Little documented features of IBM Tivoli Monitoring
I have been implementing the monitoring products from IBM, and I wondered what open source achieved compared to IBM solutions in the area of hardware and software monitoring. For what I began to install the most popular monitoring systems from the world of open source and read the documentation. I was mainly interested in the solution architecture. The following open source products came into my view: Zabbix, Nagios, NetXMS. I found them the most popular and frequently mentioned. All of them can be compared with IBM Tivoli Monitoring (ITM). ITM is the core of IBM service monitoring. As a result, I decided to describe the non-documented ITM architecture of the product, which is an advantage in large installations.
It is mentioned that ITM is not the only product of such functionality from IBM today. Recently, a product called IBM Application Performance Management appeared, but about its architecture another time.
Due to the nature of ITM, it is not recommended to use it for monitoring a large number of network equipment. There are all sorts of unusual situations, but IBM Tivoli Network Manager is usually used for this.
I will mention about zabbix. I often met him at customers and heard a lot. Once the customer struck me deeply with the requirements to receive data from the agent every 10 seconds. He was very disappointed that you can’t create triggers on average for a period in ITM (if you argue, then you can tinker with crutches, but why?). He was familiar with zabbix.
')
In zabbix (similar to NetXMS), triggers analyze historical data. This is very cool, but I have never needed this. The zabbix agent transfers data to the server (or through a zabbix proxy). Data is stored in a database. After that triggers are worked out for them, and a powerful macro system helps them. Hence, there are requirements for the performance of iron to perform the basic functionality.
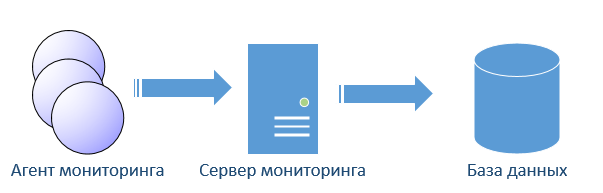
ITM has its own characteristics. The ITM server receives all data exclusively from agents. No built-in SNMP protocols, etc. The server is a multi-threaded application with an embedded database. The peculiarity of ITM in the work of triggers (they are the same situation, but to comply with the general terminology I will name the triggers). Triggers are executed on the agent. In addition, these triggers are conditional SQL queries. The server compiles the triggers into a binary sql code and gives it to the agent for execution. The architecture of the agent is such that it looks like a database.
All sorts of metrics already built into the agent (they recently added the ability to get data from applications / scripts) and are described as tags in a relational database. The agent executes the sql query according to the specified interval. The layer, which amateurishly call the “database”, performs the necessary queries to the operating system (OS) and puts the data in a table. The frequency of requests to the OS no more than 30 seconds. That is, the data in the table often 30 seconds. do not upgrade. It is clear that the agent can perform a lot of monotonous triggers, which does not have a strong impact on the load, because again, more often 30 seconds. he will not collect data. Another interesting fact is that the agent will not disturb the server until the sql query it performs returns 0 rows. As soon as the sql query returns a few lines, all these lines will go to the server (the trigger condition has come). The server, in turn, will put the data in a temporary table until a separate thread passes through it, which checks for additional conditions and generates an event in the system. Heralding the question of how the agent handles events, such as logs? Everything is normal there, the agent immediately sends such data to the server in active mode.
Hence the conclusion. The ITM server database does not contain history, only operational data. Triggers are executed on the side of the agent who will take over part of the load.
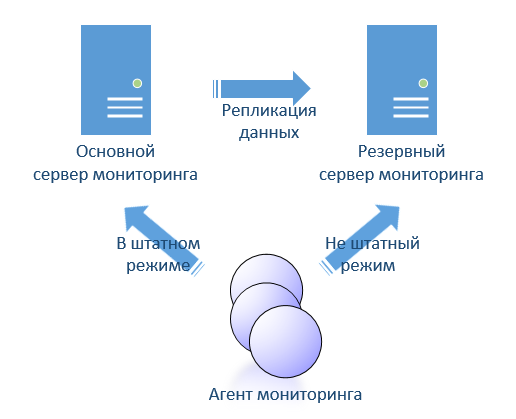
Also considering open source, I immediately wondered about the implementation of fault tolerance. I did not see what I would like. Since ITM allows you to implement hot-stanby (hot backup), I would like something like this in open source. In ITM, this is implemented quite simply. Two servers that replicate their databases from active to passive. In the agent settings are both servers. Agents switch between two servers automatically.
