96 cores and optimization code ant search route
Today we will talk about code optimization that implements an ant algorithm for finding optimal paths on graphs. We will look for bottlenecks in the program using Intel VTune Amplifier XE 2016 Update 2, and optimize using MPI , OpenMP and the library of Intel Threading Building Blocks.

Our goal is to achieve effective work of the program on a computer with four Intel Xeon E7-8890 v4 processors . The system is equipped with 512 GB of RAM, it is installed with Linux 3.10.0-327.el7.x86_64, the code was compiled using Intel Parallel Studio XE 2016 U2.
The problem of finding the optimal route in the transport network is known as the “traveling salesman problem”. In practice, it is, for example, finding the best ways to transport goods. Initially, “efficiency” in such tasks meant choosing the cheapest way, but over the past few decades the concept of “route cost” has expanded. Now they include the environmental impact, the price of energy, and time. In addition to this, the globalization of business and supply chains has led to the fact that the size and complexity of transport networks, and therefore the models on which the calculations are based, have increased significantly. Now, typical route optimization problems are classified as NP-hard. Usually, deterministic methods are not suitable for solving such problems.
')
With the development of distributed and multi-core computing systems, heuristic methods for solving problems have been developed and successfully applied, in particular, the so-called ant algorithm (Ant Colony Optimization, ACO). Now we will look at the process of analyzing the basic implementation of ACO and tell you about the gradual improvement of the code. Looking ahead, we note that our optimization technique allowed us to bring the program to performance and scalability levels that are close to theoretically achievable.
Let's talk about the algorithm that is used in our program. It is based on the behavior of an ant colony. Insects look for food sources, marking the paths covered with pheromones that attract other ants. Over time, the pheromones evaporate, that is, the longer paths become less attractive than the shorter ones, or those that can be reached quickly. As a result, the shorter or faster the path, the more ants he is able to interest, while each of them, passing along the path, makes it even more attractive.
The figure below shows an example of a transport network. Solid lines mark direct routes between nodes, dotted lines indicate indirect routes.

Sample transport network
Simple computer agents are able, using a probabilistic approach, to find solutions to transport problems using an ant algorithm. Parallel implementations of this algorithm, differing, however, by some limitations, have already been investigated in the past.
For example, in 2002, Markus Randall and co-authors published a material (A Parallel Implementation of the Ant ColonyOptimization, Journal of Parallel and Distributed Computing 62), which shows an approach to parallelizing the problem, which led to an acceptable acceleration of calculations. However, in this implementation, in order to maintain the matrix of pheromones, a large number of interactions between “ants” were required, which operated in parallel, and each of them was an independent unit of the model. As a result, the performance of the solution was limited to the message passing interface (Message Passing Interface, MPI) between the ants.
In 2015, the material was published (Veluscek, M., T. Kalganova, P. Broomhead, A. Grichnik, Composite goal systems for transportation, Expert Systems with Applications 42), which describes the method for optimizing the transport network using technology OpenMP and shared memory. However, this approach is well suited only for systems with a relatively small number of cores and threads.
Here is a block diagram of the basic architecture of the parallel implementation of the ant algorithm. It was with her that we began the experiments.

Scheme of non-optimized implementation of the ant algorithm
This diagram shows how many “iterative” processes start each “month”. In each of them, a group of “ants” is released into the network, which build pheromone matrices. Each iterative process is completely independent, it is executed in its own thread.
It uses a static distribution of tasks, each OpenMP thread performs its part of the work, finding a local solution. After all threads have completed execution, the main thread compares the local solutions they have found and selects the best one that becomes global.
One of the fastest ways to find out if an application is scaled effectively with an increase in the number of cores available to it is as follows. First get a baseline performance on a single processor (NUMA node). Then this figure is compared with the results of performance measurement when running on multiple processors, moreover, both with the use of Hyper-Threading technology, and without it. In an ideal scenario, assuming that performance depends only on the number of cores, a two-socket system should show performance that is twice as high as the performance of a single-core system. Accordingly, four sockets should give a fourfold increase in performance.
In the figure below you can see the test results of the basic version of the application. Now our code is far from ideal. After the number of sockets has exceeded two (48 cores), the program does not scale very well. On four sockets with Hyper-Threading technology enabled (192 logical cores), the performance is even lower than when using a single socket.

