Date outside, date inside, date dance, date die

In the 2005 Data Outside and Inside Data article, Pat Helland reflects on data in service-oriented architectures. Currently, SOA is considered to be “microservice architecture” consisting of “microservice”. Helland shows that encapsulated data and data that services are exchanged require completely different approaches. The transition from a monolithic structure to microservices is deeper than simply refactoring code into convenient, independently deployable modules:
The transition to microservices is like a transition from Newtonian physics to Einstein's physics. At the time of Newton, the theory was somewhat at variance with practice, which did not suit everyone. Before the advent of microservices, many systems for distributed computing looked like: with RPC , 2PC, and so on. In Einstein’s universe, everything is relative and depends on a particular point of view. In microservices, the “present” is inside (the service), and the “past” comes in messages.
It seems that we should rename the “extract microservice” refactoring to “change the space-time model” :).
')
Recently, microservices have attracted a lot of attention. These are systems consisting of numerous services, each with its own code and data capable of operating independently of each other ... This work reflects a number of fundamental differences between the data inside the service and the data sent to the external space, outside the service.
Let's figure it out.
Services encapsulate the data they own. Any changes, as well as read operations of this data are carried out through a strictly defined interface. Changes can be made only by the trusted application logic within the service. There are no ACID transactions outside the service:
Participation in an ACID transaction implies a willingness to hold a database lock until the transaction coordinator decides to commit or cancel the transaction. For the non-coordinator, this is a serious violation of his independence ...
“Inside Data” is encapsulated private data contained within a service. “Data outside” is information transmitted between independent services.
Past, present, future and “later”
Inside the service, we can use transactional data access, with transactional isolation, creating the illusion that each transaction is executed at a specific time ...
ACID transactions exist in the "present". As time progresses and commits transactions, each new transaction receives input data from predecessor transactions. The logic of the performance of services exists with a clear and distinct feeling of the "real".
Messages sent by a service can often contain service data. The sender will not apply locks to the data after sending the message. Consequently, by the time the recipient processes the message, the original data inside the sender may have changed.
The content of the message always comes from the past! It is never in a state of "present."
Each service has its own perception of internal data, forming an idea of the current moment. And external data form a view of the past. Command messages giving tasks to services are “hopes for the future.”
It turns out explosive mixture of past, present and future:
Operands may exist either in the past or in the future (depending on the pattern of their use). In the past, they live when they have copies of unlocked information from a remote service. And in the future they live when they contain the estimated values that can be used with the successful completion of the operator. Between services, everything is in a state of "later" ... As a result, data from the outside lives in the world of "later." This is either the past or the future, but not the present.
Since each service lives in its own present, the synchronization of this present with the incoming and outgoing “later” depends on the logic of the service.
Impacts of external data
Data from the outside must be immutable and identifiable so that it remains the same regardless of when and where it is referenced. As part of the service, you can refer to The New York Times, and the current version will always be kept in mind. In this case, The New York Times is an object that does not depend on the version of the identifier . But when data leaves the service, it’s not enough to say “The New York Times”; a version-independent identifier must become a version-dependent identifier . For example, "The New York Times, January 4, 2005, California edition."
Immutability is not a sufficient condition to avoid confusion. There must be an unambiguous interpretation of the data context. Stable data has an unambiguous and unchanging interpretation throughout “space and time” ... There are several ways to create stable data — using timestamps and / or versioning, or using unique and important identifiers.
Messages must be immutable (for example, their contents should not be changed if requests are repeated) along with their schema.
That is why it is recommended to version the message schemas, and each message should use a version-specific identifier to accurately define the message format.
(Further in his article, Helland discusses a scheme that provides extensibility.)
When referring to other data, it is necessary that the identifier used for the reference is also immutable.
Internal data
Internal data is the kingdom of SQL and SQL DDL. SQL and DDL live in the "present" ...
Like other SQL operations, schema updates via DDL are performed under transaction protection and are applied atomically. Changes to the schema can make significant differences in the ways of interpreting the data stored in the database. The key quality of the DDL is that the transactions preceding the DDL operation are based on the scheme that existed previously, and the transactions following the DDL operation are based on the new scheme. In other words, schema changes are involved in database serialization mechanisms.
The data received from the outside can be converted into a form convenient for use by the service. Suppose you can store external data in a “document” (for example, the article shows XML, the most popular language in 2005). Using this, you can achieve extensibility and add information that is not declared in the original message scheme.
Extensibility is much like margin notes. She often gives the desired result, but without any guarantees.
The second option is “shredding” data: conversion to a relational representation.
