8 myths about deduplication
It's time to look at all the myths and find out where the truth is in deduplication issues for data arrays.

Despite the fact that the deduplication technology has been known for quite some time, but only now the technologies used in modern data arrays have allowed her to experience a second birth. In all modern data arrays, deduplication is currently used, but the presence of this function in the array does not mean that it will give significant advantages for your data.
Unfortunately, a large number of administrators are taken "on faith" and believe that deduplication has unlimited possibilities.
It doesn't matter if you are a tier-1 storage system administrator, archive storage, or all-flash hybrid storage systems , you will be interested in exploring myths and legends of deduplication to avoid annoying mistakes when designing or working with your storage systems.
')
While deduplication has become available both for arrays that store your productive data, and for arrays that store backup data, the deduplication ratio on these arrays can be completely different. Architects very often believe that the coefficient achieved on an archived array can be applied to productive storage.
Deduplication is an automatic process that exists on many arrays of well-known manufacturers, but the potential coefficient you can get is different for arrays of different types. As a result, for example, if you need an array of 100TB, and you consider a factor of 10: 1, then you will acquire storage under 10TB, or, say, if you evaluate the ratio as 2: 1, therefore, you will acquire storage of 50TB - in the end, these completely different approaches lead to a completely different purchase price! You must, in practice, understand what coefficient you can get on your productive data before making a choice in favor of a particular model with a certain volume.
When building configurations of data sets for various operational storage and backup storage tasks, one often faces difficulties in correctly determining the deduplication factor. If you are interested in the subtleties of architectural design of arrays for deduplication, this discussion is for you.
At a minimum, understanding at the basic level the 8 myths below will allow you to consciously understand deduplication and evaluate its coefficient for your data.
Is it true that if one vendor offers a deduplication ratio of 50: 1, this is five times better than the alternative 10: 1 offer? You need to check and compare the total cost of ownership! Deduplication can reduce resource requirements, but what are the potential savings in volume? 10: 1 reduces the size of the stored data (reduction ratio) by 90%, while a 50: 1 ratio increases this figure by 8% and gives a 98% reduction ratio (see chart below). But this is only 8% of the difference ...
In general, the higher the deduplication rate, the less advantages there are for reducing the amount of data, according to the law of diminishing returns . The explanation of the law of diminishing returns may be as follows: the additionally applied costs of one factor (for example, the deduplication coefficient) are combined with a constant amount of another factor (for example, the amount of data). Consequently, new additional costs for the current volume provide less and less resource savings.
For example, you have an office where clerks work. Over time, if you increase the number of clerks without increasing the size of the room, they will get in the way of each other’s feet, and perhaps the costs will exceed revenues.

Fig. 1 Increased deduplication ratio and reduced storage
Deduplication reduces the amount of stored data by removing duplicate data sequences from the pool. Deduplication can be at the file level, block level, or at the application or content level. Most products combine deduplication with compression to further reduce the amount of stored data. While some manufacturers do not share these terms, some separate them and introduce terms such as “compaction”, which, in essence, is simply another name for “deduplication plus compression”. Unfortunately, there is no unique definition of deduplication. At the philistine level, it will be important to you how you can save on disk resources of your storage and backup system using deduplication. Below we will cover this topic.
Speaking about the line of HPE storage and backup systems, it is important to note that both storage systems and backup systems have interesting functionality that allows customers to save on disk resources.
For the storage systems of operational data in the 3PAR array, a whole complex of utilities and mechanisms has been developed, which allows reducing the amount of data on the productive array.
This complex is called HPE 3PAR Thin Technologies and consists of several mechanisms:
All three technologies are available free of charge and without time or volume restrictions for any 3PAR storage system, including those installed with our customers, for more information about these technologies .
