JSON serializer on fast templates

What is the problem of text data exchange formats? They are slow. And not just slow, but monstrously slow. Yes, they are redundant in comparison with binary protocols and, in theory, the text serializer should be slower by about as much as it is redundant. But in practice, it turns out that sometimes textual serializers are orders of magnitude inferior to binary analogues.
I will not talk about the advantages of JSON over binary formats - each format has its own scope in which it is good. But often we are forced to abandon something convenient in favor of the not very comfortable because of the catastrophic inefficiency of the first. Developers refuse JSON, even if it is perfect for solving a problem, just because it turns out to be a bottleneck in the system. Of course, it is not JSON itself that is to blame, but the implementation of the corresponding libraries.
')
In this article I will talk not only about the problems of text format parsers in general and JSON in particular, but also about our library, which we have been using for many years in the most heavily loaded projects. It suits us so much both in terms of speed and usability that sometimes we give up the binary format where it would fit better. Of course, I mean some border conditions, without claims for all occasions.
To assess the scale of the tragedy, I measured the time of serialization of a not very complex object for a couple of well-known JSON libraries, google :: protobuf, “manual” JSON serialization, and for the wjson library, of which I am the developer, and will tell you in detail in this article below.
The results are shown in the diagram:
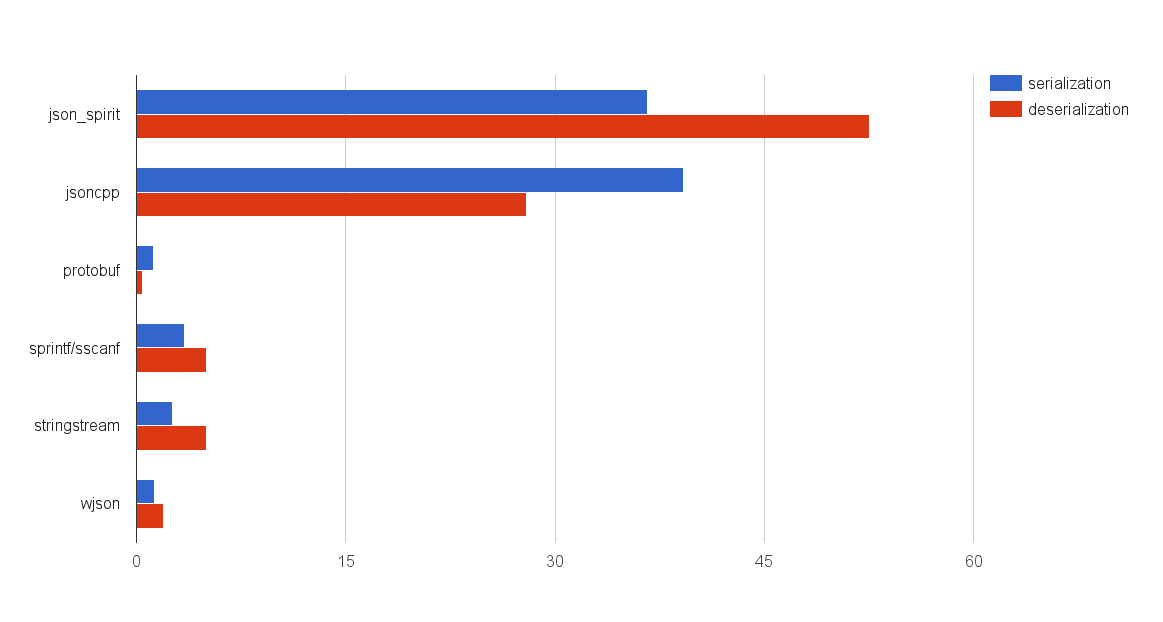
I confess that these results at one time, let's say gently, slightly surprised me.
The performance of jsoncpp and json_spirit (based on boost :: spirit) catastrophically loses google :: protobuf. The situation with “manual” serialization using sprintf / sscanf or std :: stringstream is much better. But if you use the first two tools, then do not hurry to drop everything, and with a cry: “I told you what to do yourself!” - to redo your projects. On the chart, measurements for a single sprintf / sscanf call, into which we stuffed a serializable object without any checks and the ability to rearrange or skip fields in a JSON object. I will give more detailed figures in the section on object serialization.
In this article, I see JSON as a messaging format with an emphasis on performance. Accordingly, I compare certain technologies in this context. This also means that the structure of messages at the design stage (compilation) is known to us. The proposed wjson library was also developed specifically for these tasks. Of course, it is possible to explore unknown JSON documents, and perhaps wjson will be more efficient than many libraries, in any case, jsoncpp and json_spirit - that's for sure.
In fact, wjson is conceptually closer to protobuf than, for example, to the libraries mentioned above. It also generates serialization / deserialization code by some meta description. But unlike protobuf, it does not use an external application, but a C ++ compiler. In the previous article I showed how a compiler can be taught to play tic-tac-toe , and to teach him how to generate a serialization code is a matter of technique.
But what I like most is the fact that there is no need to implement any additional functionality in the serializable data structures - flies separately, cutlets separately. And inheritance is supported, including multiple inheritance, aggregation of any nesting, and some buns, for example, serialization of enums.
Initially, wjson was conceived solely for the declarative description of JSON constructs on c ++ templates in order to save the programmer from writing run-time code with a lot of necessary checks. But it quickly became clear that the compiler was aggressively inline-it-like constructs. And it took quite a bit of effort to make these structures work quite effectively and reach an acceptable level of performance.
So why is JSON so slow?
If you worked with XML, then you know that there are two approaches to deserialization — the DOM (Document Object Model) and SAX (Simple API for XML). Recall that in the case of DOM, the text is converted into a tree of nodes that can be explored using the appropriate API. And the SAX parser works differently - it scans the document and generates certain events that are processed by the user code, implemented, as a rule, in the form of callback functions. Anyway, most text de-serializers use one of these approaches, or combine them.
The main drawback of the DOM is the need to build a tree, which is always expensive. The process of building such a tree at the stage of deserialization can take much longer than the execution of applied algorithms. But besides this, it is necessary to search for the required fields and convert them into internal data structures. And this task falls on the programmer’s shoulders, which he can realize extremely inefficiently. In fact, this is not so important, because it is the construction of the DOM trees that eats up the main resources.
SAX type parsers are much faster. By and large, they pass the text once, causing the appropriate handlers. Implementing a similar parser for JSON is a trivial task, because JSON itself is simple to disgrace, and that’s its beauty. But it requires a programmer who uses it, much more effort to extract data. And this is more work for the programmer, more errors and inefficient code, which can negate the effectiveness of SAX.
In general, the topic of efficient serialization is very interesting from the point of view of developing some kind of universal solution. But from the perspective of application programming, this is extremely tedious and boring, and as a result, huge amounts of inefficient govnokod. It is much more interesting for a programmer to optimize an application code, and the fact that deserialization occurs an order of magnitude slower and its optimization in this context does not make much sense, it does not bother him much.
