YT: why does Yandex need its own MapReduce-system and how it works
Over the past six years, Yandex has been working on a system codenamed YT (in Russian, we call it “Yt”). This is the main platform for storing and processing large amounts of data - we already talked about it at YaC 2013. Since then, it has continued to evolve. Today I will talk about how the development of YT began, what was new in it and what else we plan to do in the near future.

By the way, on October 15 at the Yandex office we will tell not only about YT, but also about our other infrastructure technologies: Media Storage, Yandex Query Language and ClickHouse . At the meeting we will reveal the secret - we will tell you how many in Yandex MapReduce-systems.
')
By the nature of its activities, Yandex is constantly faced with the need to store and process data of such volumes that the average user never has to deal with. Search logs and indices, user data, cartographic information, intermediate data and the results of machine learning algorithms can all take up hundreds of petabytes of disk space. For efficient processing of such volumes, the MapReduce paradigm is traditionally used, which allows achieving a good balance between computation efficiency and simplicity of user code.
In one form or another, MapReduce-like calculations are used in all of the largest companies involved in Big Data: Google, Microsoft, Facebook, Yahoo and others. In addition, de facto MapReduce has long become standard when working with data of a much more modest size - not least thanks to the successful open source implementation in the Hadoop MapReduce framework and the presence of a developed ecosystem that provides convenient analytical tools on top of MapReduce.
Of course, not all tasks successfully fall on the MapReduce model. The main limitation is that it implies batch execution, in which significant amounts of data go through the whole chain of transformations. These transformations take minutes, hours, and sometimes many days. This way of working is unsuitable for interactive responses by users, therefore, in addition to MapReduce-calculations, systems like KV-storage (key-value storage) are traditionally used, which allow reading and writing data (and possibly some calculations over them) with low latency. There are many dozens of such systems in the world: starting with classic RDBMS (Oracle, Microsoft SQL Server, MySQL, PostgreSQL), suitable for storing tens and hundreds of terabytes of data, and ending with NoSQL systems (HBase, Cassandra) capable of working with many petabytes.
In the case of MapReduce, the presence of several different and parallel used systems does not make much sense. The fact is that all of them, in fact, will solve the same task. However, for KV-storages, the degree of diversity of tasks and the general level of specificity are much higher. In Yandex, we use several such systems at once. Part of the data is stored in MySQL, well-proven in terms of reliability and variety of functions. Where the data volume is large and the speed of their processing is important, we use ClickHouse , Yandex's own DBMS. Finally, for the last three years we have been actively working on the task of creating a KV-storage facility within the framework of YT. We use it when high reliability of storage, support for transactionalities, and integration with MapReduce-calculations are necessary.
For a large part of our own Big Data-infrastructure there are publicly available products that solve similar problems. First of all, of course, we are talking about the Hadoop ecosystem, on the basis of which - in theory - it is possible to build the entire computing stack: starting with the distributed file system (HDFS) and the MapReduce framework and ending with KV storages (HBase, Cassandra), tools for analytics (Hive, Impala) and data stream processing systems (Spark).
For small and medium-sized companies working with Big Data, Hadoop is often the only choice. Large players, in turn, either actively use and develop Hadoop (as done, for example, Yahoo and Facebook), or create their own infrastructure (Google, Microsoft).
Choosing between these two possibilities, Yandex followed the second path. This decision was not easy, and, of course, it can not be regarded as the only correct one. Many factors have been taken into account. We will try to briefly summarize the most significant ones:
Of course, by refusing to reuse ready-made Hadoop-tools, we greatly complicated our task, since there is no way to compete with the Hadoop-community, which numbers many hundreds and thousands of developers around the world. On the other hand, as indicated above, the actual impossibility to obtain at a reasonable price the changes that are critically important for Yandex in the ecosystem, as well as the experience of companies using Hadoop, outweighed all the advantages.
Given the choices made, we are forced to actively work on the most relevant parts of the infrastructure for us, investing the main forces in improving a small number of key systems: the YT platform itself, as well as the tools created on top of it.
From the above, it follows that at least YT is a MapReduce system. This is true, represents, but not all. From birth, YT was designed to become the basis for solving a wide range of computational problems in the field of Big Data.
Over the three years that have passed since the day of the YT report on YaC , the system has undergone significant development. Many of the problems mentioned then were successfully solved. However, we are not bored because the company (and with it the infrastructure) is actively developing. So new tasks come every day.
We briefly describe the current YT architecture.