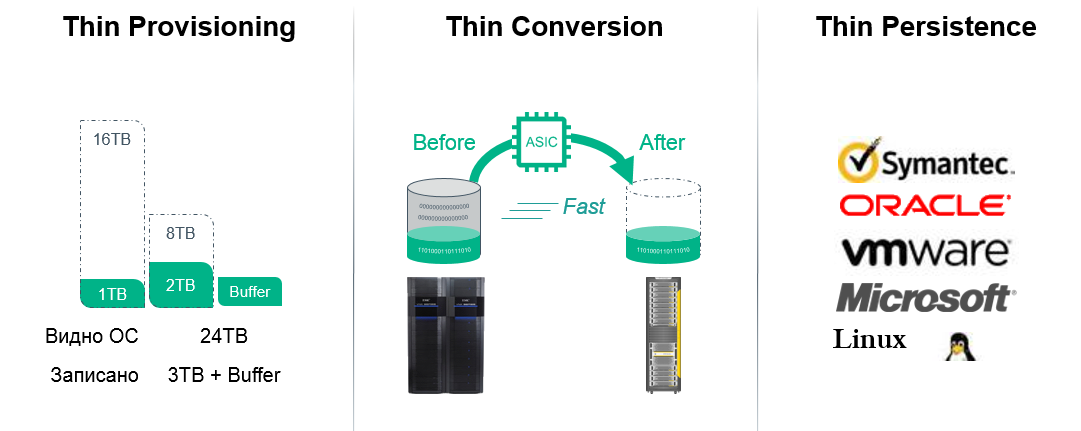
Fig. 2 Thin technologies in 3PAR arrays
Storage designers use various deduplication algorithms. Some of them require a lot of CPU resources and are more complicated than others, therefore, it shouldn’t be surprising that the deduplication ratio varies quite a lot.
However, the biggest factor affecting what deduplication rate you get is how much duplicate data you have. For this reason, backup systems containing multiple copies of the same data (daily, weekly, monthly, quarterly, annual) have such a high deduplication ratio. While operational storage systems have an almost unique set of data, which almost always results in a low deduplication ratio. In case you keep several copies of operational data on a productive array (for example, in the form of clones), this increases the deduplication factor, since apply mechanisms to reduce storage space.
Therefore, for operational storage arrays, having a ratio of 5: 1 is also wonderful, as having a ratio of 30: 1 or 40: 1 for backup systems, since this ratio depends on how many copies of productive data are stored on such arrays.
If we consider the products of HPE, then in the HPE 3PAR online storage arrays the search for duplicate sequences (for example, when virtual machines are initialized or snapshots are created) is performed on the fly on a special ASIC chip installed in each array controller. This approach allows to unload the central processors of the array for other, more important, tasks and makes it possible to enable deduplication for all data types, without fear that the array will “slip” under load. You can read more about deduplication on the 3PAR array.
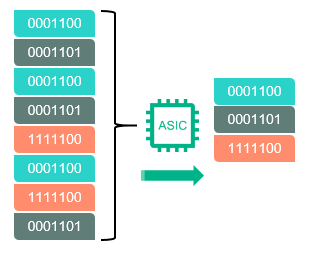
Fig.3 Deduplication in 3PAR arrays is performed on a dedicated ASIC chip
The HPE portfolio also has hardware systems for backing up data with online variable-level deduplication at the block level - HPE StoreOnce. System variants cover a full range of customers from the initial to the corporate level:

Fig. 4 HPE StoreOnce Backup System Portfolio
You can read about the advantages of StoreOnce backup systems in other articles .
It may be interesting for customers that the HPE 3PAR and StoreOnce bundle allows you to simplify and speed up the process of transferring data from the production array to the backup system without using backup software or a dedicated backup server. This bundle is called HPE StoreOnce RMC, and more about it can also be found in our article .
There should be no doubt, all data is different. Even data from the same application under different conditions will have different deduplication factors on the same array. The deduplication ratio for specific data depends on various factors:
The table below gives a superficial estimate of the deduplication ratio, depending on the type of data. It must be remembered that the deduplication coefficient on the main dataset will always be lower than the deduplication coefficient on the backup array.

Fig. 5 Estimation of deduplication ratio depending on data types and backup policies
In theory, you can mix completely different types of data in a shared storage pool for deduplication. You may feel that you have a very large set of unique data and, therefore, the probability of finding previously already recorded blocks or objects in this pool will be great. In practice, this approach does not work between unrelated data types, for example, between a database and Exchange, because the data formats are different, even if the same data set is stored. Such a growing pool all the time becomes more complex and takes more time to search for repeating sequences. The best practice is to separate pools by data type.
For example, if you perform deduplication of a single virtual machine, you will get some coefficient, if you create multiple copies of this virtual machine and perform deduplication on this pool, your deduplication ratio will increase, and if you group several virtual machines by application type and create multiple copies of these virtual machines - the ratio will increase even more.

Fig. 6. The dependence of the deduplication ratio on the number of virtual machines in the pool and the size of the data block.
