Feedback on Growing Object-Oriented Software, Guided by Tests
This article is a review of Growing Object-Oriented Software, Guided by Tests (GOOS for short). In it, I will show how you can implement a sample project from a book without using mocks.
The purpose of the article is to show how the use of mocks can harm the code and how much simpler the same code becomes if you get rid of mocks. The secondary goal is to single out the advice from the book that personally seems reasonable to me and those that, conversely, do more harm than good. The book is quite a lot of those and others.
English version: link .
Let's start with the good stuff. Most of them are in the first two sections of the book.
')
The authors define the purpose of automatic testing as the creation of a safety net (safety net), which helps to detect regressions in the code. In my opinion, this is indeed the most important advantage that the availability of tests gives us. Safety net helps to achieve confidence that the code works as expected, which, in turn, allows you to quickly add new features and refactor existing ones. A team becomes much more productive if it is confident that changes made to the code do not lead to breakdowns.
The book also describes the importance of setting up the deployment environment in its early stages. This should be the first priority of any new project, since allows you to identify potential integration errors in the early stages, before a significant amount of code is written.
To do this, the authors propose to start with the construction of a “walking skeleton” - the simplest version of the application, which at the same time in its implementation affects all layers of the application. For example, if this is a web application, the skeleton may show a simple HTML page that requests a string from a real database. This skeleton should be covered by the end-to-end test, from which the test suite will begin.
This technique also allows you to focus on deploying the deployment pipeline without paying much attention to the application architecture.
The book offers a two-level TDD cycle:

In other words, start each new functionality with an end-to-end test and work your way towards successfully passing this test through the usual red-green-refactor cycle.
End-to-end here appear more as a measure of progress. Some of these tests may be in the "red" state, because The feature is not yet implemented, this is normal. Unit tests at the same time act as a safety net and should be green all the time.
It is important that the end-to-end tests affect as many external systems as possible, this will help to identify integration errors. At the same time, the authors recognize that some external systems will have to be replaced with plugs in any case. The question of what to include in end-to-end tests should be decided for each project separately, there is no universal answer.
The book proposes to extend the classic 3-step TDD cycle, adding a fourth step to it: make the error message more understandable.
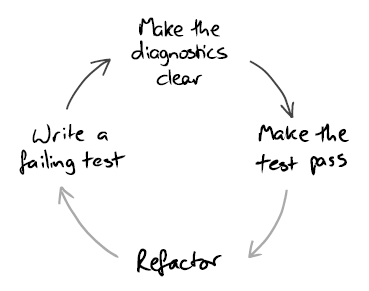
This will help to ensure that if the test fails, you can understand that it’s not so easy to look at the error message without starting the debugger.
The authors recommend developing the application in a “vertical way” (end to end) from the very beginning. Do not spend too much time polishing the architecture, start with some kind of request coming from the outside (for example, from the UI) and process this request completely, including all application layers (UI, logic, DB) with the minimum possible amount of code. In other words, do not build the architecture in advance.
Another great tip is to test behavior, not methods. Very often this is not the same thing, because a unit of behavior can affect several methods or even classes.
Another interesting point is the recommendation to make the system under test (SUT) context-independent:
"No object should have an idea about the system in which it is running."
This is essentially the concept of domain model isolation. Domain classes should not be dependent on external systems. Ideally, you should be able to completely snatch them from the current environment and run without any additional effort. In addition to the obvious advantages associated with better code testability, this method allows you to simplify your code, because You are able to focus on the domain without paying attention to aspects that are not related to your domain (database, network, etc.).
The book is the original source of the fairly well-known rule of “Replace only the types that you own” (“Only mock types that you own”). In other words, use mocks only for types that you wrote yourself. Otherwise, you cannot guarantee that your mocks correctly model the behavior of these types.
Interestingly, during the book, the authors themselves break this rule a couple of times and use mocks for types from external libraries. Those types are pretty simple, so there really isn’t much point in creating your own wrappers over them.
Despite a lot of valuable advice, the book also provides potentially harmful recommendations, and there are quite a few such recommendations.
The authors are advocates of a mockist approach to unit testing (for more on differences here: mockist vs classicist ) even when it comes to communication between individual objects within a domain model. In my opinion, this is the greatest shortcoming of the book, all the others are a consequence of it.
To substantiate their approach, the authors give the definition of OOP, given by Alan Kay:
“The main idea is messaging. The key to creating a good and expandable application lies in the design of how its various modules communicate with each other, and not how they are built inside. ”
They then conclude that the interactions between objects are what you should focus on primarily when unit testing. By this logic, communication between classes is what ultimately makes the system what it is.
