BGP protocol in Quagga
In the previous article, I described the general architecture of Quagga and the device of the routing table, which is located in the zebra daemon. In this article I want to talk about the device of the bgpd daemon responsible for implementing the BGP protocol.
I will not describe general BGP information. There are a lot of good articles and books about him, and you can get acquainted with the logic of his work, for example, here . I will focus on the mechanism for its implementation in the bgpd daemon. For convenience, the bgpd daemon job description can be divided into two parts.
The first part is called the BGP table (similar to the routing table). All known BGP routes with their attributes are stored here, comparisons are made of various BGP routes and the best ones are selected.
The second part is called strapping. A binding is a set of settings that affect which routes fall into the BGP table, which routes will be announced to neighbors, how attributes of BGP routes change, etc. Those. these are various distribute-list, prefix-list, route-map, redistribute, and so on.
')
The BGP table is very similar in its structure to the zebra routing table. Similarly, each prefix corresponds to several different routes received from different sources. Only instead of administrative distance and metrics, various BGP attributes are used, as shown in the figure.
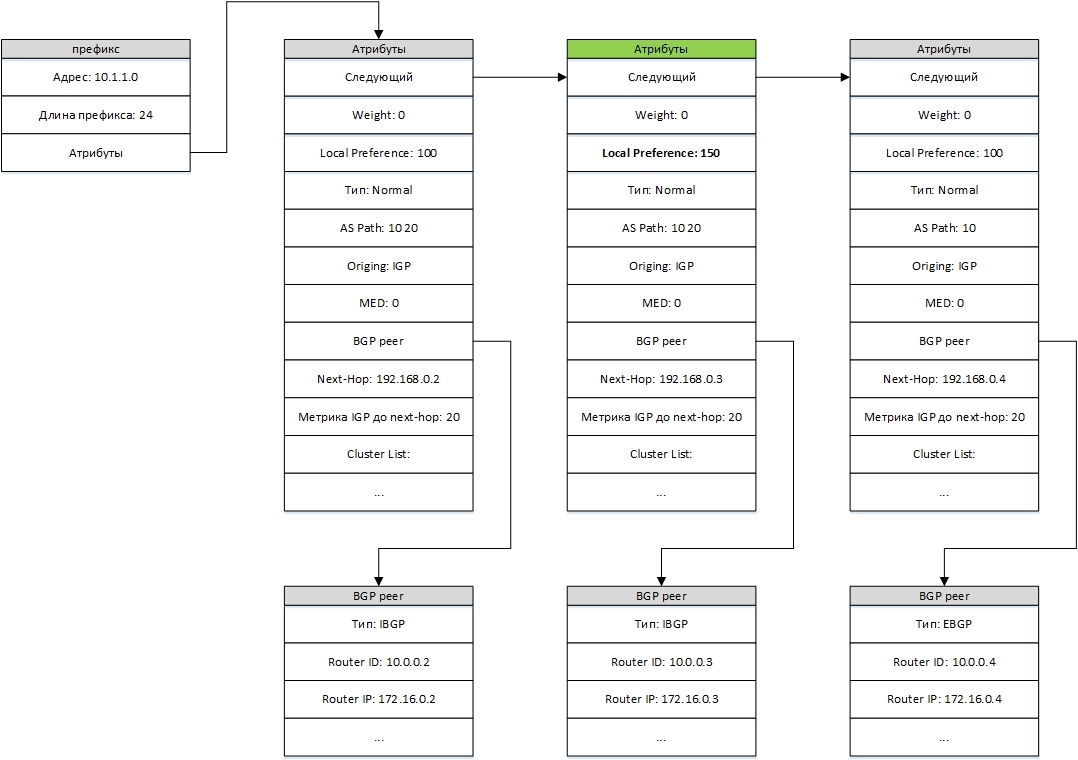
Only attributes affecting the selection of the best route are shown here. For example, the community attribute does not directly affect the choice of the best route and is not shown in the figure.
Also, each route has a pointer to a BGP neighbor (BGP Peer) from which the route was obtained, which allows the use of relevant data about the neighbor, namely: neighbor type (IBGP or EBGP), its router-id and ip-address. Upon receipt or deletion of the next route, a procedure is launched that, using successive pairwise comparison of routes, selects the best one for the given prefix.
