Tarantool: how to save a million dollars on a database on a high-load project
Anikin Denis ( danikin , Mail.Ru )

Today I will tell you how to save a lot of money on databases, for example, a million dollars, as we did. To begin with, the question is: why are databases using more often, and not files?
A database is a repository that is more structured than a file and has some features that the file does not have.
')

There you can make queries, there are transactions, indexing, tables, stable, more or less reliable storage. In fact, databases are more convenient than files.
Imagine you have an application, it works with a database, it loads this database only for reading so far, i.e. there is not a very large number of records, but a large number of selektov.
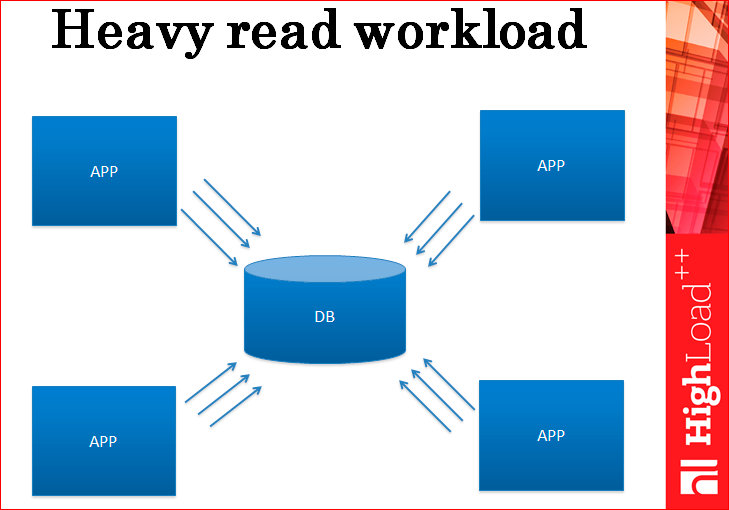
In the end, your database is overloaded and cannot handle the load.
What usually do in such cases? Another server. This is replication. That is, in fact, you deliver replicas exactly in such quantity that they hold your load.
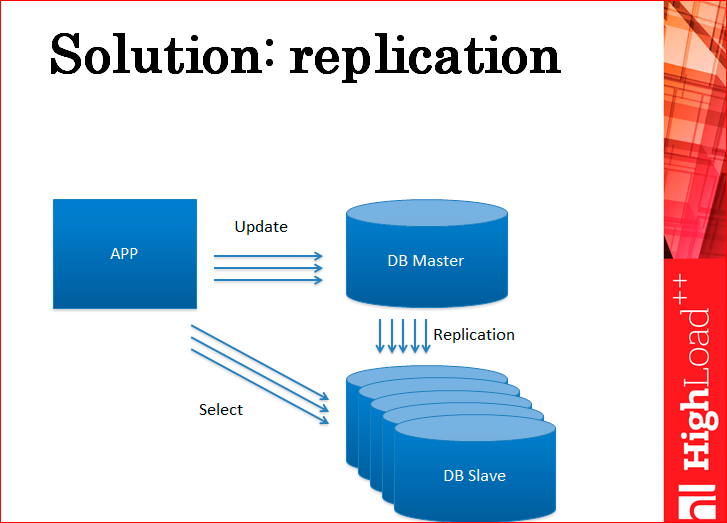
You take all the load on reading to the replicas. Accordingly, the load on the record you leave on the master. This scheme can, in principle, scale the load on reading almost to infinity.
Then we have a load on the record.
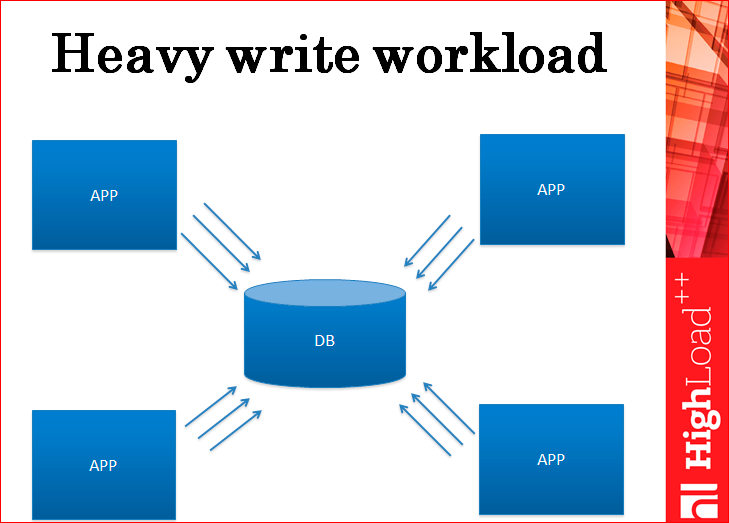
And the load on the record, again, reaches a certain limit, when the database can no longer hold it. Will replication help in this case? Not. Whatever the replication — master slave or master-master — it does not help the load on the records, because each record must go through to all servers. Even if there is a master-master there, it means that how many requests you have in total for your entire cluster, exactly the same amount will go to each of the servers, i.e. you won’t win.
