Implementation of disaster recovery
Sergey Burladyan (Avito)

Hello everyone, my name is Sergey Burladyan, I work at Avito as a database administrator. I work with such systems:

')
This is our central base of 2 TB, 4 servers - 1 master, 3 standby. We also have logical replication based on londiste (this is from Skytools), external sphinx index, various uploads to external systems such as DWH, for example. We also have our own developments in the field of a remote procedure call, the so-called xrpc. Storage for 16 bases. And another such figure is that our backup takes 6 hours, and its recovery is about 12 hours. I would like that in the case of various accidents of these systems, the downtime of our site took no more than 10 minutes.
If you try to present the various connections of these systems, they somehow look like this:

And how not to lose all this in an accident?
What could be the accident?

I consider, basically, server loss crashes, and a plus for the master may be another such crash as an explosion of data.
Let's start.
Suppose some administrator mistakenly made an update without where. We have had such a case several times. How to protect against it? We defend ourselves by the fact that we have a standby that applies WALs with a delay of 12 hours. When such an accident occurred, we took this data from standby and downloaded it back to master.

The second crash that can happen to the master is the loss of the server. We use asynchronous replication and after losing the server, we have to promote some standby. And since Since our replication is asynchronous, we still need to perform various procedures to restore the connected systems. Our master is central and is the source of data, respectively, if it switches and replication is asynchronous, then we lose part of the transaction, and it turns out that part of the system is in the unreachable future for the new master.

It’s all difficult to do with your hands, so you need to immediately make a script. What does an accident look like? In external systems, ads appear that are no longer on the master, sphinx gives out non-existent ads when searching, sequences were jumped back, logical replicas, in particular because of this, also stopped working (londiste).

But not everything is so bad, it can all be restored. We sat, thought and planned the recovery procedure. In particular, we can simply unload DWH again. And directly, because we have a simple 10 minutes, then on the monthly reports the change of these lost items is simply not visible.
How to repair xrpc? We use xrpc for geocoding, for calling asynchronous procedures on the master and for calculating the user's karma. Accordingly, if we zheokodili something, i.e. from the address they turned it into coordinates on the map, and then this address disappeared, then it's okay that it will remain zodiac, it’s just that we won’t geocode the same address a second time, respectively, we don’t need to restore anything. The local procedure call is asynchronous, since it is local, it is located on the same base server, even on the same base, and therefore, when we switch the base, it is consistent. Also, nothing needs to be restored. Karma user. We decided that if a user did something bad, and then an accident occurred, and we lost these bad items, then the karma of users can also not be restored. He did these bad things, let him stay.

Sphinx site. We have two sphinx - one for the site, the other for backoffice. Sphinx, which is the site, is implemented in such a way that it completely rebuilds its entire index every 10 minutes. Accordingly, an accident occurred, recovered, and after 10 minutes the index is completely rebuilt and corresponds to the master. And for backoffice, we decided that it’s not critical either, we can refrain some of the ads that have changed after recovery, and once a month we completely rebuild the whole sphinx backoffice, and all these emergency items will be cleaned.
How to recover sequences so that they do not jump back? We simply chose sequences that are important to us, such as item_id, user_id, the payment primary key, and after the accident we scroll them forward 100 thousand (we decided that it would be enough for us).
We restore logical replication using our system, this is a patch for londiste, which makes UNDO for a logical replica.

Patch Undo - these are the three teams. Directly the command itself and plus two commands add / remove Undo for a logical replica. And the replay in londiste, we added a flag to transfer the TICK_ID from the master to the Postgres session variable.

This is needed directly in the Undo implementation itself, since it is implemented - it's just triggers on all subscriber tables. The trigger writes in the history plate, which directly the operation occurred. In the target table. This transmitted tick_id with the master he remembers in this record. Accordingly, when the accident occurred, the logical replica turned out to be in the future, and it needs to be cleaned in order to recover changes that are from an unattainable future. This is done by performing backward queries, i.e. for insert we do delete, for update we update with the previous values, well, and for delete - insert.

