“True, true truth and statistics” or “15 probability distributions for all occasions”
 Statistics comes to our aid in solving many problems, for example: when there is no possibility to build a deterministic model, when there are too many factors, or when we need to evaluate the likelihood of the constructed model taking into account the available data. Attitude towards statistics is ambiguous. There is an opinion that there are three types of lies: lies, impudent lies and statistics. On the other hand, many “users” of statistics believe it too much, not fully understanding how it works: applying, for example, the Student’s test to any data without checking its normality. Such negligence is capable of causing serious mistakes and turning the “fans” of the Student’s test into haters of statistics. Let us try to put the currents above i and figure out which models of random variables should be used to describe certain phenomena and what kind of genetic relationship exists between them.
Statistics comes to our aid in solving many problems, for example: when there is no possibility to build a deterministic model, when there are too many factors, or when we need to evaluate the likelihood of the constructed model taking into account the available data. Attitude towards statistics is ambiguous. There is an opinion that there are three types of lies: lies, impudent lies and statistics. On the other hand, many “users” of statistics believe it too much, not fully understanding how it works: applying, for example, the Student’s test to any data without checking its normality. Such negligence is capable of causing serious mistakes and turning the “fans” of the Student’s test into haters of statistics. Let us try to put the currents above i and figure out which models of random variables should be used to describe certain phenomena and what kind of genetic relationship exists between them.First of all, this material will be of interest to students studying probability theory and statistics, although “mature” specialists will be able to use it as a reference book. In one of the following papers, I will show an example of using statistics to build a test assessing the significance of indicators of stock trading strategies.
The paper will consider discrete distributions :
as well as continuous distributions :
- Gauss (normal) ;
- chi-square ;
- Student's tutorial ;
- Fisher ;
- Cauchy ;
- exponential (exponential) and Laplace (double exponential, double exponential) ;
- Weibull ;
- gamma (Erlang) ;
- beta .
At the end of the article will be asked a question for reflection. I will present my thoughts on this in the next article.
')
Some of the cited continuous distributions are special cases of the Pearson distribution .
Discrete distributions
Discrete distributions are used to describe events with non-differentiable characteristics defined at isolated points. Simply put, for events whose outcome can be assigned to a certain discrete category: success or failure, an integer (for example, playing roulette, dice), heads or tails, etc.
Describes the discrete distribution of the probability of occurrence of each of the possible outcomes of the event. As for any distribution (including continuous) for discrete events, the notions of expectation and variance are defined. However, it should be understood that the expectation for a discrete random event is in general unrealizable as the outcome of a single random event, but rather as a quantity to which the arithmetic average of the outcomes of events will tend when their number increases.
In the simulation of discrete random events, combinatorics plays an important role, since the probability of the outcome of an event can be defined as the ratio of the number of combinations giving the desired outcome to the total number of combinations. For example: in the basket are 3 white balls and 7 black ones. When we choose 1 ball from the basket, we can do it in 10 different ways (total number of combinations), but only 3 options for which the white ball will be chosen (3 combinations giving the desired outcome). Thus, the probability of choosing a white ball:
Samples with and without return should also be distinguished. For example, to describe the probability of choosing two white balls, it is important to determine whether the first ball will be returned to the basket. If not, then we are dealing with a sample without return ( hypergeometric distribution ) and the probability will be as follows:
upstairs
Bernoulli distribution

(taken from here )
If we formalize the basket example as follows: let the outcome of the event can take one of two values 0 or 1 with probabilities
According to the established tradition, the outcome with a value of 1 is called “success”, and the outcome with a value of 0 is called “failure”. Obviously, getting the outcome "success or failure" comes with a probability
The expectation and variance of the Bernoulli distribution:
upstairs
Binomial distribution

(taken from here )
amount
Where
In other words, the binomial distribution describes the sum of
Expectation and variance:
Binomial distribution is valid only for the sample with the return, that is, when the probability of success remains constant for the entire series of tests.
If values
upstairs
Geometric distribution
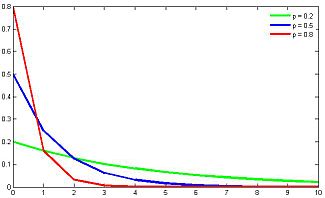
(taken from here )
Imagine the situation that we pull the balls out of the basket and return them until the white ball is pulled out. The number of such operations is described by a geometric distribution. In other words: the geometric distribution describes the number of tests
The expectation and variance of the geometric distribution:
The geometrical distribution is genetically related to the exponential distribution, which describes a continuous random variable: the time before an event occurs, with a constant intensity of events. Geometric distribution is also a special case of a negative binomial distribution .
upstairs
Pascal distribution (negative binomial distribution)