But if most of the existing solutions for some reason do not suit us, let's do it manually, the benefit of JSON is a very simple format. And here I have watched a very interesting story several times. If a programmer works with binary protocols, he scrupulously shifts bits, optimizes the code and gets pleasure from it. But if he is offered to work with the text format in the same context, it seems that something is turned off in his brain. More precisely, on the contrary, he turns on protection against a high-order bicycle industry, which he did not particularly suffer from when working with a binary format. It connects heaps of libraries for working with text for the sake of a couple of beautiful (but, as a rule, not very effective) functions, in order to somehow improve their JSON code. And the result is still deplorable.
Few people would think to write their own implementation of atoi, but we still try:
In fact, everything is simple, but more universal and more convenient (in my opinion) than the classical atoi. But the most interesting thing is that it works twice as fast. Yes, of course, mostly due to inline substitutions, but this is not the point. By the way, sscanf / sprintf fulfills% s parameters faster than% d, with comparable string length.
I will not now talk about the danger of sscanf / sprintf, they have already written about it many times and, in addition, there are safe alternatives, for example, std :: stringstream or boost :: lexical_cast <>. Unfortunately, many programmers, including C ++, are guided by the myth that labor C is faster, and with enviable persistence begin to use sscanf / sprintf. But the problem, in this context, is not in the language, but in the implementation of one or another functional. For example, std :: stringstream, if used properly, may be no worse than C alternatives, but let's say boost :: lexical_cast <> may be significantly inferior in this regard.
Therefore, you need to thoroughly test the performance of not only third-party libraries, but also familiar tools. But it will often be quicker to bridle by looking at the necessary implementations on the Internet.
The code for my_atoi is almost unchanged from wjson, maybe someone will come in handy. The serialization code is a bit more confused:
Due to such one byte brute force for other JSON and inline substitution constructions, faster deserialization can be achieved. If we assemble them in any way into a single structure, we get a kind of SAX parser, which is also very fast.
If you worked with XML, then you know that there are two approaches to deserialization — the DOM (Document Object Model) and SAX (Simple API for XML). Recall that in the case of DOM, the text is converted into a tree of nodes that can be explored using the appropriate API. And the SAX parser works differently - it scans the document and generates certain events that are processed by the user code, implemented, as a rule, in the form of callback functions. Anyway, most text de-serializers use one of these approaches, or combine them.
The main drawback of the DOM is the need to build a tree, which is always expensive. The process of building such a tree at the stage of deserialization can take much longer than the execution of applied algorithms. But besides this, it is necessary to search for the required fields and convert them into internal data structures. And this task falls on the programmer’s shoulders, which he can realize extremely inefficiently. In fact, this is not so important, because it is the construction of the DOM trees that eats up the main resources.
SAX type parsers are much faster. By and large, they pass the text once, causing the appropriate handlers. Implementing a similar parser for JSON is a trivial task, because JSON itself is simple to disgrace, and that’s its beauty. But it requires a programmer who uses it, much more effort to extract data. And this is more work for the programmer, more errors and inefficient code, which can negate the effectiveness of SAX.
In general, the topic of efficient serialization is very interesting from the point of view of developing some kind of universal solution. But from the perspective of application programming, this is extremely tedious and boring, and as a result, huge amounts of inefficient govnokod. It is much more interesting for a programmer to optimize an application code, and the fact that deserialization occurs an order of magnitude slower and its optimization in this context does not make much sense, it does not bother him much.
But if most of the existing solutions for some reason do not suit us, let's do it manually, the benefit of JSON is a very simple format. And here I have watched a very interesting story several times. If a programmer works with binary protocols, he scrupulously shifts bits, optimizes the code and gets pleasure from it. But if he is offered to work with the text format in the same context, it seems that something is turned off in his brain. More precisely, on the contrary, he turns on protection against a high-order bicycle industry, which he did not particularly suffer from when working with a binary format. It connects heaps of libraries for working with text for the sake of a couple of beautiful (but, as a rule, not very effective) functions, in order to somehow improve their JSON code. And the result is still deplorable.
Few people would think to write their own implementation of atoi, but we still try:
template<typename T, typename P> P my_atoi( T& v, P beg, P end) { if( beg==end) return end; bool neg = ( *beg=='-' ); if ( neg ) ++beg; if ( beg == end || *beg < '0' || *beg > '9') return 0; if (*beg=='0') return ++beg; v = 0; for ( ;beg!=end; ++beg ) { if (*beg < '0' || *beg > '9') break; v = v*10 + (*beg - '0'); } if (neg) v = static_cast<T>(-v); return beg; } In fact, everything is simple, but more universal and more convenient (in my opinion) than the classical atoi. But the most interesting thing is that it works twice as fast. Yes, of course, mostly due to inline substitutions, but this is not the point. By the way, sscanf / sprintf fulfills% s parameters faster than% d, with comparable string length.
I will not now talk about the danger of sscanf / sprintf, they have already written about it many times and, in addition, there are safe alternatives, for example, std :: stringstream or boost :: lexical_cast <>. Unfortunately, many programmers, including C ++, are guided by the myth that labor C is faster, and with enviable persistence begin to use sscanf / sprintf. But the problem, in this context, is not in the language, but in the implementation of one or another functional. For example, std :: stringstream, if used properly, may be no worse than C alternatives, but let's say boost :: lexical_cast <> may be significantly inferior in this regard.
Therefore, you need to thoroughly test the performance of not only third-party libraries, but also familiar tools. But it will often be quicker to bridle by looking at the necessary implementations on the Internet.
The code for my_atoi is almost unchanged from wjson, maybe someone will come in handy. The serialization code is a bit more confused:
itoa
// template<typename T> struct integer_buffer_size { enum { value = sizeof(T)*2 + sizeof(T)/2 + sizeof(T)%2 + is_signed_integer<T>::value }; }; // template<typename T, int > struct is_signed_integer_base { enum { value = 1 }; static bool is_less_zero(T v) { return v < 0; } }; // , false template<typename T> struct is_signed_integer_base<T, false> { enum { value = 0 }; static bool is_less_zero(T ) { return false; } }; template<typename T> struct is_signed_integer: is_signed_integer_base< T, ( T(-1) < T(1) ) > { }; template<typename T, typename P> P my_itoa(T v, P itr) { char buf[integer_buffer_size<T>::value]; char *beg = buf; char *end = buf; if (v==0) *(end++) = '0'; else { // if (false) // . // if ( is_signed_integer<T>::is_less_zero(v) ) { for( ; v!=0 ; ++end, v/=10) *end = '0' - v%10; *(end++)='-'; } else { for( ; v!=0 ; ++end, v/=10) *end = '0' + v%10; } } do { *(itr++)=*(--end); } while( end != beg ); return itr; } Due to such one byte brute force for other JSON and inline substitution constructions, faster deserialization can be achieved. If we assemble them in any way into a single structure, we get a kind of SAX parser, which is also very fast.
Simple types
Let's take an example of serialization right away:
int value = 12345; char bufjson[100]; char* ptr = wjson::value<int>::serializer()(value, bufjson); *ptr = '\0'; std::cout << bufjson << std::endl; Here, wjson :: value <int> is a JSON description of an integer type that contains a serializer definition for this type. Next, we create a serializer object and call the overloaded operator (). Such a record may seem strange to someone, but we will use it to emphasize that the JSON serializer object has no state and does not make sense to create its instance.
