MapReduce from scrap materials. Part III - Putting It All Together
In the first (enough captain) part of this series, we told about the basic concepts of MapReduce why it is bad, why it is inevitable, and how to live with it in other development environments (if you are not talking about C ++ or Java). In the second part, we began to talk about the base classes of the MapReduce implementation in Caché ObjectScript, introducing abstract interfaces and their primary implementations.
Today is our day! - we will show the first example collected in the MapReduce paradigm, yes, it will be strange and not the most effective, and not at all distributed, but quite MapReduce.
WordCount - simple, consistent implementation
You have probably noticed that MapReduce is about parallelism and scaling. But let's confess immediately - the algorithm, no matter how elegant and simple it is, is very difficult to debug right away in its parallel incarnation. Usually, for simplicity, we start with the sequential version (in our case it will be a wordcount algorithm) and then we mix in a bit of parallelism.
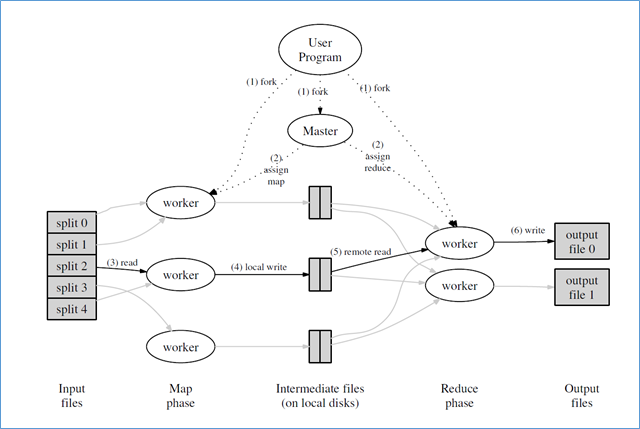
Execution in the environment of MapReduce from the article "MapReduce: Simplified Data Processing on Large Clusters", OSDI-2004
Recall the essence of the wordcount problem: we have a set of texts (for example, all the volumes of "War and Peace") and you need to count the number of words in the entire array. This simple example was used in the original Google article about MapReduce, so each following person telling about MapReduce uses the same example. Consider this "HelloWorld!" parallel execution.
So, the sequential implementation of WordCount (but using MapReduce interfaces introduced earlier) will contain all the same parts as the parallel one. And, for example, the mapper would look something like this:
Class MR.Sample.WordCount.Mapper Extends (%RegisteredObject, MR.Base.Mapper) { /// read strings from MR.Base.Iterator and count words Method Map(MapInput As MR.Base.Iterator, MapOutput As MR.Base.Emitter) { while 'MapInput.IsAtEnd() { #dim line As %String = MapInput.GetNext() #dim pattern As %Regex.Matcher = ##class(%Regex.Matcher).%New("[^\s]+") set pattern.Text = line while pattern.Locate() { #dim word As %String = pattern.Group do MapOutput.Emit(word) } } } } The Map routine receives the “input stream” via the MapInput parameter, and emittit data to the output MapOutput. The algorithm is obvious here - if there is still data in the input stream (ie, NOT MapInput.IsAtEnd () ), then it will read the following “string” via MapInput.GetNext (), break the string into words using% Regex.Matcher (see A good introductory article about using regular expressions in Caché on the Using Regular Expressions in Caché community portal) and each highlighted word is sent to the output emitter.
In the classic MapReduce interface, we always emit a “,” in this case, we made a simplification for the “, 1” case using a form with 1 argument. The explanation is given in the previous part.
The reducer procedure is even simpler:
Class MR.Sample.WordCount.Adder Extends (%RegisteredObject, MR.Base.Reducer) { Method Reduce(ReduceInput As MR.Base.Iterator, ReduceOutput As MR.Base.Emitter) { #dim result As %Numeric = 0 while 'ReduceInput.IsAtEnd() { #dim value As %String = ReduceInput.GetNext() ; get <key,value> in $listbuild format #dim word As %String = $li(value,1) #dim count As %Integer = +$li(value,2) set result = result + count } do ReduceOutput.Emit("Count", result) } } Until the end of the stream ( 'ReduceInput.IsAtEnd() ) is met, it continues to consume data from the ReduceInput stream, and at each iteration the key-value pair is $listbuild<> from the binary list format $listbuild<> (i.e., in the form $lb(word,count) ).
This function aggregates the number of words into the result variable and emits its total value and the next stage of the pipeline through the ReduceOutput stream.
