Docker in work. A look at its use in Badoo (a year later)
Anton Turetsky ( Badoo )

Today, I will invite you to such an internal Badoo kitchen to tell you whether we need a Docker. You will try to draw conclusions for yourself, do you need it. This information on the Internet, respectively, is not, because it is all like this - in our close narrow circle.

')
During the report, I will tell you about the most significant thing that concerns where to start the execution of any task. We must decide why you do it, why do you take it?
For ourselves, we answered these questions, without problems we would have no implementation. Some of the problems we solve. I selected the main ones, I will tell you about them and how we dealt with them. In the end, I will advertise how wonderful we are, how we love all sorts of different bikes, how we make them, look, invent. I will show them to you, I will tell you about them, you will form some opinion of yourself. So let's go!
The reason why we need a service of exploitation, why, in general, we need some kind of business, why we need, in particular, admins.
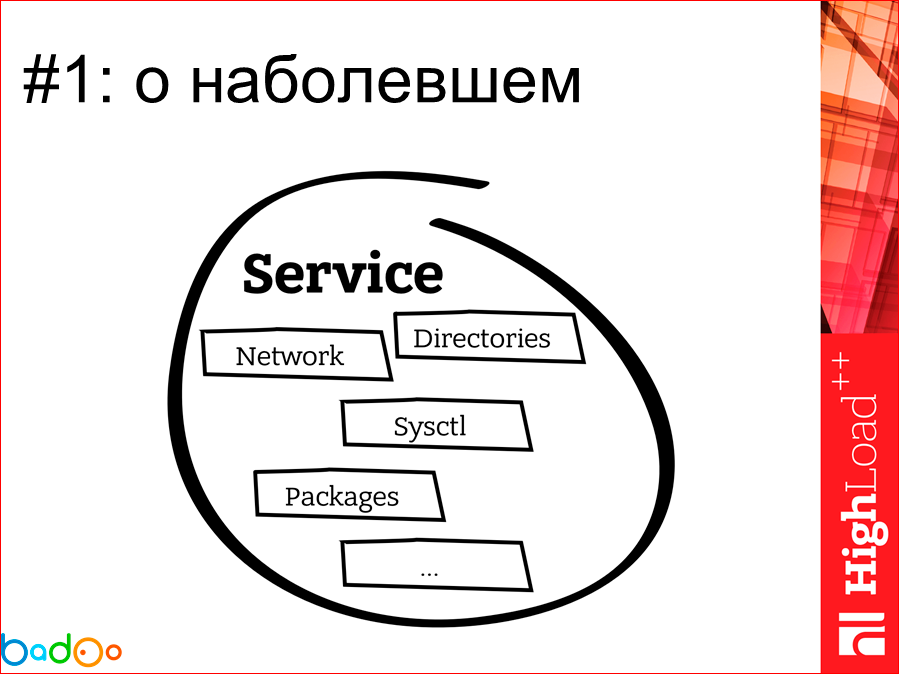
Our main key unit is service. If the service does not work, then why are we all here gathered? In a remote view, the service looks something like this. This is a piece of intellectual property of a programmer who writes some business logic and wants to get something. There are layers of some network settings on the machine, a bunch of RPM packages related and not related to the directory service. In general, this represents such a tangle, which the operation service receives to itself, and the system ticket, or how else the transfer of service from the developer to production is carried out. Our main task is that we need to take one large and powerful server and cram some services on it.
