Is your favorite C so fast or the native implementation of linear algebra on D
A library like OpenBLAS (Basic Linear Algebra Subprograms) is well known to those involved in machine learning systems and computer vision. OpenBLAS is written in C and is used everywhere where work with matrices is needed. It also has several alternative implementations such as Eigen and two closed implementations from Intel and Apple. All of them are written in C / C ++.
Currently, OpenBLAS is used in matrix manipulations in languages such as Julia and Python (NumPy). OpenBLAS is extremely well optimized and much of it is generally written in assembly language.
However, is pure C so good for computing, as is commonly believed?
')
Meet Mir GLAS ! Native implementation of the library of linear algebra on pure D without a single insert in an assembler!
To compile the Mir GLAS library we need an LDC compiler (LLVM D Compiler). The DMD compiler is not officially supported. It does not support AVX and AVX2 instructions.
Test configuration will consist of:
»The code of the test itself can be obtained here .
»Mir GLAS based on mir.ndslice library
Mir GLAS can be easily used in any language that supports C ABI. This is done elementary:
For comparison, OpenBLAS will need to write the following code:
During the test, the following values of variables were established:
Eigen compiled with the flags `EIGEN_TEST_AVX` and` EIGEN_TEST_FMA`:
Results (more is better):
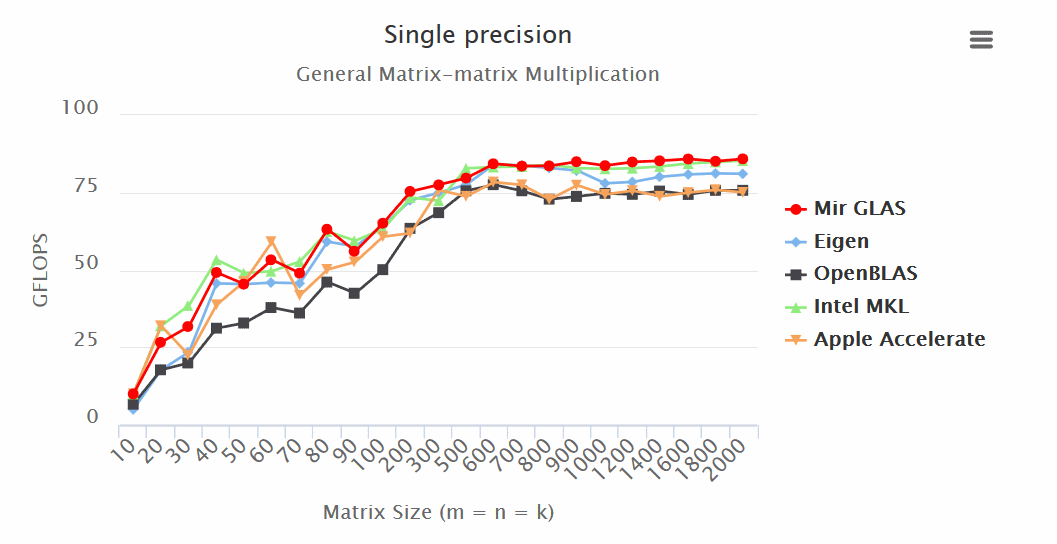
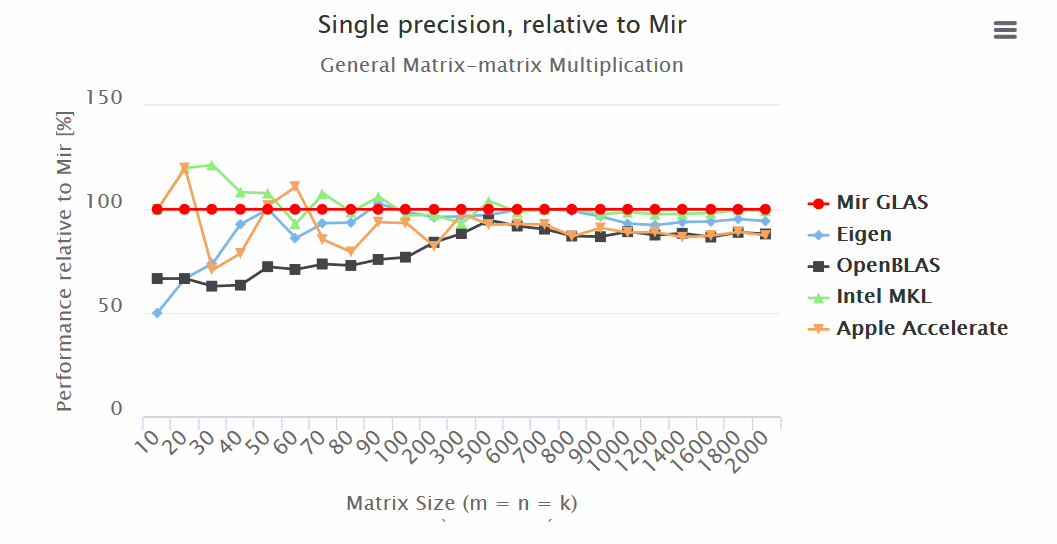

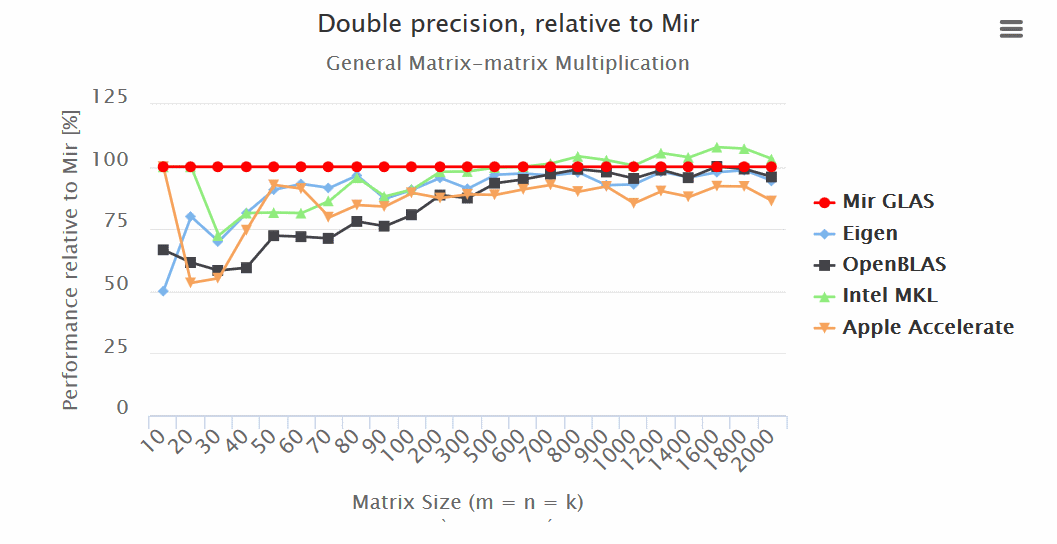

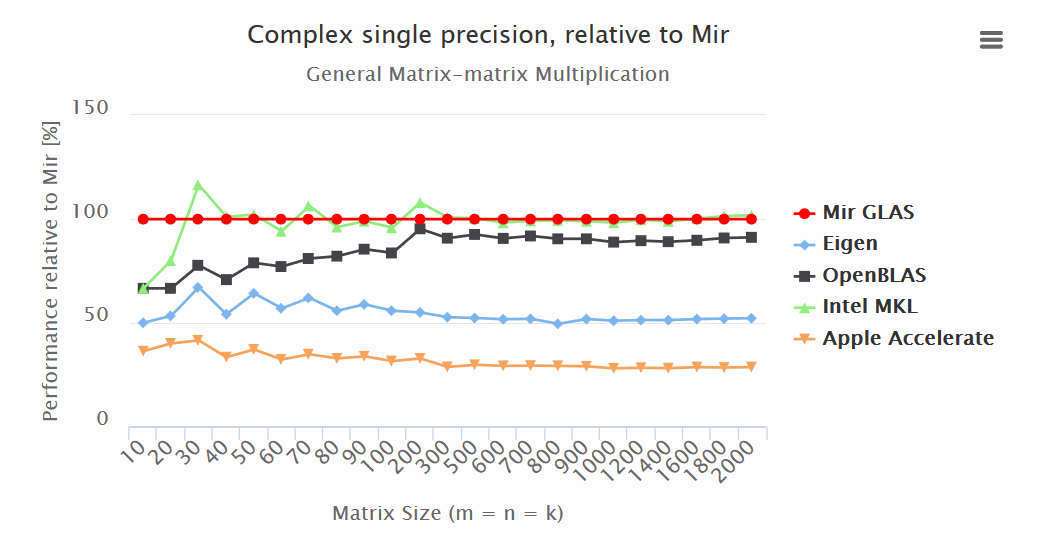
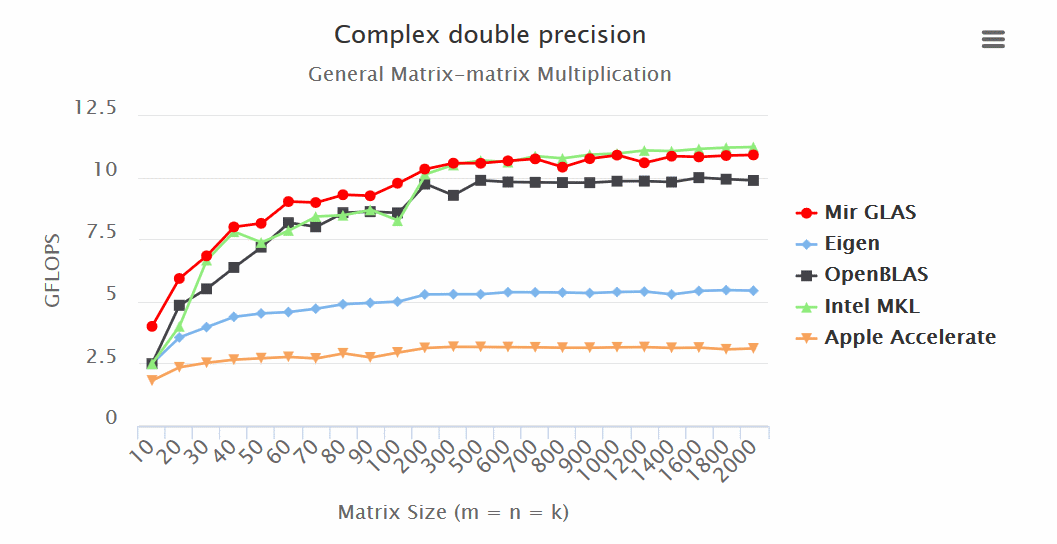
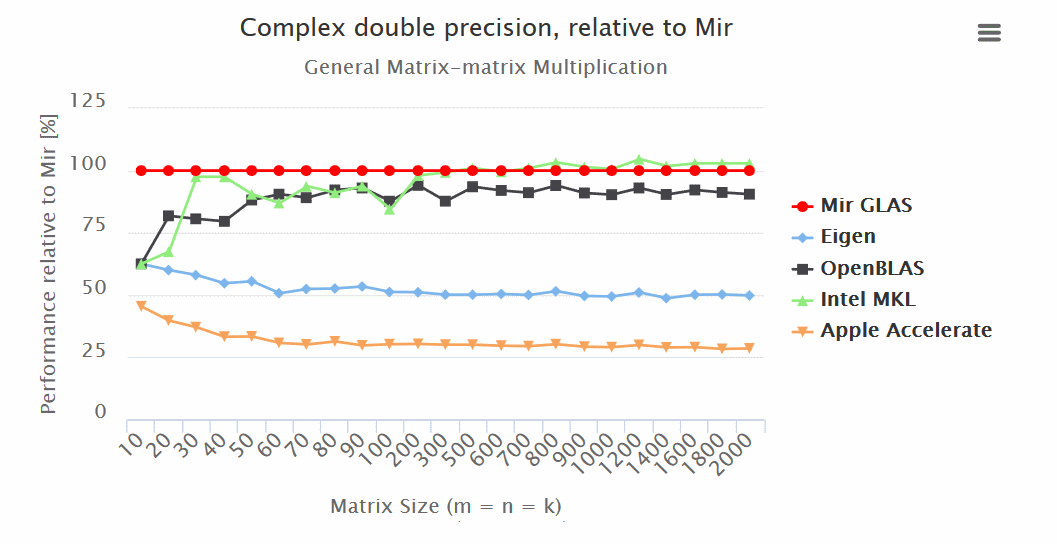
Results:
- Mir GLAS significantly ahead of OpenBLAS and Apple Accelerate in all respects.