Of the two routes, the best one is (which criteria are listed in order of decreasing priority):
1. Greater Weight.
2. Greater Local Preference.
3. The route is created locally (using the network, redistribute or aggregate-address command).
4. Shorter AS-PATH.
5. Smaller Origin (IGP <EGP <INCOMPLETE)
6. Smaller MED value.
7. The type of neighbor from which the route is received (eBGP is better than iBGP)
8. The smaller IGP metric to the next-hop specified in the route.
9. If both eBGP routes are used, the previously selected as the best (i.e., older) route is preferred.
10. Smaller Router-ID Neighbor.
11. Shorter Cluster list.
12. Lower neighbor IP address.
In the example above, the route marked in green is the best because it has the largest Local Preference.
If any of the routes match the first 8 points with the best route, they (when setting maximum-paths greater than 1) are remembered and can then be processed and transferred to zebra as a multi-path route.
Just like in zebra, all the prefixes used in the BGP table are organized as a prefix tree, and the same algorithm is used to quickly find the desired prefix.
The binding around the BGP table is shown in the figure.
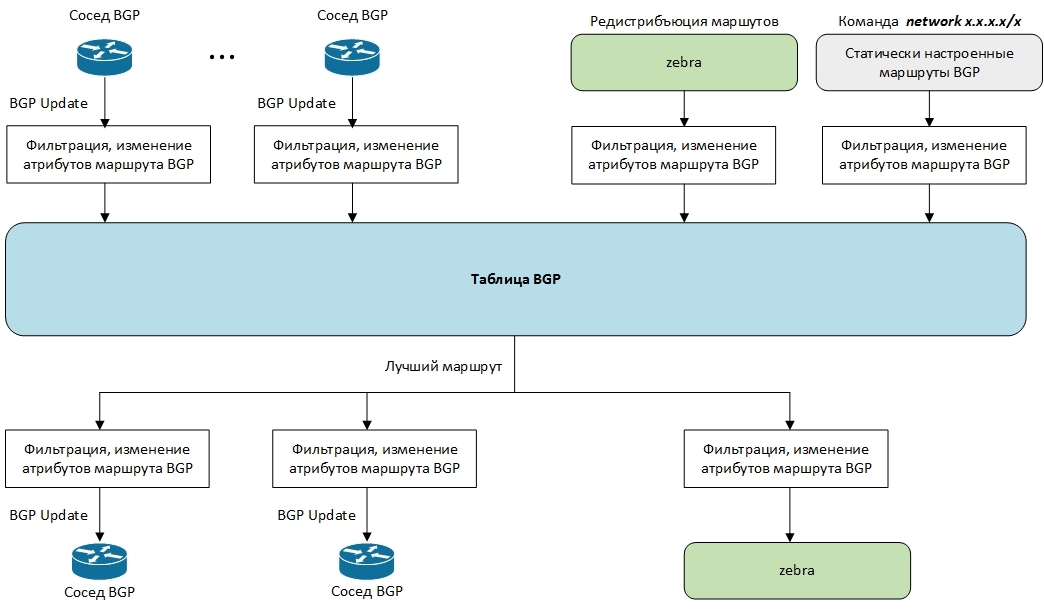
BGP routes can come either from BGP neighbors or be created locally. Before entering the BGP table, they pass a series of checks and their attributes can be filtered or changed. After choosing the best route, this route is sent to neighbors and enters the zebra routing table.
Before routes get to the BGP table, they go through several stages where they can be filtered or changed. The path of the route from getting it from a neighbor to getting into the BGP table is shown in the figure. Bold type shows commands that include the corresponding functionality.
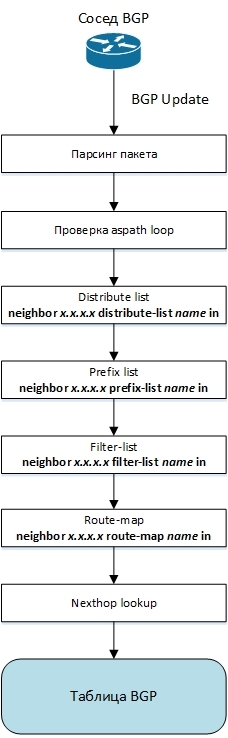
First of all, when receiving a packet, it is parsed, i.e. the contents of the packet are analyzed, checked for correctness, and an internal structure representing the BGP route is formed from the data contained in the packet.
Next, the aspath loop is checked, i.e. Verification that the AS-PATH does not contain the autonomous system number to which the router belongs. This verification is key to preventing BGP protocol routing loops.
Then, various route filtering mechanisms are executed if they are configured for the BGP neighbor from which the packet was received. Distribute-list filters the route based on the ip-address of the prefix, prefix-list based on the ip-address of the prefix and its length, filter-list filters on the basis of the AS-PATH content of the BGP route.
