How to become a super-mega-pro machine learning in 15 minutes

Recently on Habré skipped a post vfdev-5 about DIGITS . Let's take a closer look at what it is and what it is eaten with. If in a nutshell. This is an environment that allows you to solve 30-50% of the problems of machine learning on the knee within 5 minutes. Without programming skills. Well, if you have a base, of course. And more or less adequate cards from NVIDIA.
Where to get
Official page . Then it all sways from here . Same instructions. Ubuntu 14 and Ubuntu 16 are officially supported. There is a deb package for Ubuntu 14 and a docker for it. Under the 16th - assembly instructions . Collect first need caffe, then DIGITS. Sometime for a couple of hours.
What is in three words
DIGITS is a visual Front-end wrapper for well-known frameworks (caffe and Torch 7). Allows out of the box to train / to train well-known / their nets. There are a large number of cases prepared.
')
According to the form factor, this is a web service that runs in the terminal and is then available at the address “ localhost : 5000 /” on the local machine. looks like this:

For some reason casts Jupiter. Plus, it looks like TensorBoard . Unfortunately, I did not work with him much to compare.
How to work with this miracle
On the main there are only two big buttons. We need them. First you need to poke in the "New Dataset":

By default, DIGITS can work with datasets sharpened under:
- Classification - learns to recognize the belonging of N classes of images
- Find Objects - learns to search for a rectangle of an object in an image. Tomorrow I will publish a more detailed article about this piece.
- Segmentation - pixel segmentation of the image. There is a tutorial , but I did not understand.
- Processing - Do not quite understand what it is. There are no tutorials either.
Consider the classification as the simplest of options.

At the preparation stage, datasets digits clamps the base into a convenient format for them to quickly work with it, without straining hard millions of requests. In principle, everything is clear:
- The block on the left describes the format in which the image will be prepared. The standard rule of machine learning: it should look like a person to successfully recognize any image from the base. No more and no less.
- The block on the right is about the base. There you need to show where the base lies. There are two options for data that DIGITS can chew on. First format: N folders, each folder has its own class. The second format: images lie anywhere, but there is a text file of the format "<path> <class name>". % for validation - which part of the database will be used for testing during training. % for testing - how much is used for final testing.
- Block below is the base format that DIGITS will prepare for itself. In fact, the user is not very concerned.
The result of creating a database will be dynamically displayed . And also the final database statistics will be displayed:

