Site optimization. Diagnoses and treatments
Ivan Mikheev (AGIMA)

Today we will talk, as is clear from the title of the report, about optimization. Generally, someone had to optimize the sites? Had to. On this way, we are met with many interesting things, from the way the incomprehensible code comes to us - from a previous contractor, for example, or our own code, which we then have to rethink - and problems arise which, under certain loads, start to disturb us wildly.

')
If you come for some wild hardcore, you, unfortunately, will not see it in this report, and maybe, fortunately. What I’ll be telling today is, in general, no Rocket Science, nothing complicated, these are the tools that you can get even on a shared hosting, if you use, say, virtual hosting on a highload. I'll tell you about the tools, what kind of optimization examples we had in the company, and let's touch on the scaling a bit, because This is also from optimization, but in a slightly different context.

The first sad conclusion I made for myself on the path of my development history is that a silver bullet, in general, does not exist anywhere. Those. There is no universal solution, universal approach or tool that would save everyone from the headache that we encounter on the way of optimization. Therefore, this conclusion is that there is no silver bullet.

I also learned from experience with time that if you had a day of updates yesterday, and yesterday your site fell, then there is no special science here either - it’s about updating. What are we doing? We roll back and begin to understand what happened, what was wrong in the release. It is important to understand right away that something happened wrong for you.

Let's talk about a more or less approximate situation. For example, you have a growing load on the site. Perhaps it grows evenly, but most likely it grows unevenly with you, but with some peaks. And at these peaks your site gets wildly bad. It starts to render pages endlessly, you have a white screen, instead of content, various random errors 500th and not 500th, you often notice a connection that is broken off from the server, or, in general, your pages load half, half of the pictures did not load, and , in general, there is some kind of meat going on. All these symptoms indicate that it is time for you to think about optimizing your portal or site and begin to take steps towards improvement.

To structure a report, consider the typical components of an application - what does it generally consist of? Usually in any language there is some kind of front-end where the user interface is located directly, i.e. if the site is a browser, if the application, then some kind of interface. There is an application on which your application spins, all business logic spins. And there is a data layer - it can be a DBMS, it may be, God forbid, XML, it can be any data that should come to you in any way in an application. And having this structure, we return to the problem - our site is dumb, it takes a long time to load, there are some problems. Where to begin? How to approach this case, what should we do?

The first thing that suggests itself is to look at your front-end, because it will help you to drop several options at once in which direction you should go.

The main problems at this stage are precisely the problems related to why your website is slowing down. This is an inadequate page load for you, i.e. You understand that the script worked as fast as possible, but the content delivery to the client in the browser takes a very long time. Your CSS execution is blocked. This is about the fact that if you, for example, the user sees a white screen first, and then it somehow suddenly turns into something beautiful for him - this is not a very situation ... When you see a partial download of content, i.e. the picture is loaded unrealistically for a long time, or the model is drawn for a very long time - this is also not the very situation. Well, the delay in the execution of JS scripts, when you have some script connected 80th in the list of all Java scripts, and you understand that it does not work as it should, something needs to be optimized here too.

For diagnostics, there are fairly simple tools that are available in every browser, probably not in the browser.
The first thing that begs is Firebug. Everyone knows how to use it - they clicked on F12, and even in the oldest one, ie it definitely exists. They stuck Firebug, looked at what requests you had there, how many pages were being sent, when the content was loaded, and when a script was executed. This, in general, is free, just looked at the statistics, it took you 5 minutes - well, to reach the F12 key + a couple of minutes. Everything, you have all the statistics, you already have some understanding in which direction to go further.
There is a very interesting tool - YSlow. He, besides some metrics, can tell you more with words that you need to fix. This tool is a kind of discovery for me.
There is also Google PageSpeed, which will tell you how to improve the ranking of your site on the basis that you need to change something on the front. Here, by the way, the front is viewed from the client’s point of view as a browser.
Thus, we stuck these tools, looked at what was broken, and we are starting to fix something.