There are two problems with this view. First, the definition of OOP, given by Alan Kay, is inappropriate here. It is rather vague to draw such far-reaching conclusions based on it and has little to do with modern OOP languages.
Here is another famous quote from him:
"I came up with the phrase" object-oriented ", and I did not mean C ++."
And of course, you can safely replace here C ++ with C # or Java.
The second problem with this approach is that the individual classes are too small (fine-grained) to be treated as independent communicators. The way they communicate with each other often changes and has little to do with the final result, which we should ultimately check in tests. The communication pattern between objects is an implementation detail and becomes part of the API only when communication crosses the system’s boundaries: when your domain model begins to communicate with external services. Unfortunately, the book does not make these differences.
The disadvantages of the approach suggested by the book become obvious if you look at the project code from Chapter 3. The focus on communication between the objects not only leads to fragile tests because of their sticking to implementation details, but also leads to an over-complicated design with cyclic dependencies, header interfaces and an excessive number of layers of abstractions.
In the rest of the article, I'm going to show how a project from a book can be modified and what effect it has on unit tests.
The original codebase is written in Java, the modified version is in C #. I rewrote the project completely, including unit tests, end-to-end tests, UI, and an emulator for the XMPP server.
Before plunging into code, let's look at the subject area. Project from the book - Auction Sniper. Bot that participates in auctions on behalf of the user. Here is its interface:
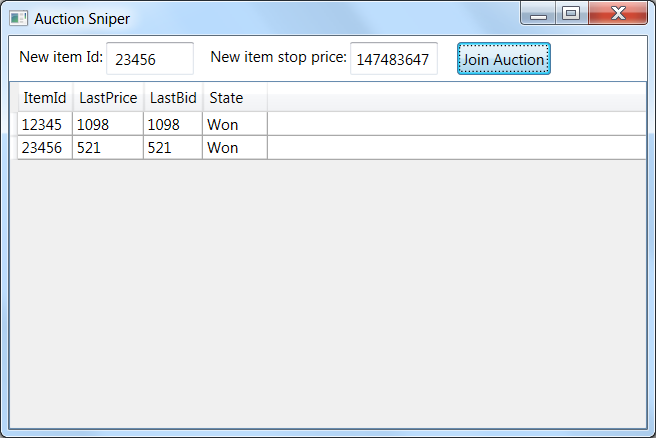
Item Id - identifier of the item that is currently being sold. Stop Price - the maximum price you are willing to pay for it as a user. Last Price - the last price you or other bidders offered for this item. Last Bid is the last price you made. State - the state of the auction. In the screenshot above, you can see that the application has won both subjects, which is why both prices are the same in both cases: they came from your application.
Each line in the list represents a separate agent that listens to messages coming from the server and responds to them by sending commands in response. Business rules can be summarized as follows:
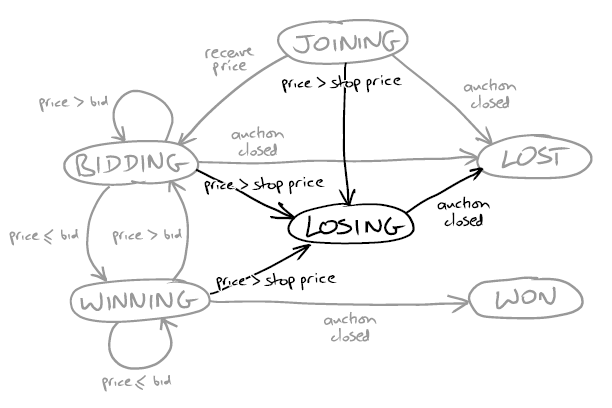
Each agent (they are also called Auction Sniper) starts from the top of the picture, in the Joining state. He then waits until the server sends an event with the current state of the auction — the last price, the user name of the bidder and the minimum price increase required to outbid the last bid. This type of event is called Price.
If the required bid is less than the stop price that the user has set for the item, the application sends its bid (bid) and enters the Bidding state. If a new Price event shows that our bid is in the lead, Sniper does nothing and goes into the Winning state. Finally, the second event sent by the server is the Close event. When it comes, the application looks in what status it is now for this item. If in Winning, then goes to Won, all other statuses go to Lost.
That is, in fact, we have a bot that sends commands to the server and supports the internal state machine.