- Mir GLAS is almost twice as fast as Eigen and Apple Accelerate when working with matrices.
“Mir GLAS turns out to be comparable to proprietary Intel MKL, which is the fastest of its kind.
“Thanks to its design, Mir GLAS can easily be adapted for new architectures.
PS At the moment, the computer vision system DCV is actively developing on the basis of GLAS.
PPS The original author is present in the comments under the nickname 9il
The original article is located on the author’s blog.
Currently, OpenBLAS is used in matrix manipulations in languages such as Julia and Python (NumPy). OpenBLAS is extremely well optimized and much of it is generally written in assembly language.
However, is pure C so good for computing, as is commonly believed?
')
Meet Mir GLAS ! Native implementation of the library of linear algebra on pure D without a single insert in an assembler!
To compile the Mir GLAS library we need an LDC compiler (LLVM D Compiler). The DMD compiler is not officially supported. It does not support AVX and AVX2 instructions.
Test configuration will consist of:
| CPU | 2.2 GHz Core i7 (I7-4770HQ) |
| L3 cache | 6 MB |
| Ram | 16 GB of 1600 MHz DDR3L SDRAM |
| Model Identifier | MacBookPro11,2 |
| OS | OS X 10.11.6 |
| Mir GLAS | 0.18.0, single thread |
| Openblas | 0.2.18, single thread |
| Eigen | 3.3-rc1, single thread (sequential configurations) |
| Intel MKL | 2017.0.098, single thread (sequential configurations) |
| Apple accelerate | OS X 10.11.6, single thread (sequential configurations) |
»The code of the test itself can be obtained here .
»Mir GLAS based on mir.ndslice library
Mir GLAS can be easily used in any language that supports C ABI. This is done elementary:
// Performs: c := alpha axb + beta c // glas is a pointer to a GlasContext glas.gemm(alpha, a, b, beta, c); For comparison, OpenBLAS will need to write the following code:
void cblas_sgemm ( const CBLAS_LAYOUT layout, const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const float alpha, const float *A, const int lda, const float *B, const int ldb, const float beta, float *C, const int ldc) During the test, the following values of variables were established:
| openBLAS | OPENBLAS_NUM_THREADS = 1 |
| Accelerate (Apple) | VECLIB_MAXIMUM_THREADS = 1 |
| Intel MKL | MKL_NUM_THREADS = 1 |
Eigen compiled with the flags `EIGEN_TEST_AVX` and` EIGEN_TEST_FMA`:
mkdir build_dir cd build_dir cmake -DCMAKE_BUILD_TYPE=Release -DEIGEN_TEST_AVX=ON -DEIGEN_TEST_FMA=ON .. make OpenBLAS Results (more is better):
Results:
- Mir GLAS significantly ahead of OpenBLAS and Apple Accelerate in all respects.
- Mir GLAS is almost twice as fast as Eigen and Apple Accelerate when working with matrices.
“Mir GLAS turns out to be comparable to proprietary Intel MKL, which is the fastest of its kind.
“Thanks to its design, Mir GLAS can easily be adapted for new architectures.
PS At the moment, the computer vision system DCV is actively developing on the basis of GLAS.
PPS The original author is present in the comments under the nickname 9il
The original article is located on the author’s blog.
Source: https://habr.com/ru/post/311568/
All Articles