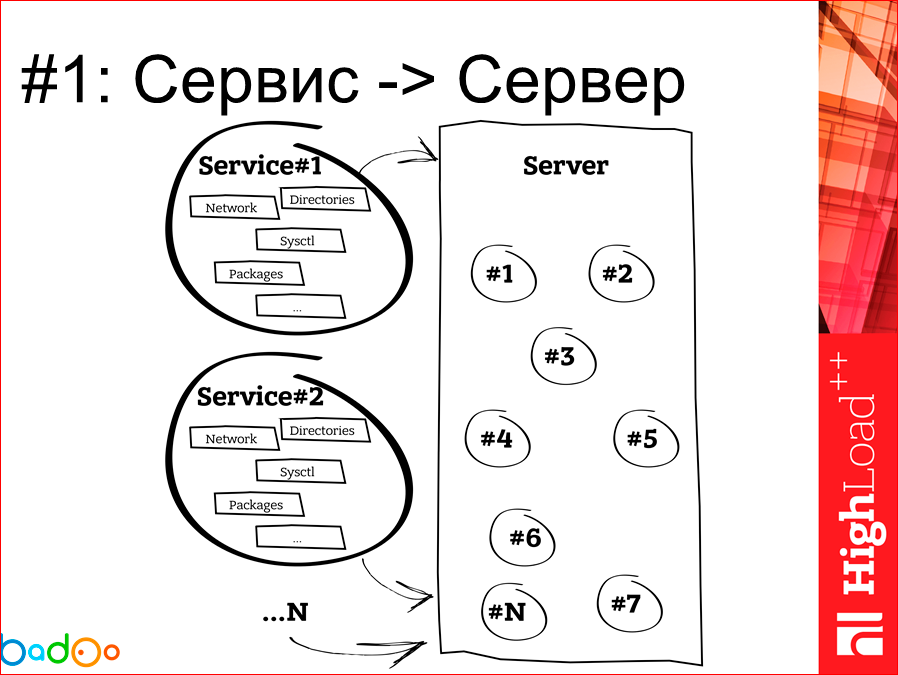
Everything looks great. Over the past few years, the situation has not changed in any way. We both rolled out services in the form of a ball, and rolled out.
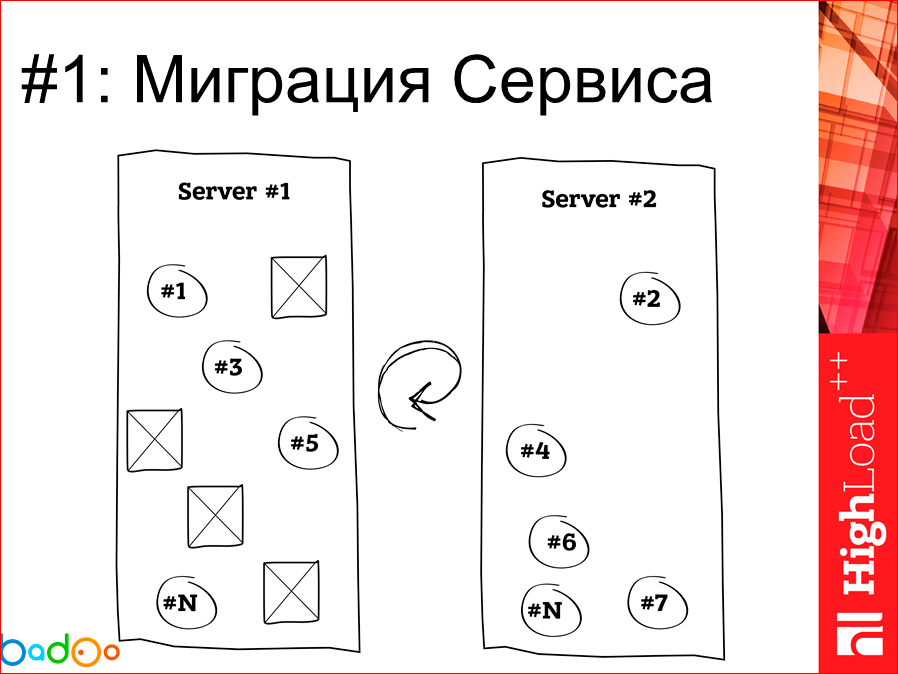
The problem that we have is when we need to take and for some reason settle our services, because the machine cannot cope, a new iron has arrived, we just want to take it and migrate. And the first thing that we get during the migration, if we don’t use, for example, Docker, is that we drag the service onto a clean machine; on a clean new machine, everything is fine, great, the directories are pulled, but one problem ... Who uses a configuration management system like Chef and Puppet, and who rolls them out? And who writes, reverse manifestos on taking everything and everything? In the hall - only three people. Accordingly, everyone who does not write this, I think, knows that in your server eventually there are some holes and pieces of the heritage of what lives there, and depending on the frequency of these migrations, the server grows sooner or later turns into some kind of trash. If we take Docker and do the same migration, then we, like a brick, took out and put it in another place, and nothing old was left there. Wonderful.
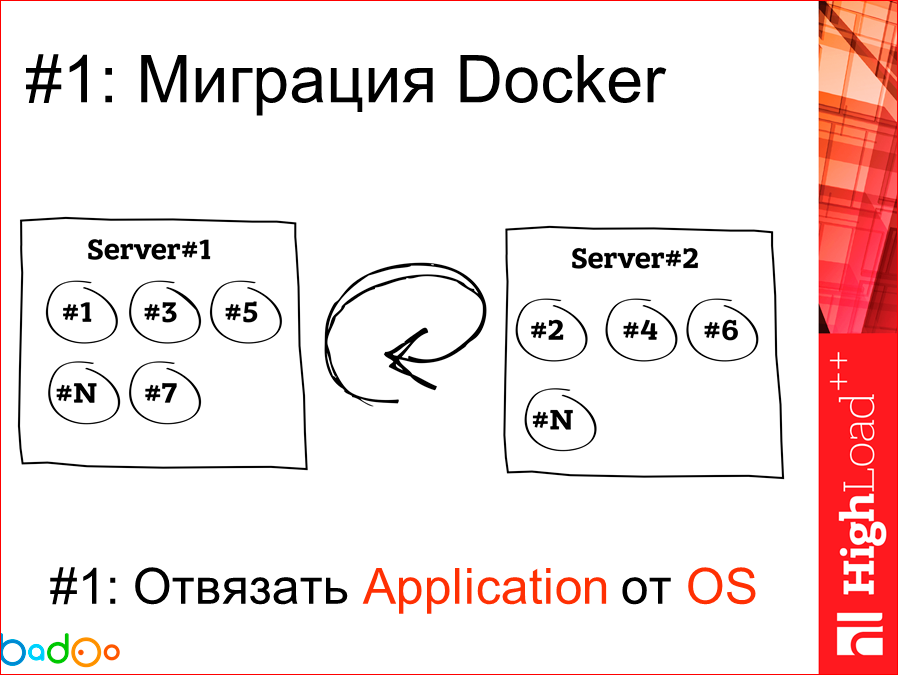
Thus, the first reason that we, in general, began to look at Docker from the exploitation side is the task of untiing the application, collecting it in a ball, from the operating system.
Next moment. Since we are not programmers at all, but still engineers and operators, then thinking about our resources, we always think about hardware. Those. iron is physical some kind of boxes that stand in large rooms, there is cool cooling, we hope that the cleaner does not come there.