If the route has successfully passed all the filtering steps, then the incoming route-map is applied to it. Here you can flexibly modify the attributes of the route received by BGP. Depending on the prefix and various BGP route attributes, such as AS-PATH, community, MED, next-hop, origin, BGP neighbor ip-addresses, you can change the weight, AS-PATH, community, next-hop, local preference, MED, origin or also filter the route.
Now our route is almost ready to be added to the BGP table, and the last step is to request the validity of next-hop and the metric before it from zebra.
A BGP route can also be created locally using the network or redistribute commands. The figure shows schemes for adding such routes.
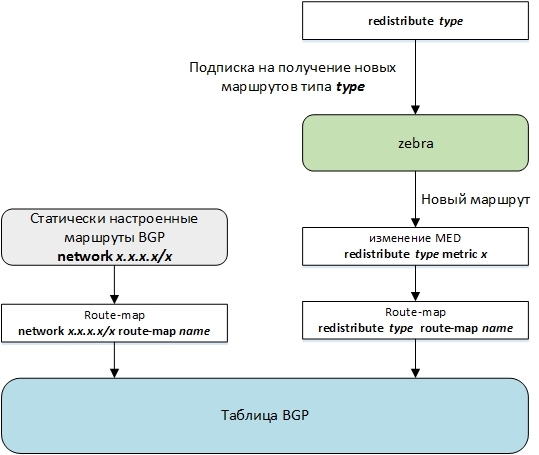
Adding a route using the network command is fairly simple. Unlike Cisco, Quagga does not check for the presence of this route in the zebra routing table. Therefore, this route is filled with default values, a route map is used to change its attributes, and the route is added to the BGP table.
When you enter the redistribute command, the bgpd daemon requests the zebra daemon to sign (tag) it to add or remove a specific type of route (for example, OSPF) in the routing table. When a new route is added to the routing table, zebra sequentially checks which daemons are subscribed to routes of this type and sends this route to the subscribing daemons. After receiving a new route from zebra, the bgpd daemon changes the MED, applies the route-map and adds it to the BGP table.
After selecting a new BGP best route, this route is sent to BGP neighbors. In this case, all BGP neighbors are sequentially sorted and it is checked whether the route needs to be sent to this neighbor. This procedure, performed for each BGP neighbor, is shown in the figure.
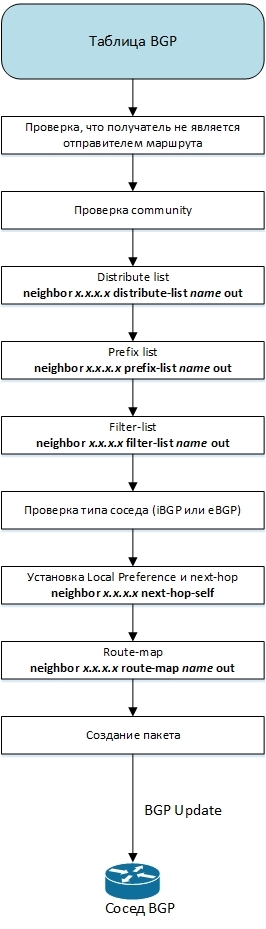
First of all, it is verified that the recipient of the route is not a neighbor from which this route was received.
Next, the route community is checked. If the community contains the value no-advertise, then the route is not announced. Also, the route is not announced if the recipient type is eBGP, and the community contains the value no-export.
Then filtering with outgoing distribute-list, prefix-list and filter-list is the same as it was done for incoming BGP routes.
It is verified that the route received from the iBGP neighbor should not be transferred to another iBGP neighbor (we assume that the Route Reflector is not used).
For routes that did not have Local Preference, Local Preference is set by default. If there is a neighbor 1.1.1.1 next-hop-self setting, or the neighbor is eBGP, then the next-hop is replaced with its own ip-address.
The outgoing route-map is used, allowing you to change the attributes of the advertised route, or filter it at the last stage.
After successfully completing all the previous steps, a BGP Update packet is generated from the BGP route and sent to the neighbor.
In addition to sending the BGP route to its neighbors, the router also sends this route to zebra. This procedure is shown in the figure.