What other ideas are there?
Sharding.
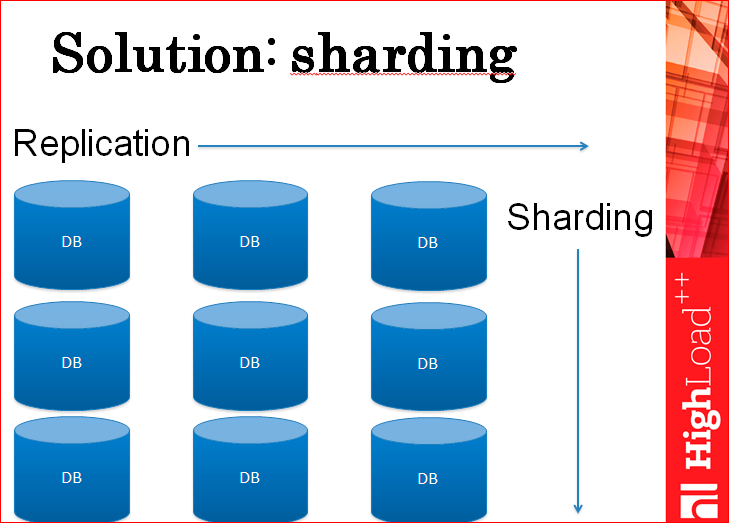
In fact, sharding can solve the problem of the load on the record and scale almost indefinitely.
There are many different ways of sharding - you can cut through databases, you can cut into tables, you can cut inside a single table. Ways - a million. Everyone uses the method that is more convenient for him.
In fact, you get such a two-dimensional cluster of databases, i.e. you have many, many shards, and each has several cues. You deliver shards, cues, and vary completely any load.
But then you have a problem. Your next problem is your boss. What he might not like about it? It seems like everything is working, everything is being shaded, replicated, but what does he not like? Money. He likes everything, except that it is very expensive, because you deliver, deliver, deliver the server, and he pays for it.
You say to him: “Dude, you do not understand, I have technology here, I have sharding, replication ... It scales endlessly - this is a very cool system.”
He tells you: “Yes, yes, but we lose money, if it goes on like this, we simply will not have money to buy a database server. We will have to close. "
What to do?
In fact, the load on the database is often arranged in such a way that some data elements for reading are loaded very, very much - they are called “hot data”.
Caching is something that partially solves our problem.
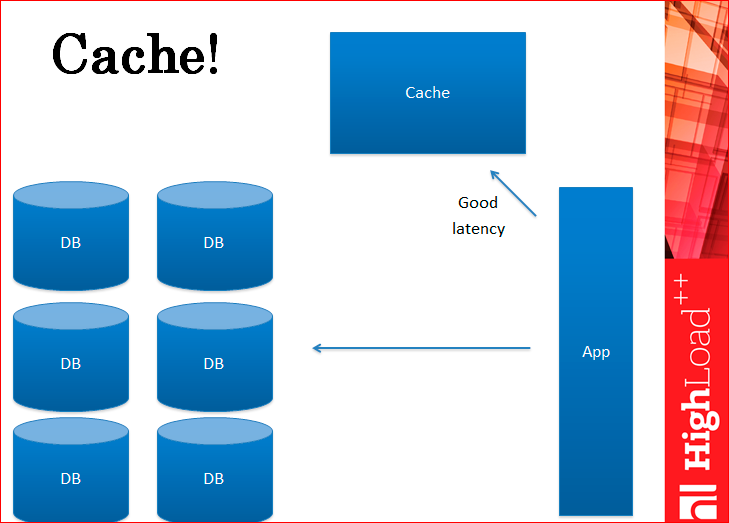
You can remove some of the replicas and thus slightly satisfy your boss. By the way, you get the best lietensi, i.e. queries work faster because the cache is faster than databases.