And since we place our equipment in dedicated data centers, removing some kind of cage, at a certain point in time we begin to think that the equipment needs to be changed. For a number of reasons, the equipment is newer, it gives us more parrots and units in performance, sooner or later we need to change.

Accordingly, the first problem related to capacity planning, more precisely, is not a problem, but even a task, is that we need to make the most efficient use of space in our racks, because the rack is some kind of return from it, it is a box rental, This is the cost of electricity and in the first place, this is money.

The next conclusion from the first point is that we also want to use the ports on the network equipment as much as possible, because the network equipment is also unit, it also takes up space, it also eats electricity.

We are smoothly approaching the fact that we save electricity, respectively, we saved money, did great for the environment, great. This does not concern us much, but here is a beautiful and wonderful such a positive bonus.

But if we say that we bundle services on a more powerful server, then we get the next item, which I have marked “±” - we come to a situation where, like, we have more options abstracted, more single points of failure. . When you have one service lives on the same physical machine, everything is fine, most likely, we lose less if our server goes down. In this case, this is too philosophical question, because if we are talking about replacing old equipment with new, new, most likely, the system will be less likely to fail than the old one. And many have heard how many problems arise in the process of deployment. Those. in fact, according to statistics, it can be said that getting this Single point of failure, it is much less pianous on your production, than the curve is some kind of calculation.

The third point, why and why we started to look at Docker - this is a thrilling and acute problem; it is to plant your application from the time it was written by the programmer until rolling out into production, without changing anything that the application can be tied to. In case of using Docker, since We initially set up our applications in a certain environment with some kind of libs, packages, even with something, we have it planted with the build process conditionally in the team city. Then we have it in the same original form goes to the Q & A testing process, then we have, through staging, development, our finished application in the container can already go to production. Those. at this stage, we are discarding some changes ... If you have a problem with the application, and the different environment of this application is on development, on staging and on Q & A testing, then it’s pretty hard to understand what affects our application in general, that it does not work, i.e. We have solved this problem here 100%.

And the last item that I marked as an item with an asterisk, because initially, when I saw the Dockerfile, it seemed to me that this was some kind of return 10 years ago. Incomprehensible bash, no bash, something needs to be written when there is a puppet, why write these txt files? But in fact, plus of this is that always, looking at the neighbor's config, you can see what the person was doing and why, what he might have thought about, and knowing how the Docker works and looking at such Docker files. , you can sometimes change this file to optimize the process of overlaying layers, doing something, using caching. Those. in fact, Dockerfile is a good, up-to-date documentation for your application.
So, we answered the question for ourselves, why we wanted Docker and, introducing it, we always return to these letters and see: decided, not decided, applies, does not apply?
Next is an interesting point that began with the process of implementing Docker with us. Of course, we faced problems. Some of these issues were discussed at Github Docker, etc. The part is solved, the part we have not caught yet. I think they will come after us.

The first interesting problem was that we want to collect the logs of our application, at least somehow centrally. We faced the challenge: “make us some syslog, programmers want to write to / dev / log, then we will send it somewhere, process it, etc.”.

We sat and thought: how can we get the second service in the container? The initial idea: one container - one service working in it. Wrong. Dilemma arises. What to do?
It turns out +1 service which should be pushed into each container, to guarantee its work because they ask from us if logs were not delivered there. This is a sub-clause that justifies laziness that something must be taken and done. And the task, which, as usual, we need yesterday. We need to already collect logs from the programmers. The part of processing these logs is ready, we just need to take and do it. Accordingly, the first thing that was invented and what we began to use was we took the dev / log socket inside the container and started writing there. Cool!

We decided, agreed, rolled out, works fine. Messages go. Before the first problem, when we had to change the config'i and syslog on the hosts and reload it. So containers continue to hold the old socket, write something there, messages do not go anywhere, they remain there. What to do?

This problem is a good case, which suggests that you do not forget about the first calls of your decisions, which were at the first stage. In this case, we had to go back, back to the idea that "let's make a syslog inside the container, God bless her, with this idea that one service is one container." And nobody told us physically about one service, that is, perhaps, the functionality of one service works there, and there are more processes. We pushed syslog into the container, the config of this syslog doesn’t change, in fact we don’t need to support anything except the current version, because from syslog we send a helmet to the local host of the machine where it starts up, and then we’ve got it from syslog 'and this machine is sending data to some of our central repository with logs.