(taken from here )
The distribution of Pascal is a generalization of the geometric distribution: describes the distribution of the number of failures
Where
The expectation and variance of the negative binomial distribution:
The sum of independent random variables distributed by Pascal is also distributed by Pascal: let
upstairs
Hypergeometric distribution
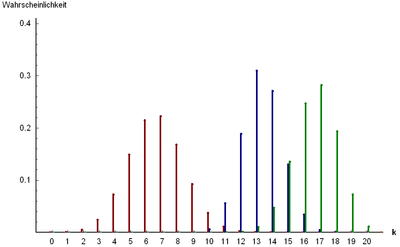
(taken from here )
So far, we have considered examples of samples with a return, that is, the probability of outcome did not change from trial to trial.
Now consider the situation without returning and describe the probability of the number of successful samples from the aggregate with a previously known number of successes and failures (a known number of white and black balls in the basket, trump cards in the deck, defective parts in the game, etc.).
Let the total population contain
Where
Expectation and variance:
upstairs
Poisson distribution
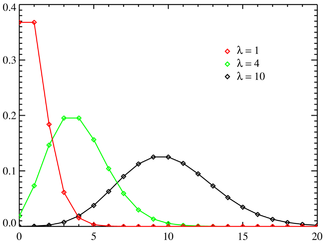
(taken from here )
The Poisson distribution differs significantly from the distributions discussed above by its “subject” area: now it is not the likelihood of one or another test outcome that is considered, but the intensity of events, that is, the average number of events per unit of time.
Poisson distribution describes the probability of occurrence
The expectation and variance of the Poisson distribution:
The variance and the expectation of the Poisson distribution are identically equal.
The Poisson distribution , combined with the exponential distribution describing the time intervals between the onset of independent events, form the mathematical basis of the theory of reliability.
upstairs
Continuous distribution
Continuous distributions, as opposed to discrete ones, are described by probability density functions (distributions)
If the probability density is known for
subject to uniqueness and differentiability
Probability density
If the distribution of the sum of random variables belongs to the same distribution as the terms, such a distribution is called infinitely divisible. Examples of infinitely divisible distributions: normal , chi-square , gamma , Cauchy distribution .
Probability density
Some of the distributions below are special cases of the Pearson distribution, which, in turn, is a solution to the equation:
Where
The distributions that will be discussed in this section have close relationships with each other. These relationships are expressed in the fact that some distributions are special cases of other distributions, or they describe transformations of random variables that have other distributions.
The diagram below shows the relationship between some of the continuous distributions that will be considered in this paper. In the diagram, solid arrows show the transformation of random variables (the beginning of the arrow indicates the initial distribution, the end of the arrow indicates the resultant), and the dotted one shows the generalization ratio (the beginning of the arrow indicates the distribution, which is a special case of the one pointed to by the end of the arrow). For particular cases of the Pearson distribution over the dotted arrows, the corresponding type of Pearson distribution is indicated.
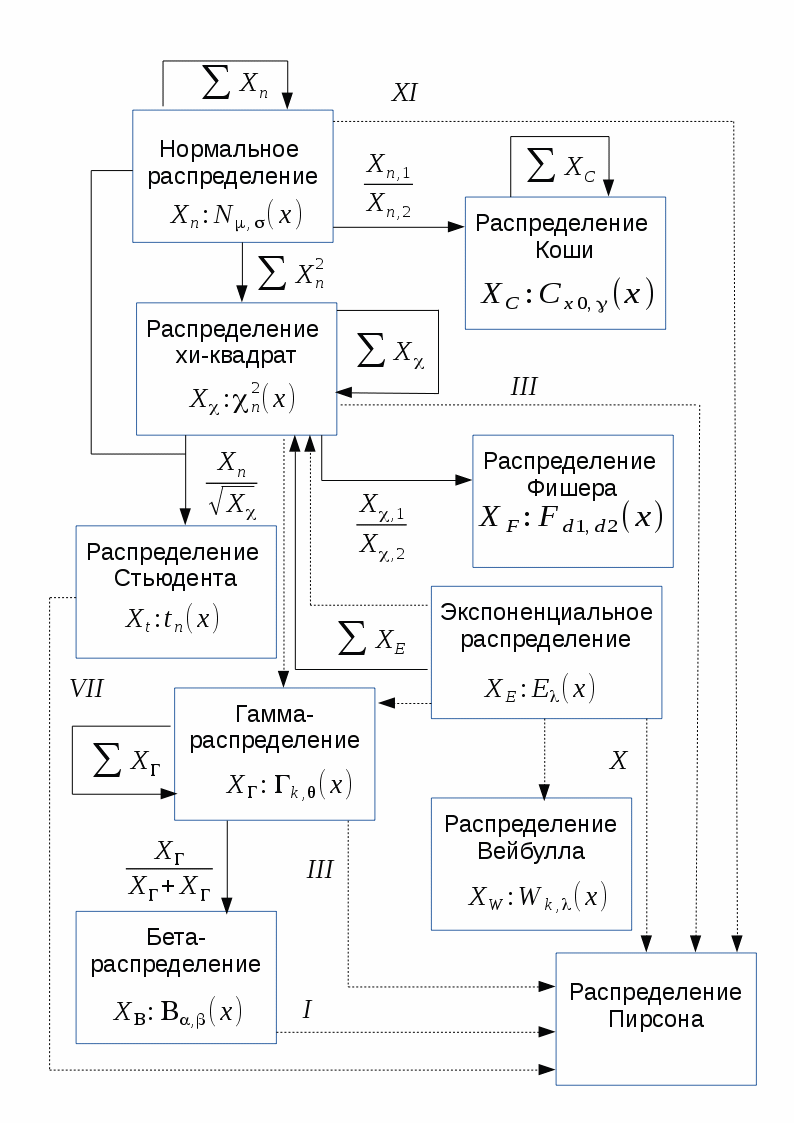
The following overview of distributions covers many cases that occur in data analysis and process modeling, although, of course, it does not contain absolutely all of the distributions known to science.