This erroneous opinion appears when comparing the coefficients on the main array and the backup system. If you are storing only one copy of the data, you may see some deduplication factor greater than one. This ratio can increase if you increase the number of copies of very similar data, such as backup copies of the current database.
The graph below shows a very typical deduplication ratio curve. The application in this graph is the SAP HANA DB, but most applications show a similar curve. Your first backup shows a certain deduplication, but the big savings come from data compression. As soon as you start to keep more copies of the data in the pool, the deduplication ratio of the pool begins to grow (blue line). The coefficient of an individual backup soars up after the creation of the second copy (orange line), since at the block level, the first and second backups are very similar.
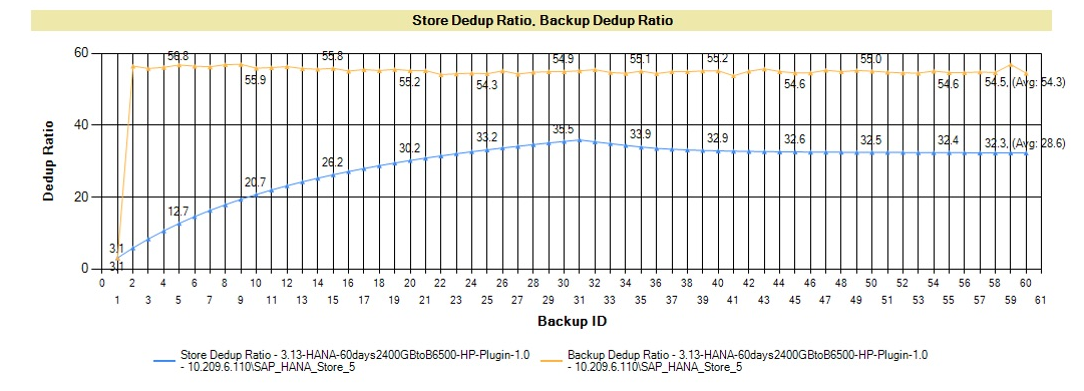
Fig. 7 Graph of the growth of the deduplication ratio with the increase in the number of backups ( more in the document ).
It would be naive to argue that there is no possibility of artificially increasing the level of deduplication. Another question - why? If you show marketing numbers, this is one thing, if you need to create an effective backup scheme, this is another. If the goal is to have the highest synthetic deduplication ratio, then you just need to store as many copies of the same data as possible. Of course, this will increase the amount of stored data, but your deduplication coefficient will soar to the skies.
Changing the backup policy also definitely affects the deduplication ratio, as can be seen in the example below for the actual data type, which compares the full backup policies and the combination of full copies with incremental and differential backups. In the example below, the best rate is obtained when using only daily full backups. However, on the same data, the storage capacity is quite different for all three approaches. Therefore, it is necessary to understand that a change in your approach to backups can quite strongly affect the deduplication ratio and the physical amount of stored data.
Every environment is unique and it is very difficult to accurately predict the actual deduplication ratio. But nevertheless, manufacturers of backup systems produce sets of small utilities for basic storage systems and backup systems, which give an idea of the type of data, the backup policy, the retention period. These utilities provide some insight into the expected deduplication ratio.
Manufacturers also have an idea of the coefficients obtained from other customers in a similar environment and industry segment and can use this information to build a forecast. While this does not guarantee that you will receive a similar coefficient on your data, at least you should look at these figures.
But the most accurate prediction of the deduplication ratio is obtained in the course of testing on real data.

Fig. 8 Changes in the deduplication ratio and the amount of data occupied depending on the backup policy on the data of a specific customer
HPE has a set of utilities and sizers that allows you to predict (with some assumption) the amount of storage systems that customers need.
It is also possible to estimate the estimated volume that we will receive after enabling deduplication on the 3PAR system in simulator mode. To do this, you need to run the evaluation command on the 3PAR online, transparently for the host:
And get a preliminary assessment:

So, there is no magic behind the concept of deduplication, and dispelling the myths cited above will allow you to better understand what your data is capable of and allow you to predict the utilization of your arrays.
It should be noted that the modern growth of SSD and reducing storage costs by 1GB on flash drives (and the cost is already equivalent to $ 1.5 per GB ) pushes issues related to the effectiveness of deduplication to the second place for operational storage, but are becoming increasingly relevant for backup systems.