The next interesting problem that concerned the fact that in the container we need some kind of directory, relatively speaking, to add or some kind of block device. It seems to be simple, there is a -v key, which you prescribe, add, everything works for you. And there is a feature in our company that we use some loop devices to distribute our code, and then we mount it with the -o loop. We have an abstract block device, we start the container, map some device there under the directory from this loop-device. Everything works fine and due to the features of Docker, that every directory, every file that he tries to put inside himself, he goes through the entire chain of mount points and drags the entire proc / mount, which he now needs to run in that state. about which you speak to it, all proc / mount drags behind itself.
Further, the very essence of the problem, I think, for everyone it becomes clear and obvious that we want to unmount this loop-device so that we don’t have 12-20-50 on the machine, we don’t need the old weekly code. And what do we get here? We get a situation where we have a process holding a block device, and we cannot unmount it. To do this, we need to go, go into the container and try to unmount it there. But since we start the container in the “no privileges” mode, we cannot make umount from the host system there.

And we have a rather interesting problem, which suggests that with the container we can only do a restart. This is not a solution, it is really a big problem, in principle, the solution of which may not be a technical one, but in the form of some kind of agreements within the organization.

Accordingly, the first solution that can come up, it basically works - it is to take and run the container in privileged mode. We do not do that.
The second is to sit down and think, with different departments, with programmers, with the release team, with someone else about what and how we can do to prevent us from arranging these dynamic mount points, let us somehow refuse them.

Those. This is one of those cases when you just need to sit down and think about what is possible to do. Any structural internal arrangements and changes that will solve this problem. Those. It did not make sense to fight about the problem from the technical position. In the case of Docker containers, we simply stopped using such dynamic loop devices.

The following interesting rakes are related to iptables, with nf_conntrack. What does Docker give us when we read about it? He says that we can run as many containers as we want, we can use a huge number of ports, we can arrange connections between containers inside, we get some kind of isolation. Everyone says that it will be, of course, through iptables, there are such rules that you can register if you forgot to specify them at the start in the container. But no one speaks explicitly about one thing - that in this case we are obliged to use the linux module nf_conntrack, which I myself would not call fast.

There are two ways in which we can solve this problem.
The first way, if your application is not very loaded on the network, it is to live as it is. Everything is fine, everything works, until you hit the nf_conntrack table overflow. What can we do to prolong our life? Enlarge the nf_conntrack table.
Further, this is such a causal link - if we increase the conntrack table itself, then we must increase the hash table of connections so that there are more of them than they are by default in the Linux kernel.
It is worth remembering about the third item, which by default in Linux stores about 10 minutes, all connections are established, already worked out. In fact, for modern service, I think that more than 30 seconds. after creating a connection, if something did not happen, then either the service is bad or the connection is simply not needed. Therefore, 10 minutes is a real overkil.

With this approach, as practice has shown, we can sit and wait. But sooner or later the problem will arise, and it will arise for sure. And at some point, these increases simply will not help, due to the fact that due to the slow work of conntrack, nothing will be done better.

How did we solve this problem for ourselves? The first thing I want to say is that we do not use conntrack, we try not to use it in the production environment, in our services. We use it in the part of the dev, we use it on staging, because there the amount of network exchange is much less.
From what I would suggest to look at, this is a wonderful Weave project that allows you to build network interactions bypassing network equipment, i.e. This is a more software solution between your Docker-hosts. The simplest solution is to use the default bridge, which, when launched, can generate Docker. You can also use the built-in Linux bridge configurator. And if you want beauty and a little more flexibility, there is a great joke - Open vSwitch. At the moment in the list of plugins for Docker there is no control for Open vSwitch, which is a pity, they promised last year.

As I said earlier, for ourselves we decided it in such a way that we practically use the launching of the network device from the host system into the container and we get rid of conntrack when we start all our containers. I didn’t put a stamp on the problem that I solved, because this is such a problem that is worth thinking about. For ourselves, we solved it this way, someone, maybe, will solve it differently.
The next interesting moment that most of those who had to deal with at least Docker had to deal with was the choice of the Storage Driver in order to store files. Because everyone has pros, everyone has disadvantages. There are AuFSs with which they entered the market and offered them, but which never entered the mainline and never will. There is a cool solution to the problem when you take logical devices, mount them, i.e. This is a Device Mapper plus some kind of built-in file system, conditionally X3. You are engaged in this mounting - remounting ... All this grows into such a generally huge chain of these layers and logical devices. There is BTRFS, which is half the functionality needed for Docker, supports by default precisely as the underlying functionality of the file system. And there are several other pieces that are implemented by some plugins, some are cool, some are not. Here I noted the three things that I had to work with, and among which I had to choose.

