Measuring Apache Ignite Cache Performance
After the previous articles in this series of reviews of the distributed Apache Ignite Java framework, we took the first steps , got acquainted with the basic principles of building topology, and even made a starter for Spring Boot , inevitably raises the question of caching, which is one of the main functions of Ignite. First of all, I would like to understand whether it is necessary when libraries for caching in Java and so full. The fact that the implementation of the JCache standard (JSR 107) is provided and the possibility of distributed caching is difficult to surprise in our time. Therefore, before (or instead of) considering the functionality of the Apache Ignite cache, I would like to see how fast it is.

For the study used benchmark cache2k-benchmark , designed to prove that the cache2k cache library is the fastest. Here at the same time and check. This article does not pursue the goal of comprehensive performance testing, or at least scientifically reliable, let the Apache Ignite developers do it. We just look at the order of magnitude, the main features and the relative position in the ranking, which will also include cache2k and the native cache on ConcurrentHashMap.
As part of the testing methodology, I did not reinvent the wheel, and took the one described for cache2k . It consists in comparing the performance of a number of standard operations using a JMH- based library:
As a reference, the method considers the values obtained for implementing a cache based on ConcurrentHashMap, since it is assumed that there is no place to be faster. Accordingly, in all nominations the struggle goes for second place. The cache2k-benchmark (hereinafter referred to as CB ) implements scripts for cache2k and several other providers: Caffeine, EhCache, Guava, Infinispan, TCache, as well as a native implementation based on ConcurrentHashMap. CB has implemented other benchmarks, but we will limit ourselves to these two.
The measurements were performed under the following conditions:
')
The work of the Apache Ignite cache was investigated in several modes, differing in topology (it is recommended to recall the basic concepts of the Apache Ignite topology ) and load distribution:
According to the CB requirements, the IgniteCacheFactory class was implemented (the code is available in GitHub , based on the CB fork). The server and client are created with the following settings:
It is important that the cache settings for the client and server are the same.
The server will be created from the command line outside the test using the same JVM with the options -Xms1g -Xmx14g -server -XX: + AggressiveOpts -XX: MaxMetaspaceSize = 256m, that is, I give it almost all memory. Let's start the server and connect to it with a visor (refer to the second article of the series for details). Using the cache command, we make sure that the cache exists and is pristine clean:
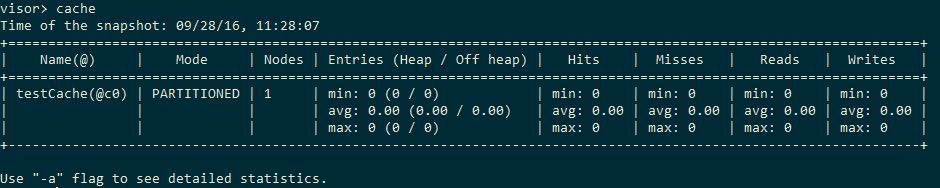
With CB connect using class
Here we connect in client mode to our server and take the cache from it. It is important to stop the client at the end of the test, otherwise the JMH swears that at the end of the test, there are still running threads - Ignite creates many of them for its operation. Also please note that there is a time spent on deleting the cache after each iteration. We will consider this as the cost of the research method, that is, we are not only looking at the performance of the cache itself, but also at the cost of administering it.
After building the project through mvn clean install, you can run tests, for example with the command
java -jar <BENCHMARK_HOME> \ benchmarks.jar PopulateParallelOnceBenchmark -jvmArgs "-server -Xmx14G -XX: + UseG1GC -XX: + UseBiasedLocking -XX: + UseCompressedOops" -gc true -f 2 -wi -30 -xX: + UseCompressedOops "-gc true -f 2 r 30s -t 2 -p cacheFactory = org.cache2k.benchmark.thirdparty.IgniteCacheFactory -rf json -rff e: \ tmp \ 1.json. JMH settings are taken from the original benchmark, we will not discuss them here. The "-t 1" parameter indicates the number of threads we are working with the cache. In memory, I pointed out 14Gb, just in case. "-f 2" means that two forks of the JVM will rise for test execution, this contributes to a sharp decrease in the confidence interval (the error column in the JMH output).
First, run the test for Apache Ignite with cacheMode = LOCAL. Since in this case there is no point in interacting with the server, we will raise the node for testing in server mode and will not connect to anyone. The time it took to cache the numbers from 1 to 1 million, 2 million, 4 million, 8 million is measured. For the number of threads 1, 4 and 8 (I have an 8-core processor), the results will be as follows:
We see that if 4 streams are about 1 times faster than 1, then adding 4 more streams gives a gain of about 20%. That is, non-linear scaling. For comparison, let's see what ConcurrentHashMap and cache2k will show.