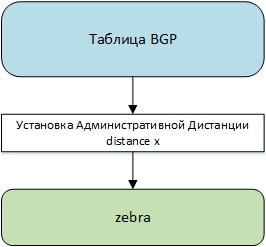
Before sending a route to zebra, an Administrative Distance is set for it, depending on the type of route (iBGP or eBGP). From the BGP route, all necessary fields are taken: route type (BGP), next-hop (or several next-hop if multi-path is used) and metric, after which the route is sent to zebra and begins to compete with routes from other routing protocols.
Of course, this article does not describe all the capabilities of BGP in Quagga. I did not consider the functionality of route-reflector, confederations, IPv6, etc. Nevertheless, the above architecture of the bgpd daemon is largely preserved with this functionality. Below is a brief description of the implementation of some additional features of the bgpd daemon.
To use IPv6, a separate BGP table is created, which uses IPv6 prefixes instead of IPv4 prefixes. The rest of the logic of the BGP table for IPv6 and its binding remains more or less similar to the above described logic of operation for IPv4.
When using the Route-Reflector, the logic of checking which neighbors to send BGP routes changes a little, and when a route is received, additional checks appear to exclude loops (checking the Originator ID and Cluster List attributes).
Small changes in the operation of the algorithm for choosing the best route in the BGP table (so to speak, its fine tuning) can be made using the following global BGP settings:
I will not describe general BGP information. There are a lot of good articles and books about him, and you can get acquainted with the logic of his work, for example, here . I will focus on the mechanism for its implementation in the bgpd daemon. For convenience, the bgpd daemon job description can be divided into two parts.
The first part is called the BGP table (similar to the routing table). All known BGP routes with their attributes are stored here, comparisons are made of various BGP routes and the best ones are selected.
The second part is called strapping. A binding is a set of settings that affect which routes fall into the BGP table, which routes will be announced to neighbors, how attributes of BGP routes change, etc. Those. these are various distribute-list, prefix-list, route-map, redistribute, and so on.
')
BGP table
The BGP table is very similar in its structure to the zebra routing table. Similarly, each prefix corresponds to several different routes received from different sources. Only instead of administrative distance and metrics, various BGP attributes are used, as shown in the figure.
Only attributes affecting the selection of the best route are shown here. For example, the community attribute does not directly affect the choice of the best route and is not shown in the figure.
Also, each route has a pointer to a BGP neighbor (BGP Peer) from which the route was obtained, which allows the use of relevant data about the neighbor, namely: neighbor type (IBGP or EBGP), its router-id and ip-address. Upon receipt or deletion of the next route, a procedure is launched that, using successive pairwise comparison of routes, selects the best one for the given prefix.
Algorithm for comparing two BGP routes
Of the two routes, the best one is (which criteria are listed in order of decreasing priority):
1. Greater Weight.
2. Greater Local Preference.
3. The route is created locally (using the network, redistribute or aggregate-address command).
4. Shorter AS-PATH.
5. Smaller Origin (IGP <EGP <INCOMPLETE)
6. Smaller MED value.
7. The type of neighbor from which the route is received (eBGP is better than iBGP)
8. The smaller IGP metric to the next-hop specified in the route.
9. If both eBGP routes are used, the previously selected as the best (i.e., older) route is preferred.
10. Smaller Router-ID Neighbor.
11. Shorter Cluster list.
12. Lower neighbor IP address.
In the example above, the route marked in green is the best because it has the largest Local Preference.
If any of the routes match the first 8 points with the best route, they (when setting maximum-paths greater than 1) are remembered and can then be processed and transferred to zebra as a multi-path route.
Just like in zebra, all the prefixes used in the BGP table are organized as a prefix tree, and the same algorithm is used to quickly find the desired prefix.
Binding
The binding around the BGP table is shown in the figure.
BGP routes can come either from BGP neighbors or be created locally. Before entering the BGP table, they pass a series of checks and their attributes can be filtered or changed. After choosing the best route, this route is sent to neighbors and enters the zebra routing table.
Receiving a BGP route from a neighbor
Before routes get to the BGP table, they go through several stages where they can be filtered or changed. The path of the route from getting it from a neighbor to getting into the BGP table is shown in the figure. Bold type shows commands that include the corresponding functionality.
First of all, when receiving a packet, it is parsed, i.e. the contents of the packet are analyzed, checked for correctness, and an internal structure representing the BGP route is formed from the data contained in the packet.
Next, the aspath loop is checked, i.e. Verification that the AS-PATH does not contain the autonomous system number to which the router belongs. This verification is key to preventing BGP protocol routing loops.
