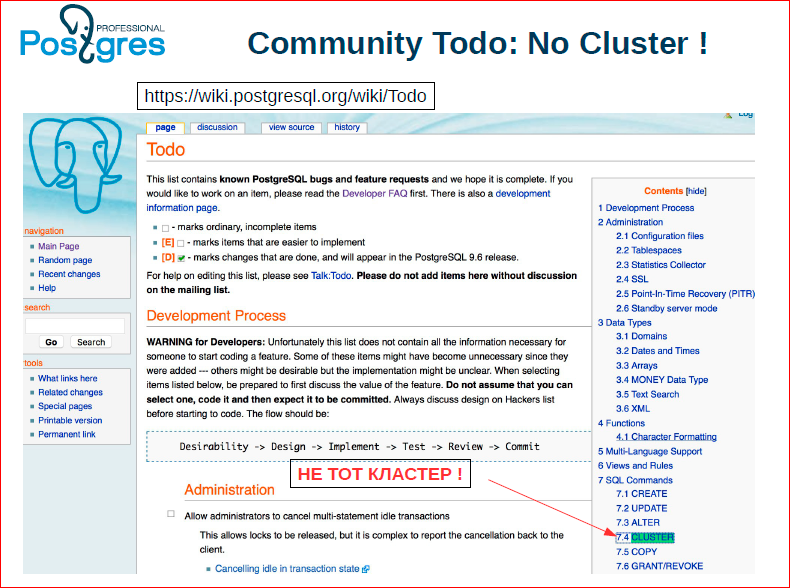
If you look at our Todo (I specifically made a screenshot) - we have a cluster there, but this is not the cluster. This is the cluster command. Those. even in our Todo there is not a word about what a horizontal cluster should do, etc.
It was all not done by chance. On the one hand, the community is conservative, on the other hand, the market has not yet supported us.
Now, especially in Russia, Postgres is considered as a candidate for very large projects, and the concept of a cluster has become a must have.
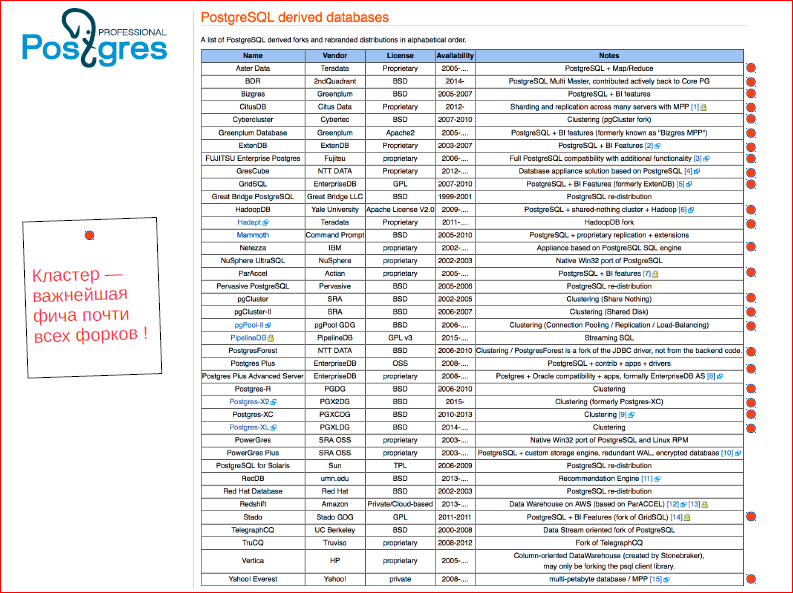
Look at the Postgres forks page. See how many forks. And that's not it.
With red circles I marked those forks in which the cluster is a feature. We see that practically all the forks that appeared from Postgres appeared only because they lacked a cluster. And, in the end, the community began to think about what the cluster really should be in our Todo, what we have to do.

This is not the first time this happens. Old-timers Postgres, old users, remember the talk of replication. Once Postgres did not have replication, and it was said that replication is not needed in the kernel, replication must be a third-party product. And so it was, until, again, users, the community suddenly realized that it should be at the core. And it appeared with us and now replication is a good, normal tool that everyone uses. There was also a story about the port on windows - how much we wanted, how much power we had, we otbrykalis from the port on windows, but in the end it was done.
Fedor Sigaev: But we otbrykalis, we did not.
Oleg Bartunov: As a result, the very revolutionary situation has now come, when the lower classes want, the leaders did not dare. Moreover, an interesting situation - we organized a company, we talk with our customers, and we say: “we make a cluster”. The 2ndQuadrant says the same thing: “we make a cluster”. EnterpriseDB says: “we also make a cluster”. However, all customers, as one, say: “we are not interested in your roadmap, we are interested in the roadmap community”, i.e. you need the community to have this cluster and the community to work.
On the slide, I briefly brought the decision, Sasha will tell.
Alexander Korotkov:
- Probably many have heard there Postgres XC XL. XL was a fork from Postgres XC. XC has now moved to X2, this is a separate fork, which implements sharding and replicable tables, it reaches global consistency through a separate service called GTM - Global Transaction Manager. It is being developed by the 2ndQuadrant, MTT and Huawei. Huawei, in addition, has its own proprietary fork MPPDB, this is fork from XC.
Oleg Bartunov: I want to say that these are databases that already have live users, i.e. many banks in China use these XC.
Alexander Korotkov: Despite the fact that there were bugs with consistency, China is so brave that it is ready to run the banks.