Let's look at the architecture of the application proposed by the book. Here is her diagram (click to enlarge):
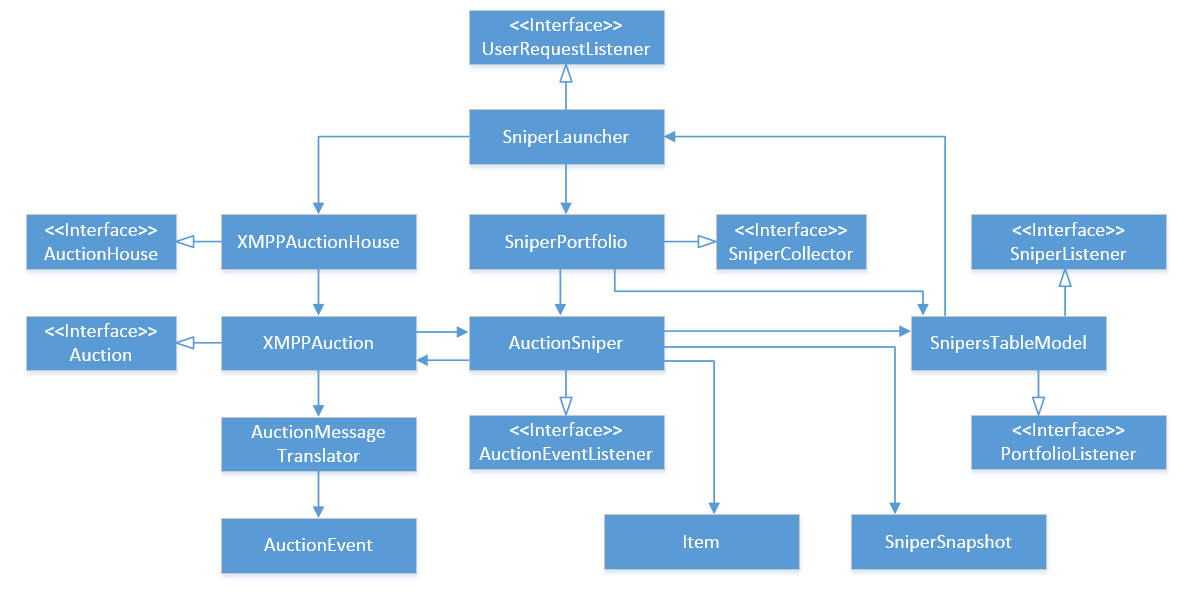
If you think that it is over-complicated for such a simple task, it is because it is. So, what problems do we see here?
The very first remark, striking, is a large number of header interfaces. This term refers to an interface that completely copies a single class that implements this interface. For example, XMPPAuction is one to one correlated with the Auction interface, AcutionSniper with the AuctionEventListener, and so on. Interfaces with a single implementation are not an abstraction and are considered to be “ design smell ”.
Below is the same diagram without interfaces. I removed them to make the structure of the diagram more understandable.
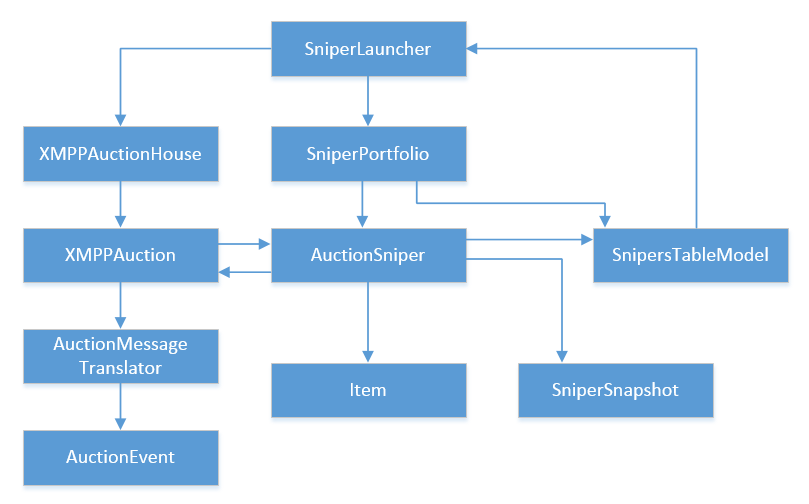
The second problem here is cyclical dependencies. The most obvious of these is between XMPPAuction and AuctionSniper, but it is not the only one. For example, AuctionSniper refers to SnipersTableModel, which in turn refers to SniperLauncher, and so on until the link comes back to AuctionSniper.