Testing the basic non-optimized implementation of the algorithm
This is not at all what we need, so it's time to explore the program using VTune Amplifier.
In order to find out what prevents the application from working normally on multiple processors, we will use the VTune Amplifier XE 2016 Hotspot analysis. We will look for the most loaded sections of the program. The VTune Amplifier used the reduced workload (384 iterative processes) to limit the size of the data collected. In other trials, a full load was applied (1000 iterations).
The figure below shows the VTune report. In particular, we are interested in the indicators in the Top Hotspots group and the Serial Time indicator, which allows us to find out the time spent on the sequential execution of a code.

Top Hotspots Report
The report shows that the application spends a lot of time on the sequential execution of code, which directly affects the parallel use of system resources. The most loaded section of the program is the module for allocating memory from the standard library for working with strings, which does not scale well enough with a large number of cores. This is an important find. The fact is that OpenMP uses one shared memory pool, so a huge number of parallel calls from different threads to the string constructor or to the module for allocating memory for objects (using the new operator) make memory a bottleneck. If you look at the CPU Usage figure below, you can find that the application, although it uses all 96 available cores, does this inefficiently, loading them only in short periods of time.

CPU usage
If you look at what the streams are busy with, we will see that the load on them is not balanced.

Unbalanced load
So, the main thread (Master) at the end of each “month” performs calculations, and the remaining threads do nothing useful at this time.
Now, after analyzing the code, we will deal with its optimization.
In order to get rid of a large set of OpenMP threads that is present in the base implementation, we used the standard master-slave approach and added another level of parallelism to our application. Namely, now MPI processes, executed in parallel, each of which, in turn, contains a certain amount of OpenMP streams, are responsible for the calculations within the framework of individual iterations. Now the loads associated with the allocation of memory for rows and objects are distributed across MPI processes. Such a hybrid MPI-OpenMP implementation of the ACO algorithm is shown in the flowchart below.

Optimized implementation # 1
Test what we did with VTune Amplifier
We are exploring an optimized version of the application using the same method by which we studied its basic version. The figure below shows the Top Hotspots report, by which one can judge that the program now spends less time on operations to allocate memory for lines.

Top Hotspots Report
And here are histograms of processor utilization in the base (left) and optimized version of the program.

CPU usage histograms
Here is what the loading thread looks like now. It can be seen that it is balanced much better than before.

