When the old MapReduce is better than the new Tez

As everyone knows, the amount of data in the world is growing, it becomes more difficult to collect and process the flow of information. For this is the popular Hadoop solution with the idea of simplifying the development and debugging methods of multi-threaded applications using the MapReduce paradigm. This paradigm does not always successfully cope with its tasks, and after a while there appears a “superstructure” over Hadoop: Apache Tez with the DAG paradigm. The appearance of Tez adapts and HDFS-SQL-processor Hive. But not always the new is better than the old. In most cases, HiveOnTez is much faster than HiveOnMapReduce, but some pitfalls can greatly affect the performance of your solution. Here I want to tell you what nuances I encountered. Hope this helps you speed up ETL or another Hadoop UseCase.
MapReduce, Tez and Hive
As I said earlier, there is more and more data in the world. And for their storage and processing, they come up with more and more tricky solutions, among them Hadoop. To make the processing of data stored on HDFS easy for even an ordinary analyst, there are several SQL add-ins over Hadoop. The oldest and “simplest” of them is Hive. The essence of Hive is this: we have data in some distinct column-store format, we enter information about them in metadata, we write standard SQL with a number of restrictions, and it generates a chain of MapReduce-jobs that solve our problem. Nice, comfortable, but slow. For example, here’s a simple query:
select t1.column1, t2.column2 from table1 t1 inner join table2 t2 on t1.column1 = t2.column1 union select t3.column1, t4.column2 from table3 t3 inner join table4 t4 on t3.column1 = t4.column1 order by column1; This query spawns four jobs:
')
- table1 inner join table2;
- table3 inner join table4;
- union;
- sort.

Steps are executed sequentially, and each of them ends with writing data to HDFS. It looks quite suboptimal. For example, steps 1 and 2 could be performed in parallel. And there are also situations where it is reasonable to use the same Mapper for several steps, and then apply several Reducer types to the results of these Mappers. But the concept of MapReduce within the framework of a single job does not allow to do so. To solve this problem, Apache Tez appears fairly quickly with the concept of DAG. The essence of the DAG is that instead of a pair of Mapper-Reducer (+ epsilon) we build a non-cyclic directed graph, each vertex of which is a Mapper.Class or Reduser.Class, and the edges mean data flows / execution order. In addition to DAG, Tez provided several more bonuses: an accelerated start-up of jobs (you can send DAG-jobs via an already running Tez-Engine), the ability to keep resources in the memory of the node between steps, independently start parallelization, etc. Naturally, together with Tez came out and the corresponding add-on over Hive. With this add-on, our request will turn into a DAG-job of approximately the following structure:
- Mapper reads table1.
- Mapper reads table2 and joins it with the result of step 1.
- Mapper reads table3 and filters column1 IS NOT NULL.
- Mapper reads table4 and filters column1 IS NOT NULL.
- Reducer joins the results of steps 3 and 4.
- Reducer doing union.
- Reducer Group By and Sort.
- Collects the result.
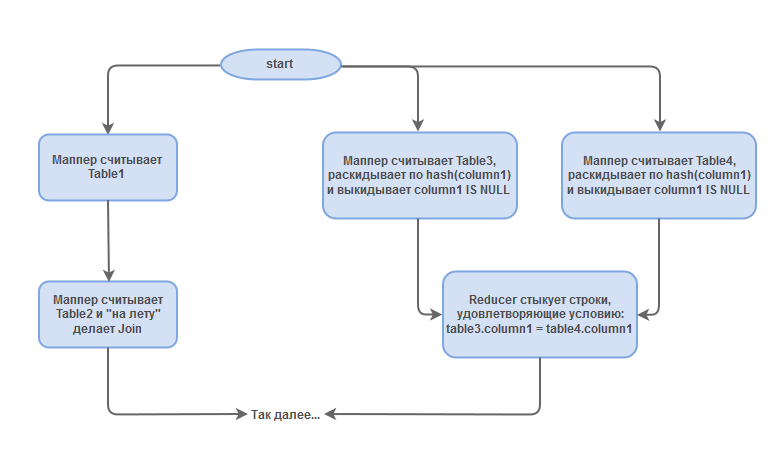
In fact, steps 1 and 2 are the first join, and 2, 3 and 4 are the second join (I specially selected tables of different sizes so that the joines were processed differently). In this case, two blocks from each other are independent and can be executed in parallel. This is very cool. Tez really gives a significant increase in the speed of processing complex requests. But sometimes Tez can be worse than MapReduce, and therefore, before being sent to production, it is worth trying a query with both
set hive.execution.engine=tez , and set hive.execution.engine=mr .So what is Tez?
