Pro release and development of True Image 2017 - all hardcore features are in place
We recently had a holiday - released the release of True Image 2017, on which we worked for a year. There are a lot of changes, but the first thing that catches your eye is the “casual” minimalistic design. If our first releases were tools of advanced users and system administrators, over the past few years, the global popularity of the product has been such that they will be backed up by very, very different people. Including those who are not particularly distinguishes the monitor from the system unit.
Therefore, our approach is to preserve all the good old hardcore, flexibility of settings and many non-trivial tools, but focus on simplifying the interface.
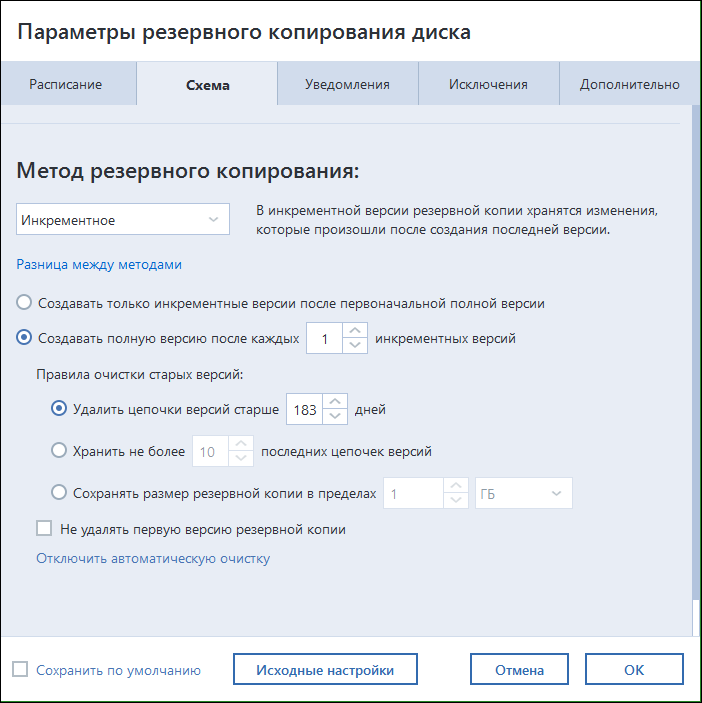
All settings are in place
')
Even in this release, we learned how to make a local backup of iOS and Android on your desktop, back up your Facebook profile (thanks to the user Masha Bucket), worked with the archive architecture, and so on. I'll tell you about the main features and difficulties in their development.
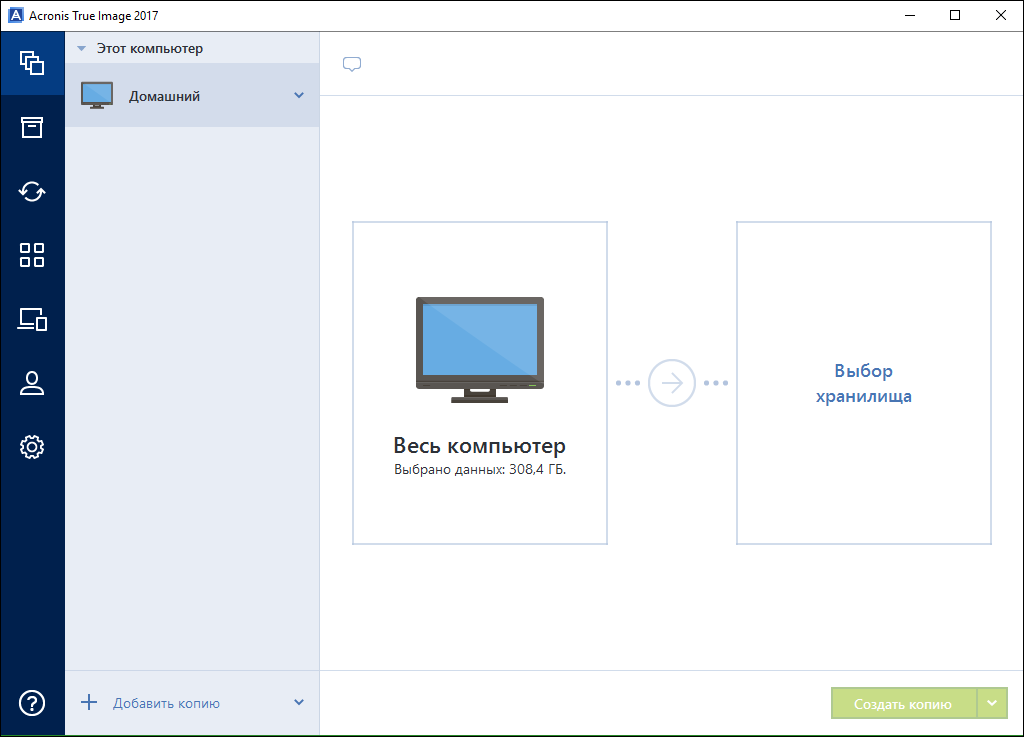
In the first place are the main actions with obviously good defaults.
The first mode with which we historically began, sector-based backup, was naturally preserved in the 2017 release. Let me remind how it works: you make a complete physical copy of the hard disk and you can work with it further as you like. This is very convenient when recovering data (so that nothing is corrupted on a barely breathing disk). Even such disks (more precisely, files with images) can be mounted directly in Acronis True Image and seen in the explorer as separate R / O disks.
Traditional backup is done a little differently, according to an iterative scheme. First, a full image is taken (all files on the hard disk, excluding exceptions), then a difference is added to the backup. The schedule and all the details are very flexible, and for “casual” users there are optimal defaults.