- There is pg_shard - this is an open source extension to Postgres, which provides basic sharding functionality. Again, there is no transaction manager, there is no distributed consistency, but you can use it for some web tasks.
- There is a Citus DB - this is still a proprietary base, which Citus Data promises to open. There are richer functions, i.e. more complex queries. There you can organize some kind of lab, but again for OLTP no distributed consistency is guaranteed.
- FDW is for now the approach that EnterpriseDB is trying to do for Postgres, i.e. add it to the main master branch. The idea is to use the already existing Foreign Data wrappers mechanism, i.e. appeal to some external data source in order to make a sharding. In 9.6. have already committed a patch that allows partitioning through the inheritance existing in Postgres. In the same way, if you do the inheritance of foreign tables, external tables, then you can make some fairly simple sharding. But, again, there are a lot of questions about how much the optimizer can optimize such distributed queries.
EnterpriseDB is currently working on patches so that Aggregate Pushdown can be done, i.e. in order not to draw everything from shards, and then count the aggregates, and so that the aggregates can be counted on the shards themselves. Similarly, Join pushdown ... And such a long enough roadmap, which may not be completely complete, is not clear when we get a full-fledged distributed optimizer. However, the advantage of this approach is that we are improving FDW, and that in itself is good.
- Greenplum is a commercial fork from Pivotal, which was recently released in open source 3 days ago.
Oleg Bartunov: You can download Greenplum on GitHub, compile, install, and you will already have the same massive parallel database that eBay has been working on for a long time, which now works at Tinkoff Bank, etc. Those. The open source development model here is open and shows its advantages.
Fedor Sigaev: Just keep in mind - these are OLAP databases, not OLTP, i.e. if you analyze something in Postgres en masse, then you can touch Greenplum or pg_shard, but it’s better not to get money there in the hope that they will be transferred reliably.
Alexander Korotkov: And our project that we started is the Distributed Transaction Manager for the Postgres wizard. About him, we will tell a little more separately.
Oleg Bartunov: These are such lively active projects that exist, that have their own customers, they are developing. And we see that there are resources, and there is no community decision.
In the past PGCon, we raised this question and agreed that after all we will arrange a big meeting, the so-called cluster summit, where we will solve this problem, what will we do with it, how to live?

2 days ago we flew in from this meeting. We met in Vienna and discussed the burning problems of the cluster, i.e. raised the question of whether the community will have a cluster solution in Todo or not.

We decided that the situation has matured so much that it should be designated in our Todo. At the same time, we must continue to develop cluster solutions, because, as we have already shown, cluster solutions are very complex things, and we cannot say in advance that tomorrow or in 2 years this solution will win, therefore solutions must be developed. At the same time, they should evolve in such a way that, say, our company’s commit does not block the road to other solutions - this is very important. Decided - peace and love.
The idea was to make Postgres infrastructure so that cluster solutions could be developed as extensions, which would greatly facilitate development. We told about our distributed transaction manager, this idea seemed interesting to people, and we will push through this business in 9.6, i.e. in 9.6 we will try to have distributed transactions already in Postgres, and anyone could already do a cluster, at least? at the application level.

I added to the slide that I took from EnterpriseDB, October 31st, 2015. I called this period as horizontal scaling (sharding), and we wrote a list of tasks that we will need to solve. Those. this is what we are promoting in the community now, so that the community is concerned about this.
Alexander Korotkov: The goals are clear, and we want scalability for both reading and writing, except for this, in order to have high valability. This can be achieved, for example, by using redundancy, i.e. the same shard is kept not in one copy, but in two copies.
And the tasks here are broken, here are the largest. It is clear that they are actually even more. The task we are busy with is managing distributed transactions. The place where many different interests now intersect is the scheduler and executor of distributed queries, i.e. FDW is one approach to distributed queries, pg_shard is another approach, Postgres XC XL is the third approach. And maybe another 4th, 5th, etc. But we hope, sooner or later in this direction, we, too, will come to some common denominator.
Oleg Bartunov: Bruce Momzhan is here at the conference, he is a responsible person who should write a paragraph on clustering on Todo, and then everything will work out for us, because we must somehow combine our efforts.

This picture means that there are a lot of ingredients, you can make a lot of things from them, but not the fact that it will work out.
