Locks aren't that slow.
Locks in general and mutexes, as their private implementation, have a long history of incorrectly assessing the speed of their work. Back in 1986, Matthew Dillon wrote in one of the Usenet conferences: “Most people mistakenly realized that locks are slow.” Today, after many years, it can be stated that nothing has changed.
Indeed, locks may work slowly on some platforms, or in an extra-competitive code. And, if you are developing a multi-threaded application, then it is quite possible that sooner or later you will encounter a situation where any one block will consume a lot of resources (most likely due to an error in the code that causes it to call too often). But all these are special cases that have no relation to the statement “locks are slow” in the general case. As we will see below, code with locks can work quite productively.
One of the reasons for the misconceptions about the speed of operation of locks is that many programmers do not distinguish between the concepts of “lightweight mutex” and “mutex as an object of the OS kernel”. Always use lightweight mutexes . For example, if you are programming in C ++ on Windows, then your choice is critical sections.
')
 The second reason for errors can serve, paradoxically, as benchmarks. For example, later in this article we will measure the performance of locks under high load: each thread will require a lock to perform any action, and the locks themselves will be very short (and, as a result, very frequent). This is normal for an experiment, but this way of writing code is not what you need in a real application.
The second reason for errors can serve, paradoxically, as benchmarks. For example, later in this article we will measure the performance of locks under high load: each thread will require a lock to perform any action, and the locks themselves will be very short (and, as a result, very frequent). This is normal for an experiment, but this way of writing code is not what you need in a real application.
Locks are criticized for other reasons. There is a whole family of algorithms and technologies called " lock-free " programming. This is an incredibly exciting and challenging development method that can bring a huge performance boost to a range of applications. I know programmers who spent weeks polishing their “lock-free” algorithms, wrote a million tests on them - and all just to catch the rare bug associated with a certain combination of timings, a few months later. This combination of danger and reward for it can be very attractive for some programmers (including me). With the power of “lock-free,” classic locks begin to seem boring, obsolete, and slow.
But do not rush to discount them. One of the good examples where locks are often used and show good performance are memory allocators. A popular implementation of malloc from Doug Lea is often used in game devs. But it is single-threaded, so we need to protect it with locks. During an active game, we may well have a situation where several threads access the allocator at a frequency of, say, 15,000 times per second. During game loading, this figure can reach up to 100,000 times per second. As you will see later, this is absolutely not a problem for code with locks.
In this test, we run a stream that will generate random numbers using the Mersenne Vortex algorithm. In the course of work, he will regularly capture and release the synchronization object. The time between capture and release will be random, but on average it will tend to the value we set. For example, imagine that we want to use a lock 15,000 times per second and hold it 50% of the time. Here is how timeline will look in this case. Red color means the time when the lock is captured, gray - when free.

This is, in essence, the Poisson process. If we know the average amount of time to generate one random number (and this is, for example, 6.349 nanoseconds on a 2.66 GHz quad-core Xeon processor), we can measure the amount of work done in some units, not in seconds. We can use the technique described in my other article to determine the number of work units between capturing and releasing the synchronization object. Here is an implementation in C ++. I have omitted some non-essential details, but you can download the full source code here .
Now let's imagine that we run two such threads, each on its own processor core. Each thread will keep blocking 50% of its work time, but if one thread tries to gain access to a critical section while it is being held by another thread, then it will have to wait. A classic case of struggle for a shared resource.

I think this is a fairly realistic example of how locks are used in real applications. When we run the above code in two threads, we find that each thread spends about 25% of the time waiting and only 75% of the time doing the real work. Together, the two threads increase performance by 1.5 times compared with a single-threaded solution.
I ran this test with different variations on a 2.66 GHz quad-core Xeon processor - into 1 stream, into 2 streams, into 4 streams, each on its own core. I also varied the duration of locking a lock from a degenerate case, where the lock was released immediately, to the opposite face, when the lock took 100% of the time the thread was running. In all cases, the frequency of capture remained constant - 15,000 times per second.
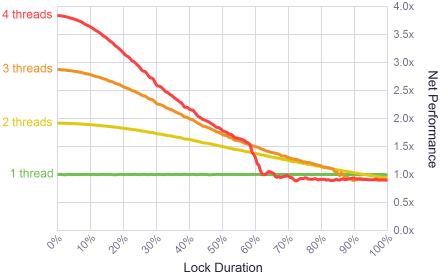
The results were quite interesting. For a short duration of capture (I would say up to 10% of the time), the system showed an extremely high degree of parallelism. Not perfect, but close to that. Locks work fast!
To evaluate the results in terms of practical application, I analyzed the work of the memory allocator in a multi-threaded game using a profiler. As the game progressed, there were about 15,000 calls to the allocator from three threads, blocking took up about 2% of the overall application performance. This value is in the “comfort zone” on the left side of the graph.
