"Spherical trader in a vacuum": instructions for use

If you analyze
Pessimists say: the market is random "because I built a random process chart and my friend (professional trader) could not distinguish it from the EURUSD chart", which means it is impossible to have a stable income on the market (Forex)!
')
Optimists object to them: if the market were random, the quotes would not have walked around 1, but went to infinity. So the market is not accidental and you can earn on it. I saw a really stable earning strategy with a large profit factor (more than that)!
Let's try to remain realistic and benefit from both opinions: suppose that the market is random, and based on this assumption, we construct a methodology for checking the profitability of the trading system for non-randomness .
The techniques considered in the article are universal for any markets, be it a fund, forex, or any other!
Formulation of the problem
Thanks to the well-known joke about a spherical horse in vacuum, a wonderful allegory was born, meaning an ideal, but completely inapplicable in practice model.
However, with the correct formulation of the problem, it is possible to extract quite tangible practical benefits by applying a "spherical model in vacuum." For example, through the denial of "sphericity" of the real object of study.
Suppose we have a trading system used in a certain market. Also suppose that the market is not accidental and the system uses something that is not a random number generator disguised as indicators for making trading decisions. To assess the stability of income, we use the profit factor:
What should be the profit factor so that you can talk about the stability of this system? Obviously, the higher the profit factor, the more reasons to trust the system. But the lower limit is estimated by different experts in different ways. The most popular options are:> 2 (so-so),> 5 (good system),> 10 (great system). There is also such a variation:
What always confused me in the profit factor was the fact that the market dynamics and the intensity of trade are not taken into account. Therefore, I propose a different approach to assessing the significance of the profit factor, rather than a comparison with some a priori given value: the profit factor should be as high as possible, but not lower than the profit factor of a random system in a random market with similar trading intensity and volatility accordingly (in fact, not lower than that of the “spherical trader” in the “ideal gas” or in the “vacuum”).
It remains only to build an ideal model for comparison.
"Spherical trader ..."
Suppose we are considering some random trading system (“spherical trader”). Since the model is random, trading events occur at random points in time, regardless of the decisions made earlier. The direction of transactions is also random (with a probability of 0.5 sale or purchase). The volume of transactions is assumed constant, and without loss of generality, we estimate the profit and loss in points.
Let the average duration of the transaction is
Also assume that we will deal with Poisson flows of events:
Transaction duration
Where
Amount of deals
Where
"... in a vacuum"
Now consider the ideal habitat of the “spherical trader” - “vacuum”, that is, a completely random market.
Suppose that the market is described by the normal distribution of changes in the values of quotes
Where
This is a known correlation for the Brownian process.
Taking into account formulas (2.1) and (1.1), the result of the transaction, considered as a change in quotations over the period from the beginning to the end of the transaction, will be described as the integral of conditional probability
or
Solving this integral using Wolfram Mathematica gives the following result:
or
Where
The resulting pattern is the distribution of Laplace .
Thus, the income or loss on a single transaction of a random system in a random market is described by the Laplace distribution, and the absolute value of the result
Where
It is known that the exponential distribution is a special case of the chi-square distribution (
Let it be done
Where
the ratio of these values will be as follows:
Where
Now consider the following value:
This value can be interpreted as a “normalized profit factor”: the ratio of the average income to the average loss per transaction. Let's see what distribution this quantity has:
The resulting quantity, the chi-squared ratio of the quantities normalized to the number of their degrees of freedom, has a Fisher distribution.
So we found the distribution of the magnitude, the statistics
Before proceeding to the generalization to the case of unknowns
"... in perfect gas"
Now consider a slightly more complicated situation: when the market is a generalized Brownian motion. That is, unlike the random, has a memory. In this case, formula (2.2) will take the following form:
Where
With
Different markets are characterized by different values of the Hurst index, in addition, they may change from time to time. Hurst index can be calculated by the values of the time series. So, when evaluating the profit factor, you can take into account the value
Suppose that a random trading strategy works on the market with the Hurst index H, then, taking into account (3.1) , the formula (2.3) takes the form:
Obviously, when
Unfortunately, expression (3.2) is not integrated analytically. Therefore, to find the distribution of the absolute values of the difference in quotations between the moments of the beginning and end of the transaction (absolute transactions) for random trading in the market with the Hurst index
I conducted simulations using Python.