I will immediately answer the question why serializer is not a static function. Firstly, the compiler does not like static elements in terms of compilation time, and secondly, it is just more convenient, at least for me. In fact, there will be a complete substitution of the code that I showed under the spoiler above, using the example of my_itoa.
The value <> construct is used not only for integers, but also for real, strings, and boolean. Definition:
template<typename T, int R = -1> struct value { typedef T target; typedef implementation_defined serializer; }; For Boolean and integer types, the argument R is not used. For lines of type std :: string or std :: vector <char> is the size of the reserve, and for real lines, the format of the presentation.
The serializer class, in addition to serialization, provides de-serialization functionality, i.e. two overloaded operator ():
template<typename T> class implementation_defined { public: template<typename P> P operator()( const T& v, P itr); template<typename P> P operator() ( T& v, P beg, P end, json_error* e ); }; The serialization function takes as input, in addition to the reference to the type being serialized, the output iterator, for example:
int value = 12345; std::string strjson; wjson::value<int>::serializer()(value, std::back_inserter(strjson)); std::cout << strjson << std::endl; std::stringstream ssjson; wjson::value<int>::serializer()(value, std::ostreambuf_iterator<char>(ssjson)); std::cout << ssjson.str() << std::endl; wjson::value<int>::serializer()(value, std::ostreambuf_iterator<char>(std::cout)); std::cout << std::endl; The serializer accepts random access iterators at the input, indicating the beginning and end of the buffer, as well as an error object pointer, which may be zero:
value = 0; char bufjson[100]=”12345”; wjson::value<int>::serializer()(value, bufjson, bufjson + strlen(bufjson), 0 ); std::cout << value << std::endl; value = 0; std::string strjson=”12345”; wjson::value<int>::serializer()(value, strjson.begin(), strjson.end(), 0 ); std::cout << value << std::endl; Both the serializer and deserializer return iterators. In the first case, it indicates the place where the serialization ended, and in the second, the place in the input buffer, where deserialization ended, if there were no errors. In case of an error, returns a pointer to the end of the buffer, and an error code if a non-null pointer was passed. About error handling a bit later, and now we will finish simple types.
Supported integers: char, unsigned char, short, unsigned short, int, unsigned int, long int, unsigned long, long long, unsigned long long. C boolean (bool), all the same, serializes to “true” or “false” and back. Automatic conversion from other types during deserialization is not supported.
The only type with which I didn’t bother too much in terms of performance is real (float, double, long double), there is the usual std :: stringstream. First of all, this is due to the fact that in real projects I worked with, it could always be replaced with either integer types (for example, transmitting meters in millimeters) or a load within 10K to the CPU core, which is not significant. If you have the bulk of traffic - it is real and can’t get away from it, then it makes sense to be confused with optimization. By default, real ones are serialized with a mantissa. When R> = 0, as with a fixed comma:
double value = 12345.12345; std::string json; wjson::value<double>::serializer()(value, std::back_inserter(json)); std::cout << json << std::endl; json.clear(); wjson::value<double, 4>::serializer()(value, std::back_inserter(json)); std::cout << json << std::endl; Result:
1.234512e+04 12345.1234 With strings, at first glance, everything should be simple if you use utf-8, but you need to pay attention to the following points:
- serialization
- all utf-8 characters with a code of 32 (space) are copied as is
- the characters '“', '\', '/', '\ t', '\ b', '\ r', '\ n', '\ f' are escaped by '\' according to the JSON specification
- the remaining characters, with a code less than 32, are serialized in hexadecimal format (\ uXXX)
- not utf-8 is serialized byte-byte in the \ xXX format, which does not conform to the JSON specification, which works exclusively with utf-8, but wjson deserializer understands this format
- deserialization
- escaped characters unscreened
- combinations of the \ uXXXX type are converted to utf-8, with the exception of some values less than 32 (if XXXX does not encode '\ t', '\ b', '\ r', '\ n', '\ f', then no conversion)
- combinations of the form \ xXX are unscreened without checks
- all other utf-8 characters are copied as is
Some third-party libraries, especially without straining, serialize everything that is not included in the ASCII range (codes> 127) in the \ uXXXX format. But when deserializing a similar string with wjson, this is decoded into utf-8. When wjson is re-serialized, this screening will no longer exist.
Sometimes, as a rule, due to a program error, in the middle of the line it turns out to be '\ 0', which by most serializers, including wjson, is converted to \ u0000, but when deserialized, it is not converted to \ 0, but remains as it is.
Support for the \ xXX format is dictated solely by limiting the concept of wjson serialization, which does not imply invalid data (either serialized or not compiled). To serialize binary data, use, for example, Base64.
String serialization example
#include <wjson/json.hpp> #include <iostream> #include <cstring> int main() { const char* english = "\"hello world!\""; const char* russian = "\"\\u041F\\u0440\\u0438\\u0432\\u0435\\u0442\\u0020\\u043C\\u0438\\u0440\\u0021\""; const char* chinese = "\"\\u4E16\\u754C\\u4F60\\u597D!\""; typedef char str_t[128]; typedef wjson::value< std::string, 128 >::serializer sser_t; typedef wjson::value< std::vector<char> >::serializer vser_t; typedef wjson::value< str_t >::serializer aser_t; std::string sstr; std::vector<char> vstr; str_t astr={'\0'}; // sser_t()( sstr, english, english + std::strlen(english), 0); vser_t()( vstr, russian, russian + std::strlen(russian), 0); aser_t()( astr, chinese, chinese + std::strlen(chinese), 0); // std::cout << "English: " << sstr << "\tfrom JSON: " << english << std::endl; std::cout << "Russian: " << std::string(vstr.begin(), vstr.end() ) << "\tfrom JSON: " << russian << std::endl; std::cout << "Chinese: " << astr << "\tfrom JSON: " << chinese << std::endl; // english stdout std::cout << std::endl << "English JSON: "; sser_t()( sstr, std::ostream_iterator<char>( std::cout) ); std::cout << "\tfrom: " << sstr; // russian stdout std::cout << std::endl << "Russian JSON: "; vser_t()( vstr, std::ostream_iterator<char>( std::cout) ); std::cout << "\tfrom: " << std::string(vstr.begin(), vstr.end() ); // chinese stdout std::cout << std::endl << "Chinese JSON: "; aser_t()( astr, std::ostream_iterator<char>( std::cout) ); std::cout << "\tfrom: " << astr; std::cout << std::endl; } Result:
English: hello world! from JSON: "hello world!"
Russian: ! from JSON: "\u041F\u0440\u0438\u0432\u0435\u0442\u0020\u043C\u0438\u0440\u0021"
Chinese: 世界你好! from JSON: "\u4E16\u754C\u4F60\u597D!"
English JSON: "hello world!" from: hello world!
Russian JSON: " !" from: !
Chinese JSON: "世界你好!" from: 世界你好!
