Fast rendering with DOM template engines
Boris Kaplunovsky ( BSKaplou )

I worked on the report for quite a while and tried to make it as controversial as possible. And I will immediately begin with a contradiction - I fundamentally disagree with the fact that web components can be used. The question of 300 KB has already been raised, I’m deeply convinced that 300 KB for the Javascripta page is unacceptable.
Today I will talk about a rather deep journey to the frontend. This journey began when I discovered that the frontend aviasales.ru was slow, and I had to do something. This journey began a year and a half or two years ago, and the things I will talk about are a concise narration of what I learned.
')
The most critical, in my opinion, in front-end application performance is rendering. We all know that working with the DOM is such a thing that you should try to avoid. The more calls you make to the DOM API, the slower your application will run.

What exactly will we talk about? About the rules of the game. What things in the rendering, in the work of the web application you need to pay attention to, what parameters are key for the template library for rendering, what are the types of templating tools.
Then I will walk a little bit over the bones of the giants, this is AngularJS and ReactJS, I will try to tell you what I do not like, and why they slow down. I’ll tell you what I found good in other template engines and about the product that we created based on all the above knowledge.
Probably, part of the audience is interested in what the diver at the bottom of the screen means? Our development team is in Thailand, and I personally dive. Such an analogy was born in my head: if you are under water, then the less movements you make, the more oxygen you save, the more you will be able to swim. With DOM, we see about the same thing - the fewer DOM calls you make, the more likely it is that the user will not experience brakes.

Let's start about the rules of the game. User experience depends on page initialization speed. We are all deeply involved in caching pages, but have to immediately declare in contradiction that caching does not work. It does not work, because the first contact with the site of a person is the most critical. If the site slows down when it is first loaded, the user may not return to the second time. Initial page loading is extremely important.
The second important thing is the speed of the interface response. If a person has pressed a button or checkbox, and the interface has not responded instantly, the user can close the site and go to another site, where the interface is responsive.
The next thing is resource consumption. Two main indicators are important on web pages: processor consumption (if you do a lot of unnecessary actions, you warm the processor, and it doesn’t have enough time to shortcut the animation on the interface or just draw something), besides, if you create a lot extra objects, this puts a load on the garbage collector. If you create a load on the garbage collector, then periodically it will be called, and the responsiveness of your application will fall.
And the last but no less important point. The size of the library. If you have a single page application, then 200-300, sometimes even 400 Kb javascript you can afford. However, the component web, in the direction of which we are moving fun, implies that the pages are built from different web components. Moreover, these web components are often produced in different companies and come with their own package.
Imagine a page on which dozens of widgets are inserted: a widget for currency rates, weather, air tickets, a damn stupa of what ... And each of these components weighs 300 KB, and that’s just JS. Thus, we easily get a page that weighs 5-10 MB. Everything would be fine, and the Internet is getting faster and faster, but mobile devices have appeared, slow networks have appeared, and if you use the Internet not in the city of Moscow, but somewhere in Yekaterinburg, then a 15 MB site will turn out to be an absolutely unacceptable for you. That is why the size of the library, in my opinion, is critical.
Below, I compare several libraries, and do not compare polymers, I do not compare for the reason that 200 KB for a library of web components is too much.

So, let's move on to the topic of conversation - to template engines.
All of us who are engaged in the development of the web, have become accustomed to the string templating. String template engines are template engines that return a string to us as a result of their work. The string that we later insert with innerHTML into html. This is a wonderful, ancient, familiar mechanism. However, it has several disadvantages. The main drawback is that every time you make a template and insert into innerHTML, you have to throw out the whole DOM that was there before and insert the new DOM.
As I recall, working with the DOM is very, very slow. If you have thrown out 20 tags with 30 attributes and inserted the same, same 20 tags with 10 attributes, then it will take considerable time. 20 milliseconds easily. In addition, string template engines do not allow to leave anchors for quick updates of single attributes, single text nodes, etc.
Having discovered these non-optimalities, we began to look, how can we get rid of these shortcomings, what can we do about it? And the first thing that Goggle suggested was “Use the DOM API”. This thing is not very simple. But she has advantages.