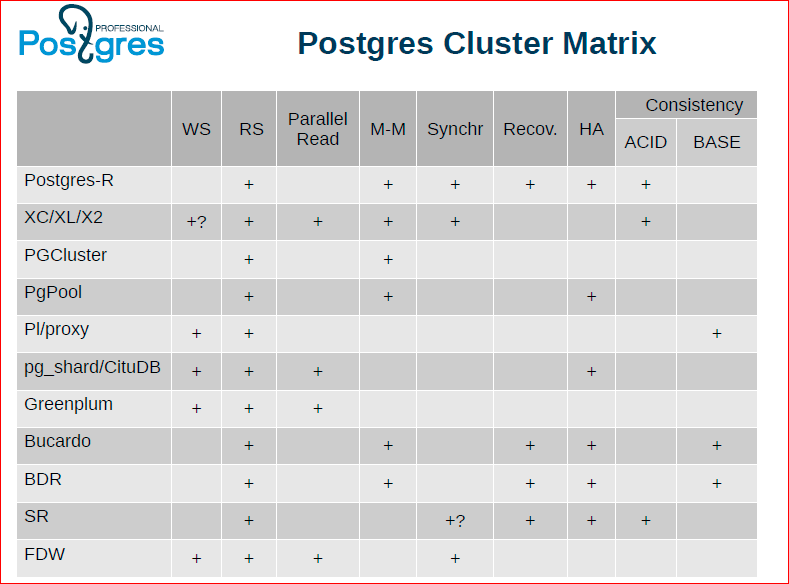
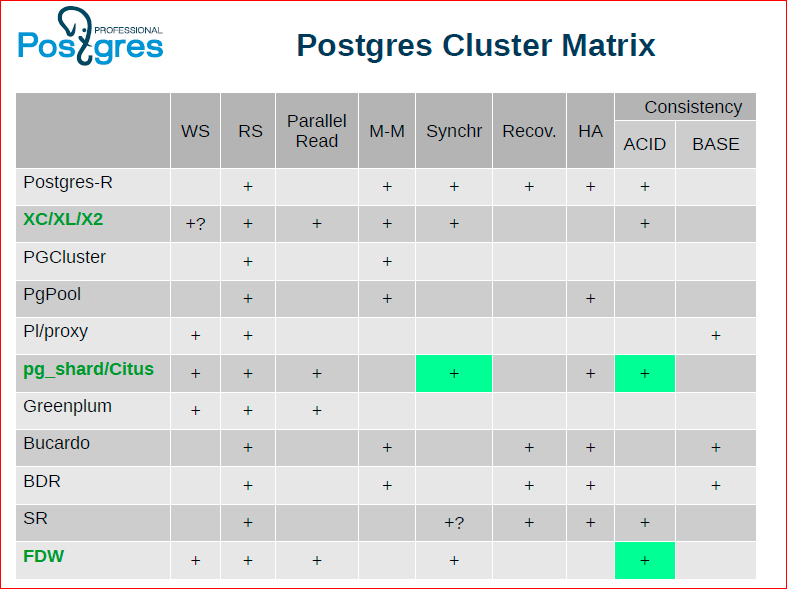
Alexander Korotkov: We tried to make such a matrix in the table, we entered cluster solutions here, and both those that now exist and are developing, and those that once were in history and are no longer supported.
Fedor Sigaev: We took the most popular. Oleg initially showed that this matrix is even bigger, we could make pixel-by-pixel graphics, but nothing will be clear from it.
Oleg Bartunov: One can consider this table for a long time, one can argue on it, it shows that there is no perfect solution. For example, XC / XL / X2 looks the most attractive, it has the most plus signs. FDW and pg_shard also have a lot of pluses, but something is missing, in particular, they lack data integrity.
When the whole fight began, each company declared that “we make decisions, our decisions are good,” etc. After all, we also took XL and started playing with it, we decided to make our cluster, but then we realized that XL was not very ready to use it in production, and we decided not to get involved in a common fight, but to concentrate on that common technological an element that everyone needs. Those. all cluster solutions need a distributed transaction manager.
Therefore, we chose this direction and implemented it. Now, we will tell what it is and why it is important, and what it gives to cluster solutions.
Alexander Korotkov: What do we, in general, want from a distributed transaction manager? It is clear that we want the commit on our distributed system to be atomic. Atomic means that, firstly, it is either atomically everywhere, or else it has rolled away. Secondly, we want its atomic appearance, i.e. This means that if you make a request to read to several databases (what we showed in the 2nd sketch), then we must either see everywhere every single commit or not see it everywhere. There should not be such that we saw on one server that the money had already been transferred, and on another server we saw that they had not transferred, and as a result, the amount did not converge.
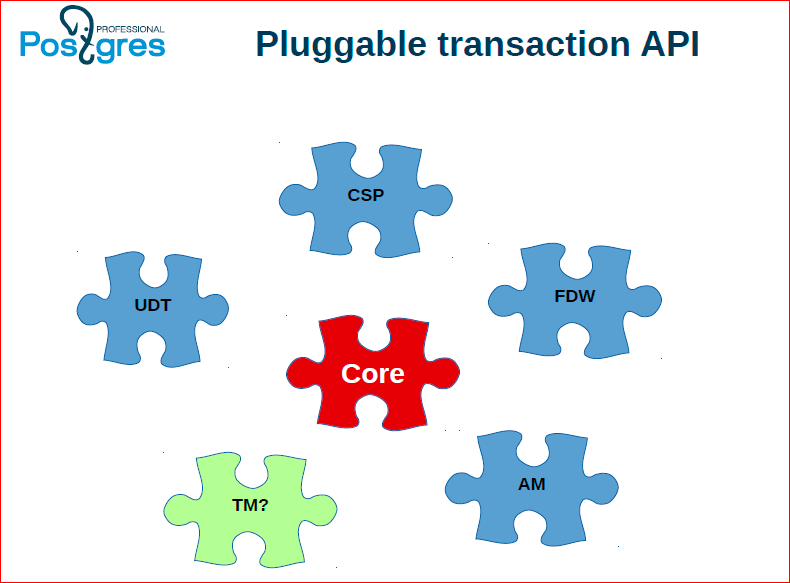
There are different solutions for this problem, none of them are ideal in their properties. I’ll talk about this in more detail in the next slides, but I’ve got the idea that we want some pluggable API for the transaction manager. Those.we have a manager in Postgres that allows you to perform local transactions - this is one implementation, then add to it several implementations of distributed transaction managers. So far, we can highlight three things, perhaps, then, we will have some more ideas, maybe even better than the ones we see now.

We took and allocated API which is necessary to implement such manager of distributed transactions. This is just a set of functions that Postgres has previously been protected with, and we select them into a separate so's, into a separate library, which can be changed.
Oleg Bartunov:In general, we are just following the pluggable path. We have a glider pluggable, executer pluggable, we can do data types, indexes, and now we have Transaction Manager also be pluggable.