All you need to know about Tez: it changes the MapReduce logic to DAG logic (directed by acyclic graph - directed acyclic graph), allowing you to perform several different processes in the same DataFlow, be it Mapper or Reducer. The main thing is that its input data is ready. You can store data locally on the nodes between steps, and sometimes just in the node's RAM, without resorting to disk operations. You can optimize the number and location of Mappers and Reducers in order to minimize data transfer over the Network, even taking into account multi-step calculations, reuse containers that have already worked in neighboring processes within the same Tez-Job, and adjust parallel execution for statistics, collected in the previous step. In addition, the engine allows the end user to create DAG tasks with the same simplicity as MapReduce, while he himself will be engaged in resources, restarts and DAG management on the cluster. Tez is very mobile, adding support for Tez does not break processes already running, and testing the new version is possible locally "on the client side" when the old version of Tez will work in all cluster tasks. Last but not least: note that Tez can run on a cluster as a service and work in the "background" mode, which allows it to send tasks for execution much faster than it happens when you start MapReduce. If you have not tried Tez and you still have doubts, then look at the speed comparison published in the HortonWorks presentation :
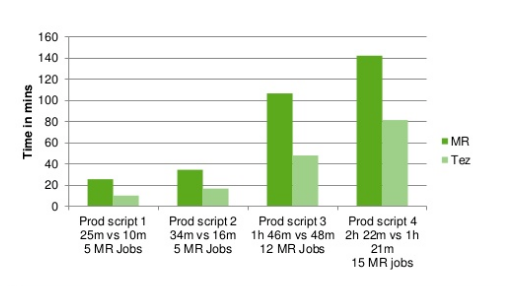
And paired with Hive:

But with all this beauty of graphics and descriptions in HiveOnTez there are problems.
Tez is less resistant to uneven data distribution than MapReduce
The first and biggest problem is the difference between creating a DAG-job and MapReduce-job. They have one principle: the number of Mappers and Reducers is calculated at the moment of starting the job. Only when a request is executed by a chain of MapReduce-jobs, does Hadoop calculate the required number of tasks based on the result of the previous steps and the collected analytics by source, and in the case of DAG-job this happens before all steps are calculated, only on the basis of analytics.
Let me explain by example. Somewhere in the middle of a query as we perform subqueries, we have two tables. According to statistics estimates, each has n lines and k unique join-key values. At the output we expect approximately n * k lines. And let's say that this quantity fits well into one container, and Tez will select one Reducer for the next step (say, sorting). And this number Reducer'ov already in the process of execution will not change regardless of anything. Now suppose that in fact these tables have a very bad skew: for one value there is n - k + 1 row, and all the rest - for one row. Thus, at the output we get n ^ 2 + k ^ 2 - 2kn - k + 2n rows. That is, (n + 2 - 2k) / k + (k - 1) / n is more than n / k twice. And already such amount one Reducer will carry out eternity. And in the case of MapReduce, having received n ^ 2 + k ^ 2 - 2kn - k + 2n at the output of this step, Hadoop will objectively evaluate its strength and produce the necessary number of Mappers and Reduceres. As a result, with MapReduce, everything will work much faster.
Dry calculations may seem far-fetched, but in reality this situation is real. And if it did not happen, then consider yourself lucky. I came across a similar effect from Tez-DAG when using the lateral view in complex queries or custom Mappers.
Features tuning Tez
Ironically, the last important feature of Tez I know that can harm is related to its strength - DAG. Most often, a cluster is not just a repository of information. It is also the system in which the data is processed, and it is important that this part of the cluster is not affected by the rest of the activity. Since nodes are a resource, usually the number of your containers is not unlimited. So, when you run a job, it is better not to clog all containers, so as not to slow down the regular processes. And then the DAG can give you a pig. DAG is required (on average in the ward) fewer containers due to their reuse, smoother loading, etc. But when there are many fast steps, containers begin to multiply exponentially. The first Mappers have not yet finalized, but the data is already being distributed by other Mappers, containers are allocated for all this, and - boom! Your cluster is crammed into the ceiling, no one else can run a single job. There are not enough resources, and you see how the numbers on the progress bar are slowly changing. MapReduce is free of this effect because of its consistency, but you pay for it, as always, with speed.
We have long known how to deal with the fact that the standard MapReduce takes too many containers. Adjust the parameters:
mapreduce.input.fileinputformat.split.maxsize: decreasing - increasing the number of Mappers;mapreduce.input.fileinputformat.split.minsize: increasing - decreasing the number of Mappers;mapreduce.input.fileinputformat.split.minsize.per.node,mapreduce.input.fileinputformat.split.minsize.per.rack: more fine-tuning to control local (in the sense of a node or rack) partitions;hive.exec.reducers.bytes.per.reducer: increasing - reducing the number of Reducer'ov;mapred.tasktracker.reduce.tasks.maximum: set the maximum number of Reducer's;mapred.reduce.tasks: set a specific number of Reducer'ov.
Caution! In a DAG, all reduce-steps will have as many processes as you specify here! But the Tez parameters are more cunning, and the parameters that we set for MapReduce do not always affect it. First, Tez is very sensitive to
hive.tez.container.size , and the Internet advises taking values between yarn.scheduler.minimum-allocation-mb and yarn.scheduler.maximum-allocation-mb . Secondly, take a look at the hold options for an unused container:tez.am.container.ide.release-timeout-max.millis;tez.am.container.ide.release-timeout-min.millis.