This is a screenshot from jsperf. A benchmark that sees the performance of string templating engines that insert html chunks from innerHTML and DOM JS. Here we see at the top of the performance on Android, and we see that the JSDOM API allows us to speed up rendering several times. Here about three times. At the same time, there is no hellish performance boost on desktop browsers.
About half a year ago, Google began to promise mobile web developers to mobile developers. This means that all sites that are not adapted for mobile devices, responsive, adaptive, will be pessimized in search results. This means that if you are not ready for mobile devices, just the traffic from Google on your sites will significantly decrease.
In fact, this slide clearly says that using the DOM API, you can significantly speed up the rendering on mobile devices. And this applies not only to Android'am. As you know, all modern Androids and IOS devices use the same WebKit engine, with about one set of optimization, which means you will get the same performance gain on all IOS devices if you render pages through the DOM API.

However, the DOM API is a rather cumbersome thing. Here I gave five main calls that can be used to create DOM sections. I brought them about in the form in which they will appear in the code of your program if you create DOM sections directly through the API.
Creating one element that you used to fit into 15-17, maybe 30-50 characters, through the DOM API you can easily get 5-10 lines of code. The programmers work time is valuable, which means that we cannot replace html with manual DOM programming.

This is where we need template engines. As you remember, string template engines are slow, and I want to have DOM template engines, template engines working through the DOM API, but allowing you to use all the buns that we are used to when working with regular template engines.
So, what do the DOM template engines give us, besides the possibility not to use the native JSDOM API? They allow you to save DOM objects in variables for quick update later. Using DOM template engines, you can use the same DOM section several times.
What I mean? Suppose we visit a web store page. Users enter one category of goods, and data on a single list of goods are inserted into the prepared templates. When a person goes into another category of goods, other data is substituted into the same templates. In essence, we are not recreating the DOM, we are using the same portions of the DOM to display the data. This allows you to save a lot on CPU resources, and on memory, and sometimes programmers.
After realizing this idea that the tool I need is DOM template engines, we went to see what already exists in the industry, what can you use to quickly and efficiently work with the DOM, and quickly render it?
Then I will tell you where, in my opinion, the giants have stumbled.

The first giant I want to talk about is AngularJS.
AngularJS, it seems to me, stumbled right at the very start. If you used it, you probably noticed that all templates are transmitted to the client as either DOM plots (which is not a very good style) or as strings. After the library has loaded, Angular has to compile your strings or DOM into real templates. This happens on the client.
Imagine an interesting situation. The user enters the page, loads the entire JS, which for Angular applications can be quite a lot - 100-200-300 Kbytes easily. After that, each pattern with string parsing starts to compile. This leads to just one thing - the initial download of Angular applications may take half a second, a second, during this compilation (during which users do anything but work with the site). I met sites on which the template compilation process took even two seconds. Moreover, this problem is growing like a snowball: the more templates in your application, the more complicated your single page application, the more time we spend on the initial compilation of templates.
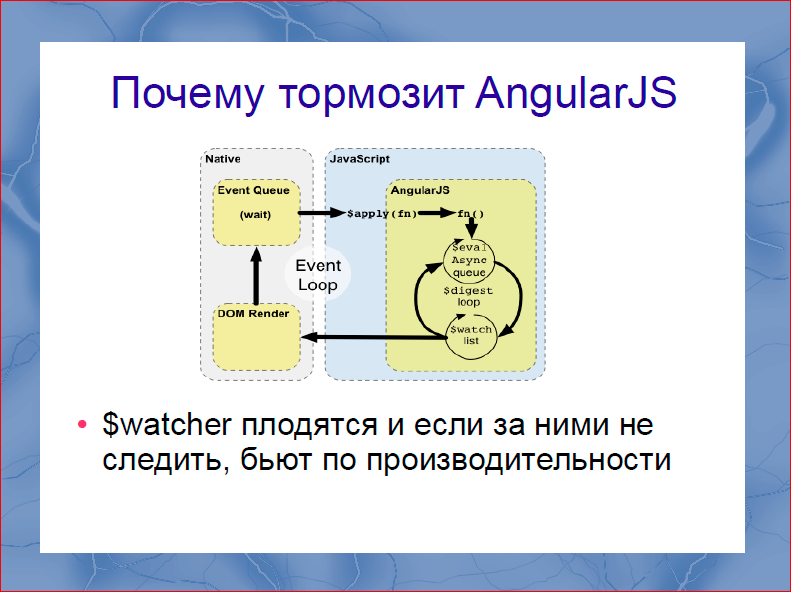
The next problem is in Angular. We all remember that Angular was sold to us by the gentlemen from Google, as the first coolest framework with bilateral binding. Moreover, this bilateral binding is realized through the so-called. $ watchers that you put on data structures for later display in the DOM. The slide is an interesting picture, but you are not looking at it. Only this wonderful cycle is interesting in it, in which all $ watch'i are managed, on all the data that you have in the system. And, of course, in the documentation and in all tutorials, no one will tell you that you need to follow $ watcher. It literally leads to the following. At some point, your wonderful application starts braking well every 100 ms. Begin to slow down the animation, memory begins to flow. It turns out that it is simply impossible to allow a lot of $ watchers. As soon as you allow a lot of $ watchers, your application starts to slow down spontaneously. Here you begin to tricky to tinker, go for anything, reduce the amount of $ watchers, refuse to apply bilateral binding for which you took Angular, only to get rid of the brakes.

