Create your own bot to play Go

I am developing my humble go bot. And I am genuinely surprised by the lack of information on this topic in Russian. Therefore, I decided to share the accumulated knowledge in this article.
I will tell you how to make a simple bot. I will cover the main stages, starting from search for moves and heuristic algorithms and ending with the publication of your creation on the KGS online server.
A brief history of computer Go:
1968 - the first program to play Go, written by Albert Zobrist
1984 - the first championship among go-programs
1990s - programs lose to professionals with a handicap of 25-30 stones
2006 - CrazyStone wins Computer Olympics using Monte Carlo method
2008 - MoGo wins on 9 odds stones from a professional of 8th dan on a 19x19 board
2010 - Zen program gets 3rd dan on KGS server, playing with people
2013 - CrazyStone won the 9th dan professional on 4 odds stones
2015 - AlphaGo wins the European champion 5 games out of 5, without a handicap
2016 - AlphaGo wins a series of matches of professional Lee Sedol, without a handicap
1984 - the first championship among go-programs
1990s - programs lose to professionals with a handicap of 25-30 stones
2006 - CrazyStone wins Computer Olympics using Monte Carlo method
2008 - MoGo wins on 9 odds stones from a professional of 8th dan on a 19x19 board
2010 - Zen program gets 3rd dan on KGS server, playing with people
2013 - CrazyStone won the 9th dan professional on 4 odds stones
2015 - AlphaGo wins the European champion 5 games out of 5, without a handicap
2016 - AlphaGo wins a series of matches of professional Lee Sedol, without a handicap
The basis of the artificial intelligence of most modern go-engines is the Monte Carlo method, or rather its implementation, the UCT algorithm. I already wrote in detail about this algorithm here . But if briefly and without formulas, then his work can be described as follows:
')
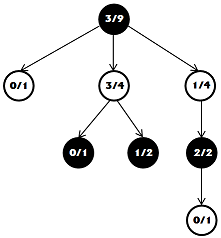
Let's imagine that at some stage we stopped the search and the move tree looks like shown in the picture. Each node has two numbers, the first is the number of random games won, the second is the total number of such games.
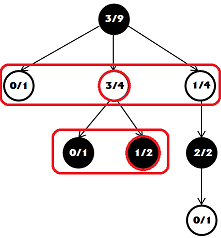
Now we need to find the best move in the tree. To do this, starting from the very top, at each level we find the most successful move with the best ratio of victories and defeats.
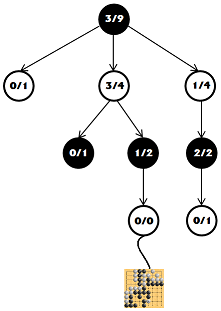
Now, from the list of allowed moves, select any and add it to our tree. And so that all these searches were not in vain, let's play a game game from this site. The party lasts until the end, the moves in it are chosen randomly.
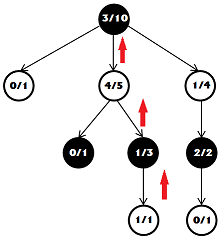
After we have played the game, we count the points and determine the winner. Next, we go on the way back up the tree and when visiting each node add to its values the result. The nodes of the winning party increase the number of wins and the number of games, while the loser has only the number of games.
After that, everything starts over again, search, disclosure, random play and back distribution of the result of the game. There can be not one thousand such passes, and more often several tens of thousands per turn. In this way a move tree is built. Due to the formula for choosing a turn at each level, the tree is built unevenly. The best moves are explored deeper. The greater the number of games, the more accurate the prediction algorithm. At the end, the move with the highest number of games / visits is selected.