Then, various route filtering mechanisms are executed if they are configured for the BGP neighbor from which the packet was received. Distribute-list filters the route based on the ip-address of the prefix, prefix-list based on the ip-address of the prefix and its length, filter-list filters on the basis of the AS-PATH content of the BGP route.
If the route has successfully passed all the filtering steps, then the incoming route-map is applied to it. Here you can flexibly modify the attributes of the route received by BGP. Depending on the prefix and various BGP route attributes, such as AS-PATH, community, MED, next-hop, origin, BGP neighbor ip-addresses, you can change the weight, AS-PATH, community, next-hop, local preference, MED, origin or also filter the route.
Now our route is almost ready to be added to the BGP table, and the last step is to request the validity of next-hop and the metric before it from zebra.
Local BGP route creation
A BGP route can also be created locally using the network or redistribute commands. The figure shows schemes for adding such routes.
Adding a route using the network command is fairly simple. Unlike Cisco, Quagga does not check for the presence of this route in the zebra routing table. Therefore, this route is filled with default values, a route map is used to change its attributes, and the route is added to the BGP table.
When you enter the redistribute command, the bgpd daemon requests the zebra daemon to sign (tag) it to add or remove a specific type of route (for example, OSPF) in the routing table. When a new route is added to the routing table, zebra sequentially checks which daemons are subscribed to routes of this type and sends this route to the subscribing daemons. After receiving a new route from zebra, the bgpd daemon changes the MED, applies the route-map and adds it to the BGP table.
Sending a new route to BGP neighbors
After selecting a new BGP best route, this route is sent to BGP neighbors. In this case, all BGP neighbors are sequentially sorted and it is checked whether the route needs to be sent to this neighbor. This procedure, performed for each BGP neighbor, is shown in the figure.
First of all, it is verified that the recipient of the route is not a neighbor from which this route was received.
Next, the route community is checked. If the community contains the value no-advertise, then the route is not announced. Also, the route is not announced if the recipient type is eBGP, and the community contains the value no-export.
Then filtering with outgoing distribute-list, prefix-list and filter-list is the same as it was done for incoming BGP routes.
It is verified that the route received from the iBGP neighbor should not be transferred to another iBGP neighbor (we assume that the Route Reflector is not used).
For routes that did not have Local Preference, Local Preference is set by default. If there is a neighbor 1.1.1.1 next-hop-self setting, or the neighbor is eBGP, then the next-hop is replaced with its own ip-address.
The outgoing route-map is used, allowing you to change the attributes of the advertised route, or filter it at the last stage.
After successfully completing all the previous steps, a BGP Update packet is generated from the BGP route and sent to the neighbor.
Sending a new route to zebra
In addition to sending the BGP route to its neighbors, the router also sends this route to zebra. This procedure is shown in the figure.
Before sending a route to zebra, an Administrative Distance is set for it, depending on the type of route (iBGP or eBGP). From the BGP route, all necessary fields are taken: route type (BGP), next-hop (or several next-hop if multi-path is used) and metric, after which the route is sent to zebra and begins to compete with routes from other routing protocols.
Conclusion
Of course, this article does not describe all the capabilities of BGP in Quagga. I did not consider the functionality of route-reflector, confederations, IPv6, etc. Nevertheless, the above architecture of the bgpd daemon is largely preserved with this functionality. Below is a brief description of the implementation of some additional features of the bgpd daemon.
To use IPv6, a separate BGP table is created, which uses IPv6 prefixes instead of IPv4 prefixes. The rest of the logic of the BGP table for IPv6 and its binding remains more or less similar to the above described logic of operation for IPv4.
When using the Route-Reflector, the logic of checking which neighbors to send BGP routes changes a little, and when a route is received, additional checks appear to exclude loops (checking the Originator ID and Cluster List attributes).
Small changes in the operation of the algorithm for choosing the best route in the BGP table (so to speak, its fine tuning) can be made using the following global BGP settings:
- bgp bestpath as-path ignore - skips step 4 (comparing the lengths of AS-PATH)
- bgp bestpath compare-routerid - skip step 9 (select the older route)
- bgp bestpath med missing-as-worst — if the route has no MED, then this setting assumes that the route has the highest possible MED configured. Without this setting, the missing MED is considered to be 0.
- bgp always-compare-med - allows you to compare MEDs for routes received from different ASs. Without this setting, item 6 for routes received from different ASs is skipped.
- bgp deterministic-med - changes the order of comparison of routes. Instead of sequential comparison of routes with each other, the routes received from the same AS are compared with each other first. You can read more about this setting here .
Source: https://habr.com/ru/post/310736/
All Articles