ConcurrentHashMap:
cache2k:
Thus, in local mode, when inserting, the Ignite cache is about 10 times slower than ConcurrentHashMap and 4-5 times slower than cache2k. Next, we will try to evaluate what kind of overhead cache partitioning between two server nodes on the same machine (that is, the cache will be divided in half) —Ignite developers took steps to make it not gigantic. For example, they use their own serialization, which they say is 20 times faster than native. During the execution of the test, you can see the visor, now it makes sense, we have a topology:
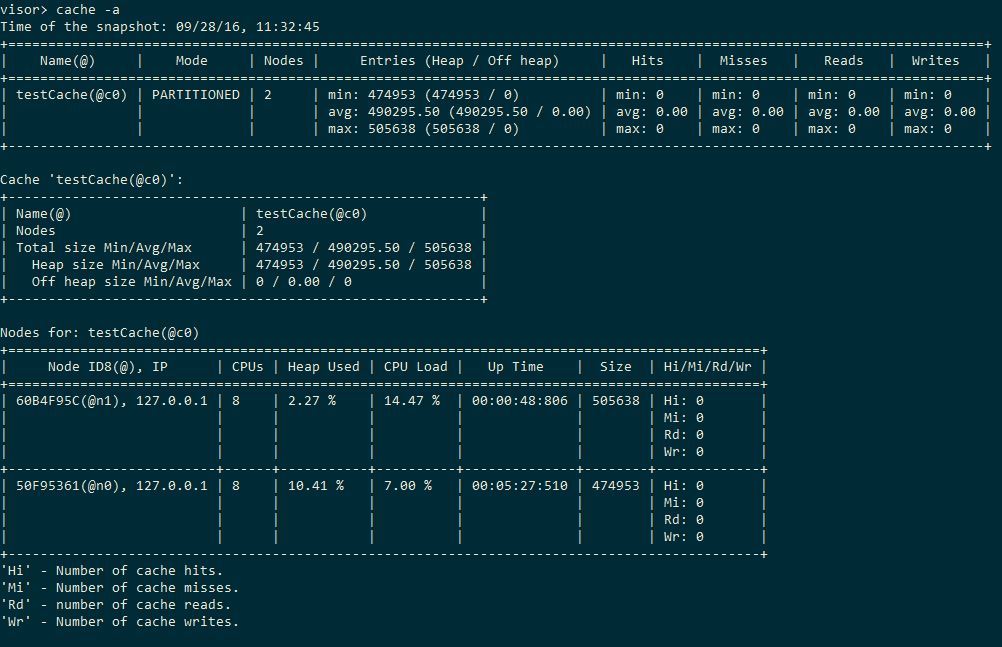
At the end we see these heart-rending numbers:

That is, cache partitioning was not very cheap, every 10 times it got worse. The REPLICATED cache mode has not been investigated, data would be stored in it at both nodes.
In order not to complicate the picture with a variety of parameters, we will conduct this test in 4 threads, run Ignite only locally. Here we use ReadOnlyBenchmark . The cache is filled with 100k entries and various randomly selected values from it, with a different hit rate. Measure the number of operations per second.
Here is the Cache2k / ConcurrentHashMap / Ignite data:
That is, Cache2k is 1.5-2.5 times worse than ConcurrentHashMap, and Ignite is 2-3 times worse.
Thus, Ignite, to put it mildly, does not shake the speed of its caching. I will try to answer in advance possible accusations:
Well, and so on. In general, in my experience, Ignite should be used as an architectural framework for distributed applications, and not as a source of performance gain. Although, perhaps, he is able to accelerate something else more inhibited. IMHO, of course.
I invite you to share your observations on the performance of Ignite.
For the study used benchmark cache2k-benchmark , designed to prove that the cache2k cache library is the fastest. Here at the same time and check. This article does not pursue the goal of comprehensive performance testing, or at least scientifically reliable, let the Apache Ignite developers do it. We just look at the order of magnitude, the main features and the relative position in the ranking, which will also include cache2k and the native cache on ConcurrentHashMap.
