Modern operating system: what the developer needs to know
Alexander Krizhanovsky ( NatSys Lab. )

We will be interested in the operating system today - its insides, what is happening there ... I would like to share ideas that we are working on now, and a small introduction from here - I will tell you what modern Linux consists of, how can you try it?
In my opinion, a modern OS is a bad thing.

')
The fact is that the picture shows the graphics of the Netmap site (this is a thing that allows you to very quickly capture and send packets of a network adapter), i.e. This picture shows that on a single core with different clock speeds up to 3 GHz Netmap allows 10 Gbps - 14 million packets per second. work out already at 500 MHz. The blue line is pktgen - the fastest that, in general, is in the Linux kernel. This is such a thing — a traffic generator that takes one packet and sends it to the adapter many times, i.e. no copying, no creation of new packages, that is, nothing at all - just sending the same package to the adapter. And here it is so much sags compared to Netmap (what is done in the user-space is shown by the pink line), and it is generally somewhere down there. Accordingly, people who work with very fast network applications are moving to Netmap, Pdpdk, PF_RING - such technologies are the sea now.
The second point is about databases. It was about networks, now about databases. If someone looked into the databases, we know and today we will see that you can use MMAP, you can use O_DIRECT. In large databases - Postgres, MySQL, InnoDB - they mostly use O_DIRECT, and back in 2007 there was a discussion in LKML, and it was said that O_DIRECT is a dirty collection, it is incorrect. If we look at the code of the operating system, at the code of a powerful database, we will see that the database rakes in a large area of memory and manages it itself. She herself holds a pool of pages, working with pages, displaces them, discards, i.e. everything that the operating system does at the level of virtual memory, file system level, etc.
Linux then said that please use madvise to work for you. Peter Zaitsev asked: “But how can we live without O_DIRECT? Because we need to know when what page to drop. " There was no answer, and we continue to live the same way.
The next point is about how we program our applications. If you write multithreaded network daemons, then you usually have a question: “What am I going to use? Will there be processes, events, streams, how many threads there can be started, how to make friends of the state machine so that each stream handles many events, state machines and streams, or maybe use coroutines, like Erlang does? ”And etc. This is a rather complicated question.
There are wonderful articles - “Why Events are A Bad Idea” (Rob von Behren) and “SEDA: An Architecture for Well-Conditioned, Scalable Internet Services” (Matt Welsh), which completely contradict each other. Some say that it is necessary to do everything on threads, that the modern OS works very well with threads, and we can give it as many threads as we want, and it is good to synchronize them and everything will work well. SEDA talks about a heavier architecture, that we are launching a certain number of threads, we redistribute them between certain tasks, there is a rather complicated mechanism for scheduling flows and tasks for these flows.
In general, quite a hemorrhoid issue that needs to be addressed, and, in fact, either we use some kind of streaming framework, for example, Boost.Asio, or we ourselves do everything with our hands and should think about what we need. We need a performance, we have to think about it.
We live in a world where we have a lot of memory allocators, i.e. if we write something simple, then we use malloc or new in C ++ and do not think about how we are doing what happens. As soon as we leave for high loads, we start dragging jemalloc, hoard and other ready-made libraries, or we write our own memory allocators - SLAB, pool, etc. Ie. if we make a server, first we start with a simple program and then we leave to re-implement the OS in user space.

We make a buffer pool for fast I / O, we make our threads, some sort of scheduling, synchronization mechanisms, our own memory allocators, etc.
On the other hand desktop. Yesterday I looked at what I’ve run - I’m running 120 processes, many of them are not even known to me. I love light systems and, in principle, I understand what works for me. If I run KDE or GNOME, then there will be a sea of processes - 200-300, which I don’t even know what it is, what they do. What kind of load they give to the system, I also do not guess, and, in general, it does not matter to me. I type, collect code, in general, I am not interested in the maximum benchmarks in my desktop, I am interested in the maximum benchmarks on my server - where I need to set records.
The second is that the desktops are now rather thin, this is some kind of ordinary single processor, a few cores, a little memory, no NUMA, i.e. everything is very simple, everything is very small. And, nevertheless, we know that we have Linux running on our phones and on large servers. This is not very correct.