But ... what's the problem? The inconsistency problem is one of the biggest problems with the cache.
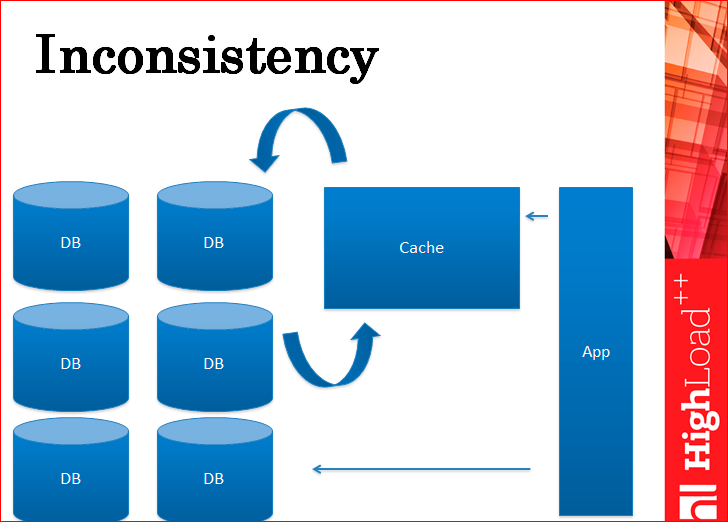
This is the very first problem that is immediately visible.
See, you have an application separately writes to the cache, for example, to Memcached and separately writes to the database. Those. the cache is not a replica of the base, the cache is a separate entity. There are arrows between the cache and the base, which are actually virtual, i.e. there is no replication between them. Everything is done at the application level. Accordingly, this leads to inconsistency of data.
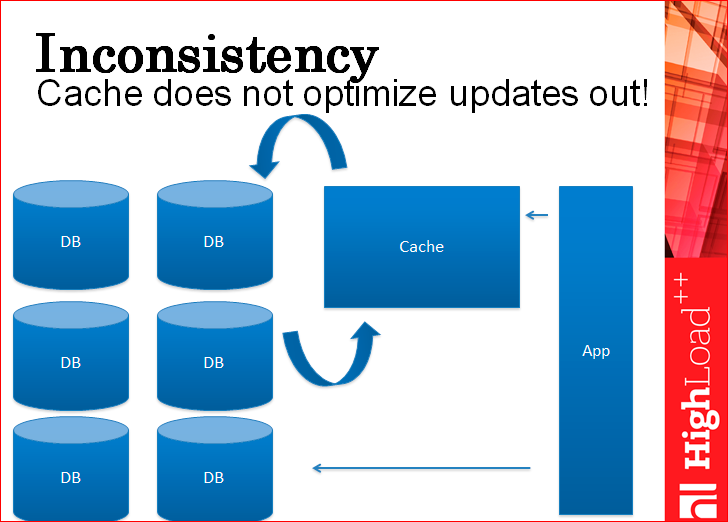
And, by the way, you still have sharding, because the write cache does not optimize, because nothing can be stored in the cache, everything flies through it into the database. Well, not through, but to the side of it, but it flies by.
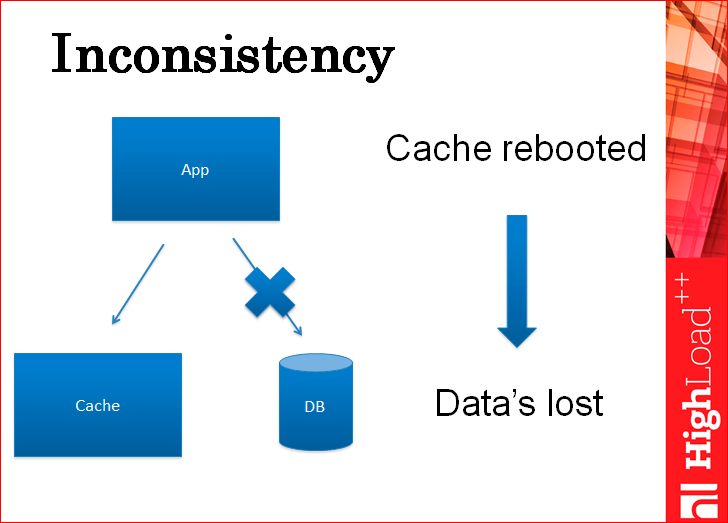
There is a picture to show you that you can write first to the base, then to the cache, or first to the cache, then to the base. In both cases you will have an inconsistency. Look: you write the data to the cache, then your application safely drops and does not have time to write them into the database. The application rises and works with data that is already in the cache, but not in the database, but no one knows about it. When the cache reloads (and it ever reboots), you get outdated data from the database when the cache is empty.