These results also show that as soon as the duration of the operation of the code inside the lock goes to the gracina at 90% of the total time, there is no longer any point in writing multi-threaded code. A single-threaded application will work faster in this case. What is even more surprising is the sharp jump in the productivity of 4 flows in the region of 60%. It was like an anomaly, so I repeated the test several times, tried running the tests in a different order. But each time it turned out the same thing. My best guess is that this combination of the number of threads, the duration of locks and the load on the processor brought the Windows scheduler to some extreme mode of operation, but I didn’t explore it more deeply.
Even a lightweight mutex incurs some overhead. A pair of lock / unlock operations for the critical section in Windows runs at about 23.5 nanoseconds (on the above processor). Thus, even 15,000 locks per second do not carry any significant load affecting performance. But what if we increase the frequency?
The above algorithm offers very convenient means of controlling the amount of work performed between the blocking locks. I conducted another series of tests: from 10 nanoseconds to 31 microseconds between locks, which corresponds to about 32,000 locks per second. Each test used two streams.

As you might imagine, at a very high frequency, the overhead of locks begins to affect the overall performance. At such frequencies, only a few instructions are executed inside the lock, which is comparable in time to the capture / release of the synchronization object itself. The good news is that for such short (and therefore simple) operations, it is quite possible to develop and use some lock-free algorithm.
At the same time, the results showed that calling locks up to 320,000 times per second (3.1 microseconds between locks) can be quite effective. In a game dev, a memory allocator can work normally at similar frequencies during game loading. You still get up to 1.5x gain from multithreading in this case (but only if the duration of the blocking itself is short).
We examined a wide range of different cases of using locks: from their very high performance to cases when the very idea of multithreading loses meaning. An example with the memory allocator in the game engine showed that in real applications, a high frequency of using locks is quite acceptable when certain conditions are met. With such arguments, no one will be able to simply say unfoundedly that "locks are slow." Yes, blocking can be used in an inefficient way, but you shouldn’t live with this fear - fortunately we have profilers who easily identify such problems. Every time you want to throw yourself headlong into the pool of exciting and dangerous lock-free programming - remember this article and the fact that locks can work quite quickly.
The purpose of this article was to return a little bit of respect to locks that they rightly deserve. I understand that with all the wealth of options for using locks in industrial software, programmers were accompanied by both successes and painful failures in the process of finding a balance of performance. If you have an example of one or the other - tell about it in the comments.
Indeed, locks may work slowly on some platforms, or in an extra-competitive code. And, if you are developing a multi-threaded application, then it is quite possible that sooner or later you will encounter a situation where any one block will consume a lot of resources (most likely due to an error in the code that causes it to call too often). But all these are special cases that have no relation to the statement “locks are slow” in the general case. As we will see below, code with locks can work quite productively.
One of the reasons for the misconceptions about the speed of operation of locks is that many programmers do not distinguish between the concepts of “lightweight mutex” and “mutex as an object of the OS kernel”. Always use lightweight mutexes . For example, if you are programming in C ++ on Windows, then your choice is critical sections.
')
The second reason for errors can serve, paradoxically, as benchmarks. For example, later in this article we will measure the performance of locks under high load: each thread will require a lock to perform any action, and the locks themselves will be very short (and, as a result, very frequent). This is normal for an experiment, but this way of writing code is not what you need in a real application.Locks are criticized for other reasons. There is a whole family of algorithms and technologies called " lock-free " programming. This is an incredibly exciting and challenging development method that can bring a huge performance boost to a range of applications. I know programmers who spent weeks polishing their “lock-free” algorithms, wrote a million tests on them - and all just to catch the rare bug associated with a certain combination of timings, a few months later. This combination of danger and reward for it can be very attractive for some programmers (including me). With the power of “lock-free,” classic locks begin to seem boring, obsolete, and slow.
But do not rush to discount them. One of the good examples where locks are often used and show good performance are memory allocators. A popular implementation of malloc from Doug Lea is often used in game devs. But it is single-threaded, so we need to protect it with locks. During an active game, we may well have a situation where several threads access the allocator at a frequency of, say, 15,000 times per second. During game loading, this figure can reach up to 100,000 times per second. As you will see later, this is absolutely not a problem for code with locks.
Benchmark
In this test, we run a stream that will generate random numbers using the Mersenne Vortex algorithm. In the course of work, he will regularly capture and release the synchronization object. The time between capture and release will be random, but on average it will tend to the value we set. For example, imagine that we want to use a lock 15,000 times per second and hold it 50% of the time. Here is how timeline will look in this case. Red color means the time when the lock is captured, gray - when free.