If we look at how the progressive world lives ... Maybe, if someone faced with severe DDoS, they know this sign:

This is a data plate from one of the pioneers of building large data centers for filtering traffic, they run on regular Intel hardware without any network accelerators, and people make their own OS. The red color shows what they removed, and they received data that they can take 10 Gbps of traffic from the basic cheap server.
If you just start Linux, then you will not remove anything. Moreover, these people do quite serious filtering at the Application Layer DDoS level. They not only get into IP / TCP - what a regular OS does, but they also parse the HTP, parse it, run some classifier, and they manage to parse one packet in a few CPU cycles - everything is very fast.

If we try to answer why we live with Linux this way, we are happy. Somewhere in the 2000s, Solaris had a strong position, there was a dispute that Solaris is old, heavy, Linux is fast and easy, because it is small — this can also be found on mailing lists. Now we have what Solaris had then - Linux is very large, its code is just enormous, there are a lot of options, it can do a lot of things, everything you want to do, you can do in it. There are other operating systems like OpenBSD, NetBSD, which are much simpler, they are less used, but Linux is a very powerful thing.
I ripped off the picture above from Wikipedia - they tried to portray Linux in some way. We have vertical columns — its subsystems are in its directories in the kernel, and below they went from a higher level to a lower level. Here is a very complicated graph. In fact, if you look at a certain point, for example, at planning input-output at the level of a stack, blue and blue-green, not everything is shown there. Everything is actually more complicated, there are large connections, a lot of different queues, a lot of locks, and all this should work, and it all works slowly.
Let's go over the vertical bars, look at the Linux subsystems, and what can be done with them, where there may be problems. Partly from the point of view of the administrator, partly from the point of view of the developer of the application code.

First, work with processes and threads. Linux has an I / O scheduler, fair, which works in logarithmic time. He is now the default scheduler, before that there was a scheduler that works in constant time. I have never had to get into the scheduler itself in order to optimize, get more performance out of it, that is, how it works there, I know, but I never had to optimize it. There, somehow everything is planned and, probably, it is planned well. Problems usually arise elsewhere.
As I said, desktops and servers are completely different worlds, i.e. if there is a server with one processor, 8 or 16 cores - this is one option. If we have a server with 4 processors, each has 10 cores - we have 40 cores in the system, plus hyper-threading, we have 8 threads. Now the processors have become more massive, there are even more parallel contexts, and the picture is completely different.
First of all, if we talk about threads, about processes, about events, then whatever we choose - threads, processes or state machines - this is all about your convenience.
If you want to write quickly, take some kind of framework and use it, or Vent, or Boost.Asio with a bunch of threads, whatever.
If you need a performance, you need to understand exactly that you have a certain amount of iron, cores, which can do something in a unit of time. If you force one unit to do more than it can, if you give a lot of software streams to one hardware stream, then nothing good will happen. The first Context switch will occur. Context switches are cheap if you have a system call. We have a special optimization in the operating system that if an application process goes into the kernel and immediately comes back, then its caches are not so much washed out, and it does not invalidate the caches. A little leaching occurs, but, in general, we live well. If you start to reschedule application contexts, then everything becomes very bad.
- On modern Intel'ovskih processors, we must disable the level 1 caches, i.e. our most valuable, the fact that we have the smallest and most expensive, that which allows us to work really quickly with slow memory - we lose it. Older caches L2, L3 are simply washed out. If you have several threads running in parallel, several processes, programs that work with a sufficiently large amount of data, and they are rescheduled from you, then it is clear that the memory with which each program or each thread runs is loaded into caches and washes out what did the previous one, the one that gained its caches. And when the reverse switch occurs, when the first program gets control again, it essentially goes to cold caches and starts pulling data from memory, and we have a completely different order of operation time.
- Following. What we do not meet on desktops, on our smartphones is NUMA. Modern X86, previously used to be AMD, now Intel, they have become an asymmetric architecture. The bottom line is that our OS scheduler - and we have different processors - are our different nodes. Each node works with its physical local memory, and if the OS scheduler decides to move from one node, from one processor to move the process to another processor, then everything becomes very bad. We have a memory through slow channels. Fortunately, the OS knows the topology of the kernels on which it works, it tries not to do this, but, nevertheless, sometimes it has to do it, due to some considerations of its own.