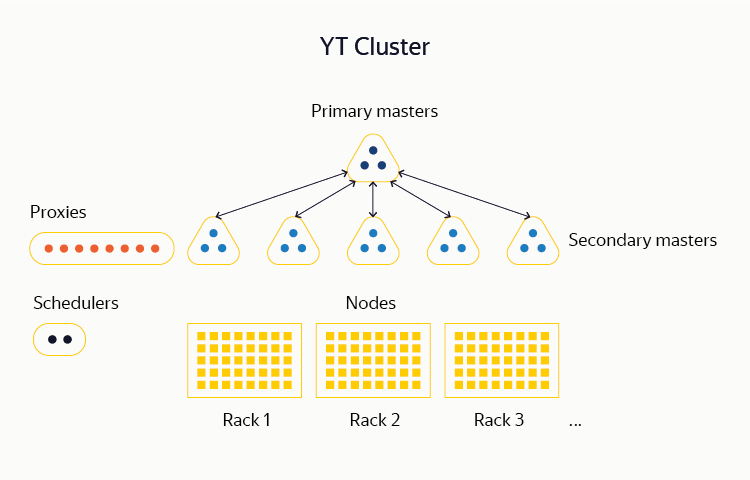
YT is a multicomponent system whose unit of deployment is a cluster . Now we support clusters with the total number of servers ( nodes ) up to 10,000. We can store hundreds of petabytes of data on such a number of machines, as well as plan and perform calculations on hundreds of thousands of CPU cores.
Most of our YT clusters are located entirely within a single data center. This is done because in the process of MapReduce-computing it is important to have a homogeneous network between the machines, which in our scales is almost impossible to achieve if they are separated geographically. There are exceptions to this rule: some YT clusters, in which the internal data flows are small, are still distributed among several DCs. So a complete failure of one or more of them does not affect the operation of the system.
The bottom-most YT layer forms a distributed file system (DFS). Early DFS implementations were similar to classic HDFS or GFS. Data is stored on the nodes of the cluster in the form of small (usually up to 1 GB) fragments, called chunks . Information about all the chunks available in the system, as well as which files and tables are present in DFS and what chunks they consist of, is located in the memory of the master servers .
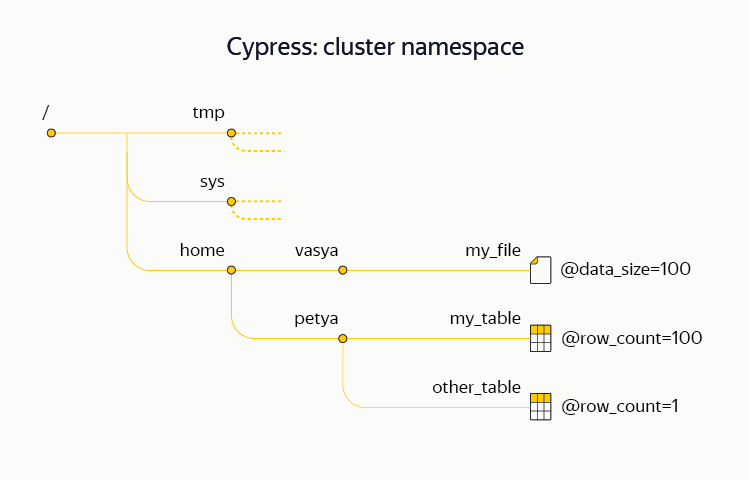
The namespace (directory structure, file and table names in them, meta-attributes, access rights, etc.) of our DFS is called Cypress . Unlike most traditional file systems, Cypress supports transactionality, that is, it allows you to atomically perform complex operations with its structure and data. For example, as part of a Cypress transaction, it is possible to atomically upload several files to the system, and also to note in the meta-attributes that a new piece of data has arrived. Cypress also supports a system of locks on the nodes. We actively use this opportunity in practice: one of the YT clusters is distributed between data centers and practically does not store chunks, but its Cypress is used by various infrastructural processes as a highly available metadata repository and coordination service (similar to Chubby, Zookeeper or etcd).
Given the number of machines that make up the clusters, equipment failures occur every day and do not represent a unique phenomenon. The system is designed to survive most types of typical failures automatically, without human intervention. In particular, the system lacks the so-called single points of failure (SPoF, single point of failure), that is, its work cannot be broken by the failure of one server. Moreover, from a practical point of view, it is important that the system continues to work in a situation when larger random subsets (for example, two randomly selected servers in a cluster) or even entire structural groups of machines (say, racks) have failed at the same time.
For a distributed DFS, the master server, if it is alone, forms a natural SPoF, since when it is turned off, the system ceases to be able to receive and transmit data. Therefore, from the very beginning, the master servers were replicated . In the simplest case, we can assume that instead of one master server we have three, the state of which is maintained identical. The system is able to continue to work when any of the three master servers fail. Such switches occur fully automatically and do not cause downtime. Synchronization between a set of master servers is provided using one of the varieties of the consensus algorithm. In our case, we use a proprietary library — it's called Hydra. The closest open source analogue of Hydra is the Raft algorithm. Similar ideas (ZAB algorithm) are used in the Apache Zookeeper system.

The described scheme with three replicated master servers is good in terms of fault tolerance, but does not allow the cluster to be scaled to the volumes we need. The fact is that in terms of the volume of metadata, we remain limited to the memory of a separate master server. Therefore, about a year ago we implemented a user-transparent system for sharding metadata of chunks, which we call multicell. When using it, the metadata are divided (as they say, shard ) between the various triplets of the master servers. Hydra is still running inside each triplet, providing fault tolerance.
Note that sharding metadata chunks within HDFS is not provided. Instead, it is proposed to use a less convenient HDFS federation - a project of dubious utility, since for small data volumes it does not make sense, and experience with its use in large companies, according to available data, is not always positive.