What should you pay attention to when you look at these metrics?
The first and key, most content sites sin this - this is the DOM rendering speed. There are such sites where DOM contains well, a lot of elements - more than 10 thousand - this already becomes a problem in order to render it, when scrolling sites start to blunt, if you open it on the phone, it becomes an even bigger problem. So, it is worth seeing how much you have, generally, with difficulty.
The second is the presence of external JS and CSS. This is, in general, a separate topic, because if you have some kind of JS that is not on your server, it is requested, and sometimes you don’t know what size it will be in the end, because there are some external libraries, and everything is difficult with them. And you, of course, are starting to block the download of these scripts, i.e. it waits for one script to load, only then it starts loading something else. The same with CSS, i.e. here you need to correctly allocate such scripts and, probably, it is no longer just about the availability of the service that this JS takes from you, but also about this.
We, for example, had a case when we rolled out the site of a fairly well-known fitness club. There was some external script that connected and did some operations. The developers developed, everything was cool for them, they didn’t take into account only the fact that it was cached on the browser, and when they drove it in, this script weighed half a meter there. What is 500 KB in the transfer between the disks? These are not very big numbers, but when it starts to load it is not very cool when you have preloads loaded seconds. Plus, there was still a lot of graphical content, which was also cached by the developers, and they seemed not to ask for the cache. In general, a lot of research was done until they finally realized that it would be possible to look at it in Firebug and that’s it.
Well, the time to establish a connection to the server. Everything is interesting here, because it’s important to understand, is it really that your front is dumbing, or you just have a very weak internet channel. Such problems also happen, and here rather you need to go to deal with your network provider, and not to dig your code.

What methods can be used to optimize the front?
Minification, merging, compression - all this affects only two factors - the weight and the number of files at boot. When you load 10 Javascript'ov, and some of them are from external services, this does not affect the frontend very well, because the browser, in my opinion, can support five simultaneous connections (depending on the version), and everything else is blocked. If you, of course, ship synchronously. Merging at some point helps you to avoid this - you have one of 10 files. And of course, one in 30 KB will load faster than 30 in 1 KB. This needs to be understood.
But here is the next point in terms of minification (especially CSS). When you have a debugging moment, then some people open a development panel on the prode and begin changing tsiferki, as this has all changed, and there they still indicate the line. So, in the case of compressed files, they will show you the line "1", except for those cases if you do not have surse mappers on these minifiers. But even so, not everything is so simple with them, because sometimes some surse mappers also give you just some key, the main element shows where it begins. And where specifically in the code, it can be very difficult. Here, too, you need to very competently apply the approach, because in debugging this can play a cruel joke with you.
Compression. Everything is probably transparent here, because media content needs to be precisely compressed and not loaded into the container 100 by 100 pixels some kind of Full HD picture. Now there are still cases when it seems that the picture is small, and Full HD is being driven there, and the client says: “Why so long?”. This moment also needs to be taken into account.
The second group of optimization tools is refactoring of your JS code, because often it is he who stinks, because it is written this way. Especially if you use some frameworks that are not completely clear to you, and you also have a DOM consisting of several thousand elements, and you also have some events on jQuery, etc. In short, everything will not really work very quickly.
Well, DOM optimization is also an important thing. When, if anyone remembers, an iPad 1 or 2 came out, they had a problem when they loaded all sorts of content sites, for example, news portals such as woman.ru or some other such. It has historically developed that the DOM was very complex, i.e. A lot of elements, and just the iPad is not digested. You opened the site, it seemed to be rendered, rendered, rendered, but it didn’t come to anything special, and then they should be optimized very much on this topic. It probably took a lot of time.
All these points will simply lead to the acceleration of your site.

And free advice, which does not apply to clients anymore, but more to the front of your proxy or nginx server - you need to give statics via nginx. Until now, we encounter such cases when the static does not go through nignx, and this does not have a very good effect on the disk, so if you have a website that is dumb and you think everything else is fine, check the statics - through nginx given or not?

Let's move on to the more interesting part, these are Application and DB. The part where most of the errors actually occur and which gives you just a testing ground for optimization.

If your pages are slowly formed, the script sucks, the html is generated, the 500th errors are often encountered, any ... Any 500th is already a bell. If you observe any site downtime through your monitoring system, then if you don’t need to sound the alarm, then you should definitely think whether everything is alright with you. If this is a single case, then you can think, look, disassemble it, but if it is a series of such cases, then you definitely need to take a comprehensive approach to this task.

What are our options when Application or DB slows down? In fact, there are three such key blocks:
- your server has exhausted its resource,
- programmers made some not very high quality code,
- or something is amiss going on in the database.
How is this all, in general, to understand?