Arrays
To describe JSON arrays, we use a similar construction with wjson :: value:
template<typename T, int R = -1> struct array { typedef T target; typedef implementation_defined serializer; }; Here T is the container being serialized, and R is the size of the reserve for stl containers that support this method. It seems everything is simple, but a record like: wjson :: array <std :: vector <int >> does not work, because we don't know how to serialize a container element, in this case an int. The correct entry will look like this:
typedef wjson::array< std::vector< wjson::value<int> > > vint_json; As a parameter T, we pass the container we need, but instead of the type of the container element, we pass its JSON description. Supported:
- V [n]
- std :: vector
- std :: deque
- std :: array
- std :: list
- std :: set
- std :: multiset
- std :: unordered_set
- std :: unordered_multiset
Of course, maximum performance is provided by the first four options. Filling lists and associative containers is too expensive by itself.
Example for classic C-arrays:
typedef wjson::value<int> int_json; typedef int vint_t[3]; typedef wjson::array< int_json[3] > vint_json; And, of course, multidimensional arrays are supported (for example, vectors of vectors, etc.), as shown in the example:
An example for a vector of vectors
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> int main() { // typedef wjson::value<int> int_json; typedef std::vector<int> vint_t; typedef wjson::array< std::vector<int_json> > vint_json; std::string json="[ 1,\t2,\r3,\n4, /**/ 5 ]"; vint_t vint; vint_json::serializer()(vint, json.begin(), json.end(), NULL); json.clear(); vint_json::serializer()(vint, std::back_inserter(json)); std::cout << json << std::endl; // ( ) typedef std::vector< vint_t > vvint_t; typedef wjson::array< std::vector<vint_json> > vvint_json; json="[ [], [1], [2, 3], [4, 5, 6] ]"; vvint_t vvint; vvint_json::serializer()(vvint, json.begin(), json.end(), NULL); json.clear(); vvint_json::serializer()(vvint, std::back_inserter(json)); std::cout << json << std::endl; // ( ) typedef std::vector< vvint_t > vvvint_t; typedef wjson::array< std::vector<vvint_json> > vvvint_json; json="[ [[]], [[1]], [[2], [3]], [[4], [5, 6] ] ]"; vvvint_t vvvint; vvvint_json::serializer()(vvvint, json.begin(), json.end(), NULL); json.clear(); vvvint_json::serializer()(vvvint, std::back_inserter(json)); std::cout << json << std::endl; } Here we take a JSON string, deserialize it into a container, clear it, serialize it into the same string, and output:
[1,2,3,4,5] [[],[1],[2,3],[4,5,6]] [[[]],[[1]],[[2],[3]],[[4],[5,6]]] The “json” line shows that between the elements of the array there can be any whitespace characters, including a line feed, as well as comments in the C-style, which is very convenient when implementing the json-configuration.
The maximum size for dynamic containers is unlimited, and for C-arrays and std :: array the limitation is the actual size of the array. If the incoming JSON elements are smaller, the rest are filled with the default value, and if more, the extra ones are simply discarded.
If JSON arrays contain elements of different types
If JSON arrays contain elements of different types, they are serialized and deserialized in two stages. First you need to describe a container of strings that will contain arbitrary non-deserialized JSON constructs, for example:
To describe the raw JSON:
Which copies the JSON string as it is to the T container. And then, using the parser, you need to determine the type of the JSON element and deserialize it accordingly. In the example below, we try to read an array of numbers [1, “2”, [3]] increment all elements and serialize it, keeping the format:
Result:
It also works with objects and dictionaries, which will be discussed further. If the numbers you can be represented by only two options, a string or, in fact, a number, then you can use a wrapper:
In fact, this construction works for any JSON description. The SerQ parameter enables dual serialization. For example, for numbers, this simply means framing in quotes. The ReqQ parameter includes dual de-serialization, i.e. it requires a JSON string at the input. If it is turned off, then the rules are a little more complicated. If the input is not a JSON string, then it simply starts the J deserializer without first deserializing it. If the input is a JSON string, then it deserializes into an intermediate std :: string. If J describes a non-string entity, then re-serialize from intermediate std :: string. For string entities, determine the need for re-deserialization. This means that if, after the first deserialization, the intermediate line begins with a quotation mark, then it is a double-serialized string and deserialized again, otherwise just copy.
It is clear that wjson :: quoted <> gives an additional overhead and should be considered as a temporary crutch, in case, for whatever reason, the client began to “freak out” and serialize numbers with terms or do double serialization of nested objects.
If JSON arrays contain elements of different types, they are serialized and deserialized in two stages. First you need to describe a container of strings that will contain arbitrary non-deserialized JSON constructs, for example:
typedef std::vector<std::string> vstr; To describe the raw JSON:
template<typename T = std::string, int R = -1> struct raw_value; Which copies the JSON string as it is to the T container. And then, using the parser, you need to determine the type of the JSON element and deserialize it accordingly. In the example below, we try to read an array of numbers [1, “2”, [3]] increment all elements and serialize it, keeping the format:
code
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> int main() { typedef std::vector< std::string > vect_t; typedef ::wjson::array< std::vector< ::wjson::raw_value<std::string> > > vect_json; vect_t inv; vect_t outv; std::string json = "[1,\"2\",[3]]"; std::cout << json << std::endl; vect_json::serializer()( inv, json.begin(), json.end(), 0 ); for ( auto& v : inv ) { outv.push_back(""); if ( wjson::parser::is_number(v.begin(), v.end()) ) { int num = 0; wjson::value<int>::serializer()( num, v.begin(), v.end(), 0); ++num; wjson::value<int>::serializer()( num, std::back_inserter(outv.back()) ); } else if ( wjson::parser::is_string(v.begin(), v.end()) ) { std::string snum; wjson::value<std::string>::serializer()( snum, v.begin(), v.end(), 0); int num = 0; wjson::value<int>::serializer()( num, snum.begin(), snum.end(), 0); ++num; snum.clear(); wjson::value<int>::serializer()( num, std::back_inserter(snum) ); wjson::value<std::string>::serializer()( snum, std::back_inserter(outv.back()) ); } else if ( wjson::parser::is_array(v.begin(), v.end()) ) { std::vector<int> vnum; wjson::array< std::vector< wjson::value<int> > >::serializer()( vnum, v.begin(), v.end(), 0); ++vnum[0]; wjson::array< std::vector< wjson::value<int> > >::serializer()( vnum, std::back_inserter(outv.back()) ); } else { outv.back()="null"; } } json.clear(); vect_json::serializer()( outv, std::back_inserter(json) ); std::cout << json << std::endl; } Result:
[1,"2",[3]] [2,"3",[4]] It also works with objects and dictionaries, which will be discussed further. If the numbers you can be represented by only two options, a string or, in fact, a number, then you can use a wrapper:
template<typename J, bool SerQ = true, bool ReqQ = true, int R = -1> struct quoted; - J - original JSON description
- SerQ - pre-serialize to string
- ReqQ - JSON input must be a "string"
- R reserve for intermediate buffer (line)
In fact, this construction works for any JSON description. The SerQ parameter enables dual serialization. For example, for numbers, this simply means framing in quotes. The ReqQ parameter includes dual de-serialization, i.e. it requires a JSON string at the input. If it is turned off, then the rules are a little more complicated. If the input is not a JSON string, then it simply starts the J deserializer without first deserializing it. If the input is a JSON string, then it deserializes into an intermediate std :: string. If J describes a non-string entity, then re-serialize from intermediate std :: string. For string entities, determine the need for re-deserialization. This means that if, after the first deserialization, the intermediate line begins with a quotation mark, then it is a double-serialized string and deserialized again, otherwise just copy.