The simulation is as follows.
1) Set the simulation parameters:
2) Generate a sample distE of an exponentially distributed random variable and a sample distN of a normally distributed variable of volume N each.
3) Given the relation (3.1) , we create a test sample distT, each value of which is calculated from the corresponding distN and distE values:
4) For the distribution obtained, a histogram of M ranges is constructed (the number of hits in the ranges). From the obtained histogram, K first ranges are selected, the number of hits in which is different from zero. Also rationing is performed on the number of hits in the first range.
5) Based on the obtained histogram, the type of distribution is approximated.
import matplotlib.pyplot as plt import numpy as np from scipy import stats def testH(N, M, H, p): distE = np.random.exponential(1, N) distN = np.random.normal(0, 1, N) distT = abs(distN * distE**H) if p == 1: plt.figure(1) plt.hist(distT, M) plt.title('H='+str(H)) [y, x] = np.histogram(distT, M) K = 0; for i in range(M): if y[i] > 0: K = i else: break y = y * 1.0 / y[0] x = x[1:K] y = y[1:K] return getCoeff(x, y, p, 'H='+str(H)) Examples of histograms of the obtained distributions for the values of the Hurst index 0.1, 0.3, 0.5, 0.7 and 0.9 are given below.

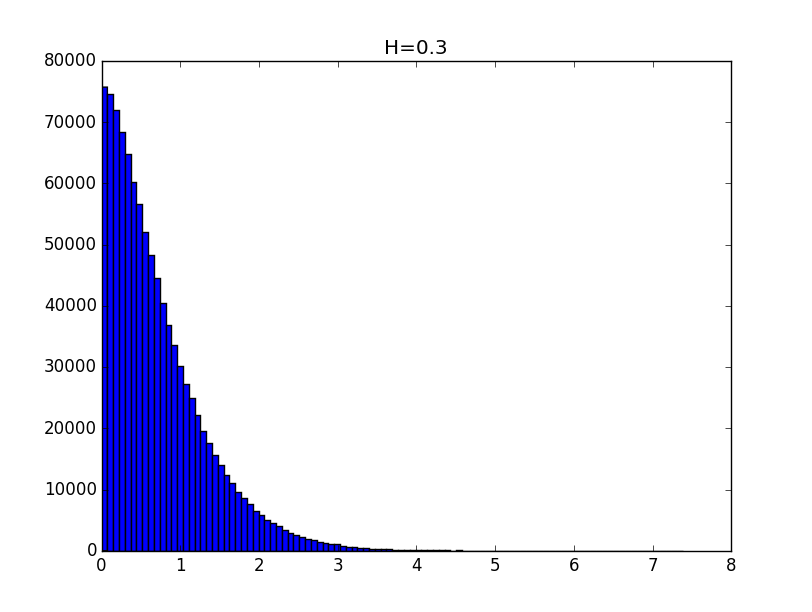
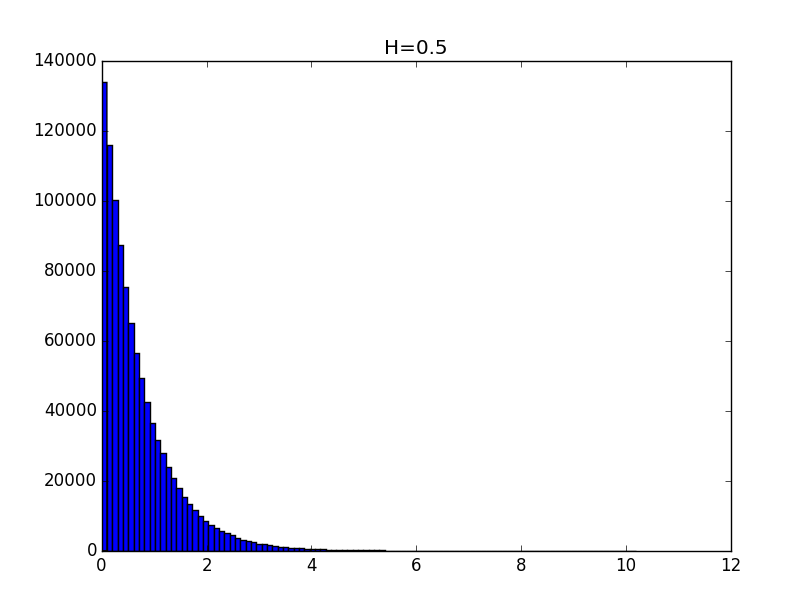
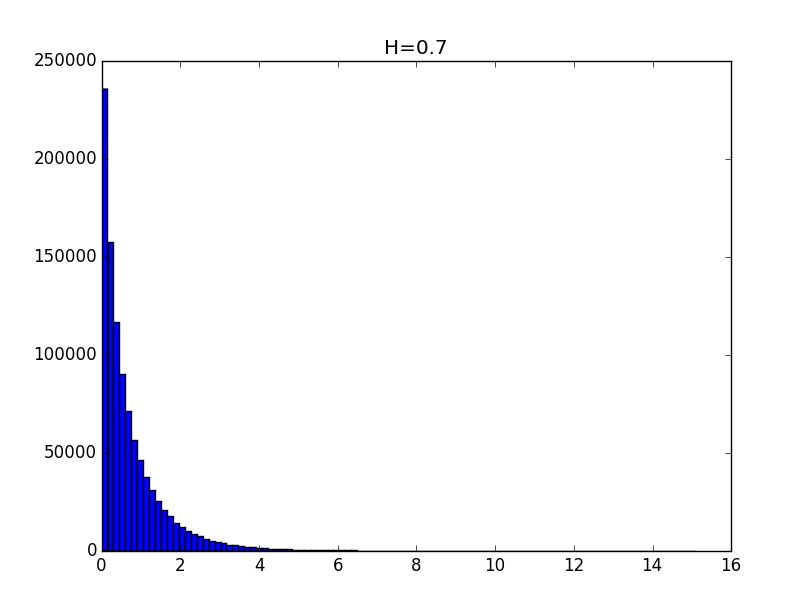

The general view of the histograms suggests that the obtained distributions, up to a constant, can be described by a function of the form:
To search for the distribution parameter, we use the following algorithm:
1) Let us be given
2) Then, ignoring the first range, perform the conversion:
3) Using the method of least squares, we find the parameters of linear regression
4) Based on received
Parameter
The listing of the procedure for calculating the coefficients is given below:
def getCoeff(x, y, p, S): X = np.log(x) Y = np.log(-np.log(y)) n = len(X) k = (sum(X) * sum(Y) - n * sum(X * Y)) / (sum(X) ** 2 - n * sum(X ** 2)) b = (sum(Y) - k * sum(X)) / n if p == 1: plt.figure(2) plt.plot(np.exp(X), np.exp(-np.exp(Y)), 