Cyclic dependencies in the code load our brains when we try to read and understand this code. The reason is that with such dependencies you do not know where to start. To understand the purpose of one of the classes, you need to put in your head a whole graph of classes, cyclically connected with each other.
Even after I completely rewrote the project code, I often had to refer to diagrams in order to understand how different classes and interfaces relate to each other. We, people, understand hierarchies well, we often have difficulties with cyclical graphs. Scott Wlaschin wrote a great article on this topic: Cyclic dependencies are evil .
The third problem is the lack of isolation of the domain model. Here’s what the architecture looks like in terms of DDD:

Classes in the middle make up a domain model. At the same time, they communicate with the auction server (left) and with the UI (right). For example, SniperLauncher communicates with XMPPAuctionHouse, AuctionSniper - with XMPPAcution and SnipersTableModel.
Of course, they do this using interfaces, not real classes, but, again, adding interfaces to the header model does not mean that you automatically begin to follow Dependency Inversion principles.
Ideally, the domain model should be self-sufficient, the classes inside it should not talk to classes from the outside world, neither using specific implementations, nor their interfaces. Proper isolation means that a domain model can be tested using a functional approach without involving mocks.
All these shortcomings are a common consequence of the situation where developers focus on testing the interactions between the classes within the domain model, rather than their public API. This approach leads to the creation of header interfaces, since otherwise, it becomes impossible to “lock in” the neighboring classes, to a large number of cyclic dependencies, and the domain classes that communicate directly with the outside world.
Let's now take a look at the unit tests themselves. Here is an example of one of them:
First, this test focuses on communication between classes, which leads to the need to create and maintain a significant amount of code associated with the creation of mocks, but this is not the most important thing here. The main disadvantage here is that this test contains information about the implementation details of the test object. The when clause here means that the test knows about the internal state of the system and simulates this state in order to test it.
Here is another example:
This code is a clear example of a leak of knowledge about system implementation details. The test in this example implements a full-fledged state machine to verify that the class under test calls the methods of its neighbors in this particular order (the last three lines):
Because of the high coherence with the internals of the system under test, tests like this are very fragile. Any non-trivial refactoring will lead to their fall, regardless of whether this refactoring is broken or not. This in turn significantly reduces their value, because tests often give false positives and because of this they are no longer perceived as part of a reliable safety net.
The complete project source code from the book can be found here: link .
All of the above are rather serious statements, and obviously I need to back them up with an alternative solution. The full source code for this alternative solution can be found here .
In order to understand how a project can be implemented with proper isolation of the domain domain, without cyclic dependencies and without an excessive amount of unnecessary abstractions, let's look at the functions of the application. It receives events from the server and responds to them with some commands, maintaining an internal state machine:

And that's essentially all. In reality, this is almost an ideal functional (functional programming) architecture, and nothing prevents us from implementing it as such.
Here’s how the alternative solution looks like:

Let's look at some important differences. First, the domain model is completely isolated from the outside world. The classes in it do not speak directly with the view model or with the XMPP Server, all links are directed to the domain classes, and not vice versa.
All communication with the outside world, be it a server or a UI, is given to the Application Services layer, the role of which in our case is performed by AuctionSniperViewModel. It acts as a shield that protects the domain model from the unwanted influence of the outside world: it filters incoming events and interprets outgoing commands.
Secondly, the domain model does not contain cyclic dependencies. The structure of classes here is tree-like, which means that a potential new developer has a clear place from which he can start reading this code. He can start from casting the tree and move up the tree step by step, without having to place the entire class diagram in his head at a time. The code from this particular project is pretty simple, of course, so I'm sure you would have no problem reading it even if there are circular dependencies. However, in more complex scenarios, a clear tree structure is a big plus in terms of simplicity and readability.
By the way, the well-known DDD pattern - Aggregate - is aimed at solving this particular problem. By grouping several entities into a single unit, we reduce the number of links in the domain model and thus make the code easier.
The third important point here is that the alternative version contains no interfaces. This is one of the advantages of having a fully isolated domain model: you just do not need to add interfaces to the code if they do not represent a real abstraction. In this example, we have no such abstractions.
Classes in the new implementation are clearly divided according to their purpose. They either contain business knowledge - these are classes within the domain model, - or they communicate with the outside world - classes outside the domain model, - but never both. This separation of duties allows us to focus on one problem at a time: we either think about domain logic, or decide how to respond to incentives from the UI and the auction server.