- Further. We have slightly changed the mechanism of how we work with shared data. If some years ago we could safely take a spin lock and assume that this is the fastest, i.e. take some small variable, spin in a cycle, expect it in some values on this variable, but now we cannot do that. If our 80 cores are bursting into one byte, into 4 bytes, then the data bus suffers and everything becomes very slow, i.e. we cannot use the synchronization mechanisms we used before.
I strongly advise reading “What Every Programmer Should Know About Memory” (Ulrich Drepper) is a wonderful book, it is a bit old, but the general concepts are very good there, it shows how it works and what you can do.
The first picture - 2008 or 2009 from AMD, when everything began to enter the masses. We have two processors in total. Blue channels are those channels through which two cores communicate, i.e. here we have 2 processors with 2 cores each. Between the two cores, we have a very fast transfer, and between different processors, it is very slow. Accordingly, if we have a 0.3 core - they work with the same lock, with the same int, then they start to drive these 4 bytes through a slow memory channel - this is very slow. If we work with P0 and P1 with the same intovy variables, then we have everything very quickly.
In modern architecture, they approached, probably, they even went further than the picture with 4 processors. If we have a flat structure here - we have 2 processors, fast and slow channels, then we already have a three-dimensional structure, and there are no longer all the cores and do not communicate with everyone. For example, P3 does not communicate with P4, it must do two hops. Those. if we need data in P3 from P4, we first go to P0, and then P0 already goes to P4, i.e. we need to use another processor in our transfer.
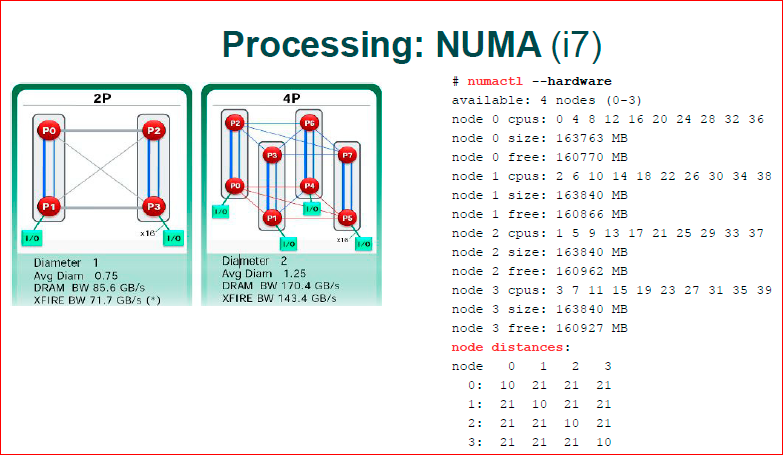
Modern Intel i7 architecture - it has a very serious bus, it has KPI. In fact, there is this infrastructure, core communication and data synchronization. They built their TCP / IP, i.e. there is a multi-level communication protocol, their packets run across the data bus between the processors, there is a rather complicated thing to understand the modern i7, where it has a faster transfer, where it is slower, very hard. Numactl shows node distances. That is, if we look diagonally, this core with itself is some weights, some parrots are the cheapest. In any other knot it is already difficult for him to walk, i.e. there is already a weight of 21 is considered.
Even the utility, which should show you the topology of your hardware, it considers that any kernel you go with has the same price. In fact, this is a bit wrong, but if we work with NUMA, it is easier to assume that everything is fast in a local processor, and slow in an alien processor.

What can we do and what is the right thing to do to make the code work fast? First, spin lock, different data structures, lock-free, which became very popular in the 2010s. Different lock-free queues and stuff does not work on large machines. Recently I was asked that “here we have 20 thousand streams, and their people wanted to write a quick queue that would allow them to quickly insert and collect data. It will not work like this, i.e. everything will be very slow. 20 thousand threads will be cached, they will be ugly to pull atomic instructions, data, and everything will be very slow. Accordingly, if you write code for the NUMA system, you think that you have a small cluster inside your machine, inside one piece of hardware, and you build your software so that you have a small machine, one processor, it is multi-core, there are 8-10 -16 cores, she does something of hers locally and sometimes communicates with strangers. And further, if you merge a cluster of machines, you will have even slower communication. You get such a hierarchy of clusters - a faster cluster and a slower cluster.