Testing method
As part of the testing methodology, I did not reinvent the wheel, and took the one described for cache2k . It consists in comparing the performance of a number of standard operations using a JMH- based library:
- Filling cache in multiple threads
- Read-only performance
As a reference, the method considers the values obtained for implementing a cache based on ConcurrentHashMap, since it is assumed that there is no place to be faster. Accordingly, in all nominations the struggle goes for second place. The cache2k-benchmark (hereinafter referred to as CB ) implements scripts for cache2k and several other providers: Caffeine, EhCache, Guava, Infinispan, TCache, as well as a native implementation based on ConcurrentHashMap. CB has implemented other benchmarks, but we will limit ourselves to these two.
The measurements were performed under the following conditions:
')
- JDK 1.8.0_45
- JMH 1.11.3
- Intel i7-6700 3.40Ghz 16Gb RAM
- Windows 7 x64
- JVM flags: -server -Xmx2G
- Apache Ignite 1.7.0
The work of the Apache Ignite cache was investigated in several modes, differing in topology (it is recommended to recall the basic concepts of the Apache Ignite topology ) and load distribution:
- Local cache (cacheMode = LOCAL) on the server node;
- Distributed cache on 1 machine (cacheMode = PARTITIONED, FULL_ASYNC), server-to-server;
According to the CB requirements, the IgniteCacheFactory class was implemented (the code is available in GitHub , based on the CB fork). The server and client are created with the following settings:
Server configuration
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="ignite.cfg-server" class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="gridName" value="testGrid"/> <property name="clientMode" value="false"/> <property name="peerClassLoadingEnabled" value="false"/> <property name="cacheConfiguration"> <list> <bean class="org.apache.ignite.configuration.CacheConfiguration"> <property name="name" value="testCache"/> <property name="cacheMode" value="LOCAL"/> <property name="statisticsEnabled" value="false" /> <property name="writeSynchronizationMode" value="FULL_ASYNC"/> </bean> </list> </property> <property name="discoverySpi"> <bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"> <property name="ipFinder"> <bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder"> <property name="addresses"> <list> <value>127.0.0.1:47520..47529</value> </list> </property> </bean> </property> <property name="localAddress" value="localhost"/> </bean> </property> <property name="communicationSpi"> <bean class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi"> <property name="localAddress" value="localhost"/> </bean> </property> </bean> </beans> It is important that the cache settings for the client and server are the same.
The server will be created from the command line outside the test using the same JVM with the options -Xms1g -Xmx14g -server -XX: + AggressiveOpts -XX: MaxMetaspaceSize = 256m, that is, I give it almost all memory. Let's start the server and connect to it with a visor (refer to the second article of the series for details). Using the cache command, we make sure that the cache exists and is pristine clean:
With CB connect using class
Cache factory for benchmark
public class IgniteCacheFactory extends BenchmarkCacheFactory { static final String CACHE_NAME = "testCache"; static IgniteCache cache; static Ignite ignite; static synchronized IgniteCache getIgniteCache() { if (ignite == null) ignite = Ignition.ignite("testGrid"); if (cache == null) cache = ignite.getOrCreateCache(CACHE_NAME); return cache; } @Override public BenchmarkCache<Integer, Integer> create(int _maxElements) { return new MyBenchmarkCache(getIgniteCache()); } static class MyBenchmarkCache extends BenchmarkCache<Integer, Integer> { IgniteCache<Integer, Integer> cache; MyBenchmarkCache(IgniteCache<Integer, Integer> cache) { this.cache = cache; } @Override public Integer getIfPresent(final Integer key) { return cache.get(key); } @Override public void put(Integer key, Integer value) { cache.put(key, value); } @Override public void destroy() { cache.destroy(); } @Override public int getCacheSize() { return cache.localSize(); } @Override public String getStatistics() { return cache.toString() + ": size=" + cache.size(); } } } Here we connect in client mode to our server and take the cache from it. It is important to stop the client at the end of the test, otherwise the JMH swears that at the end of the test, there are still running threads - Ignite creates many of them for its operation. Also please note that there is a time spent on deleting the cache after each iteration. We will consider this as the cost of the research method, that is, we are not only looking at the performance of the cache itself, but also at the cost of administering it.