We do not do all this with our hands, we do it with the help of a script. What is the feature of our script here? We have three asynchronous standby, respectively, before switching, you need to find out which one is closest to the master. Next, we select this standby, wait until it loses the remaining WALs from the archive, and select it for the future master. Next, we use Postgres 9.2. The features of this version are that in order for the standby to switch to the new promotion and the master, they have to be stopped. In theory, at 9.4 it is already possible not to do it. Accordingly, we do promote, we move the sequences ahead, we execute our Undo procedure, we run standby. And then this is also an interesting moment - you need to wait for standby to connect to the new master. We do this by waiting for the timeline of the new wizard to appear on the appropriate standby.

And so it turns out that in Postgres there is no such function for SQL, it is impossible to understand the timeline on standby. But we solve it in this way, it turns out you can connect via Postgres replication protocol to standby, and there after the first command standby will report its red highlighted timeline.
This is our master recovery script.

Let's go further. As we are restored directly, when some external systems fall apart. For example, standby. Since we have three standby, as I said, we just take, switch to the remaining standby, if one of them falls. As a last resort, even if we lose all standby, we can switch traffic to the master. Part of the traffic will be lost here, but, in principle, the site will work. There was still such a trick - at first I kept creating new standby from backup, then we got SSD servers, and I still continued to restore standby from backup. Then it turned out that if you take from a backup, the recovery takes 12 hours, and if you just take pg_basebackup from any working standby, then it takes much less time. If you have several standby, you can try to check it with you.

If the sphinx site breaks down. The Sphinx site we have written in such a way that it completely rebuilds the entire index, and the site sphinx is all active site ads. Now all 30 or 35 million ads on the site are indexed by this system. Indexing comes from a separate logical replica, it is specially prepared for indexing and is made so that everything is laid out in memory, and indexing happens very quickly, so we can do indexing every 10 minutes, completely from scratch. Our logical replicas are pairwise. And if we lose the replica, we switch to its reserve. And if something happened to sphinx, then in 10 minutes it will be fully reindexed, and everything will be fine.

How can restore export to DWH? Suppose we exported something, an accident occurred at DWH, we lost some of the latest data. Our DWH export goes through a separate logical replica, and the last four days are stored on this replica. We can simply call the export script again with our hands and unload all this data. Plus there is another archive in half a year. Or, in extreme cases, because we have several standby, we can take one of them, pause and reload, in general, all the data from the master in DWH.
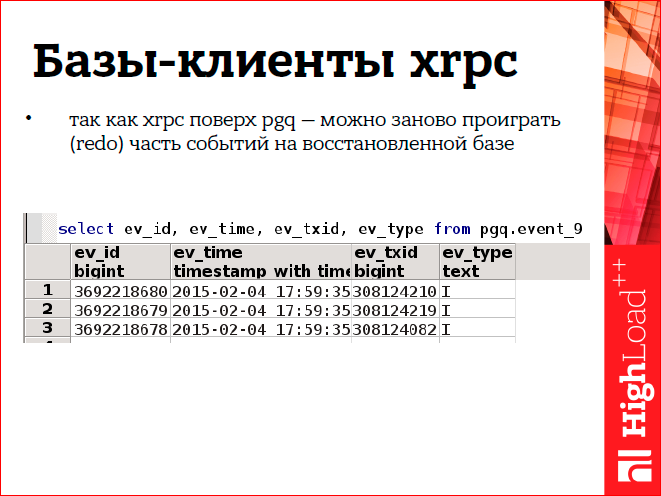
Hrpc is implemented on top of pgq (this is Skytools), and thanks to that we can do such tricky things. Pgq is, in fact, just a table in the database, it stores events. It looks something like the figure. There is an event time and transaction id. When we have restored the xrpc client, we can take and move back in this queue, and re-play those events that are not in the receiver.

Xdb - we have a repository of several databases. 16 bases are located on eight machines. This storage is reserved as follows - just Postgres binary replication is configured from one machine to another. Those. the first car is reserved by standby on the second, the second on the third, respectively, the eighth on the first. In addition, the playback of WALs, there is also a delay of four days, i.e., in fact, we have four days of backup of any of these nodes.

Now I will tell you in detail about the replica of what it is. The logical replica is built on the basis of Postgres capabilities; this is the view'ha on the master and the deferred trigger on the necessary tables. For these triggers, a special function is triggered, which writes to a separate table. It can be considered as a materialized view. And further this label means londiste is replicated on a logical turnip.

Directly it looks something like this, I will not dwell on this in detail.