A good example of shared data is that it is not good to use shared data when C ++ is shared_ptr, i.e. we have a pointer to the data - these are our smart pointers, and they have a reference counter, which changes each time the pointer is copied, respectively, if you write a busy server, you cannot use shared_ptr.
One of the reasons why a boost donkey there, for example, will never give you good server performance, is that it uses shared_ptr very much, smart pointers and other high-level things that slow down actions a lot, i.e. This high-level object code does not expect that it should work with raw iron as quickly as possible.
Farther. False sharing. Anyway, we in different high-level programming languages operate with one byte, two or four, eight bytes. The processor operates with 64 bytes - this is one cache line of the processor. Those. if your variables are stored in one cache line in 64 bytes, then for the processor it is one variable, and it will do all its algorithms exactly over your two variables. If for some reason you have your two hot variables, for example, two spin locks completely different and ideologically fall into the same cache line, then you have big problems. You have different cores, unwillingly, begin to fight for the same data, although they must work in parallel. And you come to the conclusion that you, in fact, have two locks, but work as one.
Binding processes is just the case for NUMA. Old enough test. There was a machine with 4 processors with 4 cores. First, when we run dd and send it to nc, we have dd running on one core, nc on the other. And at that moment, for some reason, the OS decided so that “we have different processors, it’s better to scatter the applied process on different processors,” and she gave one process to one processor, another to another, and got rather low performance. If we strictly prescribe that both processes must live on the same processor, then the transfer has greatly increased. Those. The OS does not always do good things, it is not always smart things in process planning.
One more thing - we have different servers, i.e. we have desktops that are spinning all over and we don’t know what it is. We have servers on which, maybe, apache, nginx, MySQL, a router or something else, i.e.there are such hodgepodge. But if we build a high-performance cluster, if you look at how large companies are built, as a rule, there is a cluster, there are levels, the first level is there - we have, for example, nginx on 10 machines, and on each machine only nginx and OS . The next level is Apache with some scripts, the next level is MySQL, i.e. we get that one machine is one high-level task. This is a completely different approach, and in this situation, our application, nginx or apache can count on the fact that it owns all the resources, it does not need the virtualization that the OS gives - this is virtual memory, this is the isolation of address spaces, something each program considers that it works with some unknown amount of CPU. We can bind, for example, when we start a web server,we run the workers either equal to the number of cores, or twice as much, i.e. we are based on the number of workers on the number of cores. This is exactly the example that we have one application that fully uses the entire machine.
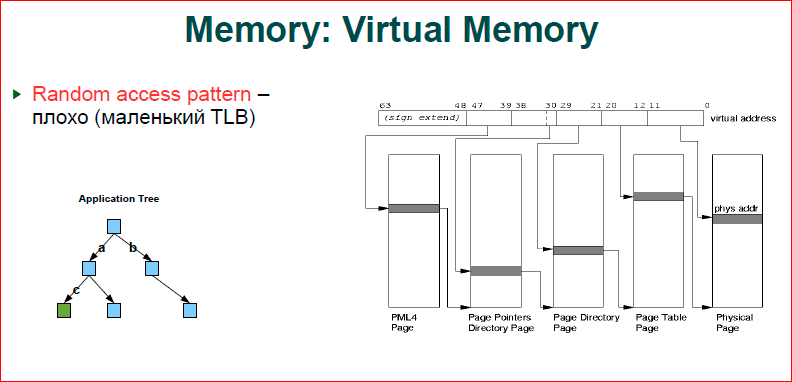
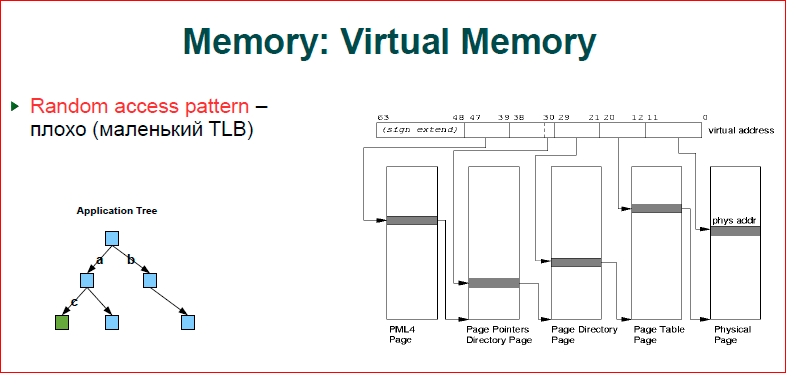
About memory. In short, the more memory you use, the worse you get. If you look at the picture, this is how our virtual memory works. We have an address (this is the ticker above) - from 0 to 63 bits, and when we work in a virtual address space, and we have hardware with a physical address space, we, as always, have a mapping of the virtual address space into a physical one. Accordingly, if two programs work for you, their variable addresses may be the same, but these addresses refer to different physical memory cells. This is the principle of operation of virtual memory. Accordingly, when we have a processor accesses a certain address, we must make a resolution of this virtual address to a physical one.