This is, in essence, the Poisson process. If we know the average amount of time to generate one random number (and this is, for example, 6.349 nanoseconds on a 2.66 GHz quad-core Xeon processor), we can measure the amount of work done in some units, not in seconds. We can use the technique described in my other article to determine the number of work units between capturing and releasing the synchronization object. Here is an implementation in C ++. I have omitted some non-essential details, but you can download the full source code here .
QueryPerformanceCounter(&start); for (;;) { // workunits = (int) (random.poissonInterval(averageUnlockedCount) + 0.5f); for (int i = 1; i < workunits; i++) random.integer(); // workDone += workunits; QueryPerformanceCounter(&end); elapsedTime = (end.QuadPart - start.QuadPart) * ooFreq; if (elapsedTime >= timeLimit) break; // EnterCriticalSection(&criticalSection); workunits = (int) (random.poissonInterval(averageLockedCount) + 0.5f); for (int i = 1; i < workunits; i++) random.integer(); // workDone += workunits; LeaveCriticalSection(&criticalSection); QueryPerformanceCounter(&end); elapsedTime = (end.QuadPart - start.QuadPart) * ooFreq; if (elapsedTime >= timeLimit) break; } Now let's imagine that we run two such threads, each on its own processor core. Each thread will keep blocking 50% of its work time, but if one thread tries to gain access to a critical section while it is being held by another thread, then it will have to wait. A classic case of struggle for a shared resource.
I think this is a fairly realistic example of how locks are used in real applications. When we run the above code in two threads, we find that each thread spends about 25% of the time waiting and only 75% of the time doing the real work. Together, the two threads increase performance by 1.5 times compared with a single-threaded solution.
I ran this test with different variations on a 2.66 GHz quad-core Xeon processor - into 1 stream, into 2 streams, into 4 streams, each on its own core. I also varied the duration of locking a lock from a degenerate case, where the lock was released immediately, to the opposite face, when the lock took 100% of the time the thread was running. In all cases, the frequency of capture remained constant - 15,000 times per second.
The results were quite interesting. For a short duration of capture (I would say up to 10% of the time), the system showed an extremely high degree of parallelism. Not perfect, but close to that. Locks work fast!
To evaluate the results in terms of practical application, I analyzed the work of the memory allocator in a multi-threaded game using a profiler. As the game progressed, there were about 15,000 calls to the allocator from three threads, blocking took up about 2% of the overall application performance. This value is in the “comfort zone” on the left side of the graph.
These results also show that as soon as the duration of the operation of the code inside the lock goes to the gracina at 90% of the total time, there is no longer any point in writing multi-threaded code. A single-threaded application will work faster in this case. What is even more surprising is the sharp jump in the productivity of 4 flows in the region of 60%. It was like an anomaly, so I repeated the test several times, tried running the tests in a different order. But each time it turned out the same thing. My best guess is that this combination of the number of threads, the duration of locks and the load on the processor brought the Windows scheduler to some extreme mode of operation, but I didn’t explore it more deeply.
Benchmark lock frequency capture
Even a lightweight mutex incurs some overhead. A pair of lock / unlock operations for the critical section in Windows runs at about 23.5 nanoseconds (on the above processor). Thus, even 15,000 locks per second do not carry any significant load affecting performance. But what if we increase the frequency?
The above algorithm offers very convenient means of controlling the amount of work performed between the blocking locks. I conducted another series of tests: from 10 nanoseconds to 31 microseconds between locks, which corresponds to about 32,000 locks per second. Each test used two streams.
As you might imagine, at a very high frequency, the overhead of locks begins to affect the overall performance. At such frequencies, only a few instructions are executed inside the lock, which is comparable in time to the capture / release of the synchronization object itself. The good news is that for such short (and therefore simple) operations, it is quite possible to develop and use some lock-free algorithm.
At the same time, the results showed that calling locks up to 320,000 times per second (3.1 microseconds between locks) can be quite effective. In a game dev, a memory allocator can work normally at similar frequencies during game loading. You still get up to 1.5x gain from multithreading in this case (but only if the duration of the blocking itself is short).
We examined a wide range of different cases of using locks: from their very high performance to cases when the very idea of multithreading loses meaning. An example with the memory allocator in the game engine showed that in real applications, a high frequency of using locks is quite acceptable when certain conditions are met. With such arguments, no one will be able to simply say unfoundedly that "locks are slow." Yes, blocking can be used in an inefficient way, but you shouldn’t live with this fear - fortunately we have profilers who easily identify such problems. Every time you want to throw yourself headlong into the pool of exciting and dangerous lock-free programming - remember this article and the fact that locks can work quite quickly.
The purpose of this article was to return a little bit of respect to locks that they rightly deserve. I understand that with all the wealth of options for using locks in industrial software, programmers were accompanied by both successes and painful failures in the process of finding a balance of performance. If you have an example of one or the other - tell about it in the comments.
Source: https://habr.com/ru/post/311134/
All Articles