Again, this simplifies the code, and therefore makes it more supported. Here’s what the most important part of the Application Services layer looks like:
Here we get the string from the auction server, transform it into event (validation is included in this step), pass it to the sniper and if the resultant command is not None, send it back to the server. As you can see, the lack of business logic makes the Application Services layer trivial.
Another advantage of an isolated domain model is the ability to test it using a functional approach. We can look at each part of the behavior in isolation from each other and check the end result it generates without paying attention to how this result was achieved.
For example, the following test checks how the Sniper, who has just joined the auction, responds to receiving the Close event:
It checks that the resultant command is empty, which means the sniper is not taking any action, and that the state becomes Lost after that.
Here is another example:
This test checks that the sniper sends a request when the current price and the minimum increment is less than the set price limit.
The only place where mocks can potentially be justified is when testing the Application Services layer, which communicates with external systems. But this part is covered with end-to-end tests, so in this particular case there is no need for this. By the way, the end-to-end tests in the book are great, I did not find anything that could be changed or improved in them.
The source code for the alternative implementation can be found here .
Focusing on communication between individual classes leads to fragile tests, as well as damage to the project architecture itself.
To avoid these disadvantages:
I just got a new course on Pluralsight on pragmatic unit testing. In it, I tried to talk about the practice of building unit tests, leading to the best result with the least effort. The guidelines from the article above became part of this course and are discussed in detail, with a multitude of examples.
I also have several dozen trial codes that give unlimited access to Pluralsight for a period of 30 days (to the entire library, not just my course). If someone needs - write in a personal, happy to share.
Course link: Building a Pragmatic Unit Test Suite .
The purpose of the article is to show how the use of mocks can harm the code and how much simpler the same code becomes if you get rid of mocks. The secondary goal is to single out the advice from the book that personally seems reasonable to me and those that, conversely, do more harm than good. The book is quite a lot of those and others.
English version: link .
Good parts
Let's start with the good stuff. Most of them are in the first two sections of the book.
')
The authors define the purpose of automatic testing as the creation of a safety net (safety net), which helps to detect regressions in the code. In my opinion, this is indeed the most important advantage that the availability of tests gives us. Safety net helps to achieve confidence that the code works as expected, which, in turn, allows you to quickly add new features and refactor existing ones. A team becomes much more productive if it is confident that changes made to the code do not lead to breakdowns.
The book also describes the importance of setting up the deployment environment in its early stages. This should be the first priority of any new project, since allows you to identify potential integration errors in the early stages, before a significant amount of code is written.
To do this, the authors propose to start with the construction of a “walking skeleton” - the simplest version of the application, which at the same time in its implementation affects all layers of the application. For example, if this is a web application, the skeleton may show a simple HTML page that requests a string from a real database. This skeleton should be covered by the end-to-end test, from which the test suite will begin.
This technique also allows you to focus on deploying the deployment pipeline without paying much attention to the application architecture.
The book offers a two-level TDD cycle:
In other words, start each new functionality with an end-to-end test and work your way towards successfully passing this test through the usual red-green-refactor cycle.
End-to-end here appear more as a measure of progress. Some of these tests may be in the "red" state, because The feature is not yet implemented, this is normal. Unit tests at the same time act as a safety net and should be green all the time.
It is important that the end-to-end tests affect as many external systems as possible, this will help to identify integration errors. At the same time, the authors recognize that some external systems will have to be replaced with plugs in any case. The question of what to include in end-to-end tests should be decided for each project separately, there is no universal answer.
The book proposes to extend the classic 3-step TDD cycle, adding a fourth step to it: make the error message more understandable.
This will help to ensure that if the test fails, you can understand that it’s not so easy to look at the error message without starting the debugger.
The authors recommend developing the application in a “vertical way” (end to end) from the very beginning. Do not spend too much time polishing the architecture, start with some kind of request coming from the outside (for example, from the UI) and process this request completely, including all application layers (UI, logic, DB) with the minimum possible amount of code. In other words, do not build the architecture in advance.
Another great tip is to test behavior, not methods. Very often this is not the same thing, because a unit of behavior can affect several methods or even classes.
Another interesting point is the recommendation to make the system under test (SUT) context-independent:
"No object should have an idea about the system in which it is running."
This is essentially the concept of domain model isolation. Domain classes should not be dependent on external systems. Ideally, you should be able to completely snatch them from the current environment and run without any additional effort. In addition to the obvious advantages associated with better code testability, this method allows you to simplify your code, because You are able to focus on the domain without paying attention to aspects that are not related to your domain (database, network, etc.).