Balanced load
In the figure below you can see that all the available 96 cores are loaded almost completely.
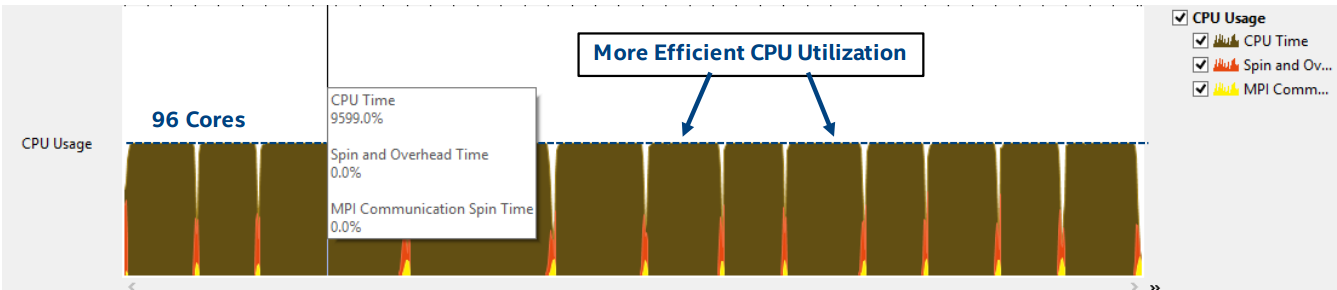
CPU usage
Unfortunately, so far too much time is spent waiting on OpenMP threads and exchanging MPI data, when the MPI process that finds the best solution sends data to the main process to update the file with the results. We assumed that this was due to the fact that the system was overloaded with MPI communication operations.
MPI uses a distributed memory interface, with each process working with a separate memory pool. As a result, the modification of objects and data structures by one process is not visible to others, but the data between processes must be transmitted using the MPI Send and Receive mechanisms. The same applies to the transfer to the main process of the best solution found in the current "month".
The found global solution is a complex C ++ object, which consists of a number of objects of derived classes, smart pointers with data and other objects from the STL template. Since the default MPI communication operations do not support the exchange of complex C ++ objects, serialization is required to use the Send and Receive mechanisms, during which the objects are converted to byte streams before being sent and then received after, the streams are again converted to objects.
The load generated by serialization is constant. It occurs, at most, once a month (or does not occur at all if the main process having rank 0 finds the best solution that will be recognized as global), regardless of the number of MPI processes running. This is very important in order to minimize the communication operations of MPI during the transition to the execution of a program on multiple cores.
In the figure above, additional loads are highlighted in yellow (MPI communication operations) and red (standby and overload).
The hybrid MPI-OpenMP version of the program showed much better results in terms of load balancing between MPI processes and OpenMP threads. She also demonstrated a much more efficient use of the large number of cores available on systems with Intel Xeon E7-8890 processors. Here are the results of testing the current version of the program in comparison with the base.
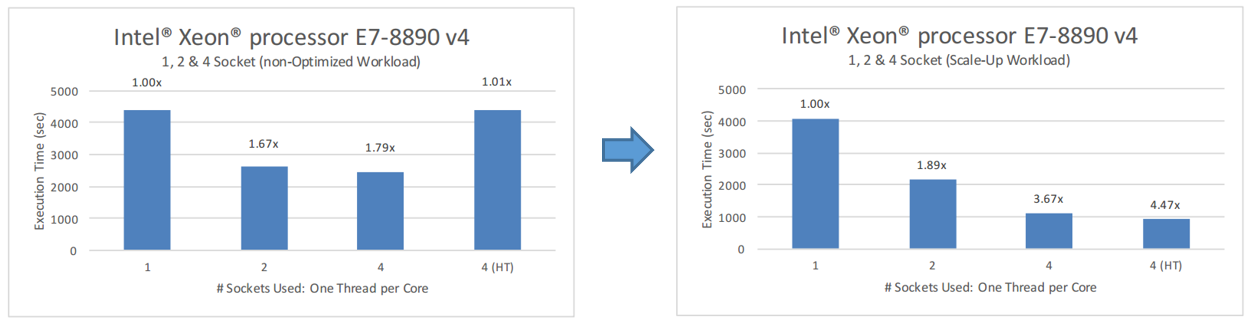
Comparison of the results of the basic and optimized versions of the program
Here you can see that the program scales much better with an increase in the number of available cores. Productivity growth is also observed when Hyper-Threading is enabled.
We achieved quite good results, but the work on optimization has not yet been completed. We use the Intel TBB library to further improve the performance of our code.
Studying the most loaded parts of the code for the hybrid MPI-OpenMP implementation of the application, we noticed that a significant proportion of the execution time still falls on the standard library for working with strings. We decided to check if the use of the Intel TBB dynamic memory allocation library would improve the situation. This library offers several memory allocation templates that are similar to the standard std: allocator class from STL, and also includes scalable_allocator and cache_aligned_allocator. These patterns help solve two critical groups of parallel programming problems.
The first group is scaling problems. They arise from the fact that memory allocation mechanisms sometimes have to compete for a single common pool, and, due to the original sequential device of the program, only one thread can allocate memory at a time.
The second group of problems is related to the general access to resources. For example, it is possible that two threads try to access different words of the same cache line. Since the smallest unit of information exchange between processor caches is a line, it will be transferred between processors even when each of them works with different words in this line. False sharing can damage performance, as moving a cache line can take hundreds of clock cycles.
One of the easiest ways to find out whether an application will benefit from using Intel TBB is to replace the standard dynamic memory allocation function with a function from the Intel TBB library libtbbmalloc_proxy.so.2. To do this, just load the library when the program is started using the LB_PRELOAD environment variable (without changing the executable file) or link the executable file with the library.
Solving the most important scaling problem that arises when using standard memory allocation mechanisms, the dynamic memory allocation library from Intel TBB provides an additional 6% performance compared to the hybrid MPI-OpenMP version of the application.