And we also look at the problems that BTRFS can cause. BTRFS requires you to keep some kind of block device that will be the rootdir for Docker on BTRFS. Not every partition partition table on our server contained BTRFS, respectively, this obliged us to deal with the re-release or re-sniping of LWM and highlighting this partition.
Secondly, no one hid the fact that BTRFS never makes a resink directly to disk, he never writes directly to a block device, he first keeps some kind of his own journal, writes information to the journal, then the nuclear process of BTRFS itself starts, which looks at this queue makes some gestures and writes something down somewhere. In practice, according to our measurements, the performance of using BTRFS turned out. Somewhere we have a block device on the 10th raid, and we got from it somewhere divided in half - this is what BTRFS gave us.
A very urgent problem for the monitoring service, the operations department is how to understand how much space is occupied by BTRFS, how much is free? And the biggest problem is when you have a place, it seems, but there’s no place like it - it has gone somewhere, and you understand that your meta-date is swollen, files are busy, like, a little, and you need to run rebalance, and you are close to the peak and IO and so suffers, but also rebalance. Sadness

Of the benefits of BTRFS over the past year or two - this is the only storage driver that is normal and, at least, expectedly worked with Docker. It seems like the problem was solved, BTRFS is our choice. Let's buy SSD, we will live, God bless him with performance, let's figure it out.

And here not so long ago we looked towards the new Storage Driver - OverlayFS. Looking ahead, I will say that we are engaged in its implementation, we have already passed the testing stage, we received some tests, the tests are quite good.
Why did I leave the FS gray and Overlay reddish it? Since version 3.18, it entered the kernel under a different name, it entered the kernel under the module name just Overlay. Does anyone know what the OverlayFS module is built into for a long time already in the core? I do not know either. There will be no new slides about Overlay, I will tell you the information that was ready just last week. According to our tests, the speed of response using OverlayFS based on EX4, in percentage terms, we have Docker overhead within an error of up to 3-5%, not more, i.e.for ourselves, we consider it the next point and the next point where we will begin to migrate and do. The only minus that it imposes on itself is, again, the kernel 3.18, at least, i.e. need to be updated, we must go ahead.
Overlay FS works relative to BTRFS in order to arrange these read-only layers, it uses hard links. There is one more plus in comparison with BTRFS, which is that your operating system can use the file cache in RAM. But if you use BTRFS, because there are subvolums and even if the file is, like, deduplicated, and, like, you understand that the file is one file, from the Linux OS point of view, the file is different. And if from the same container and from the other container we request the same file, it seems, it will most likely not remain in the cache or two different caches will appear for this file. Overlay saves us from this. As I said, performance is obtained in read / write very similar to the capabilities of the native file system, why not? And for exploitation,and for monitoring, and for all the old DF continues to work. We know how much we have there, how much is free. Cool. Those.there is no this puzzle, no rebalance is needed, great! I believe that this is our future solution to the problem and those who have not tried it, I urge you to at least just look at this driver.

Further generalized non-highlighted problems encountered. They consist in the fact that we have moved away from the idea that only one service or one service can be launched in one container. But then the question arose of choosing how to run more than one, i.e. there is a cmd, but what levers do we still have to run something else?
The first thing we decided was to write a crutch for the Entrypoint, where we start up some crowns, etc., prepare our container before launching, start some background services and then transfer control to the Docker cmd instruction and start our basic service.

Sinceit all looked like some kind of crutch, and it was scary to support him, and every entry from the operation team wrote an entrypoint on their own — they were very different depending on their mood. It was necessary to look for some more unified approach. And from what we saw, the choice fell on the S6, and we are using it now. I left the coordinates of the project, this is a kind of init-manager to work inside the Docker-containers. It allows all the basic things that, at a minimum, we need, i.e. It allows you to start, make a stop. Depending on the stop, you can complete the container or not, you can execute some set of commands before starting the container and before stopping it. Everything is pretty good. For those who are interested in the tasks and problems of running more than one service in a container, I recommend looking at this.
Such a semi-problem, half-no, and the question also arises - is it possible to use several From in Dockerfile. The answer to this question during the year changed three times. Moreover, dramatically.Yes, no, no, yes - depending on the Docker version. In our experience, I can say that you can use it until the first problem, when you have a hierarchy of layers of one image that does not intersect with the hierarchy of another, and you suddenly lose some file. Those.you will think that he is there, and he is not there. And you will lose some amount of time in search of why he is not there, and he should be. Those. I would recommend not to use.
Another interesting problem that we have recently encountered is that we recently learned about it. This is such a cool feature in Docker from version 1.6, in my opinion. They took and did the docker.exec command where you can take and execute something, unload the container from the host system, and look at the result. Everything is cool, but not so long ago it turned out that this exec was made, in general, for debugging, development-mode, i.e. he didn’t assume that you could run some monitoring things from the host system that find there worked something like that, looked for it, cut it. And the problem was that in Docker inspect, if you look at the name-space of a specific container, all the execs, all their urls, by which you could look at their result, they lived as long as you the container will not reload. Starting from 1.7, or rather from version 1.8, they made some garbage collector, which looks in the old manner, if there are dead dead unnecessary execs, and cleans them. This was a really big problem, because if you look at memory consumption, over the course of days, weeks, the memory just grew and grew, it is not clear why.

General advice, if you have any problem, try to ask somewhere and look for a solution to this problem, because the Docker, by itself, is developing very quickly, and there a lot of things change. It happens when you try to decide what others have already decided a week ago or in a previous release, or simply something else did not enter the master.

The main point in our company is the basic image, against which we are rolling out our application with some instructions. Accordingly, it is not just a problem area for us, but it is the only point in all of this containerization that it makes sense to follow.