Collecting history in ITM is implemented by the same triggers, only in the system they are marked as historical and are configured separately. According to the history setting, the server sends the historical sql execution requests to the agent, only they have no condition (like select * from table). The result of these sql is all the data in the agent tables. This data is added to the file. The agent periodically gives historical data to a special warehouse proxy agent, which in turn puts it in a special database, which is usually called Warehouse. If the agent loses connection with the server or with the proxy agent, then nothing terrible except the growth of the history file does not happen. The agent will give the proxy history as soon as it can. The ITM server does not have access to the warehouse database and therefore it is impossible to make triggers on top of the history.

I like open source and affordable solutions have their advantages and disadvantages. There is a certain feeling that the choice of architecture was due to where the solution was originally applied. The ITM core was born in the depths of another company, apparently somewhere in the early 90s. I suppose in those days there was little memory, the processor was weak by modern standards. Therefore, complex resource saving solutions were sought.
It is mentioned that ITM is not the only product of such functionality from IBM today. Recently, a product called IBM Application Performance Management appeared, but about its architecture another time.
Due to the nature of ITM, it is not recommended to use it for monitoring a large number of network equipment. There are all sorts of unusual situations, but IBM Tivoli Network Manager is usually used for this.
I will mention about zabbix. I often met him at customers and heard a lot. Once the customer struck me deeply with the requirements to receive data from the agent every 10 seconds. He was very disappointed that you can’t create triggers on average for a period in ITM (if you argue, then you can tinker with crutches, but why?). He was familiar with zabbix.
')
In zabbix (similar to NetXMS), triggers analyze historical data. This is very cool, but I have never needed this. The zabbix agent transfers data to the server (or through a zabbix proxy). Data is stored in a database. After that triggers are worked out for them, and a powerful macro system helps them. Hence, there are requirements for the performance of iron to perform the basic functionality.
ITM has its own characteristics. The ITM server receives all data exclusively from agents. No built-in SNMP protocols, etc. The server is a multi-threaded application with an embedded database. The peculiarity of ITM in the work of triggers (they are the same situation, but to comply with the general terminology I will name the triggers). Triggers are executed on the agent. In addition, these triggers are conditional SQL queries. The server compiles the triggers into a binary sql code and gives it to the agent for execution. The architecture of the agent is such that it looks like a database.
All sorts of metrics already built into the agent (they recently added the ability to get data from applications / scripts) and are described as tags in a relational database. The agent executes the sql query according to the specified interval. The layer, which amateurishly call the “database”, performs the necessary queries to the operating system (OS) and puts the data in a table. The frequency of requests to the OS no more than 30 seconds. That is, the data in the table often 30 seconds. do not upgrade. It is clear that the agent can perform a lot of monotonous triggers, which does not have a strong impact on the load, because again, more often 30 seconds. he will not collect data. Another interesting fact is that the agent will not disturb the server until the sql query it performs returns 0 rows. As soon as the sql query returns a few lines, all these lines will go to the server (the trigger condition has come). The server, in turn, will put the data in a temporary table until a separate thread passes through it, which checks for additional conditions and generates an event in the system. Heralding the question of how the agent handles events, such as logs? Everything is normal there, the agent immediately sends such data to the server in active mode.
Hence the conclusion. The ITM server database does not contain history, only operational data. Triggers are executed on the side of the agent who will take over part of the load.
Also considering open source, I immediately wondered about the implementation of fault tolerance. I did not see what I would like. Since ITM allows you to implement hot-stanby (hot backup), I would like something like this in open source. In ITM, this is implemented quite simply. Two servers that replicate their databases from active to passive. In the agent settings are both servers. Agents switch between two servers automatically.
Collecting history in ITM is implemented by the same triggers, only in the system they are marked as historical and are configured separately. According to the history setting, the server sends the historical sql execution requests to the agent, only they have no condition (like select * from table). The result of these sql is all the data in the agent tables. This data is added to the file. The agent periodically gives historical data to a special warehouse proxy agent, which in turn puts it in a special database, which is usually called Warehouse. If the agent loses connection with the server or with the proxy agent, then nothing terrible except the growth of the history file does not happen. The agent will give the proxy history as soon as it can. The ITM server does not have access to the warehouse database and therefore it is impossible to make triggers on top of the history.
I like open source and affordable solutions have their advantages and disadvantages. There is a certain feeling that the choice of architecture was due to where the solution was originally applied. The ITM core was born in the depths of another company, apparently somewhere in the early 90s. I suppose in those days there was little memory, the processor was weak by modern standards. Therefore, complex resource saving solutions were sought.
Source: https://habr.com/ru/post/311938/
All Articles