The first thing that comes to mind is not to install any profilers there, not to invent some incomprehensible thing, but just go to your terminal and use the usual OS tools.
You have a top command that will help you understand how much memory you have left on the server. There are strace, lsof, etc. All these commands are in Linux OS, under Windows there are similar commands too, i.e. you are not doing anything, you have everything at your fingertips, you just look at the current state of your server. And in general there is nothing scary.
There was a case with one retailer. They have such things as catalogs, maybe, you know, they are downloaded in pdf. And it is interesting that on the day when they post them, for some reason, a lot of people start downloading them. I don’t know for what purpose, but there’s really 2,000 people who, for some reason, go to this portal and start downloading directories. And our site has arrived a little bit. Began to understand. The system administrator simply stuck the laptop and realized that all the files were given via apache by access_log. But, of course, giving pdf files through apache is not very good. Just switched the config to nginx (again, we remember the tip? - static through nginx), everything flew. Those. here is an obvious example - we spent 5 minutes on it, just stuck a laptop, looked at what was happening with the disks, looked at access_log, that's it. And all at once it became clear corrected.
Even if you are even cooler - there is a monitoring system, then you don’t even need to go especially in the OS, you can understand all of them. Those. There are various metrics by which you understand where in which place the server has a slight crisis.

The second point is slow logs. Slow logs are almost everywhere, they help you determine the places and times when a particular request occurred, or the skrpit took an unusually long time. The main topic with slow logs may be a problem, or even a problem, but just a reason to argue, to talk - this is the time to determine a slow query. Everything is actually even easier. You are the owner of your system and you know what time to request the execution of a script for you is optimal or acceptable. Just set up a slow log so that all critical requests are written to you, and all non-critical ones are not written, i.e. it is important for you to understand what time is critical for you, so as not to assume that if two requests are executed for more than three seconds, then this is all. Because there is such a thing as statistics, calculations or reports, and there seems to be 5 seconds to fulfill the request as a whole is normal.

Another tip is that slow logs should be included immediately at the beginning of development. This will save you from unexpected load peaks and subsequent debriefing like “what happened to us?”. Because with the same update, when you roll out to the prod, and your load starts to load very unevenly on the server, then you need to quickly roll back and return the status. And if your slow log has not been enabled, it will be very difficult to collect some statistics or metrics. If you have it turned on, then you just look at the metrics, then you decide everything, maybe you do some kind of load testing. Actually, that's all.
We also have various logs - this is error_log and access_log, i.e. All server tools that we have at our disposal can be used without using any additional tools. This is what you have in the OS box, plus monitoring. But monitoring needs to be set up already.

The next step towards a faster understanding of your application, and if it is not yours, then this tool that is even more interesting for you is profilers. Profilers have almost every language, I think they have every language. And every self-respecting profiler is marked by some advantages, which, in principle, are the same for any profiler. This is ease of use, i.e. you just determine from what point you can start, where he needs to finish, write in the settings, what he should write, what behavioral characteristics and everything. At the exit, you get a callstack of all executed functions during the profiling, i.e. you see what function was executed how much, you have an understanding of how much this function was executed by itself, how many of its nested functions were executed, there is an understanding of how much memory it consumes. And the profiler logs still allow you to build a callgraph, so that you can follow the route of some action that is heavily loaded, in this case, in which the runtime is more than the nth number of seconds.

For example, there is Xhprof. We are developing in PHP, and we have Xhprof. This is what it looks like. It seems to me that many profilers have a similar interface - there is a certain table with callsteck, and there is a certain graph that shows you where a complex query started from and where it ended.
There is also a Visual Studio profiler, still different, any profilers can easily glance at many languages.
Further, in order for us to better understand what we need to do, I propose to consider a small example. Let's start with the symptom.

We suddenly realize that our site is very slow. In this case, the high execution time of the script is on the server, i.e. we realized that we had all the rules at the front, but there are some problems with the formation of the script. All we need is a profiler or slow logs - as you like, who has what, who can configure what.
And such a small thing - the EXPLAIN team. In the future, you will understand why.