Fedor Sigaev: For those who don't know, the Postgres executer is completely pluggable, i.e. you can use absolutely your executer, just like a glider.

We are asked: why these seven functions, and not the other seven functions on the previous slide? The answer is this: because we tried three different managers by nature and found out that these seven functions are enough to bring the Transaction Manager from Postgres into a separate process.
Alexander Korotkov: Seven because we would like six, but six did not work, but eight are not needed.
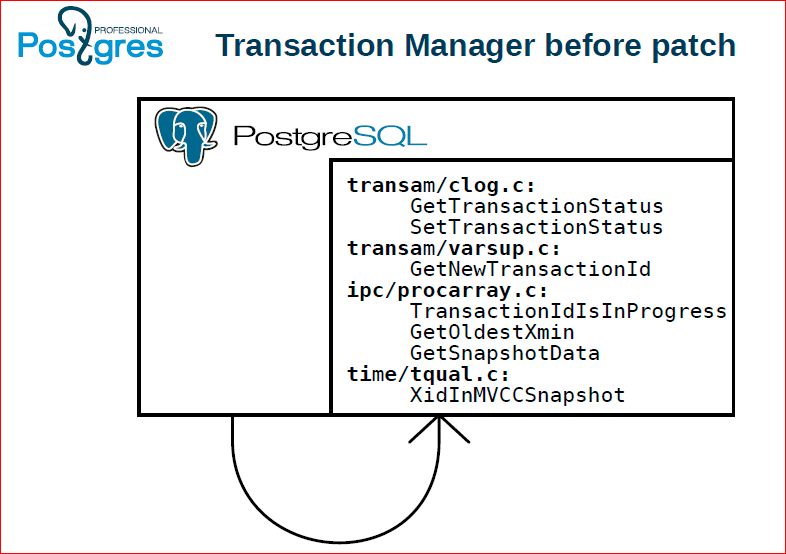
This is how it was before the patch, i.e. if all these calls went directly, they were wired into Postgres itself.
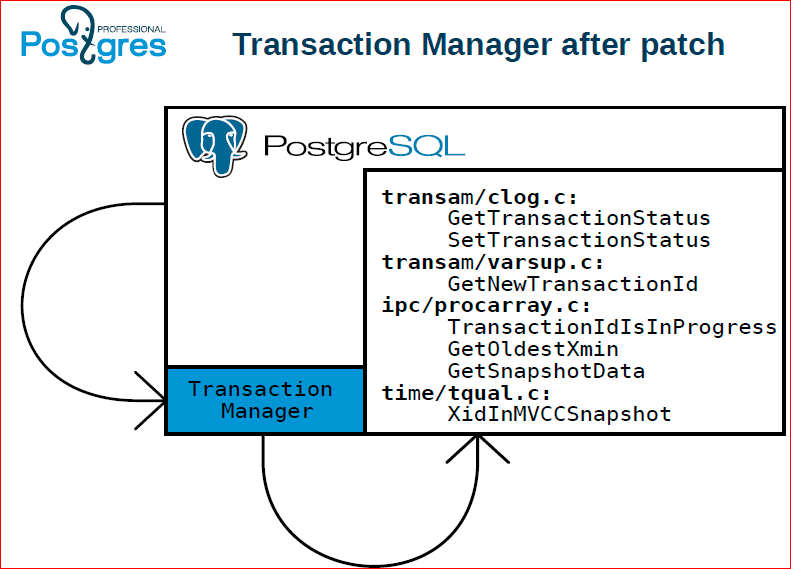
And then we selected it in a separate component called Transaction Manager.
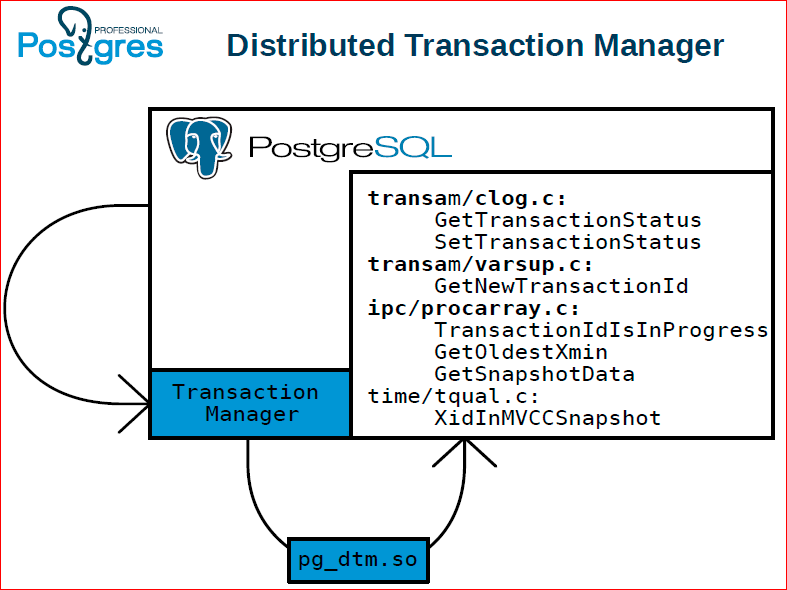
Further.