Fault tolerance, of course, is important not only at the metadata level, but also at the data level stored in the chunks. To achieve this goal, we use two methods. The first is replication , that is, storing each chunk in several (usually three) copies on different servers. The second is erasure encoding , that is, splitting each chunk into a small number of parts, calculating additional parts with checksums and storing all these parts on different servers.

The latter method is especially interesting. If using conventional triple replication to store the amount of X you need to spend another 2X for additional replicas, then using the appropriate erasure codes this overhead decreases to X / 2. Given the volumes that we have to deal with (these are dozens and hundreds of petabytes), the gain is enormous. As part of our existing systems, erasure coding has been available for about four years. Note that similar support in Hadoop (the so-called EC-HDFS) became available only less than a year ago.
Tables
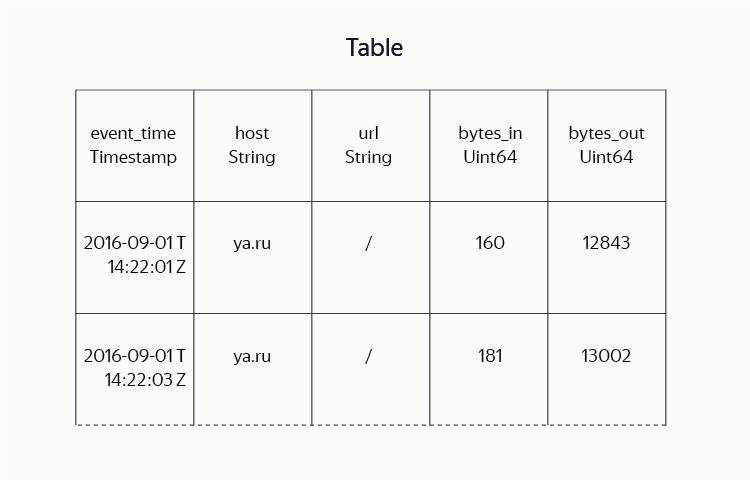
Unlike HDFS bundles with Hadoop Mapreduce, where the main storage unit visible to a user is a file, although present in YT DFS files, they are not used so actively. Instead, the data is mainly stored in tables — sets of rows consisting of columns of data. During the development of the system, we spent a lot of effort in order to achieve efficient and compact data storage in tables. We combine the ideas of column storage formats (Hadoop ORC, Parquet) with a variety of block compression algorithms (lz4, gzip, brotli, etc.).
For the user, such implementation details are transparent: it simply sets the table schema (specifies the names and types of columns), the desired compression algorithm, the replication method, etc. Where in Hadoop users are forced to present the tables as a set of files containing data in a specific format , YT users operate with terms of tables as a whole and their parts: perform sorting, map-, reduce- and join-operations, read tables by ranges of rows, etc.
Most of the computation of the data we have is performed in the MapReduce model. As already mentioned, the total pool of computing power of the cluster is hundreds of thousands of cores. Their use is controlled by a central planner. It breaks up large computations (called operations ) like map, sort, reduce, etc. into separate local parts ( jobs ), allocates resources between them, controls their execution, and provides fault tolerance by restarting part of the calculations in case of failures.
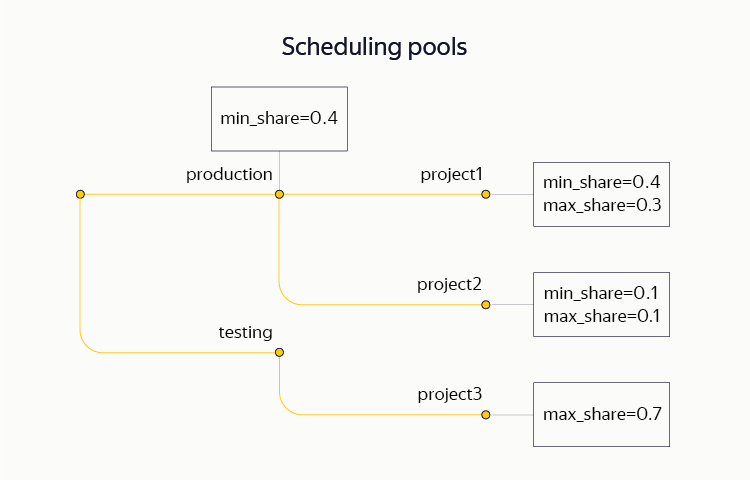
We allocate two main resources for planning: PU and memory. To share resources between operations, we use a very flexible Hierarchical Dominant Resource Fair Share scheme, which allows grouping calculations into a tree structure and setting constraints (lower and upper) on separate subtrees. In particular, within a single cluster, various projects simultaneously hold both production- and testing-contours. On the same cluster, some of the resources are allocated for ad hoc analytics.
During the day, a typical large YT cluster performs more than 250 thousand operations, totally consisting of 100 million jobs.
At the moment, there is always one active scheduler in the cluster, but there are always passive standby replicas in the system for fault tolerance. When the main scheduler fails, a switch to another replica of it takes about ten seconds. The latter restores the state of computational operations and continues their execution.