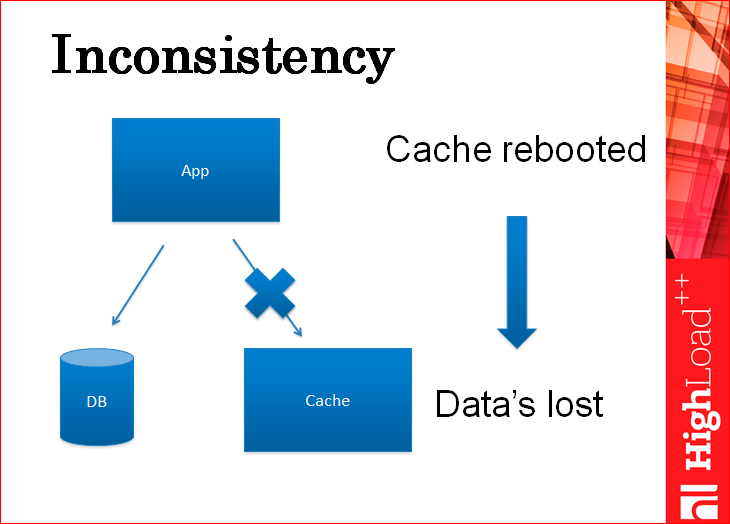
Strangely enough, if you write in the reverse order - first to the database, then to the cache, there will be exactly the same problem: we recorded the database, the application fell, the old data is in the cache, everything works with the old data, the cache rebooted, pulled new data from the database , as if another data branch, which are not complete, which do not correspond to the changes that were made on top of another copy ...
Those. There are at least two problems with the cache: there is no data integrity, and you still need sharding.
What other problems with the cache? What problems did you have with the cache the moment your boss started to get angry? The problem is this: the cache is not a database.

You had a database before the cache, there were requests, transactions, and all these things from the cache almost all disappear, your application is already working with the cache. Indices and tables remain, not all caches have secondary indexes, not all caches have tables, but somehow crookedly obliquely over the key-value, both of them can be supported, so we believe that these properties are observed, and the rest is not.
Now, regarding the problem of incompleteness of data. What to do with it? How to make the data updated in the cache and database holistically? Smart cache.
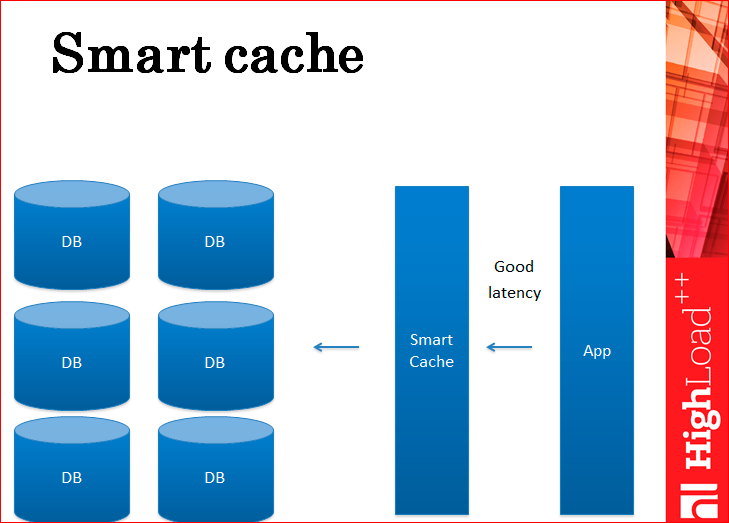
What is smart cache? In fact, many of you are most likely doing this - in fact, this is the cache that communicates with the database itself. Those. This is not a separate Memcached daemon, but some kind of your own samopisny daemon, which inside itself caches everything and writes to the database itself. The application does not write to the database, it works completely through the cache.