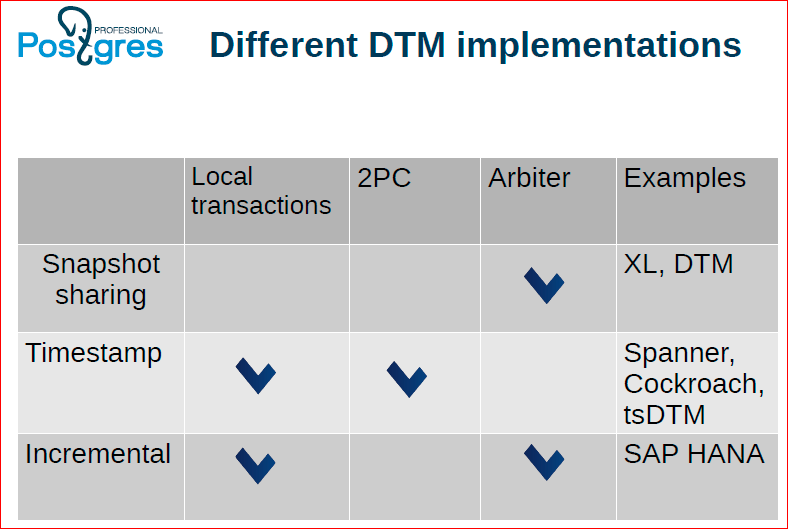
This is about how we have varieties of methods for managing distributed transactions, what advantages and disadvantages they have.
- — Snapshot sharing — , Postgres XC, XL. , , , . , , , - , . ? , . , , , — , , ..
- Timestamp. , , , Timestamp. Timestamp, , , , , , , . MTP , . , , , , , . . , , , , - , , , . , two-phase commit, , , .
- — . , . , . , , , ' , , , .. , . , , .
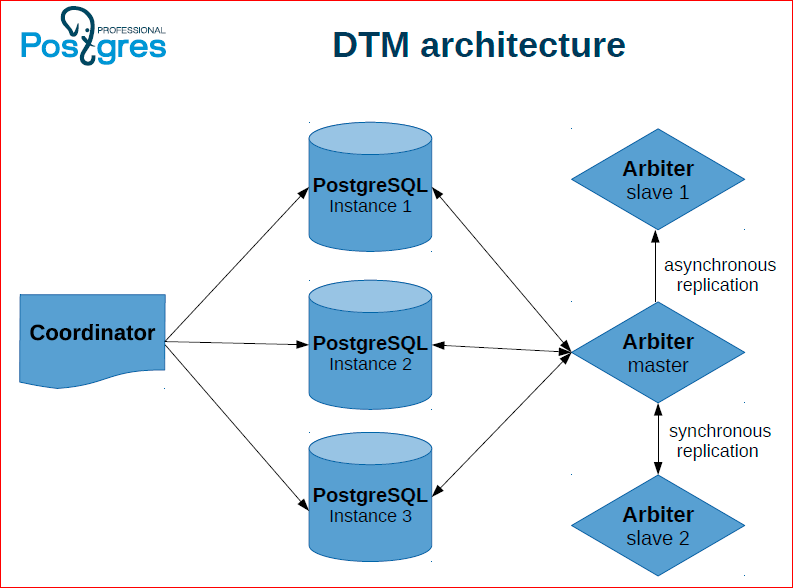
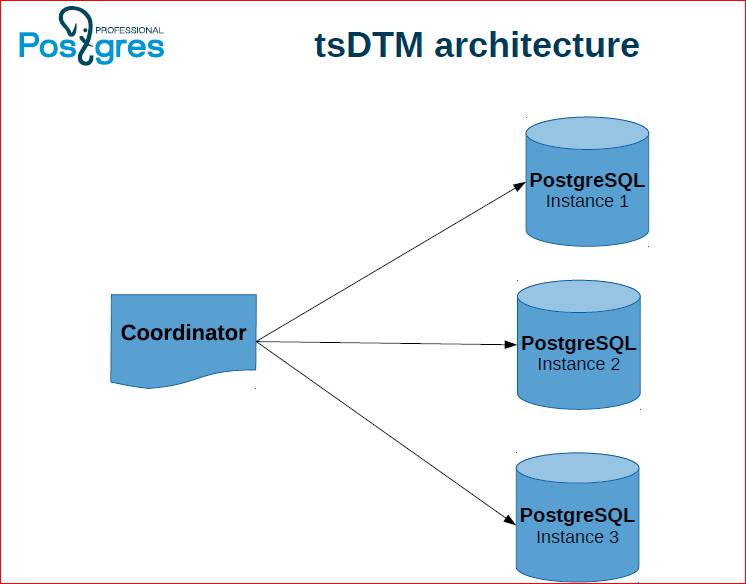
This architecture is the first approach we call DTM. We have several Postgres instances where data is directly stored, a coordinator who performs transactions and an arbitrator who stores transaction statuses gives snapshots. Moreover, in order for this arbitrator not to be a single point of failure, we also duplicate it, make slaves, and in the event of a failure, we switch the arbitrator to the slave.

Here's how it can work: our coordinator keeps two connections to two servers. From one of them, he starts a distributed transaction, and the other says to join this distributed transaction. Then it performs some actions, and then performs commit on both nodes.