Of course, we still suggest making an emergency disk or an emergency flash drive to boot from. We actually write Linux to the USB flash drive with recovery tools (in the case of a Mac, their native standard disaster recovery tools and our utility are written there). You can use this as, in fact, the tool of Next-Next-Finish, without special knowledge, or you can switch the screen and make something of your own.
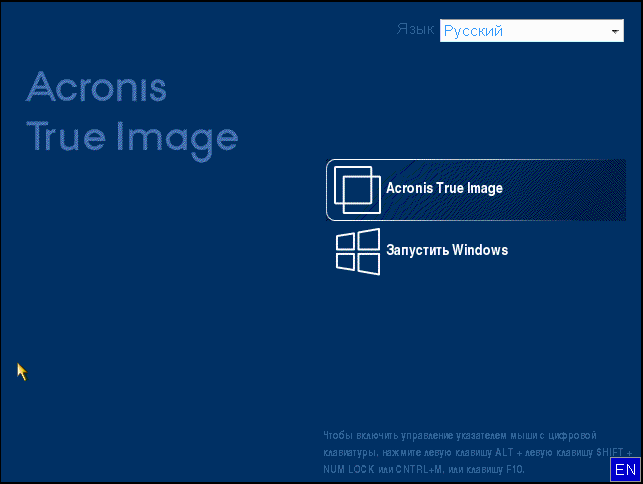
Boot branch selection
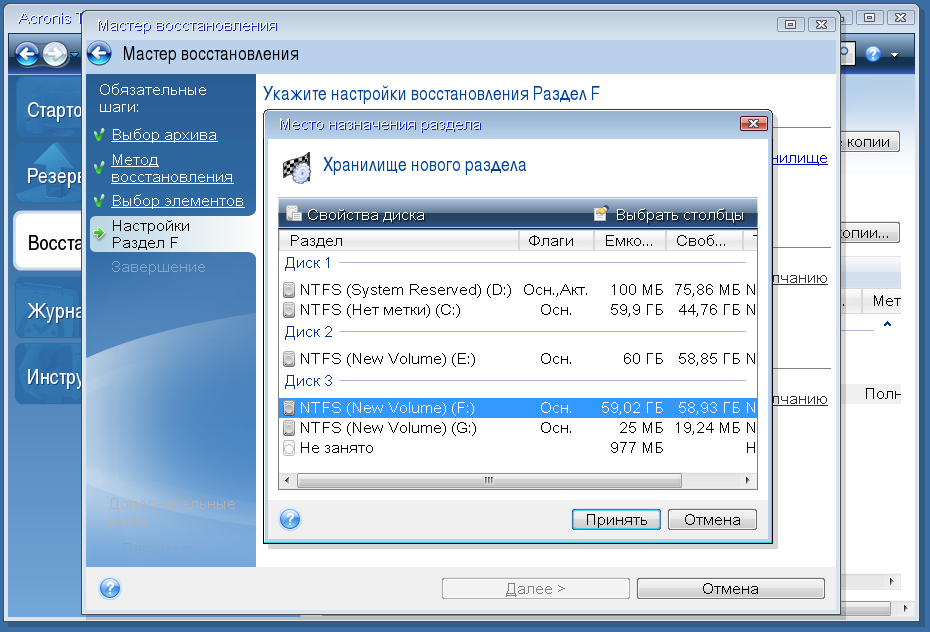
Recovery utility
The Russian version has a full-fledged history of the restoration of drivers and their knurling on a new system (in the United States there are legal difficulties with this). The story is that if you take a backup with XP, Vista or Win7, and then add it to a new computer (with a different hardware), nothing will just start. You will need to reinstall all the drivers, in fact, once again configure the entire OS. As a result, about 8 years ago, we dug deep into the reverse of the Windows code and wrote our own driver installer. Now you just need to move to a new configuration, make a recovery and show where the drivers for the changed hardware lie. We have a separate utility for this, it is bundled (that is, free for users of the 2017 release), but you need to download it separately.
Another challenge is the transfer of MBR / EFI data. We have a script where we can take an MBR OS and create a branch for it in EFI so that it loads properly and supports large disks. Now this choice arises for users who want to roll the old OS on a new machine. Here are a few more details about the low level with different branches of conversions:
Naturally, since we have so well dismantled the lower level, you can make an emergency tool right on the local computer. We are creating a new boot branch in EFI, where we write our modified compact Linux and recovery tools. If you have something covered, you can try to boot from the same computer on an alternative branch and recover from the backup. This protects users from laziness who do not want to carry a hard drive to a computer for backup on a schedule (and at the same time they are not backed up to the cloud). However, of course, this will not save iron from complex failures, so a separate carrier with your data is still important.
Another interesting thing is automapping. We already had it, but in this release it has become much smarter. The fact is that recovery is happening now from almost any carrier, and even there can be several such carriers. For example, a network resource, a local copy and something else. If the system has significantly changed since the last iteration of the backup (for example, you roll back a year ago, this happens, for example, when installing a new workplace in some companies), then you need to correctly understand where and how to restore it. A typical example is another layout of a hard disk. Another case: when the backup is old, but from this computer, and you do not want to wait for a full recovery, you can try to exclude something that is clearly not damaged. To not wait a couple of hours. Our auto-code allows you to quickly get the difference and correctly recover in such cases.