How are we following her right now? We need to check that all the packages, necessary patch sets for our basic image are present, so that we don’t roll out a well-known hole, for example, to production. How do we solve this problem? We take on some crown or launch our container interactively for some time and, using zypper or what else we can think of for some other OS, we simply check for any updates on all our repositories. and, if they are, we pass this information in the form of a ticket to the team of service operators, who decide whether to update it further or not. If you update, we update the base image and roll it out to where we are building. If there is a need, and some serious patch, we need a fix, we go, we update the container we need.

And before we, in general, roll our application to production, we make a comparison of our, let's say, the current RPM-list of packages and their versions, which should be with what is present in our newly created container. If something does not converge, we go back to the branch at the time of assembly, testing, etc. Those.until we get here the conformity of the fact that we agree with such a set of production versions, we accept it.

In order to somehow assemble our applications, it is clear that we will not write with our hands every time and change the Dockerfile version of our basic image. We need some kind of automation. We made this automatics by resorting to the use of puppet. We called it just docker_build.

What requirements did we put on our automation? We wanted to generate a directory and configs structure for a particular service. We wanted to teach and taught him to do the Dockerfile instruction automatically. We wanted to deliver / pull out the executable files of the application itself from our systems, assemblies of our services, and put them side by side. We wanted, of course, that he perform the assembly. Send the result to the Registry, and with the ability to either send or not send, because there something may go wrong, we just wanted to locally see what it will collect there. And the necessary functionality was that we wanted to allow the one who collects the container to do it by hand.

Services we roll out as follows. The JIRA receives the problem that our developers have decided that they have assembled a new version, and they want it for production. They set us the task. The container is automatically collected at that time, he says that the status is “collected”, everything is fine. In this interface, we have the functionality, if we changed some configs in puppet, we want to rebuild. Those.if we need a container, not the one that we collected, sent, and with other config'ami, we can do it here. The next, second step (on the slide) is to make sure that the reassembly team is sent, and if everything went well, we get some success with the address and link of our new container in the registry, from where we can pick it up.
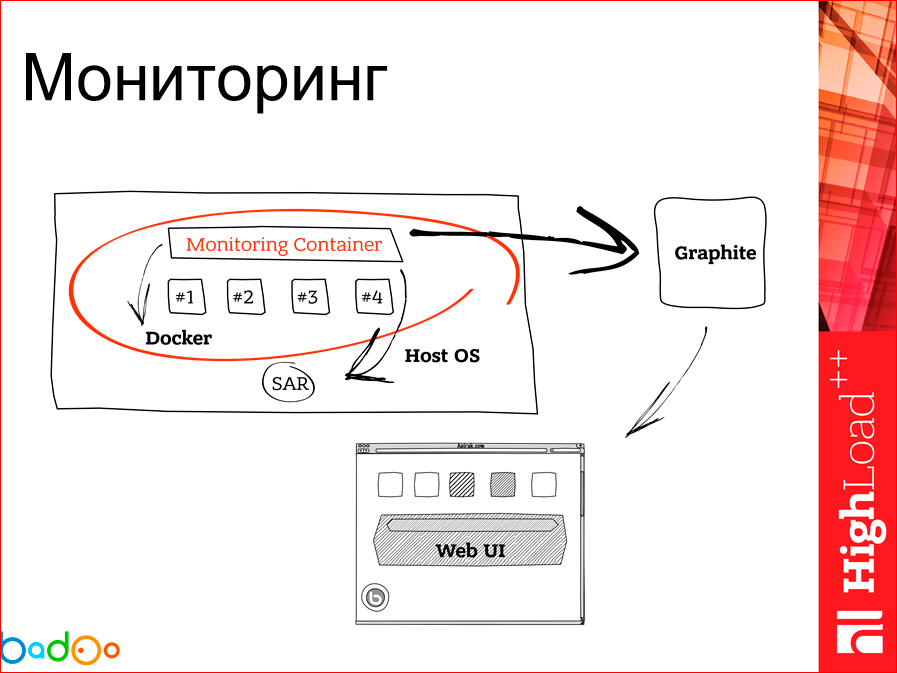
Docker host and container running on it, there is a need to monitor. To solve this problem, we in this case wrote down the first bike, which is the image of the container on each docker host in which we collect some information. The general scheme is as follows; we collect information on the container, send it to Graphite once in a while, and there we draw a beautiful interface.

What does this monitoring container look like? We have a Docker CLI inside, because we need to collect statistics through docker stats, on the CPU and on memory for each container. And we default on our SAR servers and run our monitoring container. We diru SAR'om pull up. Once in a while, our docker monitoring container starts a stat aggregator, which needs to be sent to Graphite. Sticks her there. Couldn't send? Next pass. He will check if there were any impressions on the FS, will send the second run. Then we draw it on Graphite. The container itself, that it is running, that it, in general, is on the Docker host, we monitor with Zabbix.