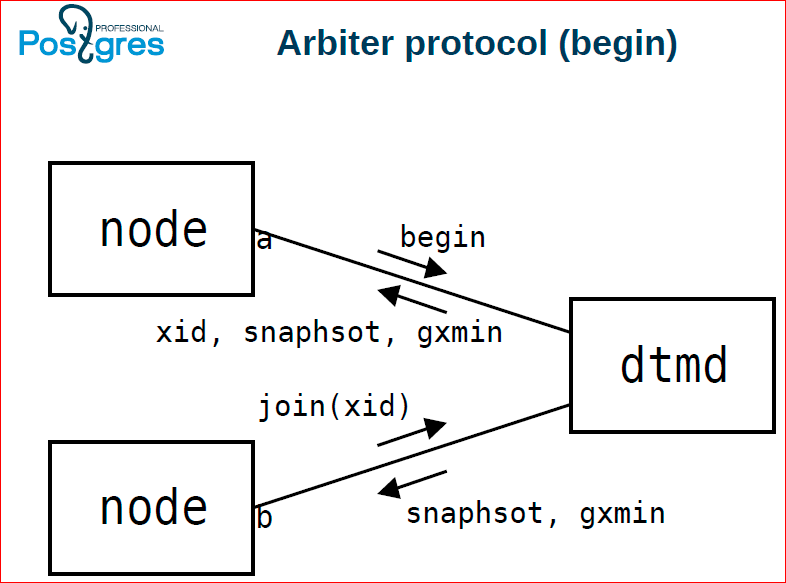
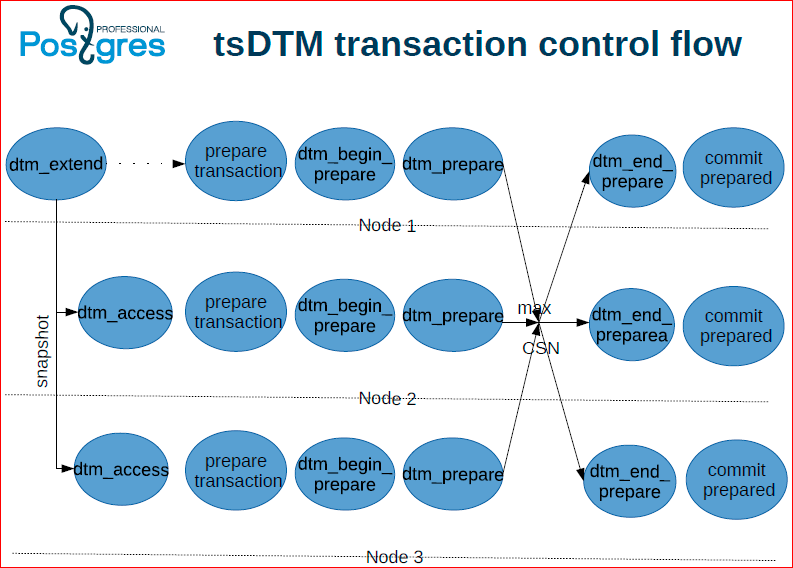
At the same time, these two nodes work with dtmd - with a daemon to support distributed transactions. The node from which the distributed transaction started begins, in response, it is assigned the id'shnik of this transaction, snapshot. Then the next node joins this transaction, gives the join command, also receives a snapshot. Global xmin must be maintained so that the vacuum can be distributed only the necessary things to clean.
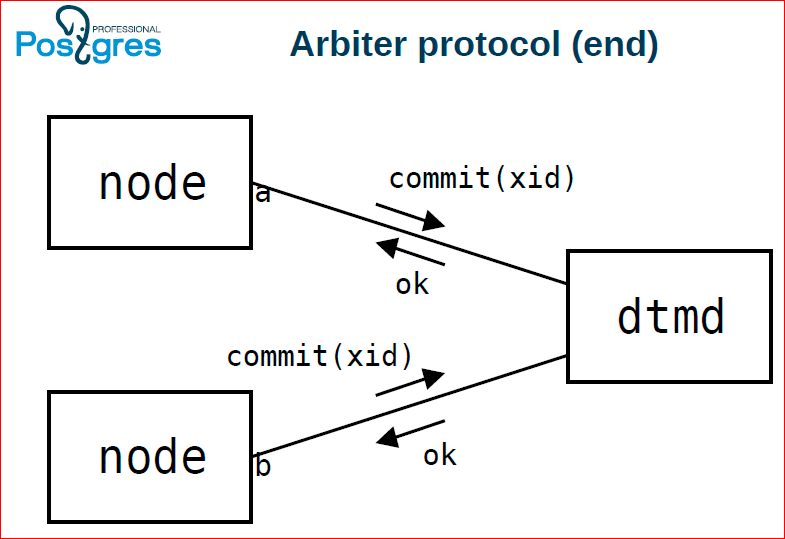
In the end, both of these nodes send a command, the client says a commit, they in turn send a commit to dtmd too. If dtmd sees that a commit has come from each of the nodes that participated in this transaction, then it returns OK to both of them. If at least one of them told him a roadback, then he returns an error to all of them.
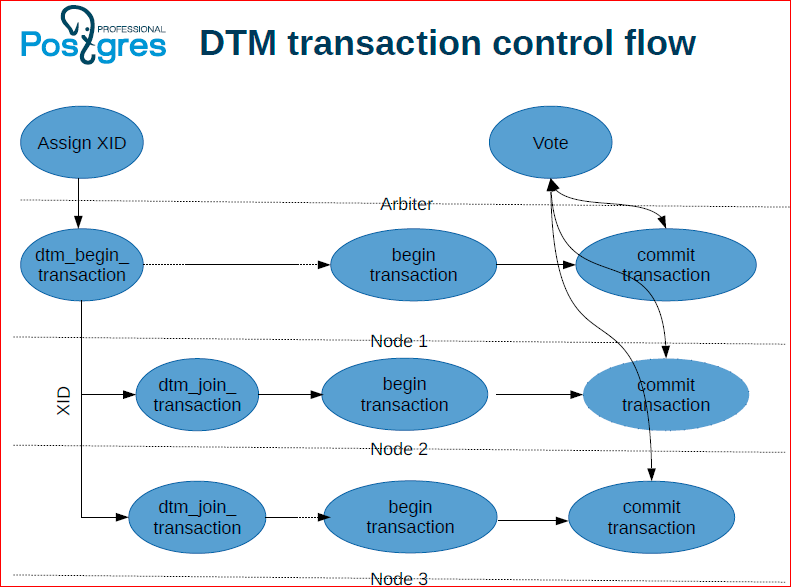
flow - this is what I explained, only in the form of a diagram.