In addition, it seems to me that Angular’s architectural blunder is that in Angular there is no one correctly described way to work with the DOM. Directives are virtually independent, each of them working with the DOM as it sees fit. And it turns out that by going through the Angular directives, we can mark some directives as fast, some as slow, and some directives as very slow.
If you used ng-repeat, then you probably saw that if you stuff 100 elements into it, and there are still $ watchers, then it will all be rendered for a very long time. The problem is so wide that working with Angular (our previous version of the output was built on Angular), we came to write our ng-repeat. This was done by our employee Anton Pleshivtsev and told about this at a variety of conferences. In addition, 50 Kbytes of minimized library size, in my opinion, is still a bit too much. Those. what do you pay for? If you look at the Angular code, then in these 50 Kbytes is its own class system, there is a very poor quality, in my opinion, Underscore version. And this is all you get for free as part of the 50-kilobyte code.

Following. A much better framework, in my opinion, is ReactJS. Judging by the way the Internet is boiling up, every first programmer, not even always a front-end programmer, used Angular and was delighted with it. I do not think that virtualDOM can speed up work with DOM.
See what virtualDOM offers us. VirtualDOM is the source from which ReactJS creates the real DOM, i.e. besides the real DOM, from the creation of which you will not get anywhere (virtualDOM only allows you to create it), ReactJS still holds virtualDOM in memory, this is called redundancy.
VirtualDOM is somewhat smaller than the current DOM, maybe 5 times. However, in fact, you have to keep two copies of virtualDOM in memory. Those. you hold the real DOM, you hold the reflection of the real DOM in virtualDOM, and besides, every time you are going to make a div in virtualDOM, you make another copy of the DOM. You had one DOM, now you have three of them - well done! Moreover, for every change in data, you create another copy of virtualDOM, this is the third copy, however, you create it from scratch.
This creates a serious load on the garbage collector and on the processor. In addition, in my opinion, the library is still fat - 35 KB. And again, the guys decided to draw their own class system, draw their own lowdash, for some reason they didn’t suit the original one, and they stuffed it all in 35 Kb. In addition, virtualDOM is packed there with a mythical algorithm that supposedly gives tremendous performance.
The next problem virtualDOM and React in particular, is that ReactJS knows nothing about the semantics of your data. Let's see this very simple example.

Here we see two nested <div>, and another <i> tag is nested inside them. To change the value via virtualDOM, the virtualDOM algorithm inside React is forced to compare three tags and one text value. If we know the semantics of the data, it’s enough for us to compare only the text value, simply because the template says that inside one <div> there is always another <div>, inside the next <div> tag <i> ... Why should we compare them every time? This is a real overhead.
In addition, if you programmed to React, then you are familiar with such a thing as a pure-render-mixin. Its essence is to get rid of work with virtualDom. It happens a very interesting situation close to comical. First, gentlemen from Google sold us React as a piece for a couple of years, which with the help of virtualDOM hellishly speeds up work with DOM, and then it turns out that in order to work quickly with DOM, you need to exclude virtualDOM. Well done, well done.
And now something else. I wanted to search - maybe there are libraries on the planet, there are people who have done something better. I did not try to find one library, a silver bullet, but I wanted to peek into things in libraries that could be used either to speed up React or to create my own library. And that's what I found.

I will review two interesting libraries. The first one is RiotJS.
In my opinion, RiotJS is the correct AngularJS, simply because the size of the library is 5 KB. The guys took exactly the same ideas that were in AngularJS, but did not begin to rewrite lowdash, they simply said: “Why? It is already written. ” The guys did not rewrite, reinvent their class system, did not do anything. Got a library of 5 KB. More performance than AngularJS, the ideas are exactly the same. Moreover, the templates used in RiotJS use data semantics, which gives a good performance boost. But the problem remained - the compilation of templates is still happening on the client. This is not very fast, but much better.