Benchmark class
@State(Scope.Benchmark) public class IgnitePopulateParallelOnceBenchmark extends PopulateParallelOnceBenchmark { Ignite ignite; { if (ignite == null) ignite = Ignition.start("ignite/ignite-cache.xml"); } @TearDown(Level.Trial) public void destroy() { if (ignite != null) { ignite.close(); ignite = null; } } } results
After building the project through mvn clean install, you can run tests, for example with the command
java -jar <BENCHMARK_HOME> \ benchmarks.jar PopulateParallelOnceBenchmark -jvmArgs "-server -Xmx14G -XX: + UseG1GC -XX: + UseBiasedLocking -XX: + UseCompressedOops" -gc true -f 2 -wi -30 -xX: + UseCompressedOops "-gc true -f 2 r 30s -t 2 -p cacheFactory = org.cache2k.benchmark.thirdparty.IgniteCacheFactory -rf json -rff e: \ tmp \ 1.json. JMH settings are taken from the original benchmark, we will not discuss them here. The "-t 1" parameter indicates the number of threads we are working with the cache. In memory, I pointed out 14Gb, just in case. "-f 2" means that two forks of the JVM will rise for test execution, this contributes to a sharp decrease in the confidence interval (the error column in the JMH output).
Filling cache in multiple threads
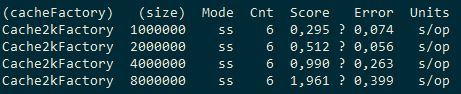
First, run the test for Apache Ignite with cacheMode = LOCAL. Since in this case there is no point in interacting with the server, we will raise the node for testing in server mode and will not connect to anyone. The time it took to cache the numbers from 1 to 1 million, 2 million, 4 million, 8 million is measured. For the number of threads 1, 4 and 8 (I have an 8-core processor), the results will be as follows:
 |  |  |
We see that if 4 streams are about 1 times faster than 1, then adding 4 more streams gives a gain of about 20%. That is, non-linear scaling. For comparison, let's see what ConcurrentHashMap and cache2k will show.
ConcurrentHashMap:
 | 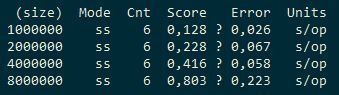 | 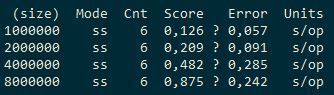 |
cache2k:
 | 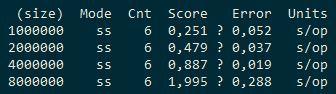 | 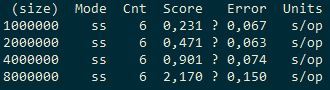 |
Thus, in local mode, when inserting, the Ignite cache is about 10 times slower than ConcurrentHashMap and 4-5 times slower than cache2k. Next, we will try to evaluate what kind of overhead cache partitioning between two server nodes on the same machine (that is, the cache will be divided in half) —Ignite developers took steps to make it not gigantic. For example, they use their own serialization, which they say is 20 times faster than native. During the execution of the test, you can see the visor, now it makes sense, we have a topology:
At the end we see these heart-rending numbers:
That is, cache partitioning was not very cheap, every 10 times it got worse. The REPLICATED cache mode has not been investigated, data would be stored in it at both nodes.
Only reading
In order not to complicate the picture with a variety of parameters, we will conduct this test in 4 threads, run Ignite only locally. Here we use ReadOnlyBenchmark . The cache is filled with 100k entries and various randomly selected values from it, with a different hit rate. Measure the number of operations per second.
Here is the Cache2k / ConcurrentHashMap / Ignite data:
 |  |  |
That is, Cache2k is 1.5-2.5 times worse than ConcurrentHashMap, and Ignite is 2-3 times worse.
findings
Thus, Ignite, to put it mildly, does not shake the speed of its caching. I will try to answer in advance possible accusations:
- I just do not know how to cook it , and if Ignite ottyunit, it will be better. Well, everything, if ottyunit, will be better. The work was investigated in the default configuration, in 90% of cases it will be the same in production;
- Apples and bananas , products of different classes, nails, microscope etc. Although it was possible to compare it with something more sophisticated like the Inifinispan type, no one demanded the impossible from Ignite in this study;
- Eliminate overhead , factor out expensive operations to raise a node and create / delete a cache, reduce the hearthbeat frequency, etc. But we are not measuring a horse in a vacuum ?;
- This product is not intended for local use , you need enterprise-equipment. Perhaps, but this will only smear the whole overhead in topology, and here we saw it all at once. During testing, %% CPU and memory never reached 100%;
- This is the specific product. You can look at the results as very decent, given the incredible power of Ignite. It is necessary to take into account that caching is carried out in another stream, through sockets, etc. On the other hand, Ignite is different and does not have it.
Well, and so on. In general, in my experience, Ignite should be used as an architectural framework for distributed applications, and not as a source of performance gain. Although, perhaps, he is able to accelerate something else more inhibited. IMHO, of course.
I invite you to share your observations on the performance of Ignite.
Links
Source: https://habr.com/ru/post/311140/
All Articles