The book is the original source of the fairly well-known rule of “Replace only the types that you own” (“Only mock types that you own”). In other words, use mocks only for types that you wrote yourself. Otherwise, you cannot guarantee that your mocks correctly model the behavior of these types.
Interestingly, during the book, the authors themselves break this rule a couple of times and use mocks for types from external libraries. Those types are pretty simple, so there really isn’t much point in creating your own wrappers over them.
Bad parts
Despite a lot of valuable advice, the book also provides potentially harmful recommendations, and there are quite a few such recommendations.
The authors are advocates of a mockist approach to unit testing (for more on differences here: mockist vs classicist ) even when it comes to communication between individual objects within a domain model. In my opinion, this is the greatest shortcoming of the book, all the others are a consequence of it.
To substantiate their approach, the authors give the definition of OOP, given by Alan Kay:
“The main idea is messaging. The key to creating a good and expandable application lies in the design of how its various modules communicate with each other, and not how they are built inside. ”
They then conclude that the interactions between objects are what you should focus on primarily when unit testing. By this logic, communication between classes is what ultimately makes the system what it is.
There are two problems with this view. First, the definition of OOP, given by Alan Kay, is inappropriate here. It is rather vague to draw such far-reaching conclusions based on it and has little to do with modern OOP languages.
Here is another famous quote from him:
"I came up with the phrase" object-oriented ", and I did not mean C ++."
And of course, you can safely replace here C ++ with C # or Java.
The second problem with this approach is that the individual classes are too small (fine-grained) to be treated as independent communicators. The way they communicate with each other often changes and has little to do with the final result, which we should ultimately check in tests. The communication pattern between objects is an implementation detail and becomes part of the API only when communication crosses the system’s boundaries: when your domain model begins to communicate with external services. Unfortunately, the book does not make these differences.
The disadvantages of the approach suggested by the book become obvious if you look at the project code from Chapter 3. The focus on communication between the objects not only leads to fragile tests because of their sticking to implementation details, but also leads to an over-complicated design with cyclic dependencies, header interfaces and an excessive number of layers of abstractions.
In the rest of the article, I'm going to show how a project from a book can be modified and what effect it has on unit tests.
The original codebase is written in Java, the modified version is in C #. I rewrote the project completely, including unit tests, end-to-end tests, UI, and an emulator for the XMPP server.
Project
Before plunging into code, let's look at the subject area. Project from the book - Auction Sniper. Bot that participates in auctions on behalf of the user. Here is its interface:
Item Id - identifier of the item that is currently being sold. Stop Price - the maximum price you are willing to pay for it as a user. Last Price - the last price you or other bidders offered for this item. Last Bid is the last price you made. State - the state of the auction. In the screenshot above, you can see that the application has won both subjects, which is why both prices are the same in both cases: they came from your application.
Each line in the list represents a separate agent that listens to messages coming from the server and responds to them by sending commands in response. Business rules can be summarized as follows:
Each agent (they are also called Auction Sniper) starts from the top of the picture, in the Joining state. He then waits until the server sends an event with the current state of the auction — the last price, the user name of the bidder and the minimum price increase required to outbid the last bid. This type of event is called Price.
If the required bid is less than the stop price that the user has set for the item, the application sends its bid (bid) and enters the Bidding state. If a new Price event shows that our bid is in the lead, Sniper does nothing and goes into the Winning state. Finally, the second event sent by the server is the Close event. When it comes, the application looks in what status it is now for this item. If in Winning, then goes to Won, all other statuses go to Lost.
That is, in fact, we have a bot that sends commands to the server and supports the internal state machine.
Let's look at the architecture of the application proposed by the book. Here is her diagram (click to enlarge):
If you think that it is over-complicated for such a simple task, it is because it is. So, what problems do we see here?
The very first remark, striking, is a large number of header interfaces. This term refers to an interface that completely copies a single class that implements this interface. For example, XMPPAuction is one to one correlated with the Auction interface, AcutionSniper with the AuctionEventListener, and so on. Interfaces with a single implementation are not an abstraction and are considered to be “ design smell ”.
Below is the same diagram without interfaces. I removed them to make the structure of the diagram more understandable.
The second problem here is cyclical dependencies. The most obvious of these is between XMPPAuction and AuctionSniper, but it is not the only one. For example, AuctionSniper refers to SnipersTableModel, which in turn refers to SniperLauncher, and so on until the link comes back to AuctionSniper.