It is clear that wjson :: quoted <> gives an additional overhead and should be considered as a temporary crutch, in case, for whatever reason, the client began to “freak out” and serialize numbers with terms or do double serialization of nested objects.
Parser
In wjson, there is a class parser, which contains only static methods that can be divided into two types. This is a test for compliance with one or another JSON type and, accordingly, the methods are parsers. For each JSON type there is a method:
list of methods
class parser { /*...*/ public: template<typename P> static P parse_space( P beg, P end, json_error* e); template<typename P> static P parse_null( P beg, P end, json_error* e ); template<typename P> static P parse_bool( P beg, P end, json_error* e ); template<typename P> static P parse_number( P beg, P end, json_error* e ); template<typename P> static P parse_string( P beg, P end, json_error* e ); template<typename P> static P parse_object( P beg, P end, json_error* e ); template<typename P> static P parse_array( P beg, P end, json_error* e ); template<typename P> static P parse_value( P beg, P end, json_error* e ); /*...*/ }; As well as for the deserializer, here beg is the beginning of the buffer, the end-end of the buffer, and in “e”, if not equal to nullptr, the error code will be written. If successful, a pointer will be returned to the character following the last character of the current entity. And in case of an error, end will be returned, and e will be initialized.
Suppose you have a string with several JSON objects of a certain structure that are separated by a newline or other whitespace entities, then you can work it out (without error handling):
for (;beg!=end;) { beg = wjson::parser::parse_space(beg, end, 0); beg=my_json::serializer()(dict, beg, end, 0); /* …. */ } All serializers assume that the first character should be the character of the object being deserialized, otherwise there will be an error. But, as I said, there can be whitespace characters inside the objects and arrays, including comments that the deserializer parses with the same parse_space. An example of parsing a string with several JSON entities:
wjson::json_error e; for (;beg!=end;) { beg = wjson::parser::parse_space(beg, end, &e); beg = wjson::parser::parse_value(beg, end, &e); if ( e ) abort(); } Here parse_value checks any JSON entity for validity. If the input parse_space is not a whitespace, it will simply return beg. It may return an error if, for example, an unclosed C-style comment is detected, but additional verification is redundant here. If an initialized error object arrives at the parser (as well as the deserializer), then it simply returns end.
To define a specific JSON entity, there is the following set of methods:
list of methods
class parser { /*...*/ public: template<typename P> static bool is_space( P beg, P end ); template<typename P> static bool is_null( P beg, P end ); template<typename P> static bool is_bool( P beg, P end ); template<typename P> static bool is_number( P beg, P end ); template<typename P> static bool is_string( P beg, P end ); template<typename P> static bool is_object( P beg, P end ); template<typename P> static bool is_array( P beg, P end ); }; Despite the fact that they receive pointers to the beginning and end of the buffer, these methods determine the essence by the first character: {is an object, [is an array, “is a string, any digit is a number, and t, f or n is true , false or null, respectively. Therefore, if, for example, is_object, returns true to us, then to make sure that this is a valid object, you need to call parse_object and check that there are no errors.
Error processing
It is almost always necessary to check errors during deserialization. In the examples, I do not do this solely for clarity. Consider an example where a foreign character is embedded in the source array:
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> int main() { typedef wjson::array< std::vector< wjson::value<int> > >::serializer serializer_t; std::vector< int > value; std::string json = "[1,2,3}5,6]"; wjson::json_error e; serializer_t()(value, json.begin(), json.end(), &e ); if ( e ) { std::cout << "Error code: " << e.code() << std::endl; std::cout << "Error tail of: " << e.tail_of() << std::endl; if ( e.type() == wjson::error_code::ExpectedOf ) std::cout << "Error expected_of: " << e.expected_of() << std::endl; std::cout << "Error position: " << wjson::strerror::where(e, json.begin(), json.end() ) << std::endl; std::cout << "Error message: " << wjson::strerror::message(e) << std::endl; std::cout << "Error trace: " << wjson::strerror::trace(e, json.begin(), json.end()) << std::endl; std::cout << "Error message & trace: " << wjson::strerror::message_trace(e, json.begin(), json.end()) << std::endl; } } Actually, the object of the error wjson :: json_error contains information about the error code and the position relative to the end of the buffer where the parser has detected any inconsistency. For the special errors of the “Expected of” type, the symbol he expected.
To get readable messages, use the wjson :: strerror class. In the example above, the symbol} is found in the JSON array, and the parser expects a comma (or a square bracket), which is what it says. The example shows all available methods for analyzing the error. The result is as follows:
Error code: 3 Error tail of: 5 Error expected_of: , Error position: 6 Error message: Expected Of ',' Error trace: [1,2,3>>>}5,6] Error message & trace: Expected Of ',': [1,2,3>>>}5,6] Thus, you can get not only the error code, readable message, but also the place where it occurred. The trace uses the combination “>>>”.
JSON Objects
Deserializing JSON objects directly into data structures is what wjson was designed for. Consider a simple structure:
struct foo { bool flag = false; int value = 0; std::string string; }; Which needs to be serialized in JSON type:
{ "flag":true, "value":42, "string":" !"} A JSON object is simply an enumeration of a list of fields that consist of a name and a value (any JSON), separated by a colon. To serialize a separate field, copy the name that is known at the compilation stage, add a colon, and serialize the value. This concept is implemented by the construction:
template<typename N, typename T, typename M, MT::* m, typename J = value<M> > struct member; - N - field name
- T - structure type
- M - field type
- m - pointer to the structure field
- J - JSON field description
But explicitly passing strings to template parameters is problematic. Therefore, we use the following trick. For each name of the structure field we will create a structure of the form:
name for flag
struct n_flag { const char* operator()() const { return “flag”; } }; Which we will be able to pass the template parameter. Of course, to produce such structures for each name is not very convenient, so the rare case when I allowed myself a macro substitution. To do this, you can use the macro:
JSON_NAME(flag) which will create about the same structure. The prefix n_ is used for historical reasons. But if you do not like it, you can use the second option:
JSON_NAME2(n_flag, “flag”) which allows you to create a structure with an arbitrary name and string. An example to describe a separate field:
wjson::member< n_flag, foo, bool, &foo::flag> For simple types, the JSON description (wjson :: value <>) can be omitted, but for all others it is required. By itself, the serialization of the structure field does not make much sense, so you need to combine the descriptions of all the fields into a list as follows:
wjson::member_list< wjson::member<n_flag, foo, bool, &foo::flag>, wjson::member<n_value, foo, int, &foo::value>, wjson::member<n_string, foo, std::string, &foo::string> > For C ++ 11, the number of fields is unlimited; for C ++ 03, the limit is 26 elements, which is easy to get around using the nested member_list. The rules for serializing a JSON object into structures are given by the construction:
template<typename T, typename L> struct object { typedef T target; typedef implementation_defined serializer; typedef implementation_defined member_list; }; Here T is the data structure type, and L is the list of fields to be serialized (member_list).