An interesting point - extensibility conflicts with the "grinding". Unplanned extensions should be displayed in the planned tables.
Choosing the right data view
The article concludes with a review of three different data representations — XML, SQL, and object encapsulation. (Now we can add JSON or replace XML with it.) SQL and XML / JSON, in fact, are anti-encapsulation: they make the data completely accessible. Components and objects, on the other hand, reinforce encapsulation.
Given all the above, Helland offers a table of requirements for internal and external data:
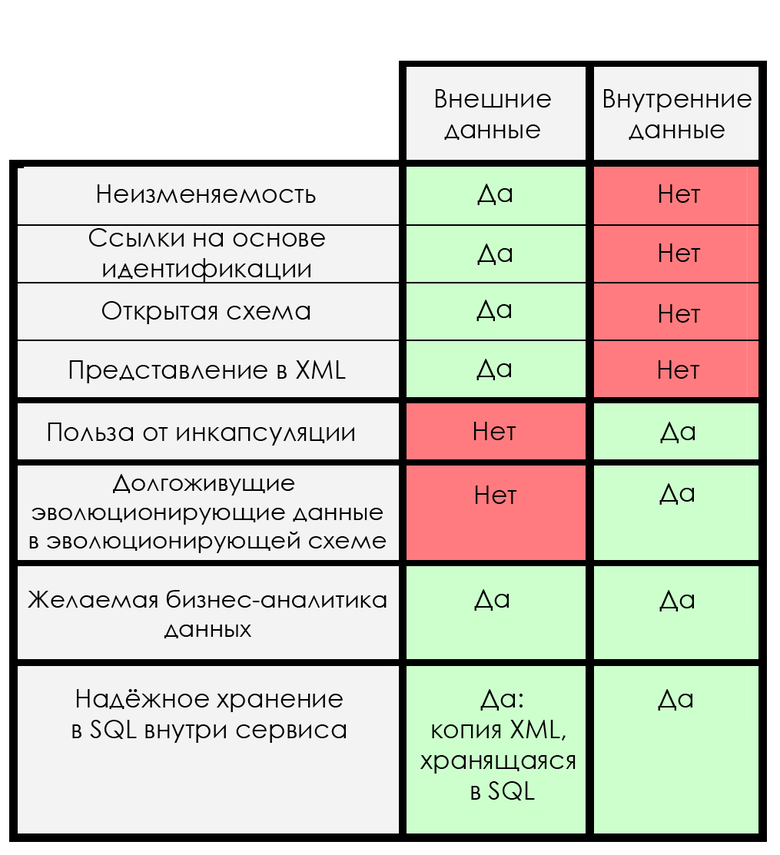
... We consider encapsulation and understand that external data is not protected by code. There is no generally accepted way to ensure that the code body is an intermediary in accessing data. Moreover, due to the current architecture, you must understand the internal structure of the message if you have access to it. Internal data is always part of the service and application logic.
Each of the three ideas has its advantages and disadvantages, so that they are different for internal and external roles:
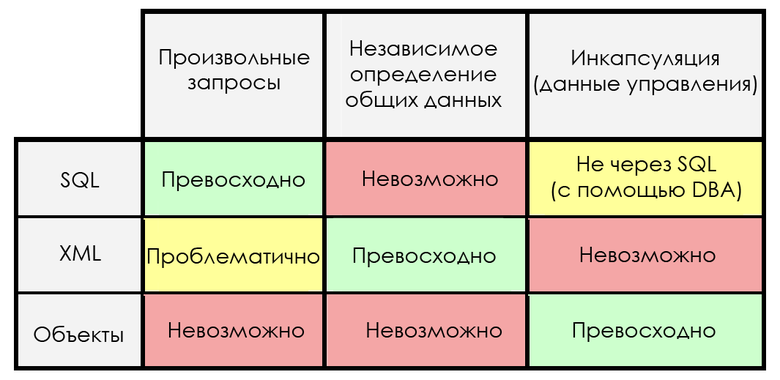
The advantage of each model at the same time is its weakness! The fact that SQL is great for creating queries makes it a terrible decision to independently determine common data. XML is great for independent definition and data creation, but is not suitable for encapsulation. Encapsulation is a key advantage of object systems, but incompatible with queries. None of these models can not add opportunities to compensate for their weaknesses, without losing the benefits!
So we can conclude that each of the models has its own role, all three are needed:
If you realize that most software developers are very smart, then this conclusion should not surprise you. Today, it is normal practice to use XML to represent external data, objects - to implement the business logic of services, SQL - to store data inside. We need all three submissions, and we should use their strengths to our advantage!
Source: https://habr.com/ru/post/312394/
All Articles