By the way, there is an alternative vision of the future (without deduplication): Wikibon believes that eliminating copies of the same data is more effective than increasing the coefficient of deduplication and compression (see the link in the middle of the report ), but this approach requires a radical introduction of a whole range of technical measures, changes in the entire infrastructure, rules for simultaneous operation of applications (processing, analytics) with data so that they do not reduce performance (when implementing good tools for working with SLA) and reliability.
And, most importantly, if all this is implemented in the entire ecosystem - both software developers, and vendors, and CIO, then in a few years the savings from this will be greater than from deduplication.
What school of thought will win - time will tell.
Despite the fact that the deduplication technology has been known for quite some time, but only now the technologies used in modern data arrays have allowed her to experience a second birth. In all modern data arrays, deduplication is currently used, but the presence of this function in the array does not mean that it will give significant advantages for your data.
Unfortunately, a large number of administrators are taken "on faith" and believe that deduplication has unlimited possibilities.
It doesn't matter if you are a tier-1 storage system administrator, archive storage, or all-flash hybrid storage systems , you will be interested in exploring myths and legends of deduplication to avoid annoying mistakes when designing or working with your storage systems.
')
Data reduction ratio: there are no miracles
While deduplication has become available both for arrays that store your productive data, and for arrays that store backup data, the deduplication ratio on these arrays can be completely different. Architects very often believe that the coefficient achieved on an archived array can be applied to productive storage.
Deduplication is an automatic process that exists on many arrays of well-known manufacturers, but the potential coefficient you can get is different for arrays of different types. As a result, for example, if you need an array of 100TB, and you consider a factor of 10: 1, then you will acquire storage under 10TB, or, say, if you evaluate the ratio as 2: 1, therefore, you will acquire storage of 50TB - in the end, these completely different approaches lead to a completely different purchase price! You must, in practice, understand what coefficient you can get on your productive data before making a choice in favor of a particular model with a certain volume.
When building configurations of data sets for various operational storage and backup storage tasks, one often faces difficulties in correctly determining the deduplication factor. If you are interested in the subtleties of architectural design of arrays for deduplication, this discussion is for you.
At a minimum, understanding at the basic level the 8 myths below will allow you to consciously understand deduplication and evaluate its coefficient for your data.
Myth1. Greater deduplication ratio provides more advantages for data storage.
Is it true that if one vendor offers a deduplication ratio of 50: 1, this is five times better than the alternative 10: 1 offer? You need to check and compare the total cost of ownership! Deduplication can reduce resource requirements, but what are the potential savings in volume? 10: 1 reduces the size of the stored data (reduction ratio) by 90%, while a 50: 1 ratio increases this figure by 8% and gives a 98% reduction ratio (see chart below). But this is only 8% of the difference ...
In general, the higher the deduplication rate, the less advantages there are for reducing the amount of data, according to the law of diminishing returns . The explanation of the law of diminishing returns may be as follows: the additionally applied costs of one factor (for example, the deduplication coefficient) are combined with a constant amount of another factor (for example, the amount of data). Consequently, new additional costs for the current volume provide less and less resource savings.
For example, you have an office where clerks work. Over time, if you increase the number of clerks without increasing the size of the room, they will get in the way of each other’s feet, and perhaps the costs will exceed revenues.
Fig. 1 Increased deduplication ratio and reduced storage
Myth2. There is a clear definition of the term "deduplication"
Deduplication reduces the amount of stored data by removing duplicate data sequences from the pool. Deduplication can be at the file level, block level, or at the application or content level. Most products combine deduplication with compression to further reduce the amount of stored data. While some manufacturers do not share these terms, some separate them and introduce terms such as “compaction”, which, in essence, is simply another name for “deduplication plus compression”. Unfortunately, there is no unique definition of deduplication. At the philistine level, it will be important to you how you can save on disk resources of your storage and backup system using deduplication. Below we will cover this topic.
Speaking about the line of HPE storage and backup systems, it is important to note that both storage systems and backup systems have interesting functionality that allows customers to save on disk resources.
For the storage systems of operational data in the 3PAR array, a whole complex of utilities and mechanisms has been developed, which allows reducing the amount of data on the productive array.
This complex is called HPE 3PAR Thin Technologies and consists of several mechanisms:
- Thin Provisioning is the most efficiently implemented in 3PAR storage systems, since disk space virtualization is applied and the array uses its internal map of the stored blocks, when the array is freed up, the array does not need to be audited (garbage collection), the released blocks are immediately ready for further use ... Allows you to select exactly as much volume as it needs, but take on the array only as much as this volume is physically recorded.