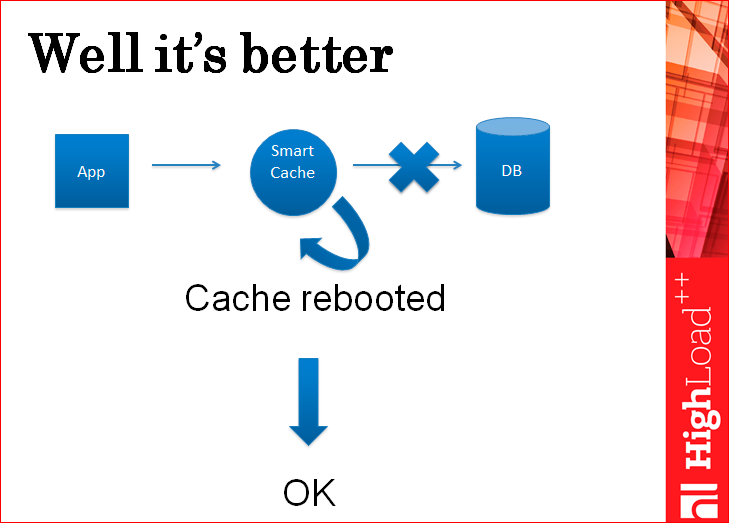
This solves the problem of incompleteness, because the cache first writes to the database, and then writes to itself. If he did not write to the database, he gave an error - everything is fine. This is certainly not good, but the data is complete. After the cache is written to the database, it will write the data in itself, because it writes to the memory, such that the data are not written to the memory almost never happens. Rather, it happens when the memory is beating on the server and at that moment everything drops, and you still lose the entire cache, at least the data integrity is not lost.
But there is one case when you can lose data even with such a smart cache.
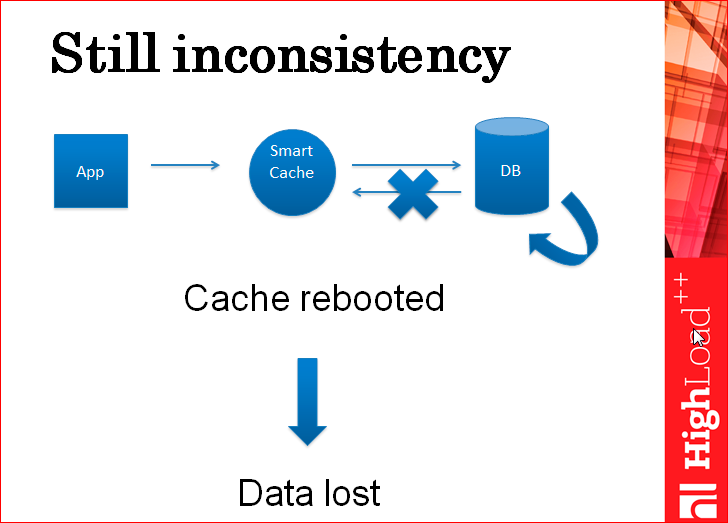
The application writes to the cache, the cache writes to the database, the database internally applies this entry, then it gives the answer to the cache, and at that moment the network breaks. The cache considers that the entry to the database failed, does not write data to itself, gives the user an error. After that, the cache begins to work with the data that is in it, and after reloading it, it picks up the outdated data from the database again.
This is a rare case, but this also happens. Those. smart cache does not completely solve the problem of data integrity. And you still need sharding.
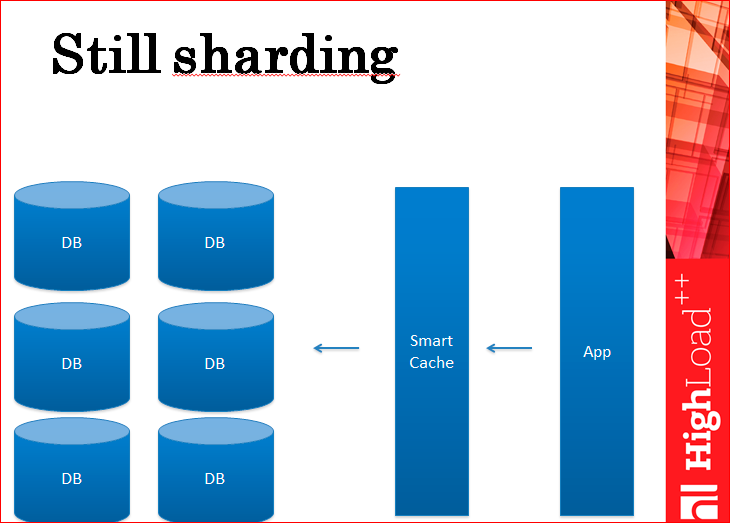
A sharding is when you have a database that is on the same server and you just cut it. You cut it into pieces and put these pieces on different servers, physical servers. This reduces the load on the record, because the load on the record goes to a specific piece. Those. you have, in fact, all the CPUs, for example, all servers are involved in processing this load, and not the CPU of just one server.