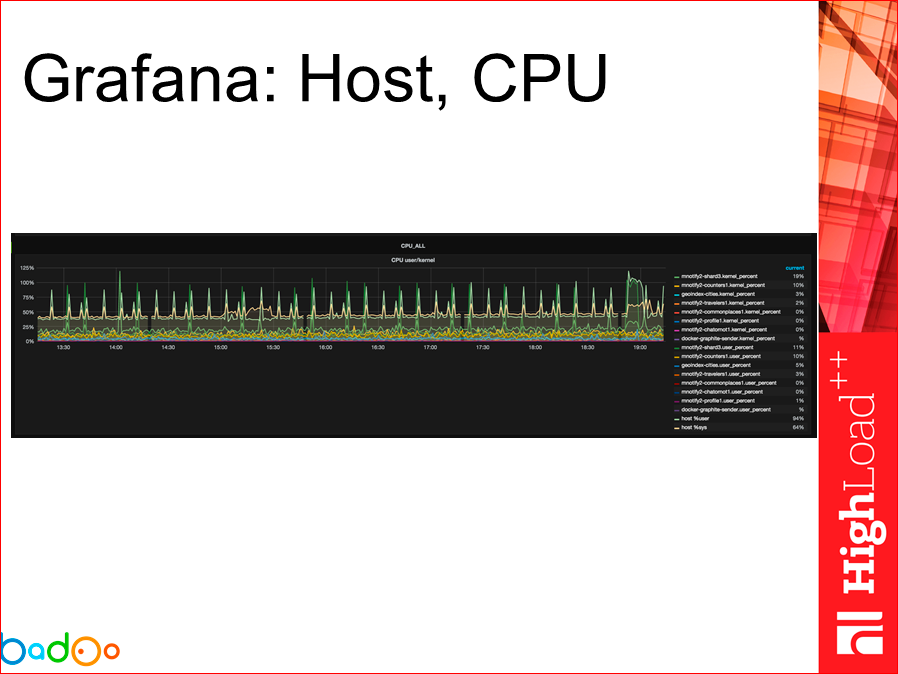
In general, the graphs are approximately as follows. There are many of them, they are not very readable, but, I think, the graphs saw everything. This is how we see information on the memory host, we can look at each container and information, in general, about the host on the CPU.
We can watch the use of the network, etc ...
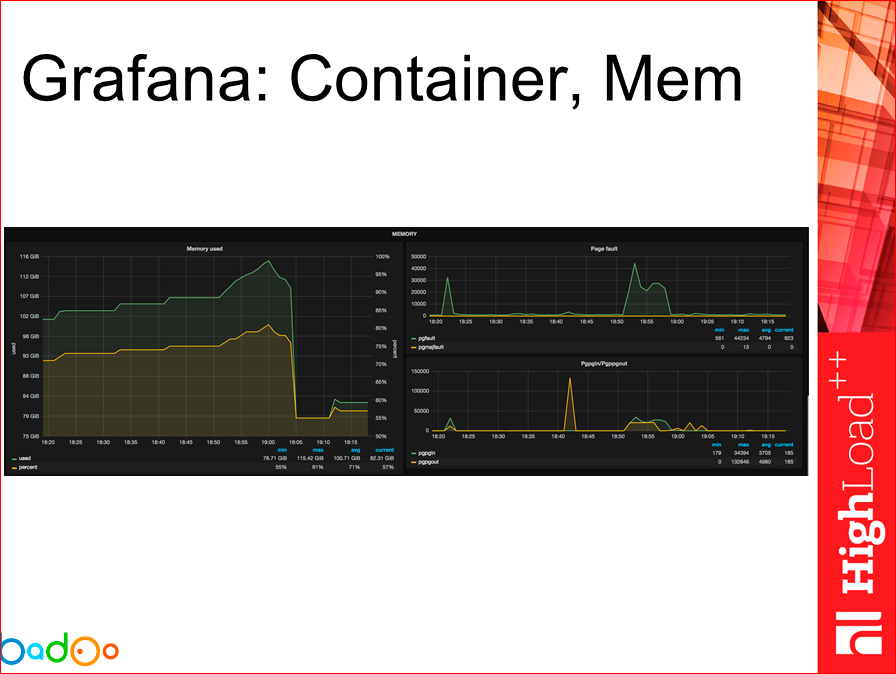
On this slide, the picture is already about what is happening with the container itself, getting rid of the host itself.
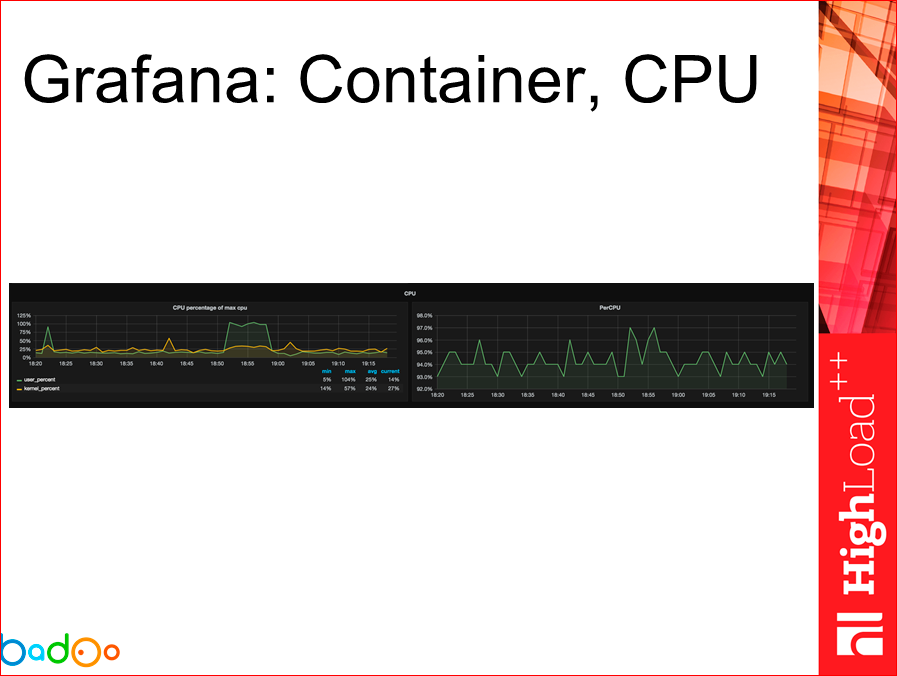
The same can be said about the CPU.
And the last moment I would like to touch on is the invention of another bicycle for orchestration, for managing our containers, because, choosing, we did not choose any of the ready-made solutions. I will not dwell on the decisions that we have considered, if it is interesting to someone, it will ask later. I will say which set of requirements we expressed to our baDocker in order to start developing it.