The page table works like this for us. Page table consists of four levels. We have the first four levels, from where it links from the 39th to the 47th bit - this is the page. This page is a plate, in it the index is the number that is encoded by the bit, we jump to the next level, then we resolve the next part of the bits, etc. Shown here is the flat structure of what is one page, one level refers to the next. It is clear that at the first level, the senior addresses in the program, as a rule, coincide.
The OS when allocating memory chooses lower addresses as close as possible to those that exist, i.e. we get a tree. The first gray ticker will be one, the second may also be one, then at the third level we have two, at the last level we begin to fully use the entire level, i.e. we have such a tree with a root in the main page, and then it branches. Thus, the more memory we spend, the more branchy we get, and, of course, that this should also be stored somewhere, this is also our physical memory. Next, let's see how it all goes and, above all, memory consumption.
The second.Suppose we create some kind of binary tree, we believe that we have blue knots and green knots where we want to go. For us, this tree, for the OS - this is a tree inside the tree, i.e. when we go through the key a - from the first level to the second, we have a transfer on our tree and completely we go through four levels of the tree. Now we jump from the second level to the third - to the next moment. Again, the tree rezolvitsya, i.e. in order to get down from the top of the tree, we will have eight memory transfers - this is a lot.
We, fortunately, have a TLB cache. This is, in fact, a rather small cache, in total about 1000 addresses are placed there, i.e. translation tables we address by pages. 4 Kb pages, 1000 pages - we get 4 MB, i.e. 4 MB is what we have cached in TLB. As soon as your application goes beyond 4 MB, you start running around the tree, and 4 MB for a modern application is, generally speaking, nothing. And you often exit the TLB cache, i.e. the more memory we spend, the more our performance degrades.
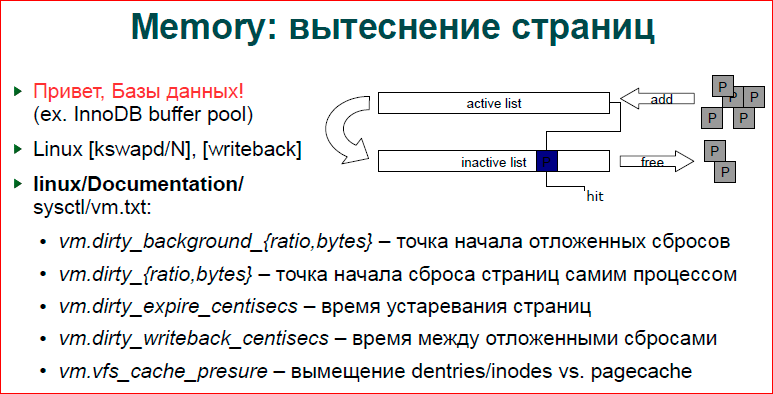
About page crowding. I have already said that our databases do this, and indeed, some of the mechanisms are very similar in databases and in the OS, and Linux keeps a double LRU list, i.e. we have an active list and inactive. Accordingly, the page, when you only do the allocation or do something with the page, is placed in the active list. Then, after some time, it is supplanted in the inactive list. The kswapd daemon, if you make ps, you will see kswapd - one by one per core, they are engaged in this transfer of pages from sheet to sheet. And when the page becomes completely out of date the second time, it is already being forced out of the inactive list, and if it is an anonymous page, for example, some kind of malloc, it goes into the swap. If this file is zamalenny, then the page is simply thrown out, we will go to the file zamaplenny.
