How to optimize the memorization of foreign words

Before taking up the development of a mobile application for learning vocabulary, we at Skyeng school spent a lot of time studying memory algorithms and memorizing words. As a result, the development of Aword took a little more time, but we are more confident in the result - the use of certain algorithms in the display of words helps to more effectively vocabulary.
 There are a large number of applications for learning foreign words on the market. All of them share a common feature - the use of cramming (drilling) as the main tool for learning. The more time a student spends repeating words, the higher the chance that he will remember them. For example, it’s quite possible to learn a hundred words in an hour. However, without repeating in 6 hours, half of them will be forgotten. After another six hours, no more than 15 words will remain in my memory. To avoid this, it is necessary to regularly repeat the whole set (cramming).
There are a large number of applications for learning foreign words on the market. All of them share a common feature - the use of cramming (drilling) as the main tool for learning. The more time a student spends repeating words, the higher the chance that he will remember them. For example, it’s quite possible to learn a hundred words in an hour. However, without repeating in 6 hours, half of them will be forgotten. After another six hours, no more than 15 words will remain in my memory. To avoid this, it is necessary to regularly repeat the whole set (cramming).')
If a student makes a pause in repeating the list (for a week, for a month, on vacation, working hard, ...) it is highly likely that words will be forgotten, and cramming will have to start from the beginning. If he switched from one set of words to the next and did not repeat the first after some time - he will forget it. In order for such memorization to work efficiently, it is necessary, independently or with the help of a teacher, to draw up a clear training plan and follow it strictly, otherwise craving will turn into a meaningless loss of a huge amount of time without an obvious, predictable result.
We thought: Is it possible to make an application that will provide not only the process of "drilling", but also the preparation and maintenance of a lesson plan and control over the knowledge gained? How to maximize learning efficiency and save student time?
We'll have to start from afar: with a conversation about the structure of our memory, which can be short-term and long-term.
Cramming vs memorization
 Short-term well familiar to students who give some not very necessary formal subject. If you study the textbook on the night before the exam, there is a high probability that most of the information, albeit in an isolated form, will remain in memory long enough to pass the exam or test. However, after a couple of days, it will disappear without a trace (more precisely, as research shows, it will not disappear, but it will be so safely hidden in the depths of consciousness that it would be problematic to extract it from there).
Short-term well familiar to students who give some not very necessary formal subject. If you study the textbook on the night before the exam, there is a high probability that most of the information, albeit in an isolated form, will remain in memory long enough to pass the exam or test. However, after a couple of days, it will disappear without a trace (more precisely, as research shows, it will not disappear, but it will be so safely hidden in the depths of consciousness that it would be problematic to extract it from there).Long-term memory - this is what allows us to easily recall the information received, and a year and five years later. But in order to make it work, regular trainings are necessary, and the most effective format of these trainings is not rereading the textbook, but checking on test questions or the constant application of the knowledge gained in practice.
For example, a student learning a new programming language gets this training in the form of daily coding sessions. Having understood the topic of objects in C ++, he will be able to remember it forever if he uses it regularly. Therefore, teachers require object programming, even trivial tasks, where it would be reasonable to do without it.
Long-term memory is not always required. A chemist does not need to know all the formulas; a lawyer does not need to have in his head full versions of the criminal, civil and procedural code. Reference books can always come to their aid; for them it is more important to understand the principles of work and knowledge of the direction of data retrieval.
But there are areas where long-term memory is needed. The most obvious are medicine and linguistics. The doctor must remember the symptoms of any, even rare, disease. A person who claims to be fluent in English should know the word serendipity, even if he has never encountered it in his life. Of course, the most effective way to develop such a long-term memory is practice. A graduate of a medical school for a few years is sent to a residency or internship. A professional translator is sure to go on an internship in the environment of native speakers.
But what if there is no such possibility? And what if the doctor during the residency did not face the case of Kawasaki syndrome?