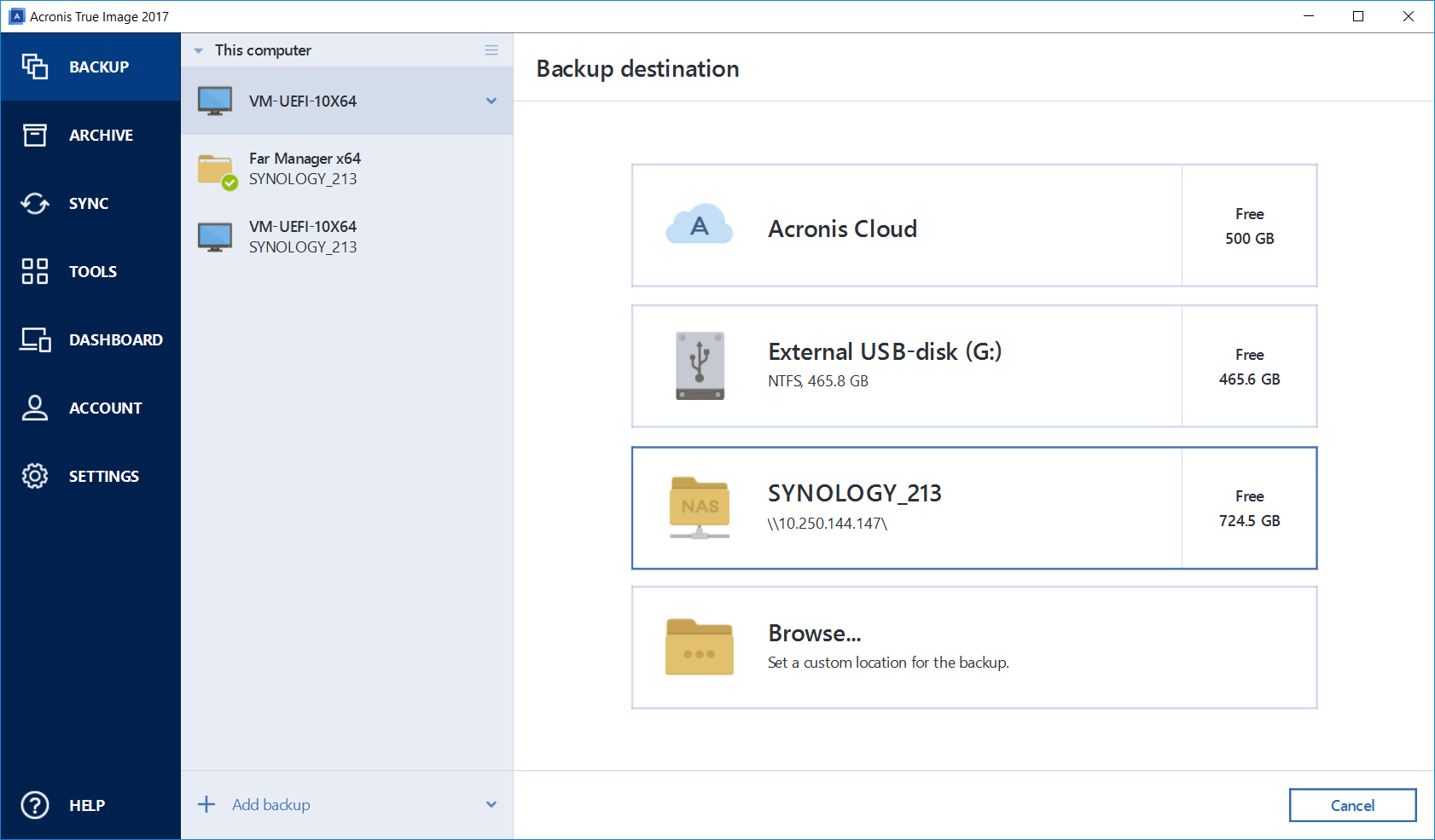
Network backup
And yes, just in case, I’ll add that all the old things, like “everything on my grandmother’s computer is backed up directly to a USB flash drive that is stuck in the back” or “on my virtual machine you can restore the backup of a girl’s home computer while I have it at the weekend”, they still remained.
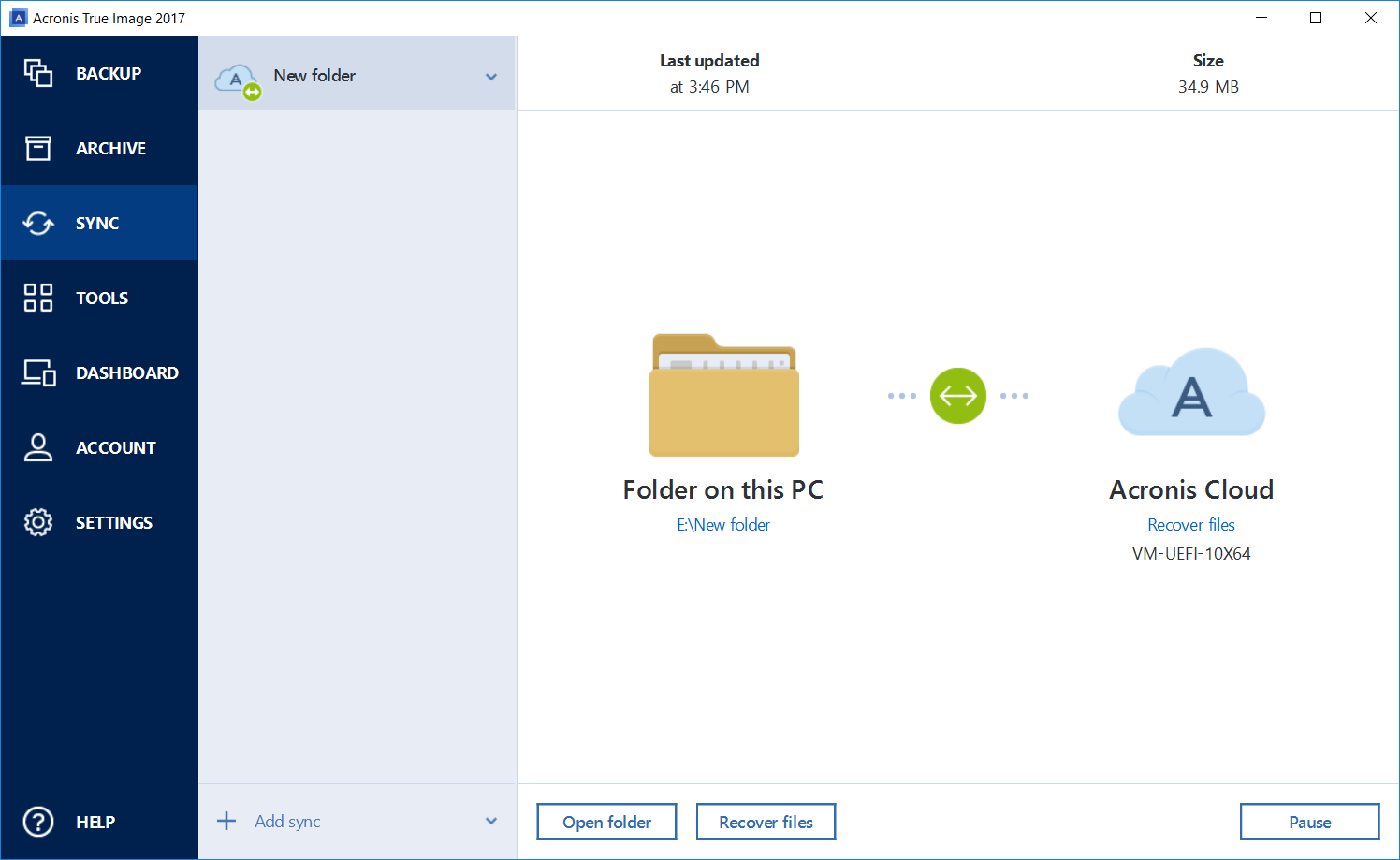
Folder synchronization
We pretty much sifted through all the technology of mobile backup in the new release. The main point is that we are well aware that not everyone wants to give a copy of their data to someone’s cloud, so we have provided for the function of a local backup. The old cloud option is also available, but the local backup was very, very much in demand. We had server code in corporate development (just made for paranoids and backups of corporate devices within the network), and we decided to reuse it. To make it clearer, first I will tell you how the new scheme works:
Difficulties were almost everywhere. First, of course, traffic, activation from the background and power consumption on new versions of iOS and Android. In general, this is solved relatively simply, and there were ready-made recipes. After the first full backup, as a rule, we are talking about a few megabytes of new photos, a couple of kilobytes of contacts and other user information. We rewrote the code responsible for the fill: chunks are not torn, they are well downloaded, even after a daily break in the network. Contacts are now the first in priority. At the same time, the cloud fill was updated (in case the backup is not local), now the contacts can be seen immediately after they were received, without even waiting for the end of the chunk.
It was quite nontrivial to establish a connection between the phone and the desktop. We tried many methods until we stopped at QR codes - you need to take a picture of the QR code from the desktop screen in the application. But even in this version it was rather difficult: at first we sewed a full-fledged SSL certificate into the visual code immediately, and not all library readers read it. I had to greatly reduce QR and install a new key exchange protocol.
The discovery itself is done at once in different ways, so even if you run the operating system inside a virtual machine (as we like to do), the phone will find its pair. A frequent home case is when the phone is connected via Wi-Fi, and the laptop is connected with a local cable. Rezolv goes on IP4, bonjour services and hostname. Unfortunately, Russian Yota users still remain without this feature: their “provider” modems that distribute Wi-Fi create NAT, for which it is rather difficult to find something.