'b', np.exp(X), np.exp(-np.exp(k * X + b)), 'r') plt.title(S) plt.show() return k The following are examples for envelopes of histograms for the Hurst values of 0.1, 0.3, 0.5, 0.7 and 0.9 (blue line) and their models (red line):
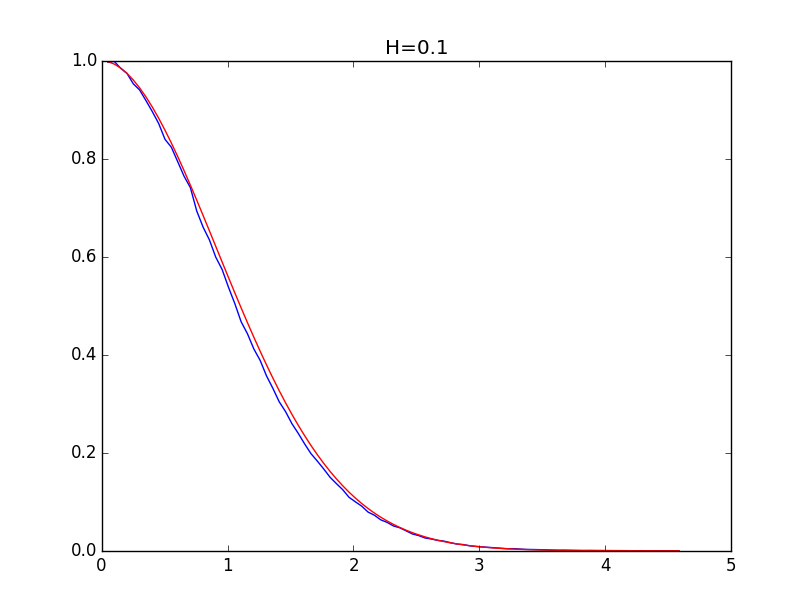
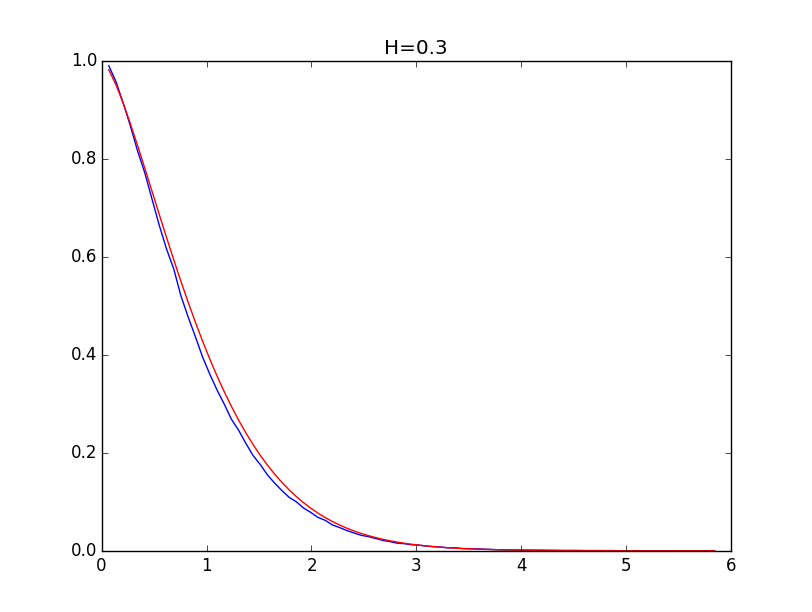
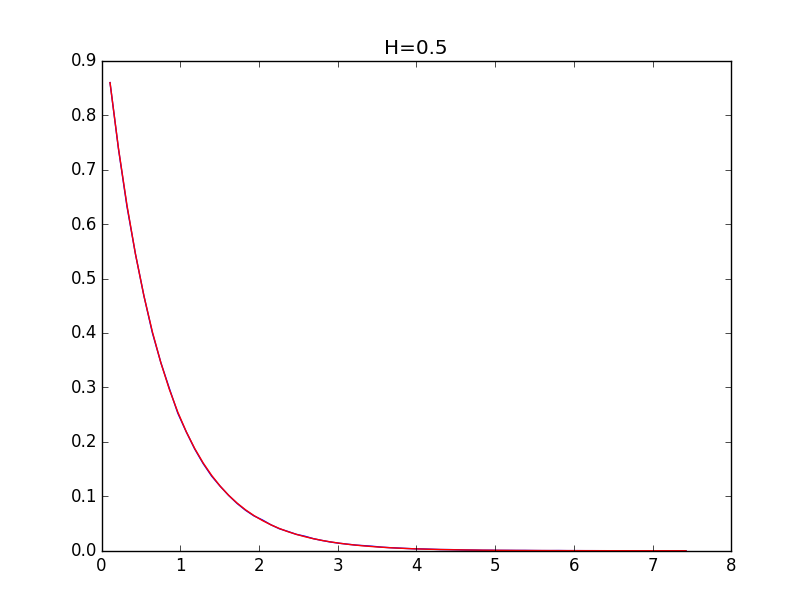


With the values of the Hurst index above 0.5, the simulation accuracy is higher.
Now we find the dependence
I used to simulate the values
if __name__ == "__main__": N = 1000000; M = 100; Z = np.zeros((99, 2)) for i in range(99): Z[i, 0] = (i + 1) * 0.01 for j in range(20): W = float('nan') while np.isnan(W): W = testH(N, M, (i + 1) * 0.01, 0) Z[i, 1] += W Z[i, 1] *= 0.05 print Z[i, :] X = Z[:, 0].T Y = Z[:, 1].T plt.figure(1) plt.plot(X, Y) plt.show() The resulting dependence is as follows:

The graph looks like a distorted sigmoid, so we will look for the pattern as a sigmoid:
A numerical minimization procedure using the least squares method gives the following results:
The total quadratic error is about 0.005.