The next library that caught my attention is PaperclipJS.
PaperclipJS uses a number of very interesting optimizations. In particular, cloneNode is used to create templates, and then I will show that it gives a big performance boost, but this solution allows PaperclipJS to be more transparent, more understandable for the developer.
But this library also had two drawbacks: it is quite large - 40 Kbytes, this is more than React; and, despite good ideas, development is rather sluggish. This library is already a couple of years old, however, it still has not left the beta stage.
After talking with these libraries and other libraries, having read the html5 guru, I was able to come up with the following list of techniques that allow you to speed up your work with the DOM.

The first thing is VirtualDOM. I searched for its advantages for a long time, and found only one - it allows you to reduce the number of calls to the DOM, thereby raising productivity. However, the overhead to create a copy of the DOM, in my opinion, is still significant. The sophisticated comparison algorithm, which still has a veil of secrecy that is used in React, is not as fast as we are promised. To understand how it works, you spend two days. And all this magic, which was told in blogs, is not there, in my opinion. In addition, virtualDOM sits on the problem that the algorithm knows nothing about the data structure. As long as we do not know anything about the data structure, all our vrypery, all our layout elements, have a negative impact on performance, because the virtualDOM algorithm should participate in their comparison.

Techniques that have been known for a very long time are the use of cloneNode, which I have already talked about within PaperclipJS and DocumentFragment. These two techniques are used to improve performance. Neither one nor the other technique, as far as I know, is used in either AngularJS or ReactJS. However, the screenshot of the benchmark with jsperf clearly shows that this allows you to speed up the work with the DOM, at least three times. Pretty good practice, I strongly advise you to use.

The next technique that lies absolutely on the surface, moreover, is implicitly found even in the React tutorial, this is the creation of DOM sites in advance. What I mean? Suppose a person visits an online store of electronic teapots. Enters the name of the kettle, the name of the company of the kettle that wants to purchase. At this moment, a search request is sent to the server. If your server programmers are fast and lightning fast, then you can get an answer in 20 ms, the user does almost nothing at 20 ms. And at this moment we can create a DOM structure for the data that will be returned from our server. Pretty simple practice. I do not know why it is not widely used. I use it, it turns out very cool.
Total, what happens? We send a request to the server, while we are waiting for a response from the server, we prepare DOM structures for the data that must come to us from the server. When the answer comes to us from the server, in fact, we still need to disassemble it. More often than not, it’s not just accepting Json, but somehow adopting it. If at this point we have already prepared the DOM, then we can spend the 2-3-4 ms that we have for JS to adapt and insert data into the DOM and add data to the page.
I strongly advise you to use this, and this thing is not explicitly supported in the frameworks, but you can create an item by hand when sending a request to the server.
So, having dressed up with all this knowledge, and having found a bit of free time at night and on weekends, I decided to write a small prototype with which we began to work further.

This is temple templator. It is very simple, very small, there are literally less than 2000 lines of code.
What properties does it have?Templates are compiled at the time of assembly into JavaScript code, i.e. No work is done on the client, except for loading JavaScript code. The ability to create DOM chunks is pre-supported right in the library. The library makes it easy and simple to reuse templates. The size of the library, in my opinion, is more than modest in the minimized and gzip form - it is only 700 bytes. Moreover, the thing I like most about it is the fastest DOM update.
Then we will try to sort it out in pieces, how all this is done and works.

The pattern structure is extremely simple and primitive. These are whiskers inside which variables are substituted.

Everything is pretty obvious, no magic. In addition, it supports two designs. This is a forall iteration over the key for loops and if branching. Expressions are not supported. Some time ago, before the appearance of React, the industry was dominated by the opinion that the View and the model should not be in any way interfered. I still believe that this is the right approach, so if you want to use complex expressions, it is better to put it in a separate component. If you remember, there are such pattern Presenter or ViewModel, if you need to prepare the mapping data into the templates, it is better to do it there, and not drag out the expressions into the templates.
Then I will show you how to work with it. I believe that it is not necessary to create a framework for everyone, that the future of the web, and especially the component web, in very small and independent libraries that do not require a change of religion and cutting out all the previous from the program for their integration into them.
How does the work with the templ.

We take a named template from the templa, update the data in it by calling update. And insert it into the DOM. In fact, this is very similar to working with the usual DOM API. After we use the template, we can remove it from the DOM by calling remove. Everything is very simple.