And the logical replica server itself, why is this, in general, necessary? This is a separate server. It is characterized by the fact that everything is in memory there, i.e. shared_buffers of such size that all this plate and its indexes completely fit into it. This allows for such logical replicas to handle a large load, in particular, for example, one turnip serves 7000 transactions per second and 1000 events are poured into the queue from the master. Since This logical replica is implemented by means of londiste and pgq, then there is a handy thing - tracking which transactions have already been lost on this logical replica. And based on this thing, you can do such things as Undo.

I have already said that we have two replicas, we can recover by simply switching. If one replica is lost, switch to the second. This is possible because pgq allows multiple consumers to subscribe to one queue. The turnip fell, and then we need to restore its copy. If this is done simply by means of londiste, then it takes us 4 hours for the site turnip, 8 hours for the sphinx, because there triggers are called, which cut the data for convenient indexing to the Sphinx, and this is all very long. But it turned out that there is another way to create a fallen turnip - you can make pg_dump working.

But if you simply make pg_dump and run londiste on it, then all this will not work, because londiste keeps track of the current position of the lost transaction on both the master and logical replica. Therefore, there still need to take additional steps. It is necessary to correct after restoring the dump on the tick_id master, so that it corresponds to the tick_id that is on the restored turnip. If so, through pg_dump to copy, then all this takes no more than 15 minutes.

The algorithm itself looks something like this.

Backup is designed to protect against accidents, but directly with the backup itself, accidents can also occur. For example, in Postgres, the WAL archiving command doesn’t say what fsynk needs to do when WAL is written to the archive. But this is an important thing and allows you to protect against, say, an emergency reboot of the archive. In addition, our backup is still backed up by the fact that it is backed up to an external cloud. But in the plans: we want to make two active archive servers so that archive_command writes to both WAL. We can also say that at first we experimented with pg_receivexlog for receiving directly on the WAL archive servers themselves, but it turned out that at 9.2 it is almost impossible to use it, because it does not do fsynk, does not track which WAL it already received from the master which can be cleaned at checkpoint. Now in Postgres this is completed. And, probably, in the future we will use not archive_command, but pg_receivexlog after all.

We do not use streaming at home. Those. what I was talking about is all based only on the WAL archive. This was done due to the fact that it is difficult to ensure when streaming is also an archive, because if, for example, we take an archive with standby, the backup is completed, and the master has not yet managed to archive all these WALs needed to restore the backup. And we get a broken backup. This can be circumvented if we have, say, standby, from which we take a backup, it is 12 hours behind, like ours. Or - in Postgres 9.5, we made this setting archive_mode = always, in which there will be no such problem. You can safely take a backup from standby and receive WALs directly from standby to the archive as well.

It is not enough just to make a backup, it still needs to be checked to see if everything is correct there. We do this on a test server, and for this we wrote a special backup check script. It is based on what it checks after restoring the server and running error messages in the server log. And for each database restored on the cluster, a special checking function check_backup is called, which performs additional checks. In particular, such a check that the date of the last transaction should differ from the date of the last announcement by no more than a minute. Those. if there are no holes, we assume that the backup has been restored correctly.

On the slides, you can see what specific errors we analyze in the log when checking the backup.
Previously, we checked backups using vacuuming the entire database and reading the tables, but then we decided to refuse it, because we believe the restored backup still contains reports, and if the reports were calculated correctly, there are no holes, strange values, then the backup was done correctly .

I talked about asynchronous replication, but sometimes I want to make synchronous. We have Avito consists of many services, one of these services is a payment service. And due to the fact that it is selected, we can do synchronous replication for it, because He works on a separate database. There is not such a large load and standard network latency allows us to enable synchronous replication there.

What can be said at the end? Still, despite the fact that replication is synchronous, you can work and recover in this mode, if you look at your connected systems, you can think up and how they can be restored. It is important to still test backups.

Another such remark. We have a recovery script, at the end it is necessary to change the DNS, since we have this master or slave - this is fixed in the DNS. We are now thinking about using some type of ZooKeeper system to automatically switch DNS. Such plans.
This report is a transcript of one of the best speeches at the conference of developers of high-loaded HighLoad ++ systems. Now we are actively preparing for the conference in 2016 - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
The Avito team traditionally offers very strong performances, for example, this year it will be:
- Experience of migration between data centers / Mikhail Tyurin
- Sphinx 3.0 and RT indexes on the Avito main search / Andrey Smirnov, Vyacheslav Kryukov;
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/311472/
All Articles