Another option is when there is no timestamp on the Timestamp, everything is up to the Postgres instances and the coordinator.
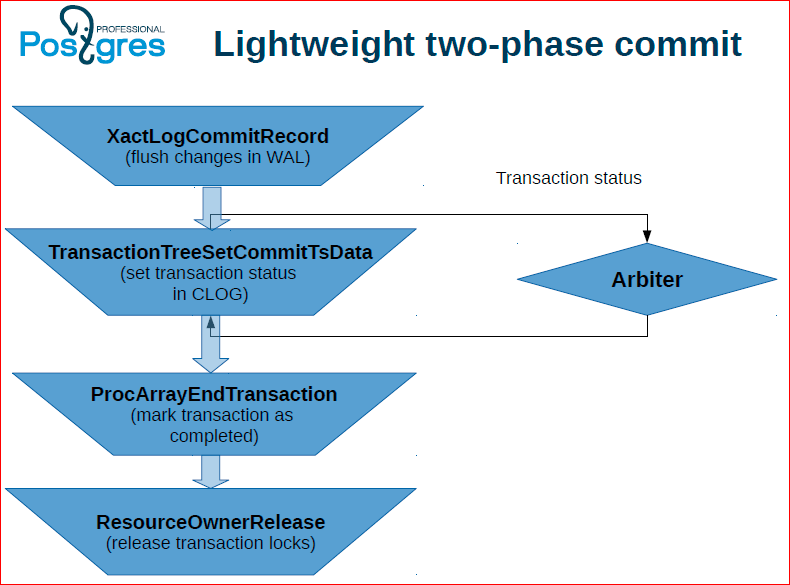
Here, about the same, but the feature is that you actually have to do a two-phase commit. We hope that we can make it easier later.
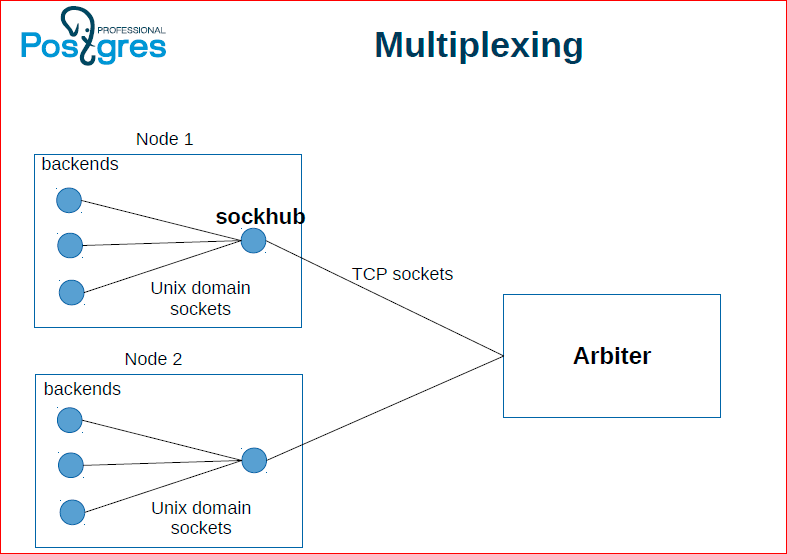
This is about communication with the arbitrator. If for everybody, i.e. for each receipt of a snapshot, we are sent a separate TCP packet to the arbitrator - this happens for a very long time, so there is a special demon, do sockhub, which accordingly groups calls to the arbitrator and sends them in batches and receives responses.



Here are some examples that we used for benchmarks.

The classic banking example, when we remove one account, transfer it to another - our second scene. Similarly, we had a second stream, which in our scene was performed by a girl, from whom we considered the sum and checked whether it converges or not.
Oleg Bartunov: Here in the example we used pg_shard. pg_shard you can download, download even a patch, and you will have transactional status.
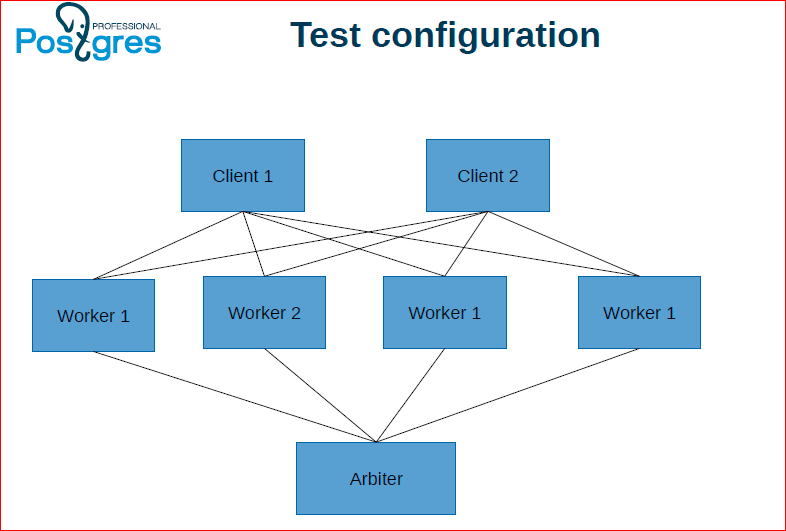
Alexander Korotkov: We have taken and applied our approach to distributed transactions to existing solutions that do not have support for distributed transactions - this is pg_shard and FDW.