Besides the fact that we have an active and inactive list, our page can be dirty and clean. Those.if we only read the page, it is clean. If we have written something down, then it is dirty until it is dumped to secondary storage - this is either a swap, or back to the file recorded. Every time we recorded something in memory, we don’t want to go and dump it all to disk. Obviously, this will slow down the work. But sometimes we need to reset, because if we have a massive load, if we now write everything, we write in memory, and then we don’t drop anything, then we don’t have enough memory. Writing to some one byte of memory comes, and we begin an active reset, pass through these lists, reset it all to disk, and we generally get up.
Accordingly, we have a writeback process, and file systems add their work to this process. And writeback, just, does dump of dirty pages on secondary storages.
We have sysctl variables. I use the documentation inside the kernel for sysctl, I always have a kernel at hand, I look in there, and there is documentation in the kernel where it is well written what each sysctl does.
Accordingly, dirty_background_ {ratio, bytes} is the starting point of the delayed drops, i.e. when our file system decides that we need to put work for writeback, how many bytes we have written, how many dirty bytes we have, or how many percent of dirty pages we get from clean pages, and then we start to reset this data to disk.
dirty_ {ratio, bytes} is when our process writes data and makes a new dirty page, and at this moment it looks at how many dirty pages we already have. If we have a lot of them, then he himself will dump to secondary storage right now, if there are few of them, then he will leave it to work for writeback, i.e. so we try to get away from the situation when we write very intensively, but the writeback stream does not have time to drop everything.
Writeback_centisecs controls how our page goes through the sheets, and how often they are pushed out.
Cache_presure is a compromise between how we push out what data. Those.if it's some kind of file server, then we need a lot of inode and a lot of directory writers. If this is just a database that has dumped a large area of memory, then we do not need inodes. For example, ngnix opens the file and keeps it in its cache, we don’t really need directories there, inodes may be needed, but most likely not, page cache is more important to it.

About large pages. I say that our page tables work with 4 KB pages and, indeed, we get that in TLB we can only address 4 MB, which is not enough. Thus, we have optimization at the kernel level and at the processor level - this is a big page. I honestly do not know how the processor works with it, but the point is that if you allocate a page, we do not have a physical page of 2 MB or 1 GB. Physically, we do not care 4 KB. And when you allocate a large page, you have an operating system, in fact, looking for a continuous block of 4 KB, which will make you this large page. This large page will comprise just one entry of the page table and one entry in the TLB.
The trouble here is that if we have TLBs of the first level for regular pages - this is about 1000 entries, then for large pages - this is probably about 8 for 2 MB, and 1-2 for GB. Proceeding from this, if you have a large database, then you may not fit large pages, and if you write only 1 byte, you have 1 GB allocated to this byte, and it jerks from the file, you will not end up being profitable. If you keep some very intense storage of relatively small data, i.e. not as you raise MySQL to 40 GB of memory, and if you have a small database, literally 1 GB, 2-4 MB, which works very intensively with data structures, then it makes sense to use hugh pages.
The beauty is that Linux 2.6.38 has introduced transparent large pages. For a while, we had to specifically bother with large pages, mount a special file system to work with it, now Linux can do everything on its own. If you specify for your area of memory, do madvise, because you want this area of memory to use large pages, then when you select pages, say in a large mmap, Linux will try to allocate a large page for you. If he cannot allocate, he will roll down to 4 Kb, but he will do everything possible for that. Support for large pages can be viewed at xdpyinfo.

About disk I / O. Here we have three options that can be divided into two large interesting categories: the first is file input-output with copying, the second two is without copying.
The picture shows the normal operation. If we make a normal open, we do a read, write, everything goes through our cache, so-called. page cache. For any ongoing file I / O, there are pages in which data read from a file written to a file is written, and they are dumped into the file using writeback streams using kswapd or, conversely, raised from it. Here we get the copy. If we have a buffer in our application program, we will make from it read or write, then we write data to this buffer, and we write to page cache, i.e. we have a double copy. This is slow, respectively, large databases use O_DIRECT I / O, we pass page cache, we say that we have our large memory area, allocate it with the same mmap and do direct I / O from the disk controller to this area.