An example of serializing and deserializing a JSON object
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> struct foo { bool flag = false; int value = 0; std::string string; }; JSON_NAME(flag) JSON_NAME(value) JSON_NAME(string) typedef wjson::object< foo, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string> > > foo_json; int main() { std::string json="{\"flag\":false,\"value\":0,\"string\":\" \"}"; foo f; foo_json::serializer()( f, json.begin(), json.end(), nullptr ); f.flag = true; f.string = " "; std::cout << json << std::endl; foo_json::serializer()( f, std::ostream_iterator<char>(std::cout) ); } Result:
{"flag":false,"value":0,"string":" "} {"flag":true,"value":0,"string":" "} What I would like to draw your attention to:
- There is no mention in the source structure (foo) that it is persistent.
- fields are serialized exactly in the order they are described in member_list.
- JSON , member_list
- .
- JSON
- member_list
- , ( )
If the order of fields in the input JSON coincides with the order in the JSON description, then deserialization occurs as quickly as possible, in fact, in one pass. Field omissions or extra items do not greatly affect performance (they are simply ignored).
But what happens if the fields in JSON come in a random order? Of course, this affects the performance, because the parser gets off and starts searching the fields from the beginning. But I recommend not to bother with the topic of field ordering at all.
Even before the moment when it really begins to be felt, you will encounter a problem not of de-serialization time, but of JSON redundancy, and you will need to think about changing the format of data exchange. This does not necessarily mean switching to binary protocols. For example, you can transfer objects in the form of JSON arrays, in which the position rigidly corresponds to some field of the structure. In particular cases, when many zeros are transmitted, such a format can be both smaller and faster than protobuf.
Not to be unsubstantiated, I drove the deserialization of the following structure into performance:
struct foo { int field1 = 0; int field2 = 0; int field3 = 0; std::vector<int> field5; }; JSON description for foo
JSON_NAME(field1) JSON_NAME(field2) JSON_NAME(field3) JSON_NAME(field5) typedef wjson::object< foo, wjson::member_list< wjson::member<n_field1, foo, int, &foo::field1>, wjson::member<n_field2, foo, int, &foo::field2>, wjson::member<n_field3, foo, int, &foo::field3>, wjson::member<n_field5, foo, std::vector<int>, &foo::field5, ::wjson::array< std::vector< ::wjson::value<int> > > > > > foo_json; With direct and inverse (most unsuccessful) sequences of fields in the input JSON. But then I noticed that the names of the fields were chosen not quite honestly, because match the last character, therefore also made a measurement for the variant:
JSON_NAME2(n_field1, "1field") JSON_NAME2(n_field2, "2field") JSON_NAME2(n_field3, "3field") JSON_NAME2(n_field5, "5field") when all fields are distinguished by the first character. As a result, for JSON:
{"field1":12345,"field2":23456,"field3":34567,"field5":[45678,56789,67890,78901,89012]} {"5field":[45678,56789,67890,78901,89012],"1field":12345,"2field":23456,"3field":34567} {"field5":[45678,56789,67890,78901,89012],"field1":12345,"field2":23456,"field3":34567} Got the following results:
- Serialization time: 151321 ns (6608468 persec), now it doesn't matter
- Deserialization for “optimal” JSON: 204113 ns (4899246 persec)
- “Worse” order of fields with optimal names: 221140 ns (4522022 persec)
- The “worst” order of fields with “bad” names: 237616 ns (4208470 persec)
For clarity and to close the topic sprintf / sscanf, raised at the beginning of the article, I also measured the execution time of this design:
sscanf( str, "{\"field1\":%d,\"field2\":%d,\"field3\":%d,\"field5\":[%d,%d,%d,%d,%d]}", &(f.field1), &(f.field2), &(f.field3), &(f.field5[0]), &(f.field5[1]), &(f.field5[2]),&(f.field5[3]), &(f.field5[4]) ); It is clear that here there can be no talk of full de-serialization - any discrepancy to the pattern can lead to disastrous results. Nevertheless, the result is 2477942 ns (403560 persec), which is ten times worse than that of wjson with all checks, with “bad” order and “not successful” field names:
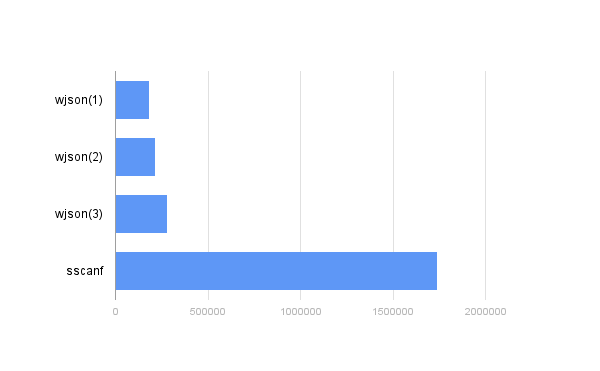
For those who could not believe their eyes and want to check These figures (which is commendable), without having read the article (and this is difficult for me to welcome), I will immediately warn you that this only works with optimization turned on. In debug mode, get the numbers exactly the opposite and even worse. You always have to sacrifice something.
The question in terms of the speed of serialization of such entities for me is already several years, but the problem of JSON redundancy sometimes pops up. To solve this problem, it is possible to serialize the structure into an array, whose fields are rigidly tied to the index:
typedef wjson::object_array< foo, wjson::member_list< wjson::member_array<foo, int, &foo::field1>, wjson::member_array<foo, int, &foo::field2>, wjson::member_array<foo, int, &foo::field3>, wjson::member_array<foo, std::vector<int>, &foo::field5, ::wjson::array< std::vector< ::wjson::value<int> > > > > > foo_json; As a result, the same structure is serialized into an array:
[12345,23456,34567,[45678,56789,67890,78901,89012]] for 139856 ns (7150211 persec), and deserialization occurs for 131282 ns (7617190)

Yes, there is a difference in speed, but first of all it is more compact. In one of the projects, in which the server returns data for plotting, where each point is described by eight fields, of which there are about 3000 for each graph, and there can be several dozen graphs on the screen, the resulting JSON could be several megabytes. Serializing the initial structures into arrays of eight elements, we not only significantly reduce the volume of transmitted traffic, but also increase its readability. But, in general, of course, translating all APIs into arrays is not the best idea.
Inheritance
Consider inheritance on the example of the following structures:
struct foo { bool flag = false; int value = 0; std::string string; }; struct bar: foo { std::vector<int> data; }; There are two ways to describe inheritance. Option one:
typedef ::wjson::array< std::vector< ::wjson::value<int> > > vint_json; typedef wjson::object< bar, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string>, wjson::member<n_data, bar, std::vector<int>, &bar::data, vint_json> > > bar_json; Here we can position the fields of the parent (or parents) and the heir in any order. Option two, more visual:
typedef wjson::object< foo, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string> > > foo_json; typedef wjson::object< bar, wjson::member_list< wjson::base<foo_json>, wjson::member<n_data, bar, std::vector<int>, &bar::data, vint_json> > > bar_json; We make a separate JSON description for the base class and implement it using the wjson :: base <foo_json> construct, which is a pseudonym for foo_json :: member_list, anywhere in the list.