You still have a sharding, and you remember that your boss does not like sharding, because it is very expensive, because there are many, many servers and everyone has replicas.
So, the non-integrity of the data, unfortunately, remains with the cache, sharding is still needed, there are no database properties.
What else is a very unpleasant problem with the cache? Cold start.

This is a super unpleasant problem when the cache rises from scratch, clean, naked, without data ... It is useless, just like a car completely covered with snow - you first need to climb into it, and still have to start it. A cold start completely kills the cache, all requests go directly to the database.
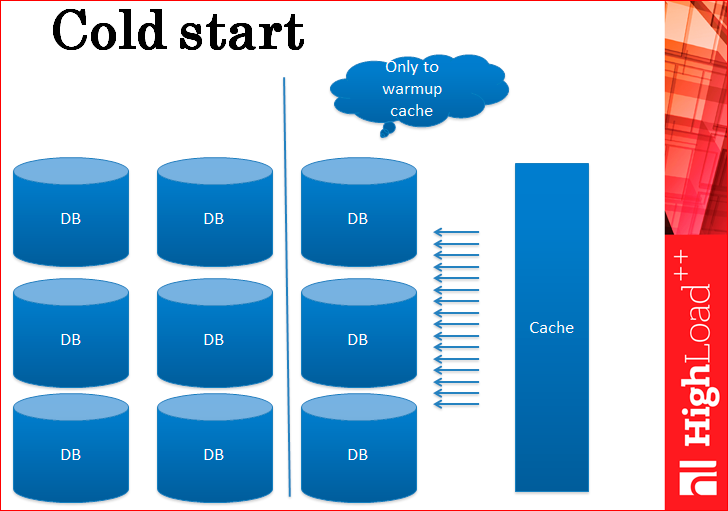
You have to do an action that, again, your boss does not approve, but what can you do? You have to deliver replicas just to warm up the cache. In fact, this layer of replicas - for each shard you deliver by replica - just to warm up the cache. You can not disable these servers or throw out when the cache is warmed up, because suddenly the server with the cache will restart at night? Anyway, everything should work at night, these servers should immediately go to workload and ensure the cache warms up. The cache warmed up, and they are no longer needed, but again they will not put them anywhere.
Four cache issues:

Question: how to warm up the cache? The cache should always be heated to make sense. It is somehow not neatly warmed up through the database, because there are many, many replicas, and they all warm it — warm it — they heat it too much.
Persistence is the right word. It is better to simply not cool the cache, it needs to be persistent, because the cache is a good and fast solution, except for a few problems, including the problem of cold start, including the fact that it is sometimes underheated, so let it always be warmed. Like, for example, in Siberia some people do not jam their cars so that they are always running, because otherwise you will not start it later - approximately from the same opera.
What is the easiest way to cache persist?
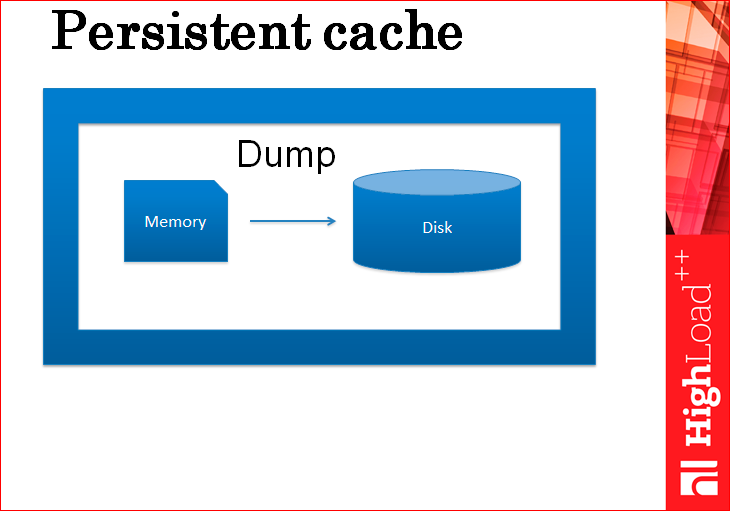
This is just a dump of data. That is, in fact, every time we, maybe, in a minute, or, for example, once every 5 minutes, we dump the entire cache completely to disk, completely right. How do you like this solution? Sucks because consistency is lost. You dump every 5 minutes, your server seems to be rising, and it loses its change in 5 minutes. It is impossible to warm them through the database, and it is not even clear where these changes come from. And this is not the only problem.