How is early DOM creation done? Suppose we sent a request to the server and we know that a set of teapots should come from the server. At this moment we say the template pool: “Create a cache for 10 dummies”. It is created, and the next time we make the same get call, there will be no real work with the DOM, we will get the already prepared and rendered template. Those.get the template to insert into the DOM instantly.
When is it most convenient to use? Look, we send a request to the server and we have 20 ms, in fact, of course, not 20, most likely it is 200-300 ms, during this time we can cache millions of DOM nodes, i.e. enough time.
The second option is to cache the templates when we expect DOMContentLoaded.
With DOMContentLoaded there is such a problem that a lot of handlers subscribe to this event and as a result, at the moment of arrival of this event, a damn cloud of scripts wakes up, all of which by callback begin processing, and after this event about 100 ms the application sleeps. It deeply believes there is something. To reduce this wait, you can do caching of DOM templates in advance, before this event comes to us.

Fast changes to the DOM. Here I give a simple and clear call, it is very similar to how update is done in React. Everyone remembers the call to setState, the difference is only in the depth of the stack. If you have seen how deep, how many function calls React makes, before you make the target action (and the target action is, rather, just substitute this value in the DOM), then you know that for React this may be the stack depth 50 -60, maybe more.
Every challenge, especially in dynamic languages like javascript, is not completely free. This is not as slow as a DOM call, but still not free. Temple allows you to do this replacement with a stack depth = 2, i.e. in essence, update is called, a function is called from it, which replaces this value. In essence, this is the value function. And with a stack depth of 2, we get the target action. In this case, the update call is recommended when we want to change several values at once. If we want to change one, then it can be even faster - direct calls to property and then this substitution will be done with stack depth = 1, it is physically impossible to quickly.

Reuse patterns. After the user made a search query for the kettles, saw enough of the kettles, and made a new search query, we can return the templates to the pool for further use, in order to reuse them. This is also supported by the framework, such a function pool.release.

Then I will try to sell you this tool using benchmarks. The first benchmark. Below, I always provide a reference to the benchmark, and remember that on jsperf "more" means "better." In this case, red is the Temple, and blue is React. I compare C React, because React is probably the fastest solution, it is 5 times faster than Angular usually. So, what do we see here? The initial initialization in Temple is done 30 percent faster in Chrom, and 10-15 percent in Firefox. What makes this happen? Inside, ultimately, use the same create element, create text, node appendchild. However, in the Temple there is almost never a stack depth greater than two. In fact, we save time solely on calls within the library. Those 35 Kb JavaScript that you download to use React,This difference in productivity is cast to you - long stacks.
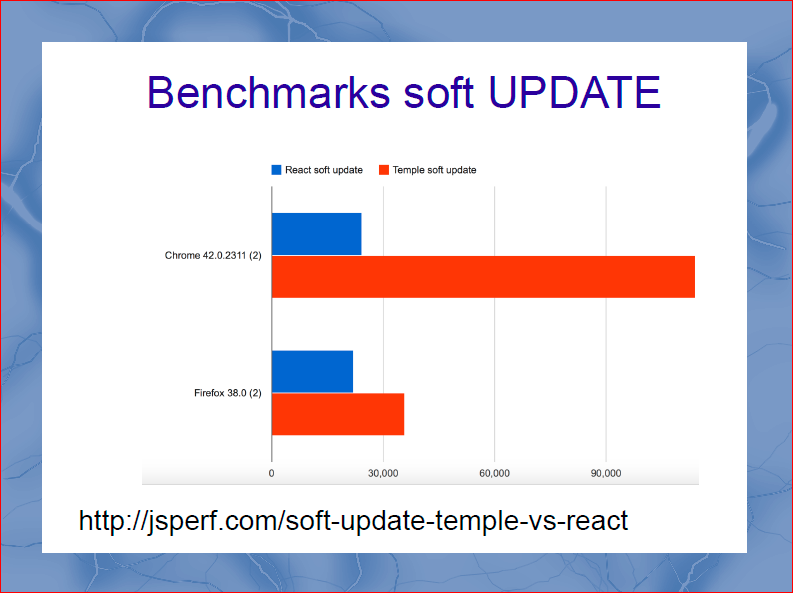
The next benchmark we invented and drove out is soft Update. Soft Update is when we insert the same data into the template that was already inserted there. This is the place where virtualDOM should wake up and say: “Guys, the data is already there, nothing needs to be done”. I have to say that for the purity of experiments on virtualDOM I did not use pure-render-mixin. And it turned out that optimizations in the browser allow you to do this four times faster. VirtualDOM applies the brakes four times.
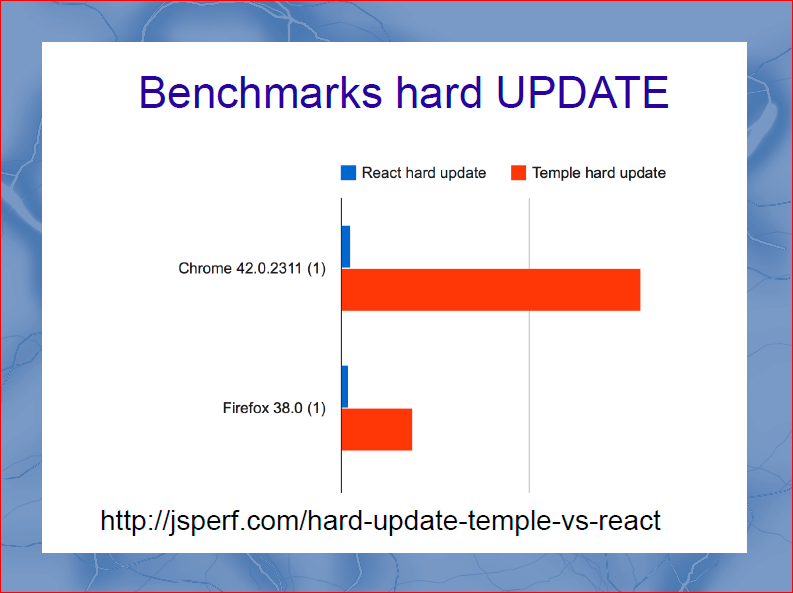
Go ahead, hard update. Hard Update is a scenario in which not one data section is updated in the template, but all the data that is. Again, no pure-render-mixin is used, but it would be useless here. And we get even more interesting data. With hard update, the win of the Temple is dozens of times, simply because there is no virtualDOM.
VirtualDOM turned out to be a very resource-intensive operation in practice. And if you deeply programmed React-applications, then you quickly came up against the fact that working with virtualDOM should be reduced. I have achieved complete perfectionism in this idea, and I believe that virtualDOM, as an idea, is bad and needs to be thrown out. This will make the React lighter KB at 20, and faster every 10.