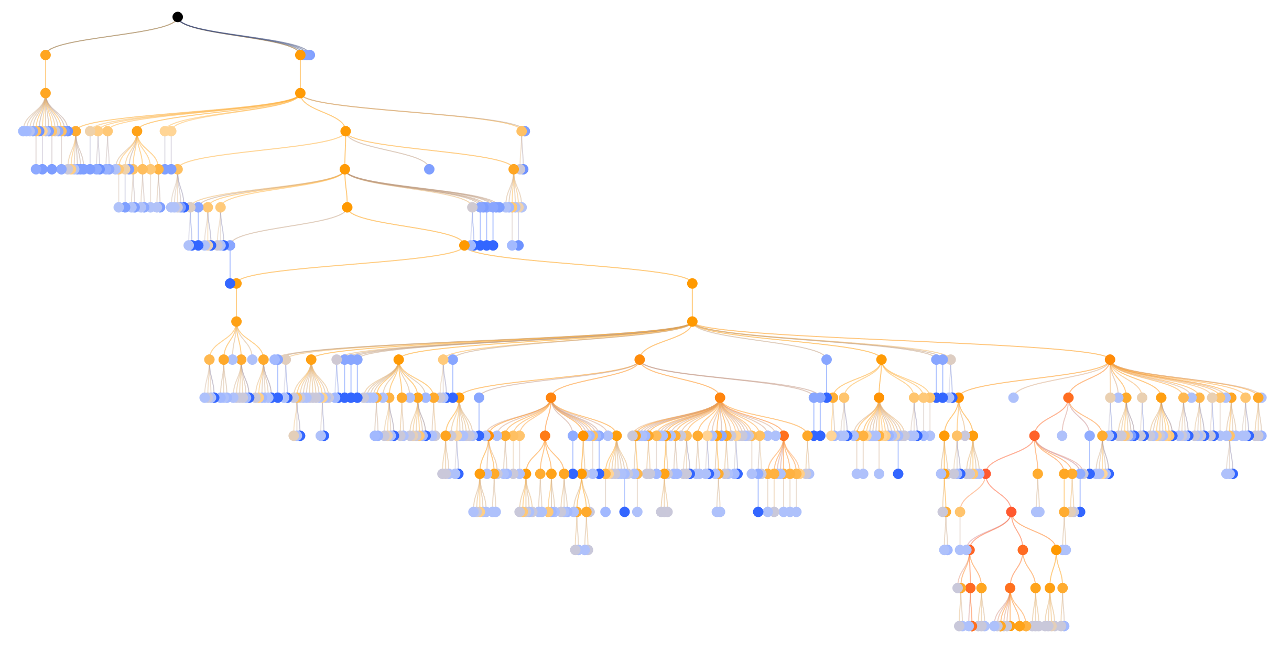
Unevenness of the tree in the MCTS algorithm
The ratio of the games won to the total number of games can be described as the odds of winning for each turn. This value is in the range from 0 to 1. The larger this number is, the more the algorithm is sure that this move will lead it to victory. The significance of this relationship for a better move shows how the program assesses its chances of winning the game as a whole.
But let's see what is meant by the end of the game? In Go, no one finishes the game to the end; the game stops when its result is obvious. For the machine, this approach is incomprehensible and, therefore, the games go on until none of the players can put a stone on the board without breaking the rules. In this case, the course in the field, surrounded by its stones (the so-called eye) is prohibited. As a result, at the end of the game, the field looks something like this:

For scoring, count free points, surrounded by each player, as well as the number of stones on the board. These are the so-called Chinese rules of counting. It is the Chinese counting system that is used so that you can safely place stones in your territory without losing points. The Japanese rules would have to spend time determining the need to put a stone into its territory, because extra stones take away points.
It is worth mentioning the rule Ko. Let me remind you that the Ko rule is a rule prohibiting repetition on the board of a position that was before the previous move.
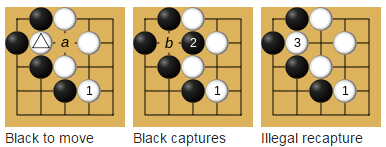
How to implement this rule? After all, saving the entire board and comparing each field on each turn in tens of thousands of games is too resource-intensive. Here it is obviously necessary to use some kind of hash function. In go, chess, and other games, an algorithm called Zobrist hash is used for such tasks. In general, this algorithm was originally invented for a program that plays go. It consists in the fact that for each board field and for each figure (in the case of the first there are only two), a random value is generated. When we put a stone in an empty field, we take from the table the value corresponding to this field and the color of the stone, and perform the XOR operation with the hash of the previous position. If the stone is removed from the position, then in the same way we make an XOR hash with the value of this stone in this position from the table.