It is necessary to develop long-term memory in some other way. It is not surprising that the main research in this area is carried out by physicians and linguists.
Polish student and German psychologist
Peter Wozniak, the author of the most famous memorization algorithm SuperMemo, thought about optimizing this process in the 80s, when he was a student at the Poznan Polytech. One of the tasks that he set for himself was full-fledged proficiency in English - he was not satisfied with the superficial-professional level that his fellow students were completely satisfied with.
Wozniak was quite a hard-nosed guy. He created a database of English and biology cards containing a question and answer, and took up daily workouts, carefully recording the results in a diary. At the end of the experiment, he formed three thousand English cards and more than one and a half thousand in biology.
Using simple calculations based on the data, Wozniak found that in order to memorize a small dictionary of 15,000 English words, he would need to spend two hours every day in training. Spent time grows in proportion to the number of words: to memorize 30 thousand will require four hours of repetitions daily. Not very comfortable.
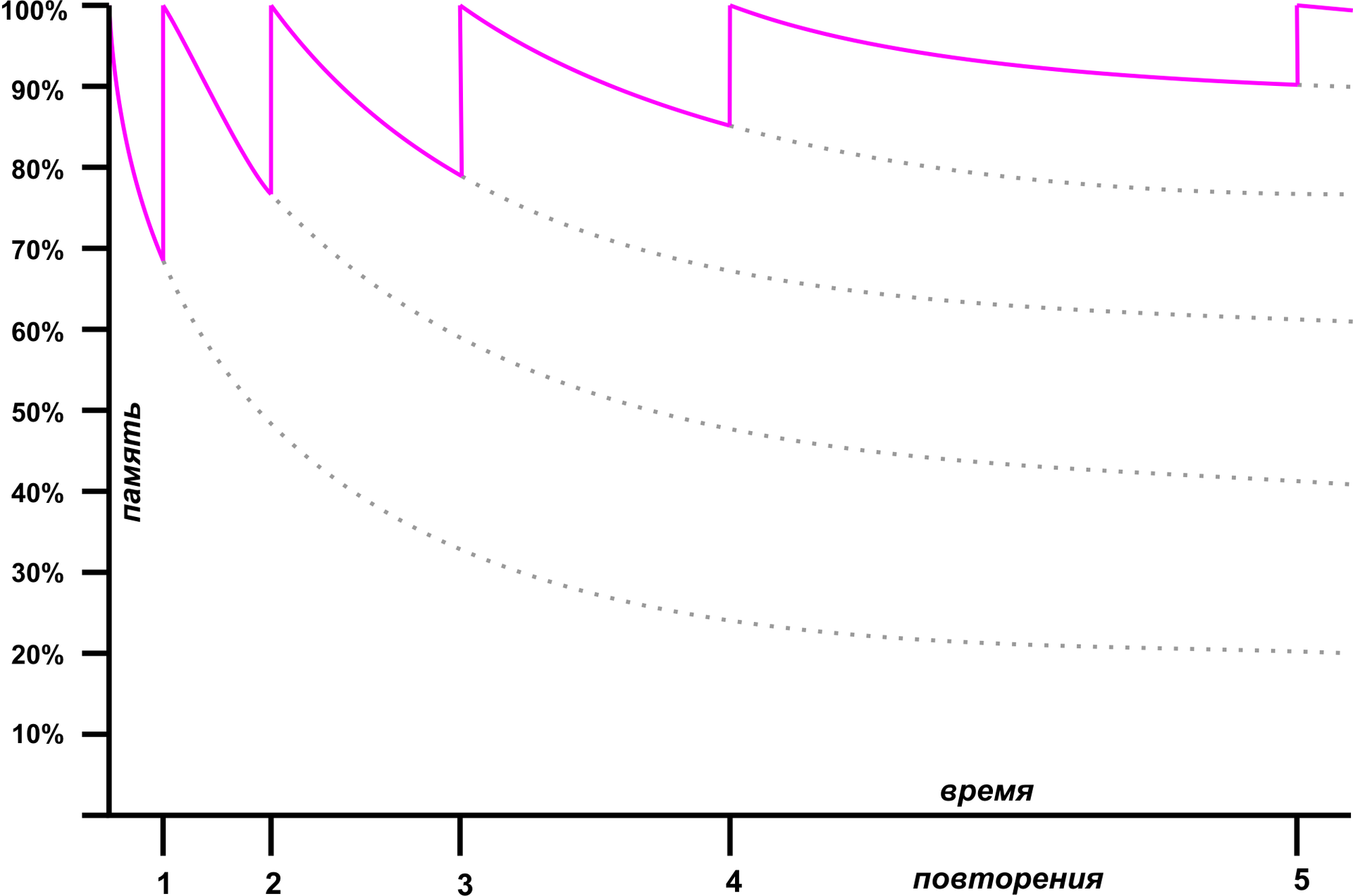
 Fortunately, a hundred years before Peter Wozniak, the German psychologist Herman Ebbingauz, also a very stubborn person, became concerned with a similar problem. Ebbingauz conducted two one-year experiments in which he memorized meaningless sets of syllables. As a result, several discoveries have been made, the most important of which is the forgetting curve.
Fortunately, a hundred years before Peter Wozniak, the German psychologist Herman Ebbingauz, also a very stubborn person, became concerned with a similar problem. Ebbingauz conducted two one-year experiments in which he memorized meaningless sets of syllables. As a result, several discoveries have been made, the most important of which is the forgetting curve.Ebingauz experimentally found that the speed of forgetting information falls after each repetition. After the first memorization of data, forgetting goes very quickly: in an hour about half of the material flies out of the head, in ten hours - 65%; however, about 20% remains a month after the study. However, if during the first hour to repeat all the material, the process of forgetting it will slow down significantly, and a new repetition can be done in a day. Using the forgetting curve, you can arrange repetitions in such a way that the maximum long-term absorption of material takes place in the minimum amount of training.