Performance Improvement with Intel TBB
At this stage, we decided to study the effect on performance of various combinations of MPI processes and OpenMP threads with the same load. All 192 available logical cores were used in the experiment, that is, 4 processors were involved and Hyper-Threading technology was turned on. During the tests, we found the optimal ratio of MPI processes and OpenMP threads. Namely, the best result was achieved using 64 MPI processes, each of which executed 3 OpenMP streams.

Performance comparison for various combinations of MPI processes and OpenMP threads.
The study of the basic parallel implementation of the ant algorithm made it possible to identify problems with scaling associated with the mechanisms for allocating memory for strings and object constructors.
The first stage of optimization, thanks to the use of a hybrid approach using MPI and OpenMP, allowed us to achieve a better use of processor resources, which significantly increased performance. However, the program still spent too much time allocating memory.
At the second stage, thanks to the library for dynamic memory allocation from Intel TBB, it was possible to increase productivity by another 6%.
During the third stage of performance improvement, it was found that a combination of 64 MPI processes is best suited for our program, each of which runs 3 OpenMP threads. At the same time, the code works well on all 192 logical cores. Here are the final optimization results.

Optimization results
As a result, after all the improvements, the program has worked 5.3 times faster than its basic version. We believe this is a worthy result, which is worth the effort spent on research and code optimization.
Our goal is to achieve effective work of the program on a computer with four Intel Xeon E7-8890 v4 processors . The system is equipped with 512 GB of RAM, it is installed with Linux 3.10.0-327.el7.x86_64, the code was compiled using Intel Parallel Studio XE 2016 U2.
The problem of finding the optimal route in the transport network is known as the “traveling salesman problem”. In practice, it is, for example, finding the best ways to transport goods. Initially, “efficiency” in such tasks meant choosing the cheapest way, but over the past few decades the concept of “route cost” has expanded. Now they include the environmental impact, the price of energy, and time. In addition to this, the globalization of business and supply chains has led to the fact that the size and complexity of transport networks, and therefore the models on which the calculations are based, have increased significantly. Now, typical route optimization problems are classified as NP-hard. Usually, deterministic methods are not suitable for solving such problems.
')
With the development of distributed and multi-core computing systems, heuristic methods for solving problems have been developed and successfully applied, in particular, the so-called ant algorithm (Ant Colony Optimization, ACO). Now we will look at the process of analyzing the basic implementation of ACO and tell you about the gradual improvement of the code. Looking ahead, we note that our optimization technique allowed us to bring the program to performance and scalability levels that are close to theoretically achievable.
About ant algorithm
Let's talk about the algorithm that is used in our program. It is based on the behavior of an ant colony. Insects look for food sources, marking the paths covered with pheromones that attract other ants. Over time, the pheromones evaporate, that is, the longer paths become less attractive than the shorter ones, or those that can be reached quickly. As a result, the shorter or faster the path, the more ants he is able to interest, while each of them, passing along the path, makes it even more attractive.
The figure below shows an example of a transport network. Solid lines mark direct routes between nodes, dotted lines indicate indirect routes.
Sample transport network
Simple computer agents are able, using a probabilistic approach, to find solutions to transport problems using an ant algorithm. Parallel implementations of this algorithm, differing, however, by some limitations, have already been investigated in the past.
For example, in 2002, Markus Randall and co-authors published a material (A Parallel Implementation of the Ant ColonyOptimization, Journal of Parallel and Distributed Computing 62), which shows an approach to parallelizing the problem, which led to an acceptable acceleration of calculations. However, in this implementation, in order to maintain the matrix of pheromones, a large number of interactions between “ants” were required, which operated in parallel, and each of them was an independent unit of the model. As a result, the performance of the solution was limited to the message passing interface (Message Passing Interface, MPI) between the ants.
In 2015, the material was published (Veluscek, M., T. Kalganova, P. Broomhead, A. Grichnik, Composite goal systems for transportation, Expert Systems with Applications 42), which describes the method for optimizing the transport network using technology OpenMP and shared memory. However, this approach is well suited only for systems with a relatively small number of cores and threads.
Basic implementation of the algorithm
Here is a block diagram of the basic architecture of the parallel implementation of the ant algorithm. It was with her that we began the experiments.
Scheme of non-optimized implementation of the ant algorithm
This diagram shows how many “iterative” processes start each “month”. In each of them, a group of “ants” is released into the network, which build pheromone matrices. Each iterative process is completely independent, it is executed in its own thread.