Great example, with all the elements
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> struct foo { bool flag = false; int value = 0; std::string string; }; struct bar: foo { std::shared_ptr<foo> pfoo; std::vector<foo> vfoo; }; struct foo_json { JSON_NAME(flag) JSON_NAME(value) JSON_NAME(string) typedef wjson::object< foo, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; struct bar_json { JSON_NAME(pfoo) JSON_NAME(vfoo) typedef wjson::array< std::vector< foo_json > > vfoo_json; typedef wjson::pointer< std::shared_ptr<foo>, foo_json > pfoo_json; typedef wjson::object< bar, wjson::member_list< wjson::base<foo_json>, wjson::member<n_vfoo, bar, std::vector<foo>, &bar::vfoo, vfoo_json>, wjson::member<n_pfoo, bar, std::shared_ptr<foo>, &bar::pfoo, pfoo_json> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; int main() { std::string json="{\"flag\":true,\"value\":0,\"string\":\" \",\"vfoo\":[],\"pfoo\":null}"; bar b; bar_json::serializer()( b, json.begin(), json.end(), nullptr ); b.flag = true; b.vfoo.push_back( static_cast<const foo&>(b)); b.pfoo = std::make_shared<foo>(static_cast<const foo&>(b)); std::cout << json << std::endl; bar_json::serializer()(b, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; } Result:
{"flag":true,"value":0,"string":" ","vfoo":[],"pfoo":null} {"flag":true,"value":0,"string":" ","vfoo":[{"flag":true,"value":0,"string":" "}],"pfoo":{"flag":true,"value":0,"string":" "}} Here is a slightly different description of JSON objects, but first about pointers. You can serialize any pointers. If it is zero, then it is serialized as null, otherwise by value. And deserialization is implemented only for std :: shared_ptr <>. If in JSON is null, then this is nullptr, otherwise an object is created and deserialization occurs into it. For any elements that we did not describe as wjson :: pointer, if null is input, then it is created with the default value. This also applies to arrays and simple types.
Why screen template classes with a large number of parameters
JSON- , , . , , . , :
:
Since deserializer , :
foo_json bar_json typedef, :
, . , , ., , typeid(T).name(). , , , , . , , :
, . . , , , ( ).
JSON- , , . , , . , :
template<typename J> struct deserealizer { typedef typename J::deserializer type; }; :
typedef deserealizer<bar_json>::type deser; Since deserializer , :
error: no type named 'deserializer' in 'struct bar_json' foo_json bar_json typedef, :
error: no type named 'deserializer' in 'struct wjson::object<bar, fas::type_list<wjson::member<n_flag, foo, bool, &foo::flag>, fas::type_list<wjson::member<n_value, foo, int, &foo::value>, fas::type_list<wjson::member<n_string, foo, std::basic_string<char>, &foo::string>, fas::type_list<wjson::member<n_vfoo, bar, std::vector<foo>, &bar::vfoo, wjson::array<std::vector<wjson::object<foo, fas::type_list<wjson::member<n_flag, foo, bool, &foo::flag>, fas::type_list<wjson::member<n_value, foo, int, &foo::value>, fas::type_list<wjson::member<n_string, foo, std::basic_string<char>, &foo::string>, fas::empty_list> > > > > > >, fas::type_list<wjson::member<n_pfoo, bar, std::shared_ptr<foo>, &bar::pfoo, wjson::pointer<std::shared_ptr<foo>, wjson::object<foo, fas::type_list<wjson::member<n_flag, foo, bool, &foo::flag>, fas::type_list<wjson::member<n_value, foo, int, &foo::value>, fas::type_list<wjson::member<n_string, foo, std::basic_string<char>, &foo::string>, fas::empty_list> > > > > >, fas::empty_list> > > > > >' , . , , ., , typeid(T).name(). , , , , . , , :
template<typename J> struct deserealizer { struct type: J::deserializer {}; }; , . . , , , ( ).
Well and, of course, no one bothers to make the same foo_json template and pass as a parameter, for example, the type of the value field, which can be used to serialize template structures.
Dictionaries
Dictionaries are needed to serialize associative arrays (key-value), for example, std :: map <>. Most JSON libraries work according to this scheme — an object is deserialized into a tree, and then you examine it, search for the required fields, etc. And for serialization you need to dynamically fill it. From the point of view of performance is not the most effective method. Therefore, before using that std :: map <> in data structures, consider whether it is possible somehow without it. Of course, this is not the case if you use JSON for configuration:
template<typename T, int R = -1> struct dict { typedef implementation_defined target; typedef implementation_defined serializer; }; Here, the concept is the same as for arrays - T is an associative stl container, which has JSON descriptions for the key and value as parameters. For example:
typedef wjson::dict< std::map< wjson::value<std::string>, wjson::value<int> > > dict_json; can be used to serialize std :: map <std :: string, int>. The construction is rather complicated, but given the fact that strings are used as the key most often, there is a simpler option for std :: map <std :: string, JSON>:
typedef wjson::dict_map< wjson::value<int> > dict_json; Of course, any JSON entity described earlier in this article can be used as a value.
The R parameter defines the size of the reserve for consecutive containers of pairs of the type std :: vector <std :: pair <>> or std :: deque <std :: pair <>>. To describe a key-value pair, the field construction is used:
template<typename K, typename V> struct field; Here K and V are JSON descriptions of the key and value, respectively. For example:
typedef wjson::dict< std::vector< wjson::field< wjson::value<std::string>, wjson::value<int> > >, 128 /* */ > dict_json; to serialize the vector pairs std :: vector <std :: pair <std :: string, int>>. This design can be used where high de-serialization is needed. The steam vector is filled much faster than std :: map (of course, if the necessary reserve was made). This design is even more complicated, and is used more often, so for it there is a simple option:
typedef wjson::dict_vector< ::wjson::value<int> > dict_json; typedef wjson::dict_deque< ::wjson::value<int> > dict_json; For example:
int main() { typedef std::vector< std::pair<std::string, int> > dict; typedef wjson::dict_vector< wjson::value<int> > dict_json; dict d; std::string json = "{\"\":1,\"\":2,\"\":3}"; std::cout << json << std::endl; dict_json::serializer()( d, json.begin(), json.end(), 0 ); d.push_back( std::make_pair("",4)); json.clear(); dict_json::serializer()( d, std::back_inserter(json) ); std::cout << json << std::endl; } Result:
{"":1,"":2,"":3} {"":1,"":2,"":3,"":4} Dictionaries are useful for configurations. In the simplest case, it is a simple key-value array, where the key will contain the name of the configured component. But if you don’t be lazy, put the component configuration into a separate structure and make a JSON description for it, then you will get rid of unnecessary runtime code, and, therefore, of initialization error handles. In addition, you can generate a configuration with the current set of fields to the delight of yourself (at the design stage) and the user, so that he can be convinced of the relevance of the documentation, which tends to become obsolete.