Now the scheduler is the only most critically loaded machine in the entire cluster. The scheduler code has been repeatedly optimized for the number of jobs (hundreds of thousands) and operations (thousands) that have to be managed simultaneously. We managed to achieve a high degree of parallelism, so now we are actually fully using the resources of one machine. However, for the further growth of the cluster size, this approach seems to be a dead end, so we are actively working to create a new distributed scheduler.
Currently, the MapReduce-YT layer is daily used by many hundreds of developers, analysts and managers of Yandex to perform analytical calculations on data. Also, it is used by dozens of various projects that automatically prepare data for our main services.
As already mentioned several times, MapReduce calculations do not cover the entire spectrum of the tasks before us. Classic MapReduce tables (we call them static ) are great for efficiently storing large amounts of data and processing them in MapReduce operations. On the other hand, they are not ways to replace KV storage. Indeed, the typical time to read a row from a static table is measured in hundreds of milliseconds. It takes no less to write to such a table, and it’s only possible at the end, so there’s no need to talk about using such tables to create interactive services.
About three years ago, in the framework of YT, we started working on the creation of new dynamic tables, similar to those found in systems like HBase and Cassandra. To do this, we needed to make a lot of modifications to the base layers (Hydra, DFS). As a result, we really have the opportunity, within the framework of a common namespace with MapReduce, to create dynamic tables for the user. They support efficient read and write operations for strings and their ranges on the primary key. Our system is distinguished by transactivity and strict consistency (the so-called snapshot isolation level), as well as support for distributed transactions — that is, the ability to atomically change several rows of one table or even several different tables in one transaction.
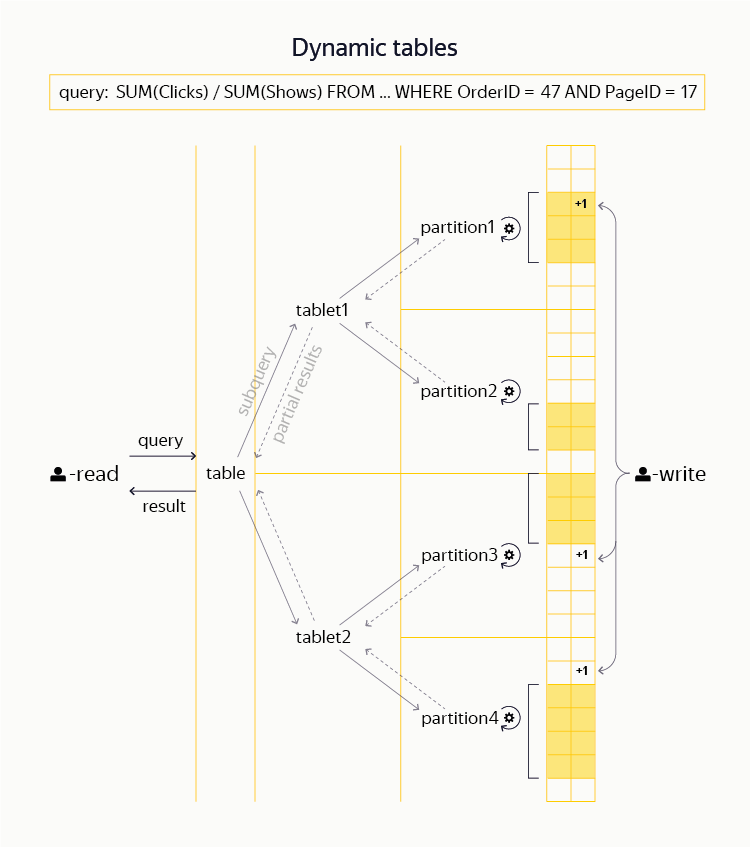
From the point of view of the closest analogues, our dynamic tables are close to the classical ideas of BigTable and HBase, but are adapted to support a stronger transactional model. At the same time, despite the similar basic principles, it does not seem to us realistic to add such functionality to existing open source systems, say in HBase, by means of commit patches. (For example, see the ticket that discusses porting a portion of the code from the HydraBase project being developed on Facebook to HBase. An example is particularly indicative of the fact that the HydraBase functionality that enhances system availability through hot replication of the server region is extremely important for our applications. and we support it inside YT.)
On top of these tables, we also have the ability to distribute interactive queries, including filtering, aggregation and the simplest types of joins. (Among publicly available systems, such opportunities are provided, for example, by Impala or Presto.) In Yandex, the largest user of dynamic tables is the Banner system, which stores there information on clicks and impressions of advertisements and provides advertisers with the opportunity to analyze their campaigns. Like any decent distributed KV storage, YT is able to handle many millions of read and write operations per second.
Even from the description above it is easy to understand that the system is actively developing. Indeed, given the scale and ambitiousness of the tasks before us, it is difficult to come up with at least one aspect of the system that could not be improved with a clear and well measurable benefit.
In the final part, it is worth highlighting a number of long-term development projects that we are engaged in as part of YT.