The second approach is we do mmap. This means that if in the case of O_DIRECT we do read or write ourselves on certain pages and dump it onto the disk ourselves, then in the case of mmap our OS will somehow somehow reset something, we don’t know when and what she will fold. Accordingly, if we have a transaction log, and we say that this data block must be recorded before another block, we cannot do this, we can only do this in the case of O_DIRECT.
Another interesting thing with mmap. Generally speaking, we have a large address space in X86, there is a temptation, because we have virtual memory, because we can swap 128 TB of memory, and to have only 10 GB is just a map, many files, and somehow work with them. In particular, we tried to do this, because we know that we have page 3, we can zapapit 128 TB, make one mmap, and these 128 TB are a few bits in our address.
Suppose there is a younger bit of some n bits, we do mmap and get an iron tree, which the hardware gives us. Those.we take any address, take the bits as our key that we store, and put them on the bus and get the data in this mmap.
So you can work. In some form, it will work quickly, but the page table grows heavily and caches sag. Thus, the page table is quite an expensive thing, for 128 TB we have 256 GB of page tables, i.e. an order of magnitude less, but the figure is very serious.

About the story. We have input / output scheduling on our storage. The picture shows what is red. Imagine that we have three blocks that are stored in different places on different tracks of our disk, and we throw them in a certain order to the controller. The controller starts to run first on the inner track, then, fortunately, he immediately sees the second block, then he must run a large enough distance to reset the third and fourth. Those.we drive is spinning all the time, if it does not order.
Green shows the optimization mechanism. He will be able to move our head as the disk rotates, it can still move it between tracks and, accordingly, do input-output from different tracks in parallel. And it turns out - in one turn, we manage to do everything. Here we make three turns.
It works just as fast, but there are also I / O schedulers in Linux. Thus, we have a simple scheduler who, in fact, does nothing, just merges requests and relies on what the hardware planner does. It merges requests in order to reduce the CPU time and OS operation for I / O, i.e. big pack immediately give more profitable.
Deadline scheduler is what is recommended for databases, it provides us with a guarantee that after some time our data will be dropped, i.e. they will not live there forever. This is a fairly simple scheduler and it allows databases to understand well how their data will fit on the disk.
There is now CFQ - this is the default scheduler, probably in all distributions, it does complex things, if you have virtualization, different users, it tries not to offend everyone, to balance input-output, to give the same quality service to each user. But for databases, for servers it is not very well suited.

Regarding optimization. There are parameters in sysctl, I have listed here, they can be pulled, in particular, by changing the scheduler, changing the length of its queue. So ... this queue, which we throw on the controller, if it is longer, then the controller and the scheduler will be better able to do its task of reordering, build a queue of requests more optimally. If it is shorter, then, for example, read from disk will be faster, because we do not expect reordering.
Read_ahead is when we read a block from a disk, we also read the following ones there. Here we just have a variable that sets how much we read. In particular, in InnoDB is a more complex mechanism, which is adapted to try to understand how the load is going on and to adapt to prefetching.
If you write your applications, there are a number of system calls that allow you to better control how data is dumped to disk.

Network. We have zero-copy output, unfortunately, we have no zero-copy inputa. Those.if we have an htp server that is in such conditions that it has very intensive input, and it filters it, or you build some kind of user space firewall, then you cannot optimize much.
The second disadvantage of this approach is that two system calls are written in the top of the user space, i.e. for each output you need to call two system calls and make, respectively, more context switches. There is a benchmark, which was made by Jen Saksburg himself, who, in fact, implemented all this. It uses the size of 64 KB. At 64 Kb, acceleration is very strong, 4-5 times. If we reduce the size, for example, to 100 bytes, our zero-copy output will be worse than with copying the entire larger number of system calls.
Another disadvantage is the inconvenience of work. When you take a page, give it to zero-copy, your data page is directly placed in the OS TCP / IP stack. You have given away, and you do not know when TCP will send the data. He can do retransmit, etc., you do not know when it will be possible to reuse this area of memory. Thus, a dual buffer approach is used. If you have, for example, 64 Kb of send TCP buffer, then you make buffer of 128 Kb. And you can be sure that if you recorded 64 KB in the beginning, you went to the second 64 KB, and the socket is not blocked on these second ones, it means that it has already sent something, and you can start using the first part of the buffer . Those.a double buffer ensures that the TCP buffer will be fully protruded before we reuse this data again.