It looks like this:
black_stone = 1 white_stone = 2 … table = zobrist_init(board_size) ... h = h XOR table[i][j] Where h is the current hash value of the board, i is the index of the position on the board, and j is the index of the figure (1 or 2).
This hash can also be used to cut off repetitive positions in the Monte Carlo tree, so as not to waste time assessing positions that have already been visited.
Also, you can use this definition of the Ko rule: You cannot remove one and only one stone from the board if it was put on the previous move, while it removed only one opponent’s stone from the board.
Here, instead of checking the status of the board, you can simply make sure that this condition is met.
A simple Monte Carlo algorithm and the number of random batches of several thousand is enough for a more or less meaningful game of the program. But, the accuracy of the random games also affects the accuracy of the algorithm. If you make them less random and more like a real game, then you can significantly improve efficiency. After all, when a person makes a move and calculates the approximate consequences of his decision, he uses knowledge from the context of the game.
To make random games not random, many different approaches are used. In fact, this is where the creative stage begins and the nature of the game of the future AI is set.
Many programs use templates for this purpose. For example, MoGo and Fuego Go use 3x3 templates, where the field in question is located in the center. In GNUGo, patterns are much more diverse and more complex.
As an example, let's consider this 3x3 size pattern:
["XO?", "Oo", "?o?"] Here X and O are colors, x and o are “not X” and “not O” respectively,? - this is any value of the field, and a dot means an empty field. This pattern imitates cutting stones of one color or cutting protection for stones of a different color. That is, it will be good for both players. In the center is the very empty field where we want to put a stone.
In fact, such templates do not need much. Just a dozen is enough for the game to resemble a real game. Templates can be found in publications-descriptions of programs like Fuego and MoGo or in their code.
To save CPU time in a variety of random games, patterns are applied only to the surroundings of the last turn. This is in good agreement with the peculiarities of Go, where a move is usually made in response to an opponent’s move, somewhere nearby.
Other heuristics are also used in conjunction with templates. Here you can not limit the flight of fancy and come up with something of their own. Here is an example of the heuristics used by Pachi, KGS 2d:
- Nakade is a common group killing technique. The move is made inside the group to prevent the opponent from creating two eyes. The program monitors such situations and puts the stone at a vital point.

- If the opponent put his group in atari (one move before the group’s death) with the last move, we capture it, if our group is in atari, we try to escape or capture the opponent’s next group.
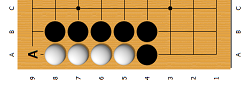
- If the enemy with the last move reduced the number of breathing points of his group to 2, we try to put the group in atari. If our group finds itself in such a situation, then we are trying to run away or to place the neighboring group of the enemy in atari.
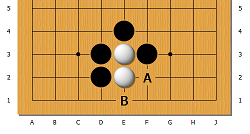
Each heuristic in random batches is applied, as well as templates, not for the whole board, but only for its part. They can be used both together and in turn. The second option is more preferable to save resources.
During the search in the tree, for the Monte Carlo algorithm all the moves are equal. In the values of each new node are zeros. The program does not understand which of these moves is good or bad, until it plays several random games. In order to cut off the consideration of obviously useless or bad moves at an early stage, or to give priority to obviously good ones, heuristic functions are also used during the search.
Here, the same functions can be used as during random games, but only applied to the entire board. Additional heuristics not included in random lots may be used.
For example, if the move in question is located on the 1st or 2nd line of the board, and there is not a single stone around, then this move must be assigned a negative priority. If we want to put a stone on the 3rd line under the same conditions, then we would like to assign a positive priority to this move. This move should be considered by the algorithm in more detail.