This method is called "interval repetition" (Spaced Repitition). In the 30s, an experiment was conducted, showing that such a technique really has a beneficial effect on the learning process. However, she didn’t gain popularity at that time because of her excessive complexity: it was necessary to prepare thousands of cards with questions and answers, to shuffle them correctly, to repeat them in time ... But then computers appeared.
Let us return to the Polish student Peter Wozniak, who dreamed of learning English, but did not burn with the desire to spend four hours a day on training. He decided to algorithmize the technique of interval repetitions, which ultimately resulted in the SuperMemo program. Of course, everything turned out to be far from simple, and the development of SuperMemo was, in fact, a matter of his life.
Algorithmization of the method of interval repetitions is quite obvious. The main problem of this method is the need to accurately calculate the time when the repetition will be as efficient as possible - i.e. the very moment when information is forgotten. If you write a program that will not only conduct training, but also promptly remind the user of their need, this theoretically allows for more effective training.
It has its own features. The forgetting curve itself is a universal phenomenon, however, different people have different exhibitors on it. Someone needs a third repetition in 20 minutes, someone in an hour; the distance between subsequent repetitions changes in the same way. Therefore, training should be flexible - in their course, the algorithm tries to understand the speed of forgetting a particular student and adapt to it.
An important problem on the path to successful learning is the human factor. In order to effectively remember the maximum amount of information for the minimum period, you need to accurately follow the schedule. In reality, this creates inconvenience, and students decide to postpone it for later. As a result, having missed the right moment, they roll back - one step, two, or even to the very beginning of training. This rollback also needs to be calculated correctly to minimize costs due to omissions.