- Thin Conversion is a technology that allows real-time conversion of volumes from old HPE data sets (3PAR, EVA), EMC, Hitachi, and other manufacturers to thin volumes (which use Thin Provisioning) on a 3PAR array with a reduction in volume on the target device.
- Thin Persistence and Thin Copy Reclamation is a technology that allows the 3PAR array at a very low granular level to understand the operation of all popular file systems and hypervisors and, in the case of deleting files (freeing up physical volume), transfer the corresponding blocks into a pool of free resources.
- Thin Deduplication is a technology that allows you to use deduplication on a productive array in real time, without a significant performance drop.
All three technologies are available free of charge and without time or volume restrictions for any 3PAR storage system, including those installed with our customers, for more information about these technologies .
Fig. 2 Thin technologies in 3PAR arrays
Myth3. The deduplication coefficients on the main array are the same as on the backup array.
Storage designers use various deduplication algorithms. Some of them require a lot of CPU resources and are more complicated than others, therefore, it shouldn’t be surprising that the deduplication ratio varies quite a lot.
However, the biggest factor affecting what deduplication rate you get is how much duplicate data you have. For this reason, backup systems containing multiple copies of the same data (daily, weekly, monthly, quarterly, annual) have such a high deduplication ratio. While operational storage systems have an almost unique set of data, which almost always results in a low deduplication ratio. In case you keep several copies of operational data on a productive array (for example, in the form of clones), this increases the deduplication factor, since apply mechanisms to reduce storage space.
Therefore, for operational storage arrays, having a ratio of 5: 1 is also wonderful, as having a ratio of 30: 1 or 40: 1 for backup systems, since this ratio depends on how many copies of productive data are stored on such arrays.
If we consider the products of HPE, then in the HPE 3PAR online storage arrays the search for duplicate sequences (for example, when virtual machines are initialized or snapshots are created) is performed on the fly on a special ASIC chip installed in each array controller. This approach allows to unload the central processors of the array for other, more important, tasks and makes it possible to enable deduplication for all data types, without fear that the array will “slip” under load. You can read more about deduplication on the 3PAR array.
Fig.3 Deduplication in 3PAR arrays is performed on a dedicated ASIC chip
The HPE portfolio also has hardware systems for backing up data with online variable-level deduplication at the block level - HPE StoreOnce. System variants cover a full range of customers from the initial to the corporate level:
Fig. 4 HPE StoreOnce Backup System Portfolio
You can read about the advantages of StoreOnce backup systems in other articles .
It may be interesting for customers that the HPE 3PAR and StoreOnce bundle allows you to simplify and speed up the process of transferring data from the production array to the backup system without using backup software or a dedicated backup server. This bundle is called HPE StoreOnce RMC, and more about it can also be found in our article .
Myth4. All data is the same.
There should be no doubt, all data is different. Even data from the same application under different conditions will have different deduplication factors on the same array. The deduplication ratio for specific data depends on various factors:
- Data type — data that has undergone software compression, metadata, media streams, and encrypted data always have a very low deduplication factor or are not compressed at all.
- The degree of data variability - the higher the amount of daily data changes at the block or file level, the lower the deduplication factor. This is especially true for backup systems.
- Shelf life - the more copies you have, the higher the deduplication ratio.
- Backup policy - a policy of creating full day copies, as opposed to a policy with incremental or differential backups, will give a greater deduplication ratio (see the study below).
The table below gives a superficial estimate of the deduplication ratio, depending on the type of data. It must be remembered that the deduplication coefficient on the main dataset will always be lower than the deduplication coefficient on the backup array.
Fig. 5 Estimation of deduplication ratio depending on data types and backup policies
Myth5. Grouping disconnected data types increases deduplication
In theory, you can mix completely different types of data in a shared storage pool for deduplication. You may feel that you have a very large set of unique data and, therefore, the probability of finding previously already recorded blocks or objects in this pool will be great. In practice, this approach does not work between unrelated data types, for example, between a database and Exchange, because the data formats are different, even if the same data set is stored. Such a growing pool all the time becomes more complex and takes more time to search for repeating sequences. The best practice is to separate pools by data type.