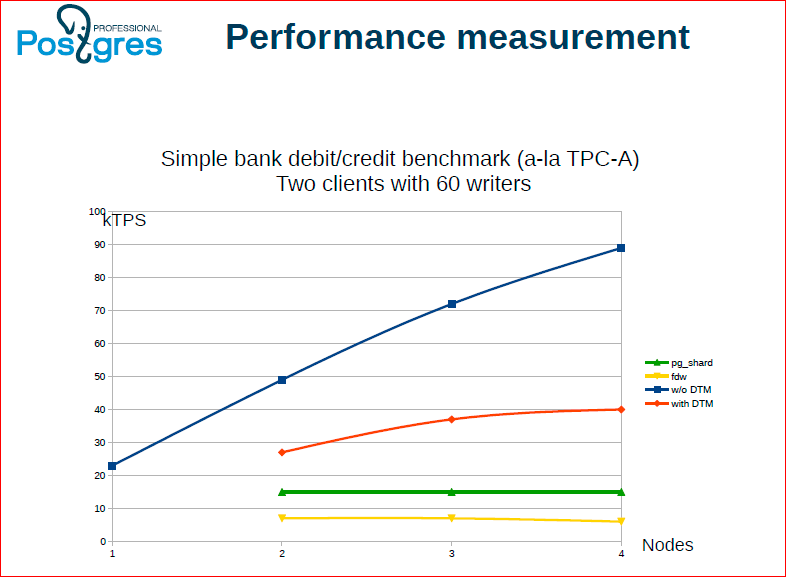
Here are the results.
- Blue is how we did without a distributed transaction manager. Those. speed here due to the lack of consistency between nodes.
- Red is when the client application does everything.
- Green is pg_shard.
- Yellow - FDW.
Accordingly, we found that we rest against the speed of interaction with the arbitrator. A certain optimization has already been done, then we continue to do further. To all this, we have an approach with a timestamp, which is very promising in terms of scalability, because there is no single point in it where everyone goes for snapshots.
Oleg Bartunov: You are not upset here, which is lower than the blue one - you can never be faster than the blue one, you have to pay. Here it is important that it is scaled, that three nodes are faster than one, and at the same time both consistency and high valability are respected. I myself first upset.
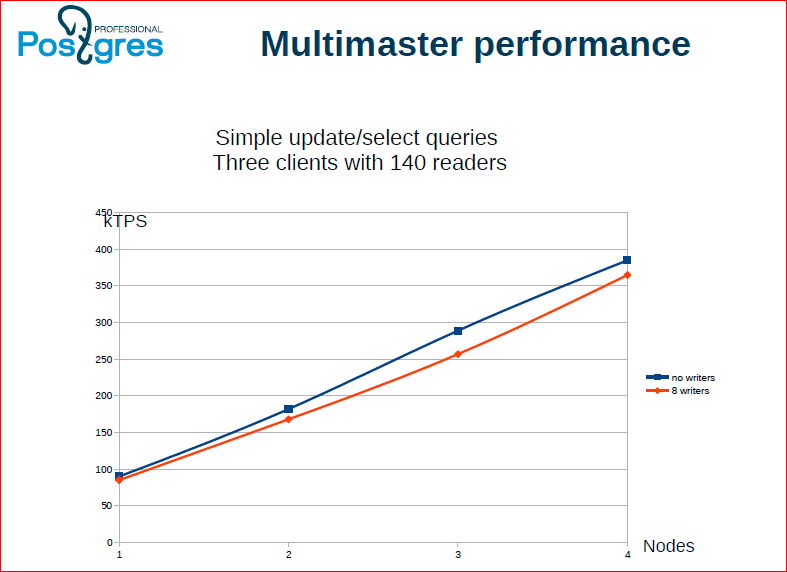
We did a multimaster.
Alexander Korotkov:We have some limited number of writing streams that replicate their write operations between all servers, and there are reading streams. You can see that the reading is scaled linearly, as expected. In the case when we have a multimaster, we can read from any server.

We have the following roadmap - make a patch called XTM - an expandable transaction manager for 9.6., Then experiment with different different approaches to implementing a distributed transaction manager, including bringing the Timestamp approach to mind, continuing our work on integrating with different solutions.
We have shown who can now benefit from our work on the distributed transaction manager:
First, these are pg_shard and FDW - they can actually get their ACID properties thanks to our distributed transaction manager. And forks XC / XL / X2, they can simply get less labor for synchronization with the master, because the distributed transaction manager will already be in the master branch and, accordingly, they can apply less labor, not synchronize their GTM.
Oleg Bartunov: Finishing, we thank you for your attention and say that we are waiting for the future. We hope that the community will insert it all into Todo ... Experience shows that Postgres, of course, is swinging, but then it does everything very well.
Contacts
» Zen
» smagen
» Blog of Postgres Professional
This report is a transcript of one of the best speeches at the conference of developers of high-loaded systems HighLoad ++ . Now we are actively preparing for the conference in 2016 - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
The most active and biggest track HighLoad ++? This is PostgreSQL! This year we were spun on a separate track, they bring their Western speakers, in general, they are coming off in full .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/312494/
All Articles