- The first thing I didn’t like when we looked at ready-made solutions was the presence of another container that needs to be run on each host
that will collect something there and manage it. The first trick is Clientless. We do not need any client, we have a Docker API, why
do we need something else? - Registry – . 1 2, Registry. AND
Docker, Registry v2. - , - , ( ). , ,
. - , - , « , ,
, ». , . - And the last thing I would like to see is the Dashboard, which says that "you have so many hosts, there are possible problems there, impossible there, if
necessary, go see."
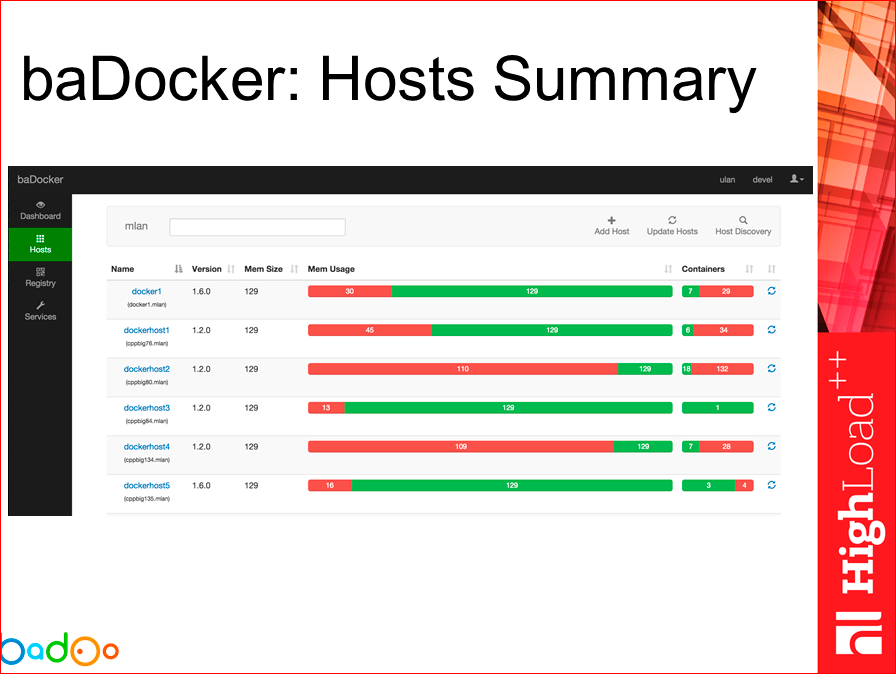
At the current time, it looks something like this. Those.we can see Summary for our hosts, for each site, how much memory is there, how much is occupied, how many containers are there, how much is stalled, how many works.

We can go in and see in detail which containers, from which images we are running. We can also tick, see which version a particular service works for us.

We can go from this interface to any container, write something there, get some kind of output, for example, “do not connect anywhere through the shell” ...

In our services we can see what types of this service are, what versions there are, on which servers are running one or another version of this service.

And we can use such hints in the form of templates, how can we launch the container for this service, i.e. we click on the type we need and see - here’s a hint: “go, run like this, if you need to do it with your hands”.

In conclusion, I would like to say the following: using any tool, in this case Docker, I would recommend using a certain approach, look at the box outside the box on some things and, while doing this, take into account the problems of other people who solved these problems or advise how they decide. And, of course, I wanted to say that reinventing bicycles is not a shame, it is cool and interesting, if only the wheels are not square on your bicycle.
Contacts
» A.turetsky@corp.badoo.com
» Badoo company blog
— HighLoad++ . 2016 — HighLoad++ , 7 8 .
HighLoad++ 2016 DevOps, docker', :
- 5 PHP- / ;
- Aviasales: docker / ;
- Docker- /
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/311830/
All Articles