About the reuse of server code is also a separate story. Initially it was a Linux server, which theoretically could be ported, for example, under Win. In this case, the entire logic of the component is designed so that it has a controlling server, which gives commands. As a result, with a corporate backup, we create a microserver that acts as a command center for this subnet. In the home case, however, such a “nanoserver” can be said to be emulated on the desktop. More precisely, the component simply sends requests, and the desktop, in the case of a local backup, gives answers itself (in the case of the cloud, the answers are given by the remote server). This component itself was required for, in particular, the console to find out what has already been saved and what is not.
Recovery also goes through the mobile application, but with the active launch via the GUI. Well, and, of course, most of the data can be migrated between different devices: for example, if you are moving from iOS to Android, dragging photos is the simplest thing.
If you have just hijacked the page - this, in general, is not a very big problem, most often, it can be restored by regular means. If Facebook unexpectedly banned you, you are unlikely to pull something out. If your page dies due to technical failure on their side - too. Sometimes the user himself accidentally deletes something (for example, a single photo) and really wants to recover. In general, many asked if it was possible to back up a Facebook profile. Yes you can. Now we do it.
When you start the profile copy tool from the desktop, the Fb page opens, where you need to allow a special application to access your data. This is a gateway for the Facebook API, in fact, a token repository for backup work. Then you can limit on Facebook the “visibility” of your profile through the API, and we can start copying.
Not everything can be copied. For example, you can not take and keep the count of friends, Facebook very carefully (unlike many other personal data) protects its main property. But it will turn out to take all the photos, the whole wall, all the messages and so on. Photos and videos, in which case, you can quickly restore - the API allows you to backfill them and not show updates in the feed, but, of course, there will be no likes and comments on them. This data is not backfilled in any way, which, in general, is quite explicable. Your timeline is also not restored: in contrast to the photo, all entries will be dated back-fill time. Your likes will be saved in the backup, but they will not be restored either.