It uses a static distribution of tasks, each OpenMP thread performs its part of the work, finding a local solution. After all threads have completed execution, the main thread compares the local solutions they have found and selects the best one that becomes global.
Baseline Test Results
One of the fastest ways to find out if an application is scaled effectively with an increase in the number of cores available to it is as follows. First get a baseline performance on a single processor (NUMA node). Then this figure is compared with the results of performance measurement when running on multiple processors, moreover, both with the use of Hyper-Threading technology, and without it. In an ideal scenario, assuming that performance depends only on the number of cores, a two-socket system should show performance that is twice as high as the performance of a single-core system. Accordingly, four sockets should give a fourfold increase in performance.
In the figure below you can see the test results of the basic version of the application. Now our code is far from ideal. After the number of sockets has exceeded two (48 cores), the program does not scale very well. On four sockets with Hyper-Threading technology enabled (192 logical cores), the performance is even lower than when using a single socket.
Testing the basic non-optimized implementation of the algorithm
This is not at all what we need, so it's time to explore the program using VTune Amplifier.
Analysis of the basic implementation of the algorithm using VTune Amplifier XE
In order to find out what prevents the application from working normally on multiple processors, we will use the VTune Amplifier XE 2016 Hotspot analysis. We will look for the most loaded sections of the program. The VTune Amplifier used the reduced workload (384 iterative processes) to limit the size of the data collected. In other trials, a full load was applied (1000 iterations).
The figure below shows the VTune report. In particular, we are interested in the indicators in the Top Hotspots group and the Serial Time indicator, which allows us to find out the time spent on the sequential execution of a code.
Top Hotspots Report
The report shows that the application spends a lot of time on the sequential execution of code, which directly affects the parallel use of system resources. The most loaded section of the program is the module for allocating memory from the standard library for working with strings, which does not scale well enough with a large number of cores. This is an important find. The fact is that OpenMP uses one shared memory pool, so a huge number of parallel calls from different threads to the string constructor or to the module for allocating memory for objects (using the new operator) make memory a bottleneck. If you look at the CPU Usage figure below, you can find that the application, although it uses all 96 available cores, does this inefficiently, loading them only in short periods of time.
CPU usage
If you look at what the streams are busy with, we will see that the load on them is not balanced.
Unbalanced load
So, the main thread (Master) at the end of each “month” performs calculations, and the remaining threads do nothing useful at this time.
Now, after analyzing the code, we will deal with its optimization.
Optimization number 1. MPI and OpenMP sharing
In order to get rid of a large set of OpenMP threads that is present in the base implementation, we used the standard master-slave approach and added another level of parallelism to our application. Namely, now MPI processes, executed in parallel, each of which, in turn, contains a certain amount of OpenMP streams, are responsible for the calculations within the framework of individual iterations. Now the loads associated with the allocation of memory for rows and objects are distributed across MPI processes. Such a hybrid MPI-OpenMP implementation of the ACO algorithm is shown in the flowchart below.
Optimized implementation # 1
Test what we did with VTune Amplifier
Analysis of an optimized algorithm implementation with VTune Amplifier XE
We are exploring an optimized version of the application using the same method by which we studied its basic version. The figure below shows the Top Hotspots report, by which one can judge that the program now spends less time on operations to allocate memory for lines.
Top Hotspots Report
And here are histograms of processor utilization in the base (left) and optimized version of the program.
CPU usage histograms
Here is what the loading thread looks like now. It can be seen that it is balanced much better than before.
Balanced load
In the figure below you can see that all the available 96 cores are loaded almost completely.
CPU usage
Unfortunately, so far too much time is spent waiting on OpenMP threads and exchanging MPI data, when the MPI process that finds the best solution sends data to the main process to update the file with the results. We assumed that this was due to the fact that the system was overloaded with MPI communication operations.
MPI uses a distributed memory interface, with each process working with a separate memory pool. As a result, the modification of objects and data structures by one process is not visible to others, but the data between processes must be transmitted using the MPI Send and Receive mechanisms. The same applies to the transfer to the main process of the best solution found in the current "month".