Cyclic dependencies in the code load our brains when we try to read and understand this code. The reason is that with such dependencies you do not know where to start. To understand the purpose of one of the classes, you need to put in your head a whole graph of classes, cyclically connected with each other.
Even after I completely rewrote the project code, I often had to refer to diagrams in order to understand how different classes and interfaces relate to each other. We, people, understand hierarchies well, we often have difficulties with cyclical graphs. Scott Wlaschin wrote a great article on this topic: Cyclic dependencies are evil .
The third problem is the lack of isolation of the domain model. Here’s what the architecture looks like in terms of DDD:
Classes in the middle make up a domain model. At the same time, they communicate with the auction server (left) and with the UI (right). For example, SniperLauncher communicates with XMPPAuctionHouse, AuctionSniper - with XMPPAcution and SnipersTableModel.
Of course, they do this using interfaces, not real classes, but, again, adding interfaces to the header model does not mean that you automatically begin to follow Dependency Inversion principles.
Ideally, the domain model should be self-sufficient, the classes inside it should not talk to classes from the outside world, neither using specific implementations, nor their interfaces. Proper isolation means that a domain model can be tested using a functional approach without involving mocks.
All these shortcomings are a common consequence of the situation where developers focus on testing the interactions between the classes within the domain model, rather than their public API. This approach leads to the creation of header interfaces, since otherwise, it becomes impossible to “lock in” the neighboring classes, to a large number of cyclic dependencies, and the domain classes that communicate directly with the outside world.
Let's now take a look at the unit tests themselves. Here is an example of one of them:
@Test public void reportsLostIfAuctionClosesWhenBidding() { allowingSniperBidding(); ignoringAuction(); context.checking(new Expectations() {{ atLeast(1).of(sniperListener).sniperStateChanged( new SniperSnapshot(ITEM_ID, 123, 168, LOST)); when(sniperState.is(“bidding”)); }}); sniper.currentPrice(123, 45, PriceSource.FromOtherBidder); sniper.auctionClosed(); } First, this test focuses on communication between classes, which leads to the need to create and maintain a significant amount of code associated with the creation of mocks, but this is not the most important thing here. The main disadvantage here is that this test contains information about the implementation details of the test object. The when clause here means that the test knows about the internal state of the system and simulates this state in order to test it.
Here is another example:
private final Mockery context = new Mockery(); private final SniperLauncher launcher = new SniperLauncher(auctionHouse, sniperCollector); private final States auctionState = context.states(“auction state”).startsAs(“not joined”); @Test public void addsNewSniperToCollectorAndThenJoinsAuction() { final Item item = new Item(“item 123”, 456); context.checking(new Expectations() {{ allowing(auctionHouse).auctionFor(item); will(returnValue(auction)); oneOf(auction).addAuctionEventListener(with(sniperForItem(item))); when(auctionState.is(“not joined”)); oneOf(sniperCollector).addSniper(with(sniperForItem(item))); when(auctionState.is(“not joined”)); one(auction).join(); then(auctionState.is(“joined”)); }}); launcher.joinAuction(item); } This code is a clear example of a leak of knowledge about system implementation details. The test in this example implements a full-fledged state machine to verify that the class under test calls the methods of its neighbors in this particular order (the last three lines):
public class SniperLauncher implements UserRequestListener { public void joinAuction(Item item) { Auction auction = auctionHouse.auctionFor(item); AuctionSniper sniper = new AuctionSniper(item, auction); auction.addAuctionEventListener(sniper); // These collector.addSniper(sniper); // three auction.join(); // lines } } Because of the high coherence with the internals of the system under test, tests like this are very fragile. Any non-trivial refactoring will lead to their fall, regardless of whether this refactoring is broken or not. This in turn significantly reduces their value, because tests often give false positives and because of this they are no longer perceived as part of a reliable safety net.
The complete project source code from the book can be found here: link .
Alternative implementation without mocks
All of the above are rather serious statements, and obviously I need to back them up with an alternative solution. The full source code for this alternative solution can be found here .
In order to understand how a project can be implemented with proper isolation of the domain domain, without cyclic dependencies and without an excessive amount of unnecessary abstractions, let's look at the functions of the application. It receives events from the server and responds to them with some commands, maintaining an internal state machine:
And that's essentially all. In reality, this is almost an ideal functional (functional programming) architecture, and nothing prevents us from implementing it as such.
Here’s how the alternative solution looks like:
Let's look at some important differences. First, the domain model is completely isolated from the outside world. The classes in it do not speak directly with the view model or with the XMPP Server, all links are directed to the domain classes, and not vice versa.