The Facebook API turned out to be quite buggy, more precisely, rich in extremely illogical features. This tool was not originally intended for large tasks: as a rule, applications pull one or two requests for something extremely specific, but not all at once. This resulted in the fact that the same incremental backup is very difficult to do. For example, to quickly get the difference between the current and the previous state on a known date is almost impossible. There are no regular methods and there will be no - this seems to be part of Facebook’s security policy. I had to think carefully about the organization of algorithms in the existing limitations. As a result, they dig out strongly, but found a balance. The second point - there are restrictions with the token. The longest token is not eternal, lives 60 days. And, according to the logic of Facebook, after 60 days you need to go back to the dashboard and press a button. Regular web tokens are renewed when the user is active: when you enter your profile and you have a cookie mentioning such a token, it is updated. We work without live approach, in a separate session. Fortunately, on the other hand, we are not the manufacturers of SmartTV. They have users get the code on the phone or desktop and clog it from the remote to the TV every two months. Fortunately, we have just one button.
Testing was very fun. Facebook allows you to create test virtual users who are not visible on the main network. Unfortunately, these "mannequins" do not know how to like each other, can not comment and have many other restrictions. As a result, we created our own “live” users, the main of which eventually became Masha Bucket (it can still be found on the net, but we cleaned the profile). In the final, we worked with the profiles of our top managers - we needed very “bloated” profiles of people who had led an active network life for many years and today lead. As a result, the volume of the backup began to be measured by one of the employees, there could be explanations for tickets like: “With Facebook, data for 50 Ivanovs was taken, but only 48 came”.
Since this is a post about a release, and not features of development, I will leave a lot of interesting things about the implementation. But my colleagues and I will try to tell hardcore details later. In the meantime, I note that we have changed more interesting.
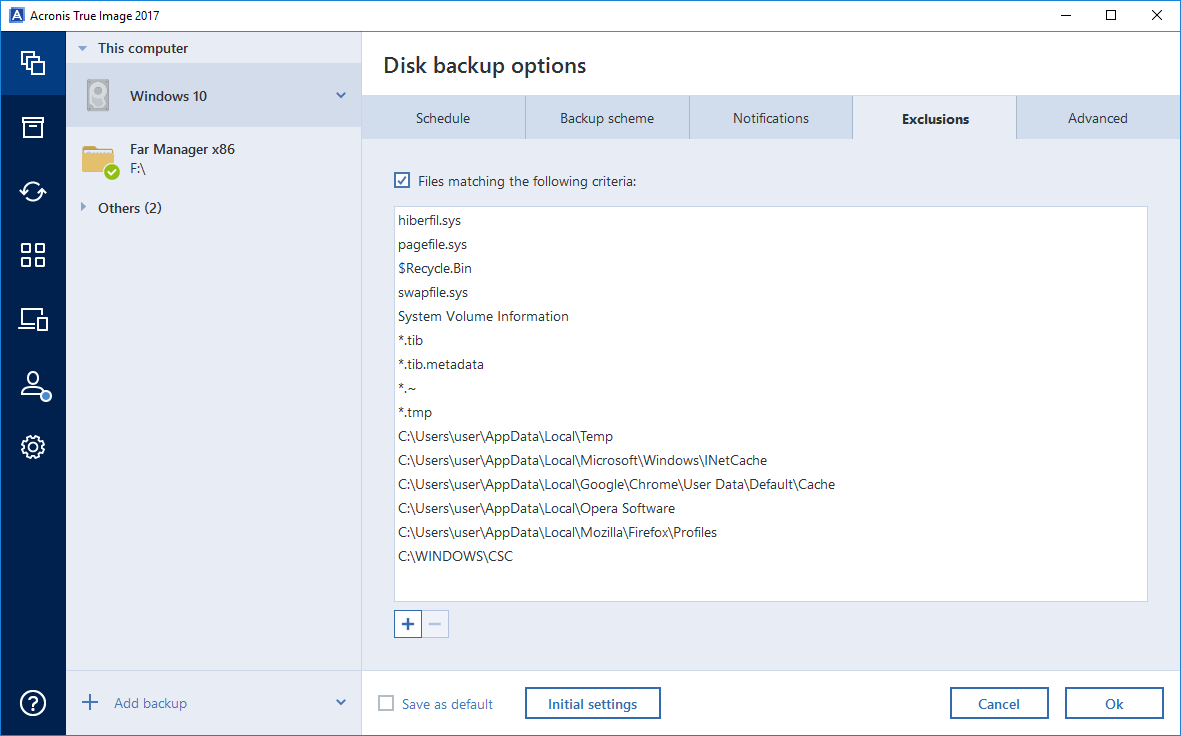
The first interesting story is the exceptions. For example, the usual backup script does not take a shadow copy of the system - it just does not make sense. To facilitate the backup (which is especially important for those who upload it over the network), we have worked very well with exceptions. In addition to temporary folders (with the exception of the browser cache - it turned out to be unexpectedly important), system logs, crash dumps and other system things, it excludes the fact that it has its own recovery tools. For example, if you do not explicitly indicate the opposite, we will not back up Dropbox, Yandex.Disk, Google Drive, OneDrive, libraries like iTunes, and anti-virus quarantines. Accordingly, we had to reverse all these tools in order to find their settings, determine from their configuration records what they are in the system, and understand what should be taken and what should not be taken. The longest running Yandex.Disk flew away from us - they store their settings in completely different ways in different versions. The first time he came across to us was in the last release - with the config in the XML file, then he started storing the settings in the SQLite database, then changing the storage format ... We drove these settings and tried to understand the logic for each exception.
In the opposite direction, too, exceptions were required. For example, in order to raise an old archive on a new system, in no case can one recover drivers from the old OS, a swap file, and so on. Accordingly, from release to release, we support such sets of rules.
We also exclude from the backup files of the same backup, if they are stored on the same disk. Otherwise, recursion would occur. At the same time, we have a new type of storage - an archive of unnecessary files (a compressed version of the folders “Disassemble1”, “Disassemble2” and so on, which the user himself shows and stores from nostalgic feelings) - we include them in backup.