Processing parallelism. In fact, this information is no longer relevant, because modern network adapters are already really cheap and have options with hardware parallelization. Those.if you do grep / proc / interrupts on an ethernet card, then you will see not one interruption for our adapter, but 16, 24, 40, a lot, in general. This is just the queue of this adapter. Those. we can use up to 20-40 interrupts for network processing, so if we put a separate interrupt on each core, then all of our cores will work in parallel.
There is a software implementation of RPS, i.e. if your adapter has only one queue, then you can use the software implementation, and already the OS, having one interrupt, decides on which kernel to process this packet. The advantages of a software implementation are that a good hash is read there, i.e. hardware implementation considers hash from destination and send IP addresses, two TCP ports, plus TCP, IGP, etc. application protocol. This five is used as a hash for selecting a kernel. In theory, it should be so, but, apparently, by default the adapter uses a rather bad hash function, and if you have enough cores, you made a lot of queues, then you will often see uneven core load. RPS, on the other hand, uses fairly good hash functions and allows you to better distribute traffic.

Offloading. If you can use Jumbo frames, use them, because the OS has to work much less. Processing each packet by the power of the stack is very expensive, and GRO and GSO help solve this problem in a slightly different way. If your application generates different packets, for example, 64 bytes each, then the OS will collect all your packets into one big chain and give this chain to the adapter at once, and the adapter will spit it out at once. As a rule, GSO, GRO operates with 64 Kb, and in principle, you can expect that if your application generates data in small pieces, then at high speeds the OS will collect it and will work with 64 Kb segments. Another thing is that these are not real packages, as is the case with Jumbo frames, but these are segments that some OS paths go much faster due to the fact that this is an assembled chain.
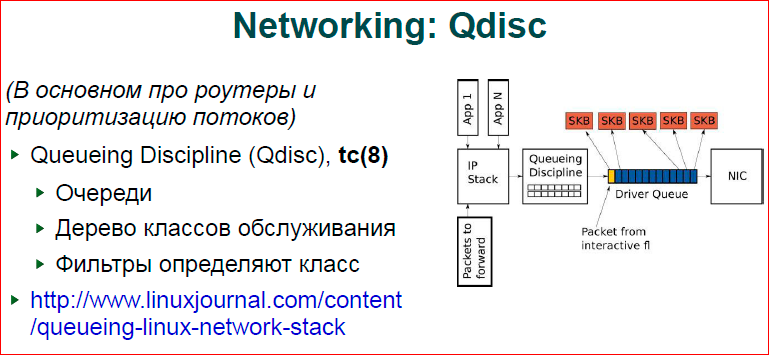
About Qdisc - this is more for routers. If you build a complex system on Linux, for example, you have a router, and you need to give a certain band to all wi-fi users, and let some users have more quality of service. You can build several disciplines of queues, each discipline to define parameters, how you define, for example, a pool of IP addresses, a network mask — this will have one discipline with one quality of service, other addresses with a different quality of service, etc. In particular, it solves the problem well. If you have any data, for example, torrents (blue packets in the picture) - massive data processing, and the yellow one packet is your skype, your voice, you cannot wait for a long time until your packet with voice passes the entire chain along with torrent.Qdisc allows you to assign a higher priority and push through a packet earlier than lower priority. There is a good article in the livejournal on these disciplines -www.linuxjournal.com/content/queueing-linux-network-stack .

I included sysctl in the presentation simply because it should be. In general, any article on the same habr on how to optimize nginx, will surely say that there are such sysctl, they can be found everywhere, and we can do it.
Contacts
» Ak@natsys-lab.com
» NatSys Lab's blog.
This report is a transcript of one of the best speeches at the training conference for developers of high-load systems HighLoad ++ Junior . Now we are actively preparing for the conference in 2016 - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
This year, Alexander Krizhanovsky will continue our excursion into the insides of the operating system (in general, Alexander is one of the most serious specialists in Russia in this area) - " Linux Kernel Extension for Databases ".
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/310848/
All Articles