To encourage progress, add the priority value to the number of games and to the number of winnings:
good_node.games = GOOD_MOVE_PRIOR; good_node.wins = GOOD_MOVE_PRIOR; For the opposite effect, the value is added only to the number of games:
bad_node.games = BAD_MOVE_PRIOR; bad_node.wins = 0; Thus, good positions for the algorithm look more promising, because he sees that they have many victories. In the case of negative priority, everything is exactly the opposite; for the algorithm, this will be a loser move, losing in most of the random games.

Check for stones in the vicinity of point C7. The metric of distance of city blocks is used.
And so, let's say, the engine is ready and you want to test it. If you want to connect to it a graphical interface or enable it to play with it online, you must use Go Text Protocol (GTP), the generally accepted standard for go-programs. With it, you can connect your creation to the graphical interface or run it on the KGS server.
The protocol is quite simple to implement, you will need to teach the bot to understand several commands:
- list_commands - queries the bot for a list of supported commands, the result should be a list with the line end character after each command.
- boardsize n - tells our program that the game will be played on a board of size n
- komi 6.5 - the team says that Komi is used in 6.5 points
- clear_board - create a new, empty board of size n
- genmove w - request for the engine to generate a move for whites (b will be for black)
- play b A1 - means that the player placed the black stone in point A1
The bot's response to each command must begin with the symbol “=”. This sign also means that your program has understood the command and is waiting for the next one. If the command is unknown, a question mark is displayed.
As an example, I’ll give an exchange of messages in a real game:
list_commands = boardsize list_commands name play clear_board komi quit genmove boardsize 9 = komi 6.5 = clear_board = play b E5 = genmove w = d4 In this example, the game goes on a 9x9 board, the person plays for black at point E5, the program answers at point d4. Please note that the coordinates of the points on the board have a symbolic and alphabetic part. This is the so-called naming of cells in chess notation .
Now you can use your engine in graphics programs that support the GTP protocol, such as Drago .
If you want to run your bot on the KGS server, you will need to use the kgsGTP proxy program .
To run, type the command:
java -jar kgsGtp.jar kgsgtp.ini Here kgsgtp.ini is the settings file. Sample file:
name = login_boot
password = password_boot
room = Computer Go // the name of the room where the bot goes
mode = custom // mode of operation, more details in the kgsGtp manual
game Notes = "Hello I knew here" // Greeting line
rules.boardSize = 9 // size of the board on which the bot plays
undo = f // support the “take back” command
engine = path / to / program
opponent = login_opponenta
If the opponent option is specified, the program can only play with the person specified in it. This is useful for debugging a bot.
Of course, this is not all that is used in AI for playing Go. Outside the article were such interesting things as All-Moves-As-First and RAVE, Common Fate Graph, convolutional neural networks, etc. But for the beginning of this material will be quite enough. In the list of sources you will find a lot of additional information.
List of sources
senseis.xmp.net/?ComputerGo
hal.inria.fr/inria-00117266v3/document
users.soe.ucsc.edu/~glin/docs/Fuego_Fall09Report.pdf
pasky.or.cz/go/pachi-tr.pdf
pdfs.semanticscholar.org/87b8/9babfa66c3bc33ad579e59e65321fb4b6d48.pdf
github.com/pasky/michi
www.cs.cmu.edu/afs/cs/user/mjs/ftp/thesis-program/2008/abstracts/lowEA.pdf
arxiv.org/pdf/1412.6564v2.pdf
hal.inria.fr/inria-00117266v3/document
users.soe.ucsc.edu/~glin/docs/Fuego_Fall09Report.pdf
pasky.or.cz/go/pachi-tr.pdf
pdfs.semanticscholar.org/87b8/9babfa66c3bc33ad579e59e65321fb4b6d48.pdf
github.com/pasky/michi
www.cs.cmu.edu/afs/cs/user/mjs/ftp/thesis-program/2008/abstracts/lowEA.pdf
arxiv.org/pdf/1412.6564v2.pdf
My bot:
Source: https://habr.com/ru/post/311392/
All Articles