Below are graphs of experimental dependence
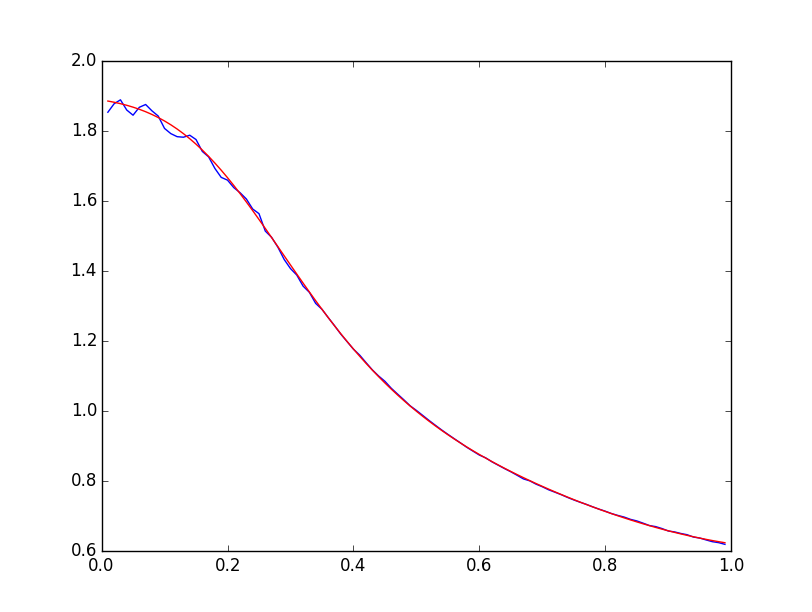
It should be noted that the obtained pattern is valid only for the case when
Now, considering (3.3) and (3.4) for the estimated value
Then:
This is a probability density function of a quantity having a gamma distribution with a number of degrees of freedom.
Let's summarize:
Having information about the Hearst Market Indicator
According to (3.7) , the values
Let it be done
and
will have a chi-square distribution with quantities of degrees of freedom
Therefore, the value:
will have a Fisher distribution c
Let's call the value
Final summary
So, we investigated the “spherical trader” in a random market and found the distribution of the normalized profit factor. Then we summarized the results for the case of a market with an arbitrary fractal dimension, represented by a measurable quantity - the Hurst index.
Now we have a value that we call the generalized normalized profit factor, which is calculated using information on the results of transactions (by the way, let's not forget to correct them taking into account the spread: take it away from losses and add to income). For greater universality of the methodology, the volume of transactions is considered constant, or we measure everything in points. Do not forget also to carry out the normalization of the average duration of the transaction and the standard deviation of the distribution of the results of transactions:
All the results obtained so far are tied to a known number of profitable and unprofitable transactions, which is a random variable with a binomial distribution for a known total number of transactions, which, in turn, is also a random variable distributed across Poisson .
We introduce a new designation. Let the generalized normalized profit factor (3.8) for a given amount of profitable
Then, taking into account the binomial distribution of the number of profitable and unprofitable transactions, as well as the equal probability of receiving income or loss on each transaction, we introduce the value
Where
In practice, with sufficiently large
Where
Now we will consider the generalized normalized profit factor without reference to any number of transactions, but only taking into account the average trade intensity
Or, for the considered number of transactions in the range
The obtained distribution can be used to test the significance of the generalized normalized profit factor calculated by (3.8) for a trading system with a known average transaction duration and trading intensity for a certain amount of time in the market with known volatility and Hurst index. The method of application of the test is absolutely similar to that for the Fisher test. To carry it out, it suffices to replace in (4.1) (or (4.1 *) ) the density function with the Fisher distribution function and substitute the value of the calculated generalized profit factor as an argument. The resulting probability value must be compared with the value
Conclusion
The proposed approach based on the construction of a generalized normalized profit factor, taking into account the volatility and fractal properties of the market, as well as the intensity of trade and the average duration of transactions, allows us to construct a statistical test of the significance of the results achieved in terms of the likelihood of similar results being obtained randomly. Using the test, it is possible with a given level of significance to talk about the fulfillment of the necessary condition for ascertaining the reliability of the system. But the results will not be a sufficient condition ...
Unfortunately, I do not know the test, the results of which will be sufficient for the unequivocal adoption of a strategy as unconditionally reliable.
Source: https://habr.com/ru/post/312096/
All Articles