Cross-datacenter replication
Yandex-scale companies cannot afford to be dependent on a single data center, and in fact a YT cluster is deployed in several at once. The task of synchronizing data between them is both complex and important, because it allows you to shift some of the concerns about fault tolerance from high-level services to the core infrastructure.
In the case when the stored data volumes are small, we traditionally deploy cross-datacenter installations of YT that can survive the loss of data centers entirely. On the other hand, this approach has several disadvantages. In particular, the development and updating of such cross-datacenter installations is a very non-trivial task. The fact is that it is necessary to ensure, if possible, close to 100% uptime.
A system from a set of semi-independent clusters, one in each data center, looks more convenient from an operational point of view. Therefore, we often use separate clusters with configured automatic processes for replicating data between static tables in them.
We also learn to replicate dynamic tables — this allows us to implement various replication modes (synchronous, asynchronous) and quorum writing to a set of data centers.
Further scaling of master servers
So, in YT, we learned to shard some of the master server metadata related to chunks. But users in most cases do not work directly with chunks, but with a tree of files, tables, and directories — that is, with Cypress. We still keep this tree in memory of one master server (three with replication), which naturally limits the number of nodes in it to about 100 million. As the number of users grows and clusters expand, we may have to solve the sharding task this piece of metadata.
Integration of static and dynamic tables
In spite of the fact that initially dynamic tables were created “aside” from the MapReduce-model and static tables, quite quickly, the benefits of being able to combine these tools within one calculation became clear.
For example, a long chain of MapReduce calculations can be used to build a static table with an index for a service, and then turn it into a dynamic one with a flick of the wrist, load it into memory, and give the service frontend the ability to take its data with latency, measured in milliseconds.
Or, say, it is possible in the process of performing complex MapReduce calculations to refer to the dynamic table for reference data by performing the so-called map-side join.
The integration of dynamics and statics within the framework of YT is a large and complex project, which is now far from complete, but it allows you to radically simplify and optimize the solution of a number of tasks that are traditionally considered to be complex.
Cloud power
It is not a secret that the so-called search clusters consisting of machines that directly store search index data and respond to user requests constitute a significant part of the Yandex server fleet. The load profile of such machines is very characteristic. If in the case of the main YR MapReduce clusters the bottleneck is almost always CPU (which shows almost 100% load 24/7), then in the search cluster the CPU load changes noticeably - for example, depending on the time of day.
This makes it possible to use the released capacity to perform MapReduce calculations. They are thus partially transferred to the search cloud of dynamically changing sizes. Efficient use of such additional capacity is another priority project for us. For its success, it is necessary to develop a cluster management system, containerization and sharing of common resources between projects (these include memory, CPU, network and disk).
By the way, on October 15 at the Yandex office we will tell not only about YT, but also about our other infrastructure technologies: Media Storage, Yandex Query Language and ClickHouse . At the meeting we will reveal the secret - we will tell you how many in Yandex MapReduce-systems.
')
What problem are we solving?
By the nature of its activities, Yandex is constantly faced with the need to store and process data of such volumes that the average user never has to deal with. Search logs and indices, user data, cartographic information, intermediate data and the results of machine learning algorithms can all take up hundreds of petabytes of disk space. For efficient processing of such volumes, the MapReduce paradigm is traditionally used, which allows achieving a good balance between computation efficiency and simplicity of user code.
In one form or another, MapReduce-like calculations are used in all of the largest companies involved in Big Data: Google, Microsoft, Facebook, Yahoo and others. In addition, de facto MapReduce has long become standard when working with data of a much more modest size - not least thanks to the successful open source implementation in the Hadoop MapReduce framework and the presence of a developed ecosystem that provides convenient analytical tools on top of MapReduce.
Of course, not all tasks successfully fall on the MapReduce model. The main limitation is that it implies batch execution, in which significant amounts of data go through the whole chain of transformations. These transformations take minutes, hours, and sometimes many days. This way of working is unsuitable for interactive responses by users, therefore, in addition to MapReduce-calculations, systems like KV-storage (key-value storage) are traditionally used, which allow reading and writing data (and possibly some calculations over them) with low latency. There are many dozens of such systems in the world: starting with classic RDBMS (Oracle, Microsoft SQL Server, MySQL, PostgreSQL), suitable for storing tens and hundreds of terabytes of data, and ending with NoSQL systems (HBase, Cassandra) capable of working with many petabytes.
In the case of MapReduce, the presence of several different and parallel used systems does not make much sense. The fact is that all of them, in fact, will solve the same task. However, for KV-storages, the degree of diversity of tasks and the general level of specificity are much higher. In Yandex, we use several such systems at once. Part of the data is stored in MySQL, well-proven in terms of reliability and variety of functions. Where the data volume is large and the speed of their processing is important, we use ClickHouse , Yandex's own DBMS. Finally, for the last three years we have been actively working on the task of creating a KV-storage facility within the framework of YT. We use it when high reliability of storage, support for transactionalities, and integration with MapReduce-calculations are necessary.
Why not use the Hadoop stack?