So, we showed the mapper and reducer, the turn has come to show the main, managing part of the program. Without risking immediately to rest against the complexity of parallelism, we go with the sequential version of the algorithm, albeit using the idiom and interfaces using MapReduce. Yes, in the sequential mode, all these push-ups with the conveyor do not make much sense, but ... simplification is necessary for pedagogical purposes.
/// , - "map-reduce". /Class MR.Sample.WordCount.App Extends %RegisteredObject { ClassMethod MapReduce() [ ProcedureBlock = 0 ] { new //kill ^mtemp.Map,^mtemp.Reduce #dim infraPipe As MR.Sample.GlobalPipe = ##class(MR.Sample.GlobalPipe).%New($name(^mtemp.Map($J))) for i=1:1 { #dim fileName As %String = $piece($Text(DATA+i),";",3) quit:fileName="" // map #dim inputFile As MR.Input.FileLines = ##class(MR.Input.FileLines).%New(FileName) #dim mapper As MR.Sample.WordCount.Mapper = ##class(MR.Sample.WordCount.Mapper).%New() do mapper.Map(inputFile, infraPipe) // reduce #dim outPipe As MR.Base.Emitter = ##class(MR.Emitter.Sorted).%New($name(^mtemp.Reduce($J))) #dim reducer As MR.Sample.WordCount.Adder = ##class(MR.Sample.WordCount.Adder).%New() while 'infraPipe.IsAtEnd() { do reducer.Reduce(infraPipe, outPipe) } do outPipe.Dump() } quit DATA ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol1.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol2.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol3.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol4.txt ;; } } Let's try to explain this code line by line:
In the usual case, we do not recommend this, but in this case it is necessary: we turn off the procedural blocks ProcedureBlock = 0 and return to the old semantics with manual control of the contents of the symbol table with local variables. We need this to embed the DATA block containing the input data (in this case, the path to the input files), which we will access via the
$TEXTfunction. In this case, we are using 4 volumes of “War and Peace” by Leo Tolstoy;We will use for the intermediate storage of data between the stages of the pipeline globals of the form
^mtemp.Map($J)and^mtemp.Reduce($J). By magic, the globals of the form^mtemp*and^CacheTemp*automatically displayed in the CACHETEMP time base and will not be logged (as far as possible) in memory. We will treat them as "in-memory" globals.- The intraPipe intermediate channel is an instance of
MR.Sample.GlobalPipe, which in our case is just a synonym for the classMR.EmitterSorted, and as we described in the previous section, is automatically cleared at the end of the program.
Class MR.Sample.GlobalPipe Extends (%RegisteredObject, MR.Emitter.Sorted) { } We go through the lines
$TEXT(DATA+i), pull out the third argument of the string, separated by ";". If the result is non-empty, then we use this value as the name of the input file.- The input mapper iterator (display object) will be an instance of MR.Input.FileLines, which we have not yet shown ...
Class MR.Input.FileLines Extends (%RegisteredObject, MR.Base.Iterator) { Property File As %Stream.FileCharacter; Method %OnNew(FileName As %String) As %Status { set ..File = ##class(%Stream.FileCharacter).%New() #dim sc As %Status = ..File.LinkToFile(FileName) quit sc } Method GetNext() As %String { if $isobject(..File) && '..File.AtEnd { quit ..File.ReadLine() } quit "" } Method IsAtEnd() As %Boolean { quit '$isobject(..File) || ..File.AtEnd } } Let's go back to the MR.Sample.WordCount.App application:
The mapper object will be an instance of the already known
MR.Sample.WordCount.Mapper(see above). An instance is created separately for each file being processed.In the loop, we sequentially call the MapMapper function, passing an instance of the input stream working with the open file. In this particular case, the mapping stage is linearized in a sequential loop. Which is not very typical for MapReduce but is needed as a simplified exercise.
At the convolution stage, we get: the emitter output object (
outPipe) as an instance ofMR.Emitter.Sorted, which points to^mtemp.Reduce($J). I remind you that the specificity ofMR.Emitter.Sortedwill be the use of the B * -Tree implementation in the Caché engine for various optimizations. Keys-values are stored in persistent storage in a naturally sorted way, and therefore implementations of convolution with autoincrement of output values become possible.The convolution object is an instance of the
MR.Sample.WordCount.Adderdescribed above.- For each open file, and on the same loop iteration, we call
reducer.Reduce, passing there both the intermediate streaminfraPipeand the output stream.
It seems to be all the parts in the collection - let's see how it all works.