upstairs
Normal distribution (Gaussian distribution)
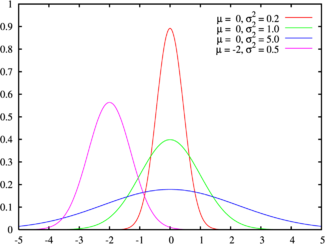
(taken from here )
Probability density of normal distribution
If a
The expectation and variance of the normal distribution:
The domain of definition of a normal distribution is the set of valid numbers.
The normal distribution is the Pearson Type VI distribution.
The sum of squares of independent normal quantities has a chi-squared distribution , and the ratio of independent Gaussian quantities is distributed along Cauchy .
Normal distribution is infinitely divisible: the sum of normally distributed values
The normal distribution well models the values describing natural phenomena, the noise of a thermodynamic nature and measurement errors.
In addition, according to the central limit theorem, the sum of a large number of independent terms of the same order converges to the normal distribution, regardless of the distributions of the terms. Due to this property, the normal distribution is popular in statistical analysis, many statistical tests are calculated on normally distributed data.
The z-test is based on the infinite divisibility of the normal distribution. This test is used to test the equality of the expectation of a sample of normally distributed values to a certain value. The value of the variance must be known . If the variance value is unknown and is calculated on the basis of the analyzed sample, then a t-test is used based on the student's distribution .
Suppose we have a sample of n independent normally distributed quantities
Due to the widespread distribution of the Gauss, many researchers who do not know the statistics very well forget to check the data for normality, or estimate the distribution density graph “by the eye”, blindly thinking that they are dealing with Gaussian data. Accordingly, boldly applying tests designed for normal distribution and getting completely incorrect results. Probably, from here the rumor about statistics as the most terrible kind of lie went.
Consider an example: we need to measure the resistance of a set of resistors of a certain value. Resistance is of a physical nature, it is logical to assume that the distribution of resistance deviations from the nominal will be normal. Measured, we obtain a bell-shaped probability density function for measured values with a mode in the vicinity of the resistors nominal value. Is this a normal distribution? If yes, then we will search for defective resistors using Student's test , or z-test, if we know the distribution variance in advance. I think that many will do just that.
But let's take a closer look at the resistance measurement technology: resistance is defined as the ratio of the applied voltage to the flowing current. We measured current and voltage with instruments, which, in turn, have normally distributed errors. That is, the measured values of current and voltage are normally distributed random variables with expected values corresponding to the true values of the measured values. This means that the obtained resistance values are distributed in Cauchy , and not in Gauss.
The Cauchy distribution only resembles a seemingly normal distribution, but has heavier tails. So the proposed tests are inappropriate. We need to build a test based on the Cauchy distribution or calculate the square of resistance, which in this case will have a Fisher distribution with parameters (1, 1).
to the scheme
upstairs
Chi-square distribution