For a large part of our own Big Data-infrastructure there are publicly available products that solve similar problems. First of all, of course, we are talking about the Hadoop ecosystem, on the basis of which - in theory - it is possible to build the entire computing stack: starting with the distributed file system (HDFS) and the MapReduce framework and ending with KV storages (HBase, Cassandra), tools for analytics (Hive, Impala) and data stream processing systems (Spark).
For small and medium-sized companies working with Big Data, Hadoop is often the only choice. Large players, in turn, either actively use and develop Hadoop (as done, for example, Yahoo and Facebook), or create their own infrastructure (Google, Microsoft).
Choosing between these two possibilities, Yandex followed the second path. This decision was not easy, and, of course, it can not be regarded as the only correct one. Many factors have been taken into account. We will try to briefly summarize the most significant ones:
- Historically, in Yandex, the largest amount of computational code is written in C ++; however, Hadoop is essentially focused on the Java platform. In itself, this is not fatal - you can always write adapters to support old code for C ++, and develop new Java. However, we have to admit that in the company over the years of development, considerable experience has been accumulated precisely in working with C ++, and Java development is much more modest.
- Examples of the successful use of Hadoop in companies like Yahoo and Facebook show that for the effective use of Hadoop, its vanilla version is usually not taken, but fork is executed followed by deep refinement. To create it is extremely desirable, and even the presence of core Hadoop developers in the company is necessary. These specialists are extremely rare even by the standards of the American IT market, so for Yandex, hiring them in sufficient quantity is a very difficult task.
- Perhaps the above fork of the platform will never be poured into the main branch of development and will cease to be compatible with this branch. Then the advantage of using ready-made ecosystem solutions will be limited to two sets of tools: which you can “take with you” at the time of separation and which can be transferred over the fork.
- But why bother to fork Hadoop? Why not use publicly available and developed versions, possibly participating in their development? The fact is that, although Hadoop itself is quite good, it is far from perfect. During our work on our own infrastructure in Yandex, we have repeatedly encountered problems that could only be solved at the cost of very radical changes to our systems. Since we do not have enough competence in Hadoop-development, we can not make such extensive changes to the public branch. Such radical patches almost certainly will not be able to get a code review in a reasonable time.
- It could also be assumed that for the full integration of Hadoop within the company it is not necessary to have highly qualified specialists on this platform - it suffices to limit ourselves to the services of large integrators of Hadoop solutions, for example, Cloudera. However, common sense and experience of companies close to us shows that although such help may be useful at the first stage of implementation, complex tasks that require significant modifications to the Hadoop codebase would still have to be solved independently (see, for example, the experience of Mail. Ru ).
Of course, by refusing to reuse ready-made Hadoop-tools, we greatly complicated our task, since there is no way to compete with the Hadoop-community, which numbers many hundreds and thousands of developers around the world. On the other hand, as indicated above, the actual impossibility to obtain at a reasonable price the changes that are critically important for Yandex in the ecosystem, as well as the experience of companies using Hadoop, outweighed all the advantages.
Given the choices made, we are forced to actively work on the most relevant parts of the infrastructure for us, investing the main forces in improving a small number of key systems: the YT platform itself, as well as the tools created on top of it.
What are we able now?
From the above, it follows that at least YT is a MapReduce system. This is true, represents, but not all. From birth, YT was designed to become the basis for solving a wide range of computational problems in the field of Big Data.
Over the three years that have passed since the day of the YT report on YaC , the system has undergone significant development. Many of the problems mentioned then were successfully solved. However, we are not bored because the company (and with it the infrastructure) is actively developing. So new tasks come every day.
We briefly describe the current YT architecture.
Cluster
YT is a multicomponent system whose unit of deployment is a cluster . Now we support clusters with the total number of servers ( nodes ) up to 10,000. We can store hundreds of petabytes of data on such a number of machines, as well as plan and perform calculations on hundreds of thousands of CPU cores.
Most of our YT clusters are located entirely within a single data center. This is done because in the process of MapReduce-computing it is important to have a homogeneous network between the machines, which in our scales is almost impossible to achieve if they are separated geographically. There are exceptions to this rule: some YT clusters, in which the internal data flows are small, are still distributed among several DCs. So a complete failure of one or more of them does not affect the operation of the system.
DFS
The bottom-most YT layer forms a distributed file system (DFS). Early DFS implementations were similar to classic HDFS or GFS. Data is stored on the nodes of the cluster in the form of small (usually up to 1 GB) fragments, called chunks . Information about all the chunks available in the system, as well as which files and tables are present in DFS and what chunks they consist of, is located in the memory of the master servers .
The namespace (directory structure, file and table names in them, meta-attributes, access rights, etc.) of our DFS is called Cypress . Unlike most traditional file systems, Cypress supports transactionality, that is, it allows you to atomically perform complex operations with its structure and data. For example, as part of a Cypress transaction, it is possible to atomically upload several files to the system, and also to note in the meta-attributes that a new piece of data has arrived. Cypress also supports a system of locks on the nodes. We actively use this opportunity in practice: one of the YT clusters is distributed between data centers and practically does not store chunks, but its Cypress is used by various infrastructural processes as a highly available metadata repository and coordination service (similar to Chubby, Zookeeper or etcd).