DEVLATEST:MAPREDUCE:23:53:27:.000203>do ##class(MR.Sample.WordCount.App).MapReduce() ^mtemp.Reduce(3276,"Count")=114830 ^mtemp.Reduce(3276,"Count")=123232 ^mtemp.Reduce(3276,"Count")=130276 ^mtemp.Reduce(3276,"Count")=109344 Here we see the calculated number of words in each volume of the book, which is displayed at the end of each iteration of the cycle. This is all good, but there are 2 questions that we have not received an answer:
- What is the total number of words in all volumes?
- And are we sure that the given numbers are correct? Which, by the way, is not the initial stage of writing programs is more important.
Let's start with the answer to the second question, with verifying the result - check it out simply by running the Linux / Unix / Cygwin wc utility on the same data itself:
Timur@TimurYoga2P /cygdrive/c/Users/Timur/Documents/mapreduce/data $ wc -w war*.txt 114830 war_and_peace_vol1.txt 123232 war_and_peace_vol2.txt 130276 war_and_peace_vol3.txt 109344 war_and_peace_vol4.txt 477682 total We see that the calculated number of words for each volume was correct, t.ch. let's turn to the calculation of the final, aggregate values.
The modified version - with the calculation of the total amount
To calculate the final amount, we need to make 2 simple changes to the program code shown above:
You need to apply the method of refactoring "Extract Method" on the part of the code mapper. In the future, we will need this part of the code separately, in the form of a class method, which, as a result, will simplify further modifications with parallelization or even remote code execution.
- Also, we need to take out the instantiation of the reducer objects and call its function Reduce from the cycle outside. The purpose of this modification is not to delete the intermediate channel with data at the end of each iteration, and continue to accumulate data between iterations, to show the total amount after the cycle. The aggregate amount will be calculated automatically, since we apply the auto-increment option.
In all other cases, the two cited examples behave identically - both use temporary globals ^mtemp.Map($J) and ^mtemp.Reduce($J) as intermediate and final storage at the display and convolution stages.
Class MR.Sample.WordCount.AppSum Extends %RegisteredObject { ClassMethod Map(FileName As %String, infraPipe As MR.Sample.GlobalPipe) { #dim inputFile As MR.Input.FileLines = ##class(MR.Input.FileLines).%New(FileName) #dim mapper As MR.Sample.WordCount.Mapper = ##class(MR.Sample.WordCount.Mapper).%New() do mapper.Map(inputFile, infraPipe) } ClassMethod MapReduce() [ ProcedureBlock = 0 ] { new #dim infraPipe As MR.Sample.GlobalPipe = ##class(MR.Sample.GlobalPipe).%New($name(^mtemp.Map($J))) #dim outPipe As MR.Base.Emitter = ##class(MR.Emitter.Sorted).%New($name(^mtemp.Reduce($J))) #dim reducer As MR.Sample.WordCount.Adder = ##class(MR.Sample.WordCount.Adder).%New() for i=1:1 { #dim fileName As %String = $piece($Text(DATA+i),";",3) quit:fileName="" do ..Map(fileName, infraPipe) //do infraPipe.Dump() } while 'infraPipe.IsAtEnd() { do reducer.Reduce(infraPipe, outPipe) } do outPipe.Dump() quit DATA ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol1.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol2.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol3.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol4.txt ;; } } Parallel implementation
Let's immediately admit to ourselves - such push-ups with MapReduce interfaces when creating a simple algorithm for word counting were not the simplest, most obvious and natural approach in developing such a trivial program. But the potential buns that we can get here still outweigh all the initial problems and the extra pain. With reasonable concurrency planning and using appropriate algorithms, we can get scaling that is difficult to obtain on sequential algorithms. For example, in this case, on a simple low-power Haswell ULT laptop on which this article is written, the sequential algorithm worked out in 4.5 seconds, while the parallel version was completed in 2.6 seconds.
The difference is not so dramatic, but significant enough, especially considering the small input set and only two cores on the laptop.
Let's return to the code - at the previous stage, at the mapping stage, we separated the function into a separate class method that takes two arguments (the name of the input file and the name of the output global). We have allocated this code into a separate function with one simple goal - to facilitate the creation of a parallel version. Such a parallel version will use the worker mechanism in Caché ObjectScript ($ system.WorkMgr). Below, we convert the serial version created in the previous step into parallel by calling the handler programs (workers) launched with the selected class method.