The archive in which the backup data is stored has been greatly changed. We have a lot of ideas for this and last year, how to optimize it and how to make it more accessible (after all, we will “transparently” mount disks from archive files and give web access to the cloud copy). Now the local backup is stored in the second version of the archive with significant additions to the architecture, and the mobile backup is already in the third version, with a completely different architecture. I think next year we will move to the third version already everywhere. By and large, our archive is a separate file system "in itself". For example, up to 20 versions of a single file can be inside it (with or without deduplication), there is its own means of deleting old versions. There is an analogue of the garbage collector: you can "clean" the archive, and inside it forms a place for storage (in this case the file size itself will not change). Like in classic file systems, deleted files inside the archive are not deleted for optimization, but are marked up as being rewritten. Due to the dictionary structure of the archive, the release of vocabulary plots for complete removal is required. We also have our own means of internal defragmentation of the archive, but we do not use it without a direct user command (as well as never move data at the time of deletion). The fact is that any movement of information creates a threat of loss. For example, the characteristic problem is “USB-garlands”, when a user sticks devices through several adapters (we often see this among users of small laptops). Attempting to delete a file inside the archive with a change in the size of the archive will cause all data to be moved by sector. On a long garland, this causes a loss, and we had dozens of such cases in support.
We also worked on the recovery of individual files. In particular, they are now very quickly searched in the local archive.
Here is the page of the Russian release . As in the previous version, you can buy a subscription (which is important for those who back up to our cloud) or the version “once and for all”, but with a limit of 5 free gigabytes in the cloud (this is an option for those who back up on the local network or on the discs in the closet). Licenses come in 1, 3 or 5 devices (Mac or Win) and plus on an unlimited number of mobile devices.
Well, and summarize. Now our release can be used for full-fledged backup to any local or networked media, to the cloud, to synchronize data on different computers, for a number of sysadmin tasks (in particular, beloved by many Try & Decide on site), for Facebook, for backup of iOS and Android mobile devices (on the Win-tablets, a desktop version is planned), to quickly mount backups as virtual disks, restore and relocate the system, quickly search for individual data in the archive.
We will try to tell about our design, mobile development and low level with colleagues in more detail later, each about our part.
Therefore, our approach is to preserve all the good old hardcore, flexibility of settings and many non-trivial tools, but focus on simplifying the interface.
All settings are in place
')
Even in this release, we learned how to make a local backup of iOS and Android on your desktop, back up your Facebook profile (thanks to the user Masha Bucket), worked with the archive architecture, and so on. I'll tell you about the main features and difficulties in their development.
In the first place are the main actions with obviously good defaults.
Traditional desktop backup
The first mode with which we historically began, sector-based backup, was naturally preserved in the 2017 release. Let me remind how it works: you make a complete physical copy of the hard disk and you can work with it further as you like. This is very convenient when recovering data (so that nothing is corrupted on a barely breathing disk). Even such disks (more precisely, files with images) can be mounted directly in Acronis True Image and seen in the explorer as separate R / O disks.
Traditional backup is done a little differently, according to an iterative scheme. First, a full image is taken (all files on the hard disk, excluding exceptions), then a difference is added to the backup. The schedule and all the details are very flexible, and for “casual” users there are optimal defaults.
Of course, we still suggest making an emergency disk or an emergency flash drive to boot from. We actually write Linux to the USB flash drive with recovery tools (in the case of a Mac, their native standard disaster recovery tools and our utility are written there). You can use this as, in fact, the tool of Next-Next-Finish, without special knowledge, or you can switch the screen and make something of your own.
Boot branch selection
Recovery utility
The Russian version has a full-fledged history of the restoration of drivers and their knurling on a new system (in the United States there are legal difficulties with this). The story is that if you take a backup with XP, Vista or Win7, and then add it to a new computer (with a different hardware), nothing will just start. You will need to reinstall all the drivers, in fact, once again configure the entire OS. As a result, about 8 years ago, we dug deep into the reverse of the Windows code and wrote our own driver installer. Now you just need to move to a new configuration, make a recovery and show where the drivers for the changed hardware lie. We have a separate utility for this, it is bundled (that is, free for users of the 2017 release), but you need to download it separately.
Another challenge is the transfer of MBR / EFI data. We have a script where we can take an MBR OS and create a branch for it in EFI so that it loads properly and supports large disks. Now this choice arises for users who want to roll the old OS on a new machine. Here are a few more details about the low level with different branches of conversions:
Source (Archive) \ Target | BIOS booted system / target HDD <2 ^ 32 logical sectors | BIOS booted system / target HDD> 2 ^ 32 logical sectors | EFI booted system / target HDD <2 ^ 32 logical sectors | EFI booted system / target HDD> 2 ^ 32 logical sectors |
MBR not UEFI capable OS (32 bit windows or 64bit windows prior to windows vista sp1) | no changes in bootability or disk layout (1) | 1. Use as non-system disk GPT - not available for Windows XP x32 host (7) 2. It is not possible to use boolean (8) | Migrate as is. warning that the system will not be bootable in UEFI (14) | 1. Use as non-system disk GPT (20). 2. It is not possible to use the UEFI (21); |
MBR UEFI capable OS (Windows x64: Windows Vista SP1 or later) | no changes in bootability or disk layout (2) | Leave MBR, warning disk user. If you are using a copyright protection system, you can use it to copy the system (9) | Convert disk to GPT layout, fix Windows bootability (15) | Convert disk to GPT layout, fix Windows bootability (22) |
MBR no OS or non-Windows OS | 1. leave MBR. (3) 2. convert to GPT, it will not be available for Windows XP x32 host (4) | 1. leave MBR, warning disk user. (10) 2. convert to GPT, it will not be available for Windows XP x32 host (11) | 1. leave MBR. (16) 2. convert to GPT, and there will be a non-system warning (17) | 1. leave MBR, warning disk user. (23) 2. convert to GPT, warning that the disk will be converted to GPT. (24) |
GPT UEFI capable OS (Windows x64: Windows Vista SP1 or later) | no bootable in BIOS (5) | no bootable in BIOS (12) | no changes in bootability or disk layout (18) | no changes in bootability or disk layout (25) |
GPT no OS or non-Windows OS | no changes in bootability or disk layout (6) | no changes in bootability or disk layout (13) | no changes in bootability or disk layout (19) | no changes in bootability or disk layout (26) |
Naturally, since we have so well dismantled the lower level, you can make an emergency tool right on the local computer. We are creating a new boot branch in EFI, where we write our modified compact Linux and recovery tools. If you have something covered, you can try to boot from the same computer on an alternative branch and recover from the backup. This protects users from laziness who do not want to carry a hard drive to a computer for backup on a schedule (and at the same time they are not backed up to the cloud). However, of course, this will not save iron from complex failures, so a separate carrier with your data is still important.