We stick the profiler and see such a thing, that we have 14 MySQL_query calls executed in 1 second. Not a good indicator.
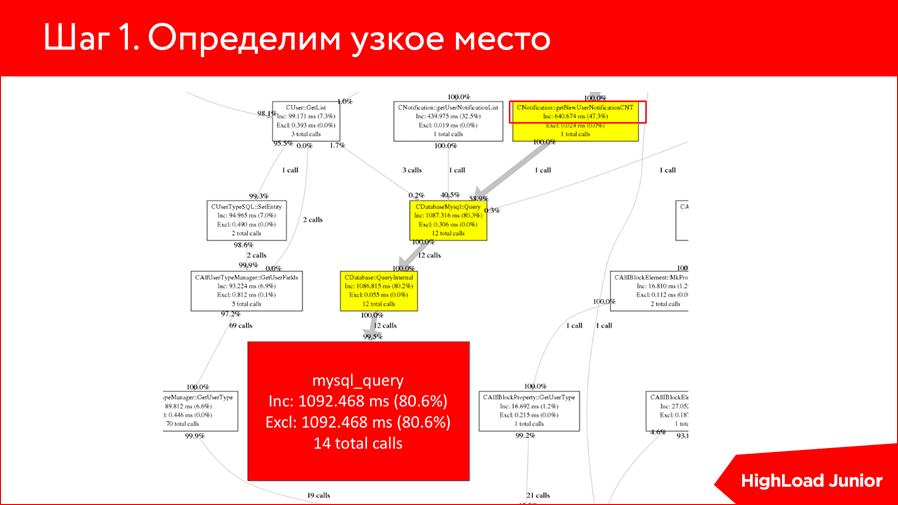
If we follow a little higher, then we understand that a certain function with the name getNewUserNotificationCNT executes only 640 milliseconds and, most likely, out of these 640, it fulfills the request 620. Those. you can simply assume and understand that here the profiler has worked, and this function is our bottleneck. All we need is to go to this function and see what it does for the request.

We see that the request is very trivial - it is the choice of the number of new, unread notifications.In fact, it may already be immediately clear what the problem is, what is wrong with this query, but to check our concerns, we do EXPLAIN of this SELECT:

We understand that this SELECT that the user wants to select all unread notice, runs over the table with a million rows. Agree, the situation is not very. I want to select a separate user, I have, there, God forbid, some 10 notifications, and he selects them for me all over a million. Plus, COUNT (*) is a fairly loaded operation. In short, something is wrong here. And we see from this EXPLAIN that there are no indexes on these tables at all, and in this respect, he clearly does not want to use anything.

We move on. We make simple ALTER TABLE, add INDEX by USER_ID and by read. And what do we see?What we have with a million records, the number was reduced to two. It seems to me that the delightful work of indices with 1 million lines go up to two.
This example shows that we stuck EXPLAIN, looked at the fact that we have an unusually large number of lines involved, and realized that we need to roll some indices.
With indexes, too, need to be careful. And with EXPLAIN. Because if you have EXPLAIN in one version, it works out one by one, then it’s not a fact that it will work in the same database, but in another version, because EXPLAIN involves both planners and optimizers, and can vary from version to version of the planning strategy . Therefore, with them, too, you need to be careful, and not the fact that the index that you rolled on one DBMS is like rules for another. Here is a very trivial example, but in principle it can be used to look at various more complex queries.
If we had some other join or other tables, EXPLAIN would show several more lines here and tell you what it would use — where or index — and how many rows from each table would be involved. An interesting tool that, I think, should be used in any query diagnostics, it will help you explain a lot of things.

As a result, we have reduced the execution of requests from 1 s to 300 ms. It seems to me a good indicator as a whole. Speaking of page load, before this operation with an index of one line of code, it was performed in 2.5 seconds, after this optimization, 700 ms. Those.wow such an optimization, it is without a cache yet.
What problems may be on our way? Here is collected some top logical errors of programmers:

The first thing that occurs is the execution of queries to the DBMS in a loop. This, when you have some select from some table, and then inside another cycle, when it goes along the lines of this select, another select is made, in principle, of the same type, which could be put into the first one via join some get additional information. For Bitrix developers, a fairly common problem is, because they make their get list, by get list they go ahead and get some more get list. Not very cool it affects performance.
The second problem is infinite loops in the code, i.e. some logical error, where you while should go to a certain value, work out five times, and you just have it sausage an infinite number of times. This is not very good for your application, and it just does not give anything in the end.
There is also such an error (with the help of the profiler, it is very well defined) - unnecessary function calls. This is when you instead of cramming the value of some function execution into a variable, this function is substituted for the variable, and it is called a wild number of times, especially when working with strings. This moment, which in theory can break off your system.

What to do with it? Here, it seems to me, there are no options, just do some refactoring, correct errors in the code and make code review more correct next.

But in this world there are also other processes that are not a developer’s mistake, but rather an error of the underestimation of your application. When you thought that this process should not affect a large amount of resources, but in the end it just sausage millions of lines - for you this is a surprise. There are practices for these things. If you have some process that is not very critical for you to perform in real time, just take it out to cron, to the scheduler, either do some step-by-step script, or enter the concept of queues, if you need to do some loaded operation, and then quickly enough to give the content to the user.