Word license
At the heart of our mobile application Aword is the concept of “word licenses” - by analogy with time-limited software licenses. After the first memorization, the “license” is valid for about an hour; if you do not repeat the word, it will be forgotten. If you repeat the words at the end of this hour, a new “license” will appear, already for six hours. The next “license” will be for a day, then for three days, a week, a month, six months, two years. The most effective moment for repetition is the borderline one, when the previous “license” expires, and in order to recall the word, some effort must be made. All the “licenses” for each word are stored on our server in the student's account, and the task of the mobile application is to remind in time that it is time to update them.
The basic algorithm underlying Aword can be described with the following pseudo-code:
function makeRepetition( user, word, license ){ var timePassed = (new Date()) - license.startTime; var answer = showWordCard( word ); user.tuneParameters( license, timePassed, answer.quality ); word.tuneComplexity( license, timePassed, answer.quality ); if(answer.quality > 0) { license.next( timePassed ); } else { license.rollback( timePassed ); } } The basic code of this algorithm determines whether it is possible to give an increased “license” per word, or whether it should be taught again. tuneParameters and tuneComplexity - conditional links to tuning algorithms; The quality of the answer (answer.quality) is a number from 0 to 1. This number is equal to one, if the student quickly learned the word from the first time; his memory works well, the task was too easy for him. In this case, the algorithm will increase the repetition intervals. If the quality of the answer is close to less than 0.5 - the answer was given with difficulty, after prompts; The standard repetition interval for this student is too long, it is necessary to conduct training more often.
The original forgetting curve was built on the basis of synthetic experiment data. Ebbinghaus deliberately used meaningless syllables to get the most pure results.
Modern medical students successfully use the forgetting curve in its initial form, for example, to memorize pharmacological data (also, in general, consisting of sets of letters). Here, for example, is a typical instruction for repeating material:
- the first repetition - immediately after reading (checking on control issues);
- the second repetition - in 20 minutes;
- the third - in a day;
- the fourth - 48 hours after the third;
- the fifth - 72 hours after the fourth.
There are universal algorithms that allow the use of the method of interval repetitions for the effective memorization of any information. The most famous (and also free) program is Anki . Of course, it does not take into account the peculiarities associated with the study of foreign languages, but it can be useful if you need to remember something really important for a long time.
 When studying a foreign language, we are not dealing with chaotic sets of letters, but with meaningful words. The degree of meaningfulness and clarity of the word student directly affects the speed of memorization. So, the engineer will remember the word “gear” much faster than the philosopher. Habitual, easily represented words (“oak”) are remembered more easily than exotic (“fir”). As a result, it is necessary to carefully select groups with approximately the same speed of memorization. The SuperMemo algorithm uses for this selection the subjective assessment of the user - how difficult is the word given to him; This is not a very accurate indicator. Another factor is the vocabulary base already available to the student, which must be assessed for the preparation of the program. All this must also be algorithmized. However, these are topics for individual articles.
When studying a foreign language, we are not dealing with chaotic sets of letters, but with meaningful words. The degree of meaningfulness and clarity of the word student directly affects the speed of memorization. So, the engineer will remember the word “gear” much faster than the philosopher. Habitual, easily represented words (“oak”) are remembered more easily than exotic (“fir”). As a result, it is necessary to carefully select groups with approximately the same speed of memorization. The SuperMemo algorithm uses for this selection the subjective assessment of the user - how difficult is the word given to him; This is not a very accurate indicator. Another factor is the vocabulary base already available to the student, which must be assessed for the preparation of the program. All this must also be algorithmized. However, these are topics for individual articles.The algorithms used in our mobile application were tested for half a year on volunteers from among the employees and their friends. This allowed us to select some average parameters (the term of “licenses”), which are ultimately used to optimize the process of long-term memorization of words. Now that the application is available to everyone, we will be able to collect significantly more analytical data to further fine-tune these parameters. And all this can be seen by downloading the mobile application in the App Store . At the end of October, the application will be posted on Google Play, and in November it will be available on the Web.
And if you yourself want to participate in the development of such pieces - we have a lot of interesting vacancies !
Source: https://habr.com/ru/post/312126/
All Articles