For example, if you perform deduplication of a single virtual machine, you will get some coefficient, if you create multiple copies of this virtual machine and perform deduplication on this pool, your deduplication ratio will increase, and if you group several virtual machines by application type and create multiple copies of these virtual machines - the ratio will increase even more.
Fig. 6. The dependence of the deduplication ratio on the number of virtual machines in the pool and the size of the data block.
Myth6. Your first backup will show you the expected deduplication ratio.
This erroneous opinion appears when comparing the coefficients on the main array and the backup system. If you are storing only one copy of the data, you may see some deduplication factor greater than one. This ratio can increase if you increase the number of copies of very similar data, such as backup copies of the current database.
The graph below shows a very typical deduplication ratio curve. The application in this graph is the SAP HANA DB, but most applications show a similar curve. Your first backup shows a certain deduplication, but the big savings come from data compression. As soon as you start to keep more copies of the data in the pool, the deduplication ratio of the pool begins to grow (blue line). The coefficient of an individual backup soars up after the creation of the second copy (orange line), since at the block level, the first and second backups are very similar.
Fig. 7 Graph of the growth of the deduplication ratio with the increase in the number of backups ( more in the document ).
Myth 7. You cannot increase the level of deduplication
It would be naive to argue that there is no possibility of artificially increasing the level of deduplication. Another question - why? If you show marketing numbers, this is one thing, if you need to create an effective backup scheme, this is another. If the goal is to have the highest synthetic deduplication ratio, then you just need to store as many copies of the same data as possible. Of course, this will increase the amount of stored data, but your deduplication coefficient will soar to the skies.
Changing the backup policy also definitely affects the deduplication ratio, as can be seen in the example below for the actual data type, which compares the full backup policies and the combination of full copies with incremental and differential backups. In the example below, the best rate is obtained when using only daily full backups. However, on the same data, the storage capacity is quite different for all three approaches. Therefore, it is necessary to understand that a change in your approach to backups can quite strongly affect the deduplication ratio and the physical amount of stored data.
Myth8. There is no way to predict the deduplication rate
Every environment is unique and it is very difficult to accurately predict the actual deduplication ratio. But nevertheless, manufacturers of backup systems produce sets of small utilities for basic storage systems and backup systems, which give an idea of the type of data, the backup policy, the retention period. These utilities provide some insight into the expected deduplication ratio.
Manufacturers also have an idea of the coefficients obtained from other customers in a similar environment and industry segment and can use this information to build a forecast. While this does not guarantee that you will receive a similar coefficient on your data, at least you should look at these figures.
But the most accurate prediction of the deduplication ratio is obtained in the course of testing on real data.
Fig. 8 Changes in the deduplication ratio and the amount of data occupied depending on the backup policy on the data of a specific customer
HPE has a set of utilities and sizers that allows you to predict (with some assumption) the amount of storage systems that customers need.
- For online data storage there is a free program for assessing the current utilization of the array and estimating space savings, in case of switching to 3PAR .
- To assess resource utilization in the operational array and build a forecast for data growth on already installed systems, subject to permission to send an array of information about its status to HPE technical support: www.storefrontremote.com
- A similar program to assess the utilization of backup systems.
It is also possible to estimate the estimated volume that we will receive after enabling deduplication on the 3PAR system in simulator mode. To do this, you need to run the evaluation command on the 3PAR online, transparently for the host:
checkvv -dedup_dryrun { } And get a preliminary assessment:
So, there is no magic behind the concept of deduplication, and dispelling the myths cited above will allow you to better understand what your data is capable of and allow you to predict the utilization of your arrays.
It should be noted that the modern growth of SSD and reducing storage costs by 1GB on flash drives (and the cost is already equivalent to $ 1.5 per GB ) pushes issues related to the effectiveness of deduplication to the second place for operational storage, but are becoming increasingly relevant for backup systems.
By the way, there is an alternative vision of the future (without deduplication): Wikibon believes that eliminating copies of the same data is more effective than increasing the coefficient of deduplication and compression (see the link in the middle of the report ), but this approach requires a radical introduction of a whole range of technical measures, changes in the entire infrastructure, rules for simultaneous operation of applications (processing, analytics) with data so that they do not reduce performance (when implementing good tools for working with SLA) and reliability.
And, most importantly, if all this is implemented in the entire ecosystem - both software developers, and vendors, and CIO, then in a few years the savings from this will be greater than from deduplication.
What school of thought will win - time will tell.
Materials used
Source: https://habr.com/ru/post/311296/
All Articles