Another interesting thing is automapping. We already had it, but in this release it has become much smarter. The fact is that recovery is happening now from almost any carrier, and even there can be several such carriers. For example, a network resource, a local copy and something else. If the system has significantly changed since the last iteration of the backup (for example, you roll back a year ago, this happens, for example, when installing a new workplace in some companies), then you need to correctly understand where and how to restore it. A typical example is another layout of a hard disk. Another case: when the backup is old, but from this computer, and you do not want to wait for a full recovery, you can try to exclude something that is clearly not damaged. To not wait a couple of hours. Our auto-code allows you to quickly get the difference and correctly recover in such cases.
Network backup
And yes, just in case, I’ll add that all the old things, like “everything on my grandmother’s computer is backed up directly to a USB flash drive that is stuck in the back” or “on my virtual machine you can restore the backup of a girl’s home computer while I have it at the weekend”, they still remained.
Folder synchronization
Mobile Backup
We pretty much sifted through all the technology of mobile backup in the new release. The main point is that we are well aware that not everyone wants to give a copy of their data to someone’s cloud, so we have provided for the function of a local backup. The old cloud option is also available, but the local backup was very, very much in demand. We had server code in corporate development (just made for paranoids and backups of corporate devices within the network), and we decided to reuse it. To make it clearer, first I will tell you how the new scheme works:
- You come home with your phone (more precisely, on the same Wi-Fi network where your desktop with the basic Acronis True Image version is).
- The application on the phone is activated (according to the iOS schedule or from the Android background) and determines the ability to connect to a computer on the current network. To do this, the phone starts searching for the primary host to establish an SSL connection.
- After this, an iterative backup begins - everything that has been changed over the past day is broken up into parts and filled with short chunks. It is assumed that the user spends quite a lot of time in his home network, so the background tools of both operating systems are used: for example, in the case of iOS, we can open the “windows” for 30 seconds, fill in a short chunk and wait for the next time window again.
Difficulties were almost everywhere. First, of course, traffic, activation from the background and power consumption on new versions of iOS and Android. In general, this is solved relatively simply, and there were ready-made recipes. After the first full backup, as a rule, we are talking about a few megabytes of new photos, a couple of kilobytes of contacts and other user information. We rewrote the code responsible for the fill: chunks are not torn, they are well downloaded, even after a daily break in the network. Contacts are now the first in priority. At the same time, the cloud fill was updated (in case the backup is not local), now the contacts can be seen immediately after they were received, without even waiting for the end of the chunk.
It was quite nontrivial to establish a connection between the phone and the desktop. We tried many methods until we stopped at QR codes - you need to take a picture of the QR code from the desktop screen in the application. But even in this version it was rather difficult: at first we sewed a full-fledged SSL certificate into the visual code immediately, and not all library readers read it. I had to greatly reduce QR and install a new key exchange protocol.
The discovery itself is done at once in different ways, so even if you run the operating system inside a virtual machine (as we like to do), the phone will find its pair. A frequent home case is when the phone is connected via Wi-Fi, and the laptop is connected with a local cable. Rezolv goes on IP4, bonjour services and hostname. Unfortunately, Russian Yota users still remain without this feature: their “provider” modems that distribute Wi-Fi create NAT, for which it is rather difficult to find something.
About the reuse of server code is also a separate story. Initially it was a Linux server, which theoretically could be ported, for example, under Win. In this case, the entire logic of the component is designed so that it has a controlling server, which gives commands. As a result, with a corporate backup, we create a microserver that acts as a command center for this subnet. In the home case, however, such a “nanoserver” can be said to be emulated on the desktop. More precisely, the component simply sends requests, and the desktop, in the case of a local backup, gives answers itself (in the case of the cloud, the answers are given by the remote server). This component itself was required for, in particular, the console to find out what has already been saved and what is not.
Recovery also goes through the mobile application, but with the active launch via the GUI. Well, and, of course, most of the data can be migrated between different devices: for example, if you are moving from iOS to Android, dragging photos is the simplest thing.
Facebook profile backup
If you have just hijacked the page - this, in general, is not a very big problem, most often, it can be restored by regular means. If Facebook unexpectedly banned you, you are unlikely to pull something out. If your page dies due to technical failure on their side - too. Sometimes the user himself accidentally deletes something (for example, a single photo) and really wants to recover. In general, many asked if it was possible to back up a Facebook profile. Yes you can. Now we do it.
When you start the profile copy tool from the desktop, the Fb page opens, where you need to allow a special application to access your data. This is a gateway for the Facebook API, in fact, a token repository for backup work. Then you can limit on Facebook the “visibility” of your profile through the API, and we can start copying.