(taken from here )
Distribution
Where
Distribution expectation and variance
The domain is the set of non-negative natural numbers.
On distribution
Suppose we have a sample of some random variable
Will give
Where
Derived values
Comparing the value
to the scheme
upstairs
Student's t-distribution (t-distribution)

( )
t-: , ( f- ). , - .
T- z- , .
:
Where
:
at
upstairs
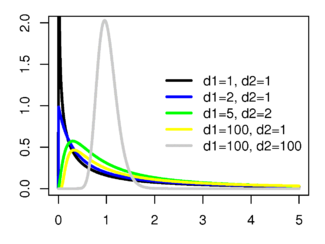
(taken from here )
Let be
Fisher distribution is defined for valid non-negative arguments and has a probability density:
The expectation and variance of the Fisher distribution:
The expectation is defined for
, , (f-, ).
F-:
upstairs
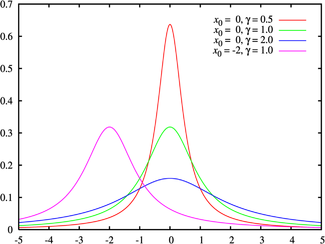
(taken from here )
The Cauchy distribution describes the ratio of two normally distributed random variables. Unlike other distributions, the expectation and variance are not defined for the Cauchy distribution. The shift
The Cauchy distribution is infinitely divisible: the sum of independent random variables distributed over Cauchy is also distributed along Cauchy.
to the scheme
upstairs
Exponential (exponential) distribution and Laplace distribution (double exponential, double exponential)
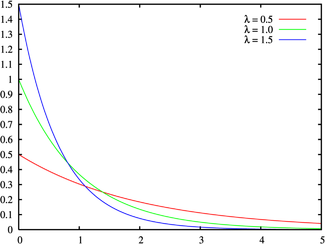
(taken from here ) The
exponential distribution describes the time intervals between independent events occurring with an average intensity
, , , , — , .
- ( n=2), , - . - - 2- , .
, .
— .
:
:
, ,

( )
, , «» . , , .
Where
:
, , , , , , ..
upstairs

(taken from here )
Weibull distribution is described by a probability density function of the following form:
Where
, — . , , , ..
:
Where
upstairs
- ( )
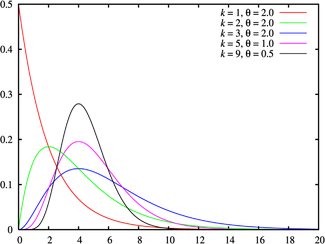
(taken from here )
The gamma distribution is a generalization of the chi-squared distribution and, accordingly, the exponential distribution . The sums of squares of normally distributed quantities , as well as the sums of quantities distributed over chi-square and exponentially distributed, will have a gamma distribution.
The gamma distribution is a Pearson Type III distribution . The domain of the gamma distribution is natural non-negative numbers.
Gamma distribution is determined by two non-negative parameters.
Gamma distribution is infinitely divisible: if magnitudes
Where
Expectation and variance:
Gamma distribution is widely used to model complex flows of events, the sums of time intervals between events, in economics, queuing theory, in logistics, describes the life expectancy in medicine. It is a kind of analogue of the discrete negative binomial distribution .
to the scheme
upstairs
Beta distribution

(taken from here )
The beta distribution describes the fraction of the sum of two terms that falls on each of them, if the terms are random variables that have a gamma distribution . That is, if the quantities
Obviously, the domain of the beta distribution
where are the parameters
Expectation and variance:
to the scheme
upstairs
Instead of conclusion
We reviewed 15 probability distributions, which, in my opinion, cover most of the most popular statistical applications.
Finally, a small homework: to assess the reliability of exchange trading systems, use such an indicator as the profit factor. Profit factor is calculated as the ratio of total income to total loss. Obviously, for a revenue-generating system, the profit factor is greater than one, and the higher its value, the more reliable the system.
Question: what is the distribution of the profit factor?
I will present my thoughts on this in the next article.
PS If you want to refer to the numbered formulas from this article, you can use the following link: link_on_statyu #x_y_z, where (xyz) is the number of the formula to which you refer.
Source: https://habr.com/ru/post/311092/
All Articles