/// #2 , Class MR.Sample.WordCount.AppWorkers Extends %RegisteredObject { ClassMethod Map(FileName As %String, InfraPipeName As %String) As %Status { #dim inputFile As MR.Input.FileLines = ##class(MR.Input.FileLines).%New(FileName) #dim mapper As MR.Sample.WordCount.Mapper = ##class(MR.Sample.WordCount.Mapper).%New() #dim infraPipe As MR.Sample.GlobalPipeClone = ##class(MR.Sample.GlobalPipeClone).%New(InfraPipeName) do mapper.Map(inputFile, infraPipe) quit $$$OK } ClassMethod MapReduce() [ ProcedureBlock = 0 ] { new #dim infraPipe As MR.Sample.GlobalPipe = ##class(MR.Sample.GlobalPipe).%New($name(^mtemp.Map($J))) #dim outPipe As MR.Base.Emitter = ##class(MR.Emitter.Sorted).%New($name(^mtemp.Reduce($J))) #dim reducer As MR.Sample.WordCount.Adder = ##class(MR.Sample.WordCount.Adder).%New() #dim sc As %Status = $$$OK // do $system.WorkMgr.StopWorkers() #dim queue As %SYSTEM.WorkMgr = $system.WorkMgr.Initialize("/multicompile=1", .sc) quit:$$$ISERR(sc) for i=1:1 { #dim fileName As %String = $piece($Text(DATA+i),";",3) quit:fileName="" //do ..Map(fileName, infraPipe) set sc = queue.Queue("##class(MR.Sample.WordCount.AppWorkers).Map", fileName, infraPipe.GlobalName) quit:$$$ISERR(sc) } set sc = queue.WaitForComplete() quit:$$$ISERR(sc) while 'infraPipe.IsAtEnd() { do reducer.Reduce(infraPipe, outPipe) } do outPipe.Dump() quit DATA ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol1.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol2.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol3.txt ;;C:\Users\Timur\Documents\mapreduce\data\war_and_peace_vol4.txt ;; } Previously, the example was called AppSum, the New example is called AppWorkers, and the difference between them is very small, but important - we call the display procedure in a separate thread (process) handler using the $system.WorkMgr.Queue API. This API can call a simple subroutine, or a class method, but (by natural reason) cannot call object methods, since there is no mechanism for transferring an object to an external process.
When you call a parallel handler through this API, additional restrictions are imposed on the types of values to be passed:
- We cannot pass values by reference and, as a result, cannot return the modified values of such arguments;
- Moreover, we can only transmit simple scalar values (numbers and strings), but not objects.
But here, dear Houston, we have a problem . In the previous example, the MR.Sample.WordCount.AppSum::Map method received as the 2nd argument an instance of the MR.Sample.GlobalPipe class. But we cannot transfer objects between processes (and a worker is a separate process from the process pool). And in this case, we need to come up with a simple "serialization" / "deserialization" scheme of the object into literal values, so that this can be passed to the parallel handler via the $system.WorkMgr.Queue API.
In the case ofGlobalPipe“simple serialization method” is really simple. If we transfer the name of the intermediate global, then this is enough for an adequate transfer of the state of our object. That is why the second argument of theMR.SampleWordCount.AppWorkers::Mapmethod is a string with the name of the global, and not an object.
We recommend reading the documentation for parallel handlers here , but for the future, remember that if you want to use parallel handlers (in the maximum amount that is allowed with your hardware and license), then when initializing handlers you should pass a parameter with a strange name " /multicompile=1 " . [The strange name is explained by the fact that this functionality was added for parallel compilation in the Caché ObjectScript class translator. Since then, this modifier has been used outside the translator code.]
As soon as we have planned the execution of the method through $ system.WorkMgr.Queue , we can run all the planned routines and wait for them to complete through $ system.WorkMgr.WaitForComplete .
All parallel processors will use the same intermediate global infraPipe to transfer data between pipeline stages, but you should not expect collisions with data. The underlying data engine will handle them correctly. Recall that the Caché architecture is initially multiprocessing , with many scalable synchronization mechanisms between processes working with the same data. Additionally, we note that our simplified example with calculating the total number of words in all volumes performs a reducer (reducer) in one thread, which also simplifies the code and saves us some headaches.
Thus, at the moment we managed to talk about the general terms of the MapReduce algorithms, created the basic MapReduce interfaces when implemented in the context of the Caché ObjectScript environment, and created a simple word counting example in the same environment. In the next article, we will show other idioms used in our implementation, using the second classic example from WikiPedia - AgeAverage. It's only the beginning!
')
Source: https://habr.com/ru/post/312338/
All Articles