The temple we did is very small. Aviasales is not Facebook, we don’t have millions of engineering hours, we only have ... As you understand, the development of such libraries is not a great product feature, and it’s impossible to do this during working hours. This can be done at night by a small group of enthusiasts. Therefore, the library is very small. Temple does not offer work with events. React has a DOM delegate, AngularJS has its own work with events. But I do not think that it is necessary to integrate work with events into the template engine. You can use standard libraries to work with events. We use Ftlabs domdelegate. Ftlabs is the IT division of the Financial Times. The guys made a very good, very simple and productive library, its size, if I am not mistaken, is less than 5 Kbytes. We use it in conjunction with the Temple, and we are pleased with the results.

In favor of my previous benchmarks and words, I want to say that at the moment we are already using Temple in two projects: this is the mobile version of aviasales.ru and the new search result aviasales.ru. In the mobile version, all templates are converted to 10 Kbytes of code, we are talking about minimized and compressed code, and the entire application is 58 Kbytes. I think this is a good size for a fairly complex single page application.
The next application we developed was a new search results, the templates already occupy 15 Kbytes, and the entire application takes 70 Kbytes. There were also several widget integrations, but they are less interesting. However, 70 KB for a single page application seems to me a good indicator. Especially when compared with libraries that weigh 200.

Actually, it is open in open source now. You can watch it, play with it by url on the slide. It's still pretty raw.
As he said, we do not have a huge amount of resources to evangelize this our work in order to do the documentation. If you're interested, you can go, there is documentation, there are examples, there are plugins for gulp and grunt and there you can see good performance.
Contacts
» BSKaplou
» bk@aviasales.ru
— - FrontendConf . 2017 , 8 .
HighLoad++ " ". , , ( , ). .
:
- / (.);
- Your hero images need you: Save the day with HTTP2 image loading / Tobias Baldauf (Akamai Technologies);
- The Accelerated Mobile Pages (AMP) Project: What lies ahead? / Paul Bakaus (Google);
Angular 2 / (IPONWEB);
Instant Loading: Building offline-first Progressive Web Apps / Alex Russell (Google);
Source: https://habr.com/ru/post/310868/
All Articles