Enumerations and Flags
It makes sense to serialize enumerations in their textual representation for the same reason why textual data presentation formats were created in general - this is readability. If you do not abuse the long names, it can turn out at least no slower than serialization as a number and is not very expensive in size. If you have read this line, then, most likely, the overall concept is generally understandable, so for example at once:
Enum serialization example
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> struct counter { typedef enum { one = 1, four = 4, five = 5, two = 2, three = 3, six = 6 } type; }; struct counter_json { JSON_NAME(one) JSON_NAME(two) JSON_NAME(three) JSON_NAME(four) JSON_NAME(five) JSON_NAME2(n_six, " !") typedef wjson::enumerator< counter::type, wjson::member_list< wjson::enum_value< n_one, counter::type, counter::one>, wjson::enum_value< n_two, counter::type, counter::two>, wjson::enum_value< n_three,counter::type, counter::three>, wjson::enum_value< n_four, counter::type, counter::four>, wjson::enum_value< n_five, counter::type, counter::five>, wjson::enum_value< n_six, counter::type, counter::six> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; int main() { typedef wjson::array< std::vector< counter_json > > array_counter_json; std::vector< counter::type > cl; std::string json = "[\"one\",\"two\",\"three\"]"; std::cout << json << std::endl; array_counter_json::serializer()( cl, json.begin(), json.end(), 0 ); cl.push_back(counter::four); cl.push_back(counter::five); cl.push_back(counter::six); array_counter_json::serializer()(cl, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; } As shown in the example, enumerations are not necessarily serialized one-on-one, but you can in an arbitrary string. Result:
["one","two","three"] ["one","two","three","four","five"," !"] In fact, the enums here are just for convenience, and you can use any integer types.
Consider this JSON:
{"code":1,"message":"Invalid JSON."} This is some kind of JSON-RPC error message. Obviously, the message message is directly related to the code. Therefore, there is no need to create a structure with a text field and fill it in; it is enough:
Two in one and not even enum
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> enum class error_code { ValidJSON = 0, InvalidJSON = 1, ParseError = 2 }; struct error { int code = 0; }; struct code_json { JSON_NAME2(ValidJSON, "Valid JSON.") JSON_NAME2(InvalidJSON, "Invalid JSON.") JSON_NAME2(ParseError, "Parse Error.") typedef wjson::enumerator< int, wjson::member_list< wjson::enum_value< ValidJSON, int, static_cast<int>(error_code::ValidJSON)>, wjson::enum_value< InvalidJSON, int, static_cast<int>(error_code::InvalidJSON)>, wjson::enum_value< ParseError, int, static_cast<int>(error_code::ParseError)> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; struct error_json { JSON_NAME(code) JSON_NAME(message) typedef wjson::object< error, wjson::member_list< wjson::member< n_code, error, int, &error::code>, wjson::member< n_message, error, int, &error::code, code_json> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; int main() { error e; e.code = static_cast<int>(error_code::InvalidJSON); error_json::serializer()(e, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; } Result:
{"code":1,"message":"Invalid JSON."} Serialization looks quite funny, but what about deserialization? It turns out that “code” is deserialized twice: once from the “code” field, and the second time from the “message” field. You can make a separate error_json variant specifically for deserialization without the “message” field, but this will not have a significant impact on performance, since it will always be parsed during serialization. And you can use this feature to double check that the code is strictly consistent. For example, if you replace the point in the message with a question mark:
e = error(); std::string json = "{\"code\":1,\"message\":\"Invalid JSON?\"}"; wjson::json_error ec; error_json::serializer()(e, json.begin(), json.end(), &ec ); Then we get an error:
Invalid Enum: {"code":1,"message":">>>Invalid JSON?"} Often, enumerations are used for various flag combinations, they can also be serialized. But in what form? Two methods are proposed: in the form of an array or in the form of a string with a specified separator. The delimiter is specified by the last flags parameter. Any character except a comma will be serialized to a string, and for a comma to an array. In the humorous example below, both options are used:
my grandmother had a gray goat
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> template<char S> struct flags_json { JSON_NAME2(w1, "") JSON_NAME2(w2, "") JSON_NAME2(w4, "") JSON_NAME2(w8, "") JSON_NAME2(w16, "") JSON_NAME2(w32, "") typedef ::wjson::flags< int, wjson::member_list< wjson::enum_value< w1, int, 1>, wjson::enum_value< w2, int, 2>, wjson::enum_value< w4, int, 4>, wjson::enum_value< w8, int, 8>, wjson::enum_value< w16, int, 16>, wjson::enum_value< w32, int, 32> >, S > type; typedef typename type::serializer serializer; typedef typename type::target target; typedef typename type::member_list member_list; }; int main() { std::string json = "\" \""; int val = 0; flags_json<' '>::serializer()(val, json.begin(), json.end(), 0 ); std::cout << json << " = " << val << std::endl; std::cout << 63 << " = "; flags_json<' '>::serializer()(63, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; std::cout << 48 << " = "; flags_json<','>::serializer()(48, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; std::cout << 49 << " = "; flags_json<'|'>::serializer()(49, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; } The idea here is simple. We use each word from the line of the children's song as a flag with the corresponding meaning. Combining flags, we get various options. And if we use a space as a separator, it is not at all obvious that this is a set of flags. First, we deserialize the string “there was a gray goat”, which corresponds to the combination 1 | 2 | 16 | 32 = 51, with a separator as a space. And below are examples of serialization with various delimiters. Obviously, you can use all the numbers up to 63 - this is the whole phrase.
Result:
" " = 51 63 = " " 48 = ["",""] 49 = "||" Conclusion
It is rather difficult not to succumb to the temptation, in order not to begin a long and tedious justifiable narration about the history of the development of this creation. Therefore, briefly. Written on the knee in 2008 just to practice some of the concepts of faslib on which it is built. In 2009, wjson (then it was just a set of code that copied) was used in experimental projects. Then it became clear that the interface is not flexible and generally sucks. In 2011, there was an attempt to do something global, comprehensive and correct. And it almost happened, but it was abandoned, because In the same year, we began to transfer all our projects to JSON, and it turned out that the current capabilities cover all our needs, and the interface is simple and straightforward, even for beginners. Since 2013 all our projects, including very high-loaded ones, work with wjson. For example,A comet daemon can support up to 1 million simultaneous active connections, and the statistics collection system grinds more than 1.5 GB of JSON-RPC notifications on one host, recording up to 4.5 million values of various metrics per second.
We use JSON for configurations, all sorts of dumps and, of course, together JSON-RPC engine, which works on the same principle, and which I will discuss in the next article very soon.
Both wjson and faslib , on which wjson depends, are the header-only libraries. To compile examples and tests:
git clone https://github.com/migashko/faslib.git git clone https://github.com/mambaru/wjson.git # wjson cd faslib mkdir build cd build cmake .. # cd ../../wjson mkdir build cd build cmake -DWJSON_BUILD_ALL=ON .. make cd ./tests ctest wjson on github: github.com/mambaru/wjson
Source: https://habr.com/ru/post/311262/
All Articles