The found global solution is a complex C ++ object, which consists of a number of objects of derived classes, smart pointers with data and other objects from the STL template. Since the default MPI communication operations do not support the exchange of complex C ++ objects, serialization is required to use the Send and Receive mechanisms, during which the objects are converted to byte streams before being sent and then received after, the streams are again converted to objects.
The load generated by serialization is constant. It occurs, at most, once a month (or does not occur at all if the main process having rank 0 finds the best solution that will be recognized as global), regardless of the number of MPI processes running. This is very important in order to minimize the communication operations of MPI during the transition to the execution of a program on multiple cores.
In the figure above, additional loads are highlighted in yellow (MPI communication operations) and red (standby and overload).
Optimization results №1
The hybrid MPI-OpenMP version of the program showed much better results in terms of load balancing between MPI processes and OpenMP threads. She also demonstrated a much more efficient use of the large number of cores available on systems with Intel Xeon E7-8890 processors. Here are the results of testing the current version of the program in comparison with the base.
Comparison of the results of the basic and optimized versions of the program
Here you can see that the program scales much better with an increase in the number of available cores. Productivity growth is also observed when Hyper-Threading is enabled.
We achieved quite good results, but the work on optimization has not yet been completed. We use the Intel TBB library to further improve the performance of our code.
Optimization №2. Intel TBB Application
Studying the most loaded parts of the code for the hybrid MPI-OpenMP implementation of the application, we noticed that a significant proportion of the execution time still falls on the standard library for working with strings. We decided to check if the use of the Intel TBB dynamic memory allocation library would improve the situation. This library offers several memory allocation templates that are similar to the standard std: allocator class from STL, and also includes scalable_allocator and cache_aligned_allocator. These patterns help solve two critical groups of parallel programming problems.
The first group is scaling problems. They arise from the fact that memory allocation mechanisms sometimes have to compete for a single common pool, and, due to the original sequential device of the program, only one thread can allocate memory at a time.
The second group of problems is related to the general access to resources. For example, it is possible that two threads try to access different words of the same cache line. Since the smallest unit of information exchange between processor caches is a line, it will be transferred between processors even when each of them works with different words in this line. False sharing can damage performance, as moving a cache line can take hundreds of clock cycles.
Features of working with Intel TBB
One of the easiest ways to find out whether an application will benefit from using Intel TBB is to replace the standard dynamic memory allocation function with a function from the Intel TBB library libtbbmalloc_proxy.so.2. To do this, just load the library when the program is started using the LB_PRELOAD environment variable (without changing the executable file) or link the executable file with the library.
: -ltbbmalloc_proxy LD_PRELOAD $ export LD_PRELOAD=libtbbmalloc_proxy.so.2 Optimization results №2
Solving the most important scaling problem that arises when using standard memory allocation mechanisms, the dynamic memory allocation library from Intel TBB provides an additional 6% performance compared to the hybrid MPI-OpenMP version of the application.
Performance Improvement with Intel TBB
Optimization number 3. Finding the best combination of MPI processes and OpenMP threads
At this stage, we decided to study the effect on performance of various combinations of MPI processes and OpenMP threads with the same load. All 192 available logical cores were used in the experiment, that is, 4 processors were involved and Hyper-Threading technology was turned on. During the tests, we found the optimal ratio of MPI processes and OpenMP threads. Namely, the best result was achieved using 64 MPI processes, each of which executed 3 OpenMP streams.
Performance comparison for various combinations of MPI processes and OpenMP threads.
Results
The study of the basic parallel implementation of the ant algorithm made it possible to identify problems with scaling associated with the mechanisms for allocating memory for strings and object constructors.
The first stage of optimization, thanks to the use of a hybrid approach using MPI and OpenMP, allowed us to achieve a better use of processor resources, which significantly increased performance. However, the program still spent too much time allocating memory.
At the second stage, thanks to the library for dynamic memory allocation from Intel TBB, it was possible to increase productivity by another 6%.
During the third stage of performance improvement, it was found that a combination of 64 MPI processes is best suited for our program, each of which runs 3 OpenMP threads. At the same time, the code works well on all 192 logical cores. Here are the final optimization results.
Optimization results
As a result, after all the improvements, the program has worked 5.3 times faster than its basic version. We believe this is a worthy result, which is worth the effort spent on research and code optimization.
Source: https://habr.com/ru/post/311618/
All Articles