Given the number of machines that make up the clusters, equipment failures occur every day and do not represent a unique phenomenon. The system is designed to survive most types of typical failures automatically, without human intervention. In particular, the system lacks the so-called single points of failure (SPoF, single point of failure), that is, its work cannot be broken by the failure of one server. Moreover, from a practical point of view, it is important that the system continues to work in a situation when larger random subsets (for example, two randomly selected servers in a cluster) or even entire structural groups of machines (say, racks) have failed at the same time.
For a distributed DFS, the master server, if it is alone, forms a natural SPoF, since when it is turned off, the system ceases to be able to receive and transmit data. Therefore, from the very beginning, the master servers were replicated . In the simplest case, we can assume that instead of one master server we have three, the state of which is maintained identical. The system is able to continue to work when any of the three master servers fail. Such switches occur fully automatically and do not cause downtime. Synchronization between a set of master servers is provided using one of the varieties of the consensus algorithm. In our case, we use a proprietary library — it's called Hydra. The closest open source analogue of Hydra is the Raft algorithm. Similar ideas (ZAB algorithm) are used in the Apache Zookeeper system.
The described scheme with three replicated master servers is good in terms of fault tolerance, but does not allow the cluster to be scaled to the volumes we need. The fact is that in terms of the volume of metadata, we remain limited to the memory of a separate master server. Therefore, about a year ago we implemented a user-transparent system for sharding metadata of chunks, which we call multicell. When using it, the metadata are divided (as they say, shard ) between the various triplets of the master servers. Hydra is still running inside each triplet, providing fault tolerance.
Note that sharding metadata chunks within HDFS is not provided. Instead, it is proposed to use a less convenient HDFS federation - a project of dubious utility, since for small data volumes it does not make sense, and experience with its use in large companies, according to available data, is not always positive.
Fault tolerance, of course, is important not only at the metadata level, but also at the data level stored in the chunks. To achieve this goal, we use two methods. The first is replication , that is, storing each chunk in several (usually three) copies on different servers. The second is erasure encoding , that is, splitting each chunk into a small number of parts, calculating additional parts with checksums and storing all these parts on different servers.
The latter method is especially interesting. If using conventional triple replication to store the amount of X you need to spend another 2X for additional replicas, then using the appropriate erasure codes this overhead decreases to X / 2. Given the volumes that we have to deal with (these are dozens and hundreds of petabytes), the gain is enormous. As part of our existing systems, erasure coding has been available for about four years. Note that similar support in Hadoop (the so-called EC-HDFS) became available only less than a year ago.
Tables
Unlike HDFS bundles with Hadoop Mapreduce, where the main storage unit visible to a user is a file, although present in YT DFS files, they are not used so actively. Instead, the data is mainly stored in tables — sets of rows consisting of columns of data. During the development of the system, we spent a lot of effort in order to achieve efficient and compact data storage in tables. We combine the ideas of column storage formats (Hadoop ORC, Parquet) with a variety of block compression algorithms (lz4, gzip, brotli, etc.).
For the user, such implementation details are transparent: it simply sets the table schema (specifies the names and types of columns), the desired compression algorithm, the replication method, etc. Where in Hadoop users are forced to present the tables as a set of files containing data in a specific format , YT users operate with terms of tables as a whole and their parts: perform sorting, map-, reduce- and join-operations, read tables by ranges of rows, etc.
MapReduce Scheduler
Most of the computation of the data we have is performed in the MapReduce model. As already mentioned, the total pool of computing power of the cluster is hundreds of thousands of cores. Their use is controlled by a central planner. It breaks up large computations (called operations ) like map, sort, reduce, etc. into separate local parts ( jobs ), allocates resources between them, controls their execution, and provides fault tolerance by restarting part of the calculations in case of failures.
We allocate two main resources for planning: PU and memory. To share resources between operations, we use a very flexible Hierarchical Dominant Resource Fair Share scheme, which allows grouping calculations into a tree structure and setting constraints (lower and upper) on separate subtrees. In particular, within a single cluster, various projects simultaneously hold both production- and testing-contours. On the same cluster, some of the resources are allocated for ad hoc analytics.
During the day, a typical large YT cluster performs more than 250 thousand operations, totally consisting of 100 million jobs.
At the moment, there is always one active scheduler in the cluster, but there are always passive standby replicas in the system for fault tolerance. When the main scheduler fails, a switch to another replica of it takes about ten seconds. The latter restores the state of computational operations and continues their execution.
Now the scheduler is the only most critically loaded machine in the entire cluster. The scheduler code has been repeatedly optimized for the number of jobs (hundreds of thousands) and operations (thousands) that have to be managed simultaneously. We managed to achieve a high degree of parallelism, so now we are actually fully using the resources of one machine. However, for the further growth of the cluster size, this approach seems to be a dead end, so we are actively working to create a new distributed scheduler.
Currently, the MapReduce-YT layer is daily used by many hundreds of developers, analysts and managers of Yandex to perform analytical calculations on data. Also, it is used by dozens of various projects that automatically prepare data for our main services.