The
tez.am.container.reuse.enabled option activates or deactivates the reuse of containers. If it is disabled, the previous two parameters do not work. And third, look at the grouping options:tez.grouping.split-waves;tez.grouping.max-size;tez.grouping.min-size.
The fact is that for the sake of parallelizing the reading of external data, Tez changed the process of forming tasks: first Tez estimates how many waves (w) can be run on the cluster, then this number is multiplied by the parameter
tez.grouping.split-waves , and the product (N) is divided on the number of standard splits per task. If the result of actions is between tez.grouping.min-size and tez.grouping.max-size , then everything is fine and the task starts in N tasks. If not, the number adapts to the frame. Documentation on Tez advises “only as an experiment” to set the parameter tez.grouping.split-count , which cancels all the above logic and groups splits into the number of groups specified in the parameter. But I try not to use this feature, it does not give flexibility to Tez and Hadoop as a whole for optimization for specific input data.Tez nuances
In addition to major problems, Tez is not free from small flaws. For example, if you use http Hadoop ResourceManager, then you will not see in it how many Tez-job containers are occupied, and even more so in what state its Mappers and Reducer are. To monitor the status of the cluster, I use this small python script:
import os import threading result = [] e = threading.Lock() def getContainers(appel): attemptfile = os.popen("yarn applicationattempt -list " + appel[0]) attemptlines = attemptfile.readlines() attemptfile.close() del attemptlines[0] del attemptlines[0] for attempt in attemptlines: splt = attempt.split('\t'); if ( splt[1].strip() == "RUNNING" ): containerfile = os.popen("yarn container -list " + splt[0] ) containerlines = containerfile.readlines() containerfile.close() appel[2] += int( containerlines[0].split("Total number of containers :")[1].strip() ) e.acquire() result.append(appel) e.release() appfile = os.popen("yarn application -list -appStates RUNNING") applines = appfile.read() appfile.close() apps = applines.split('application_') del apps[0] appsparams = [] for app in apps: splt = app.split('\t') appsparams.append(['application_' + splt[0],splt[3], 0]) cnt = 0 threads = [] for app in appsparams: threads.append(threading.Thread(target=getContainers, args=(app,))) for thread in threads: thread.start() for thread in threads: thread.join() result.sort( key=lambda x:x[2] ) total = 0 for app in result: print(app[0].strip() + '\t' + app[1].strip() + '\t' + str(app[2]) ) total += app[2] print("Total:",total) Despite the assurances of HortonWorks, our practice shows that when in Hive you make a simple SELECT smth FROM table WHERE smth, then most often MapReduce will work faster, though not by much. In addition, at the beginning of the article I deceived you a little: paralleling in HiveOnMapReduce is possible, but not so intellectual. It is enough to make
set hive.exec.parallel=true and configure set hive.exec.parallel.thread.number= ... - and independent steps (pairs Mapper + Reducer) will be executed in parallel. Yes, it is not possible that at the output of one Mapper several Reducer or next Mappers will be launched. Yes, parallelization is much more primitive, but also speeds up work.Another interesting feature of Tez is that it runs its engine on a cluster and keeps it turned on for a while. On the one hand, it really speeds up the work, since the task runs on the nodes much faster. But on the other hand, an unexpected minus: important processes in this mode cannot be started, because the TEZ-engine eventually generates too many classes and drops from GC-overflow. And it happens like this: you launched
nohup hive -f ....hql > hive.log & for the night nohup hive -f ....hql > hive.log & , came in the morning, but it fell somewhere in the middle, the hive was completed, the temporary tables went away, and everything must be considered anew. UnpleasantAdds to the piggy bank of minor problems that the good old MapReduce has already entered a stable release, and TEZ, despite its popularity and progressiveness, is still in version 0.8.4, and bugs in it can occur at any step. The most terrible bug for me is the deletion of information, but I have not seen anything like that. But with the incorrect calculation on Tez we came across, and MapReduce considers it correct. For example, my colleague used two tables — table1 and table2, which have a unique EntityId field. I made a request through Tez:
select table1.EntityId, count(1) from table1 left join table2 on table1.EntityId = table2.EntityId group by EntityId having count(1) > 1 And I got some lines on the output! Although MapReduce expectedly returned an empty result. There is a bugreport about a similar problem.
Conclusion
Tez is an unconditional good, which in most cases makes life easier, allows you to write more complex queries to Hive and expect a quick response to them. But, like any good, it requires a cautious approach, caution and knowledge of some nuances. And as a result, sometimes using the old, proven, reliable MapReduce is better than using Tez. I was very surprised that I could not find a single article (neither in RuNet, nor in English) about the minuses of HiveOnTez, and decided to fill this gap. I hope that the information will be useful to someone. Thank! Good luck to everyone and bye!
Source: https://habr.com/ru/post/312194/
All Articles