Not everything can be copied. For example, you can not take and keep the count of friends, Facebook very carefully (unlike many other personal data) protects its main property. But it will turn out to take all the photos, the whole wall, all the messages and so on. Photos and videos, in which case, you can quickly restore - the API allows you to backfill them and not show updates in the feed, but, of course, there will be no likes and comments on them. This data is not backfilled in any way, which, in general, is quite explicable. Your timeline is also not restored: in contrast to the photo, all entries will be dated back-fill time. Your likes will be saved in the backup, but they will not be restored either.
The Facebook API turned out to be quite buggy, more precisely, rich in extremely illogical features. This tool was not originally intended for large tasks: as a rule, applications pull one or two requests for something extremely specific, but not all at once. This resulted in the fact that the same incremental backup is very difficult to do. For example, to quickly get the difference between the current and the previous state on a known date is almost impossible. There are no regular methods and there will be no - this seems to be part of Facebook’s security policy. I had to think carefully about the organization of algorithms in the existing limitations. As a result, they dig out strongly, but found a balance. The second point - there are restrictions with the token. The longest token is not eternal, lives 60 days. And, according to the logic of Facebook, after 60 days you need to go back to the dashboard and press a button. Regular web tokens are renewed when the user is active: when you enter your profile and you have a cookie mentioning such a token, it is updated. We work without live approach, in a separate session. Fortunately, on the other hand, we are not the manufacturers of SmartTV. They have users get the code on the phone or desktop and clog it from the remote to the TV every two months. Fortunately, we have just one button.
Testing was very fun. Facebook allows you to create test virtual users who are not visible on the main network. Unfortunately, these "mannequins" do not know how to like each other, can not comment and have many other restrictions. As a result, we created our own “live” users, the main of which eventually became Masha Bucket (it can still be found on the net, but we cleaned the profile). In the final, we worked with the profiles of our top managers - we needed very “bloated” profiles of people who had led an active network life for many years and today lead. As a result, the volume of the backup began to be measured by one of the employees, there could be explanations for tickets like: “With Facebook, data for 50 Ivanovs was taken, but only 48 came”.
Interesting things in changelog
Since this is a post about a release, and not features of development, I will leave a lot of interesting things about the implementation. But my colleagues and I will try to tell hardcore details later. In the meantime, I note that we have changed more interesting.
The first interesting story is the exceptions. For example, the usual backup script does not take a shadow copy of the system - it just does not make sense. To facilitate the backup (which is especially important for those who upload it over the network), we have worked very well with exceptions. In addition to temporary folders (with the exception of the browser cache - it turned out to be unexpectedly important), system logs, crash dumps and other system things, it excludes the fact that it has its own recovery tools. For example, if you do not explicitly indicate the opposite, we will not back up Dropbox, Yandex.Disk, Google Drive, OneDrive, libraries like iTunes, and anti-virus quarantines. Accordingly, we had to reverse all these tools in order to find their settings, determine from their configuration records what they are in the system, and understand what should be taken and what should not be taken. The longest running Yandex.Disk flew away from us - they store their settings in completely different ways in different versions. The first time he came across to us was in the last release - with the config in the XML file, then he started storing the settings in the SQLite database, then changing the storage format ... We drove these settings and tried to understand the logic for each exception.
In the opposite direction, too, exceptions were required. For example, in order to raise an old archive on a new system, in no case can one recover drivers from the old OS, a swap file, and so on. Accordingly, from release to release, we support such sets of rules.
We also exclude from the backup files of the same backup, if they are stored on the same disk. Otherwise, recursion would occur. At the same time, we have a new type of storage - an archive of unnecessary files (a compressed version of the folders “Disassemble1”, “Disassemble2” and so on, which the user himself shows and stores from nostalgic feelings) - we include them in backup.
The archive in which the backup data is stored has been greatly changed. We have a lot of ideas for this and last year, how to optimize it and how to make it more accessible (after all, we will “transparently” mount disks from archive files and give web access to the cloud copy). Now the local backup is stored in the second version of the archive with significant additions to the architecture, and the mobile backup is already in the third version, with a completely different architecture. I think next year we will move to the third version already everywhere. By and large, our archive is a separate file system "in itself". For example, up to 20 versions of a single file can be inside it (with or without deduplication), there is its own means of deleting old versions. There is an analogue of the garbage collector: you can "clean" the archive, and inside it forms a place for storage (in this case the file size itself will not change). Like in classic file systems, deleted files inside the archive are not deleted for optimization, but are marked up as being rewritten. Due to the dictionary structure of the archive, the release of vocabulary plots for complete removal is required. We also have our own means of internal defragmentation of the archive, but we do not use it without a direct user command (as well as never move data at the time of deletion). The fact is that any movement of information creates a threat of loss. For example, the characteristic problem is “USB-garlands”, when a user sticks devices through several adapters (we often see this among users of small laptops). Attempting to delete a file inside the archive with a change in the size of the archive will cause all data to be moved by sector. On a long garland, this causes a loss, and we had dozens of such cases in support.
We also worked on the recovery of individual files. In particular, they are now very quickly searched in the local archive.
Where to get the release
Here is the page of the Russian release . As in the previous version, you can buy a subscription (which is important for those who back up to our cloud) or the version “once and for all”, but with a limit of 5 free gigabytes in the cloud (this is an option for those who back up on the local network or on the discs in the closet). Licenses come in 1, 3 or 5 devices (Mac or Win) and plus on an unlimited number of mobile devices.
Well, and summarize. Now our release can be used for full-fledged backup to any local or networked media, to the cloud, to synchronize data on different computers, for a number of sysadmin tasks (in particular, beloved by many Try & Decide on site), for Facebook, for backup of iOS and Android mobile devices (on the Win-tablets, a desktop version is planned), to quickly mount backups as virtual disks, restore and relocate the system, quickly search for individual data in the archive.
We will try to tell about our design, mobile development and low level with colleagues in more detail later, each about our part.
Source: https://habr.com/ru/post/311280/
All Articles