Examples of such operations are typical. This is either the import of goods, which obviously should not be carried out on hits, but should be carried out in the dead of night, when no one is on the site. Sending mail is also a rather illustrative example, because if you have a large flow of sending messages, it can load your server, it’s better to do queues for such things. We had such examples when the client needed to form reports in excel, and there were a lot of lines, but he needed a report to appear on the click. Here we introduced step-by-step creation or also translated into queues, i.e. He pressed there, he was told: “Soon you will have a report, come in 5 minutes,” and then this report was formed and given away. Such techniques are applicable and quite effective on any platform.

We approach the question that if you are fine, if the code is licked, if the indexes in the database are set up, if you have nothing at all on the front line and you understand that the site should, in principle, work quickly, but it still slows down.
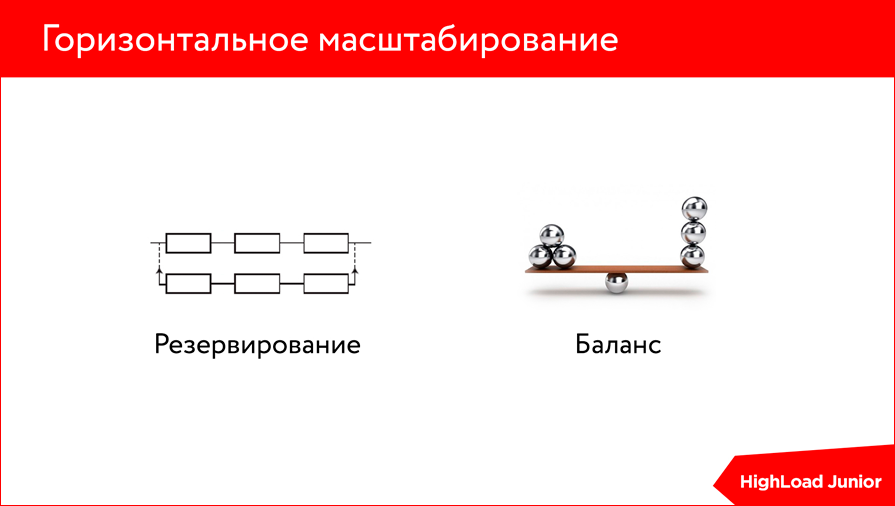
This is where horizontal scaling comes to the rescue, because any optimization comes to a standstill sooner or later - it is limited by the resources of your server anyway. Those.no matter how much you lick your code, no matter how many different approaches to index formation are developed, one way or another, everything will once again run into server resources.
And here you have two options:
- either you upgrade your server — you plug in another RAM slot, make disks faster, or just increase processor power;
- , . – , .. - , , , , .. , , .
But here it is important to understand that this is all cool when your code is working. If you have any errors in the application, then it and 10 servers can not save. You will simply have a mad load on all these servers, and instead of increasing from 100 users to 1 million, you will only get to 100 from 100. Here it is also important to understand this border.

To summarize, in principle, do not look for universal ways, because there are none, each task is unique. For some kind of optimization, it suffices right here and now to plug in the RAM slot and you do not need anything else. For the first time, this will give you a reprieve until the moment you refactor, it is not very expensive - upgrade your server, buy an additional processor, memory.
First, determine the bottleneck, i.e. before you do something, it is better to make a diagnosis in order to know exactly where you really have a bug.
Use simple tools, i.e. There is no need to invent any mega solutions, there is an operating system, there are its tools, there are various profilers - use them.
Buy RAM - this is also optimization. Here, too, about the fact that sometimes the question is not in optimizing the code or application, but simply in buying an additional RAM slot, which will solve the lion's share of your problems.
And do not be afraid of the coming horizontal scaling. Sooner or later, if you plan that your site will still live, you will come to this one way or another, because the load will increase, some processes on the site will increase, and you will still have to scale it horizontally.
Contacts
» Miheev@agima.ru
This report is a transcript of one of the best speeches at the training conference for developers of high-load systems HighLoad ++ Junior . Now we are actively preparing our older brother HighLoad ++ Junior - a conference of developers of highload systems HighLoad ++ 2016 - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
The difference between conferences is important - Junior is not for children. This is about highload in conditions of limited resources (time, money, qualification). HighLoad for design studios - how to withstand high traffic in real conditions, without developing your own modules for nginx :)
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/311464/
All Articles