All communication with the outside world, be it a server or a UI, is given to the Application Services layer, the role of which in our case is performed by AuctionSniperViewModel. It acts as a shield that protects the domain model from the unwanted influence of the outside world: it filters incoming events and interprets outgoing commands.
Secondly, the domain model does not contain cyclic dependencies. The structure of classes here is tree-like, which means that a potential new developer has a clear place from which he can start reading this code. He can start from casting the tree and move up the tree step by step, without having to place the entire class diagram in his head at a time. The code from this particular project is pretty simple, of course, so I'm sure you would have no problem reading it even if there are circular dependencies. However, in more complex scenarios, a clear tree structure is a big plus in terms of simplicity and readability.
By the way, the well-known DDD pattern - Aggregate - is aimed at solving this particular problem. By grouping several entities into a single unit, we reduce the number of links in the domain model and thus make the code easier.
The third important point here is that the alternative version contains no interfaces. This is one of the advantages of having a fully isolated domain model: you just do not need to add interfaces to the code if they do not represent a real abstraction. In this example, we have no such abstractions.
Classes in the new implementation are clearly divided according to their purpose. They either contain business knowledge - these are classes within the domain model, - or they communicate with the outside world - classes outside the domain model, - but never both. This separation of duties allows us to focus on one problem at a time: we either think about domain logic, or decide how to respond to incentives from the UI and the auction server.
Again, this simplifies the code, and therefore makes it more supported. Here’s what the most important part of the Application Services layer looks like:
_chat.MessageReceived += ChatMessageRecieved; private void ChatMessageRecieved(string message) { AuctionEvent ev = AuctionEvent.From(message); AuctionCommand command = _auctionSniper.Process(ev); if (command != AuctionCommand.None()) { _chat.SendMessage(command.ToString()); } } Here we get the string from the auction server, transform it into event (validation is included in this step), pass it to the sniper and if the resultant command is not None, send it back to the server. As you can see, the lack of business logic makes the Application Services layer trivial.
Tests without mokov
Another advantage of an isolated domain model is the ability to test it using a functional approach. We can look at each part of the behavior in isolation from each other and check the end result it generates without paying attention to how this result was achieved.
For example, the following test checks how the Sniper, who has just joined the auction, responds to receiving the Close event:
[Fact] public void Joining_sniper_loses_when_auction_closes() { var sniper = new AuctionSniper(“”, 200); AuctionCommand command = sniper.Process(AuctionEvent.Close()); command.ShouldEqual(AuctionCommand.None()); sniper.StateShouldBe(SniperState.Lost, 0, 0); } It checks that the resultant command is empty, which means the sniper is not taking any action, and that the state becomes Lost after that.
Here is another example:
[Fact] public void Sniper_bids_when_price_event_with_a_different_bidder_arrives() { var sniper = new AuctionSniper(“”, 200); AuctionCommand command = sniper.Process(AuctionEvent.Price(1, 2, “some bidder”)); command.ShouldEqual(AuctionCommand.Bid(3)); sniper.StateShouldBe(SniperState.Bidding, 1, 3); } This test checks that the sniper sends a request when the current price and the minimum increment is less than the set price limit.
The only place where mocks can potentially be justified is when testing the Application Services layer, which communicates with external systems. But this part is covered with end-to-end tests, so in this particular case there is no need for this. By the way, the end-to-end tests in the book are great, I did not find anything that could be changed or improved in them.
The source code for the alternative implementation can be found here .
Conclusion
Focusing on communication between individual classes leads to fragile tests, as well as damage to the project architecture itself.
To avoid these disadvantages:
- Do not create header interfaces for domain classes.
- Minimize the number of circular dependencies in the code.
- Isolate the domain model: do not allow domain classes to communicate with the outside world.
- Reduce the number of unnecessary abstractions.
- Focus on checking the status and the final result when testing a domain model, not communication between classes.
Pluralsight course
I just got a new course on Pluralsight on pragmatic unit testing. In it, I tried to talk about the practice of building unit tests, leading to the best result with the least effort. The guidelines from the article above became part of this course and are discussed in detail, with a multitude of examples.
I also have several dozen trial codes that give unlimited access to Pluralsight for a period of 30 days (to the entire library, not just my course). If someone needs - write in a personal, happy to share.
Course link: Building a Pragmatic Unit Test Suite .
Source: https://habr.com/ru/post/312248/
All Articles