KV storage
As already mentioned several times, MapReduce calculations do not cover the entire spectrum of the tasks before us. Classic MapReduce tables (we call them static ) are great for efficiently storing large amounts of data and processing them in MapReduce operations. On the other hand, they are not ways to replace KV storage. Indeed, the typical time to read a row from a static table is measured in hundreds of milliseconds. It takes no less to write to such a table, and it’s only possible at the end, so there’s no need to talk about using such tables to create interactive services.
About three years ago, in the framework of YT, we started working on the creation of new dynamic tables, similar to those found in systems like HBase and Cassandra. To do this, we needed to make a lot of modifications to the base layers (Hydra, DFS). As a result, we really have the opportunity, within the framework of a common namespace with MapReduce, to create dynamic tables for the user. They support efficient read and write operations for strings and their ranges on the primary key. Our system is distinguished by transactivity and strict consistency (the so-called snapshot isolation level), as well as support for distributed transactions — that is, the ability to atomically change several rows of one table or even several different tables in one transaction.
From the point of view of the closest analogues, our dynamic tables are close to the classical ideas of BigTable and HBase, but are adapted to support a stronger transactional model. At the same time, despite the similar basic principles, it does not seem to us realistic to add such functionality to existing open source systems, say in HBase, by means of commit patches. (For example, see the ticket that discusses porting a portion of the code from the HydraBase project being developed on Facebook to HBase. An example is particularly indicative of the fact that the HydraBase functionality that enhances system availability through hot replication of the server region is extremely important for our applications. and we support it inside YT.)
On top of these tables, we also have the ability to distribute interactive queries, including filtering, aggregation and the simplest types of joins. (Among publicly available systems, such opportunities are provided, for example, by Impala or Presto.) In Yandex, the largest user of dynamic tables is the Banner system, which stores there information on clicks and impressions of advertisements and provides advertisers with the opportunity to analyze their campaigns. Like any decent distributed KV storage, YT is able to handle many millions of read and write operations per second.
What are our plans?
Even from the description above it is easy to understand that the system is actively developing. Indeed, given the scale and ambitiousness of the tasks before us, it is difficult to come up with at least one aspect of the system that could not be improved with a clear and well measurable benefit.
In the final part, it is worth highlighting a number of long-term development projects that we are engaged in as part of YT.
Cross-datacenter replication
Yandex-scale companies cannot afford to be dependent on a single data center, and in fact a YT cluster is deployed in several at once. The task of synchronizing data between them is both complex and important, because it allows you to shift some of the concerns about fault tolerance from high-level services to the core infrastructure.
In the case when the stored data volumes are small, we traditionally deploy cross-datacenter installations of YT that can survive the loss of data centers entirely. On the other hand, this approach has several disadvantages. In particular, the development and updating of such cross-datacenter installations is a very non-trivial task. The fact is that it is necessary to ensure, if possible, close to 100% uptime.
A system from a set of semi-independent clusters, one in each data center, looks more convenient from an operational point of view. Therefore, we often use separate clusters with configured automatic processes for replicating data between static tables in them.
We also learn to replicate dynamic tables — this allows us to implement various replication modes (synchronous, asynchronous) and quorum writing to a set of data centers.
Further scaling of master servers
So, in YT, we learned to shard some of the master server metadata related to chunks. But users in most cases do not work directly with chunks, but with a tree of files, tables, and directories — that is, with Cypress. We still keep this tree in memory of one master server (three with replication), which naturally limits the number of nodes in it to about 100 million. As the number of users grows and clusters expand, we may have to solve the sharding task this piece of metadata.
Integration of static and dynamic tables
In spite of the fact that initially dynamic tables were created “aside” from the MapReduce-model and static tables, quite quickly, the benefits of being able to combine these tools within one calculation became clear.
For example, a long chain of MapReduce calculations can be used to build a static table with an index for a service, and then turn it into a dynamic one with a flick of the wrist, load it into memory, and give the service frontend the ability to take its data with latency, measured in milliseconds.
Or, say, it is possible in the process of performing complex MapReduce calculations to refer to the dynamic table for reference data by performing the so-called map-side join.
The integration of dynamics and statics within the framework of YT is a large and complex project, which is now far from complete, but it allows you to radically simplify and optimize the solution of a number of tasks that are traditionally considered to be complex.
Cloud power
It is not a secret that the so-called search clusters consisting of machines that directly store search index data and respond to user requests constitute a significant part of the Yandex server fleet. The load profile of such machines is very characteristic. If in the case of the main YR MapReduce clusters the bottleneck is almost always CPU (which shows almost 100% load 24/7), then in the search cluster the CPU load changes noticeably - for example, depending on the time of day.
This makes it possible to use the released capacity to perform MapReduce calculations. They are thus partially transferred to the search cloud of dynamically changing sizes. Efficient use of such additional capacity is another priority project for us. For its success, it is necessary to develop a cluster management system, containerization and sharing of common resources between projects (these include memory, CPU, network and disk).
Source: https://habr.com/ru/post/311104/
All Articles