Creating a database is complete! You can go to the training. Go to the main menu and instead of "New Dataset" poke "New Model". Again choose Classification. Here, the parameters a little more (1,2). Be sure to choose:
- Prepared base in the column Select Dataset
- Network used
There are a lot of more advanced settings:
- The number of learning epochs (how many times the base has been run)
- Configure Save and Test
- The parameters of the descent algorithm: the speed of descent, their change in the course of training
- Ability to configure the network: you can change the existing, and you can set your
- Simple dataset increments: crop, subtraction of average
You can see what the current mesh looks like:
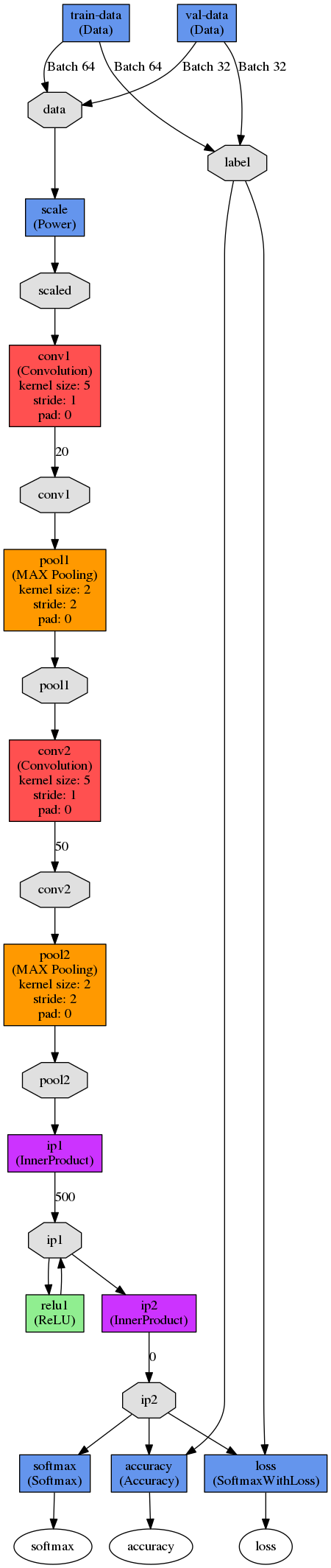
Run
Your computer hangs dead. But you see beautiful online graphs of ongoing training, assessment of time, current result, etc.:
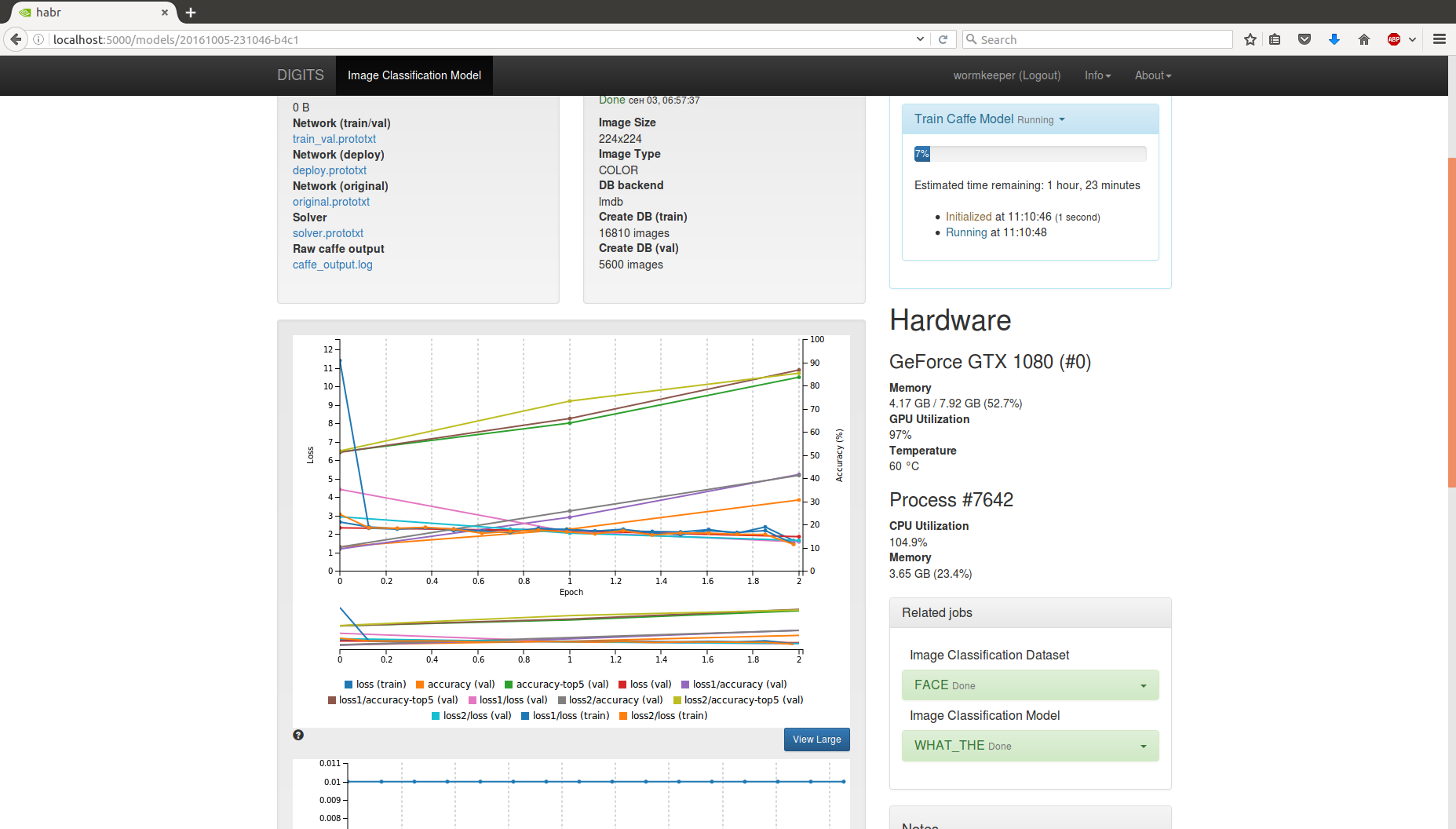
After completing the training, a menu appears that allows you to save the final model, to recognize one / several images. Build statistics.
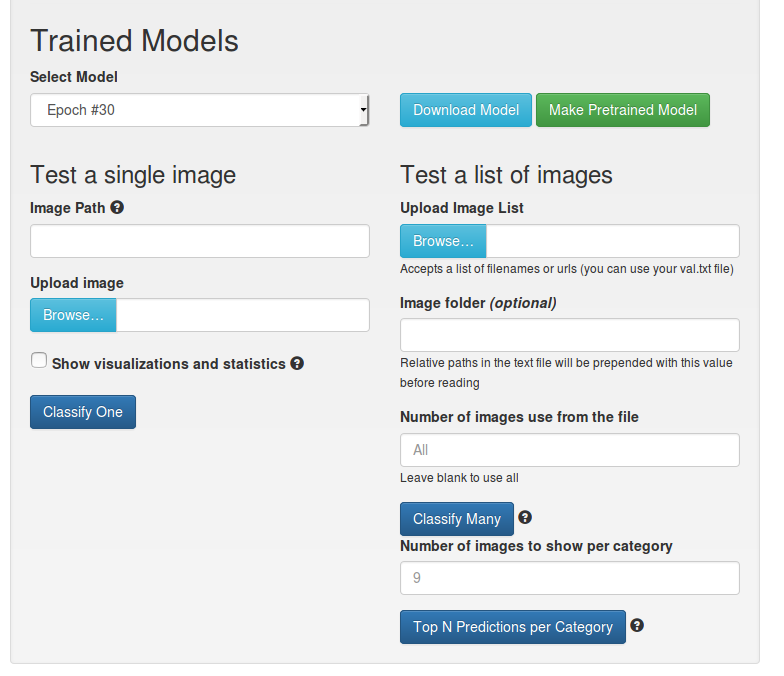
You can send in production;)
What else
DIGITS still has a good mesh for detecting objects (descriptions: 1 , 2 ). Tomorrow I will post a separate short article on her account. There, unfortunately, not everything is as good as you want.


It is possible to configure the correct pixel segmentation . But I now have customized solutions - this is not very interesting. And so, a whole example of working with DICOM images:
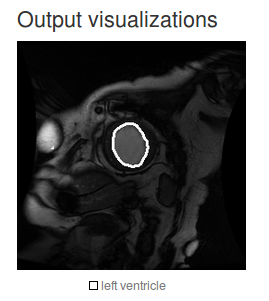
The solution is positioned as suitable for medical data segmentation tasks.
findings
The level of knowledge necessary to work with neural networks is slowly falling below the baseboard. Surely there are other analogues, or will appear in the near future. The same TensorBoard .
This does not mean that the resulting solution is a quality one. But it can work quite well in some situations. Of course, good tuning, method compilation, manual network configuration can significantly improve performance. But to show the prototype, DIGITS may be enough.
For me, it turned out to be a very suitable wrapper. But, something his nvidia is not particularly PR and does not support much.
Source: https://habr.com/ru/post/311832/
All Articles