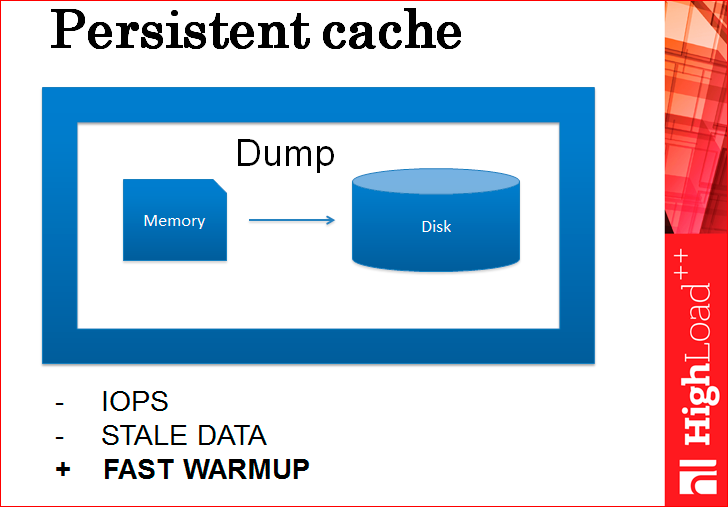
The second problem is that according to IOPS it will be bad, i.e. You will constantly load the disk. Dumps, dumps and again dumps, permanent. The more you want more complete data, the more often you dump. Some not very pleasant way.
What is the best persistence cache?
Log You just need to keep a log.
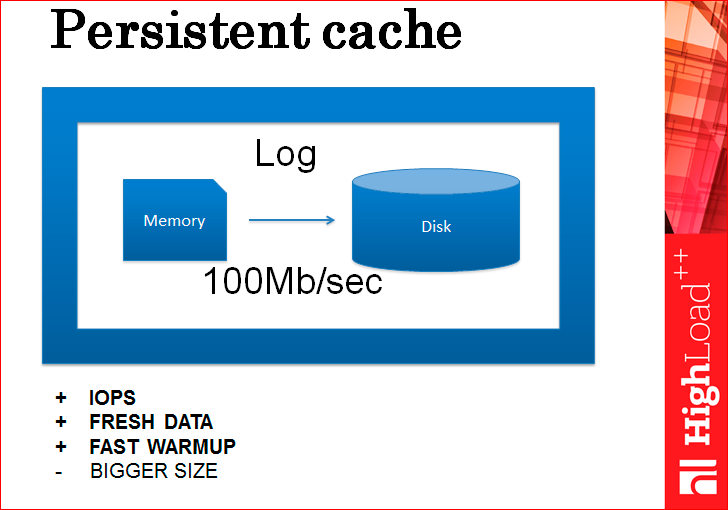
Those. why should we dump, let's keep a log, let's every cache change be logged to disk, every.
If you think that it is slow (there is always an opinion that the cache is something so fast, and when a disk appears there, then it becomes somehow slow), and so, in fact, it is not slow, because even the most usual spinning magnetic disk, not SSD, writes at a speed of 100 Mb / s, writes sequentially. If the transaction size is, say, 100 bytes, then it is 1 million transactions per second. This is an incredible speed that will satisfy almost everyone in this audience, maybe even me. Therefore, even one disk copes with this task perfectly, but there is another problem that this log grows very strongly, because, for example, there are 10 inserts, then 10 delites of the same data, they should all collapse, but they do not collapse in the log . Or there are 100 updates of the same data item, again, only the last one is needed, and everything is stored in the log. How to solve this problem? Snaps do.
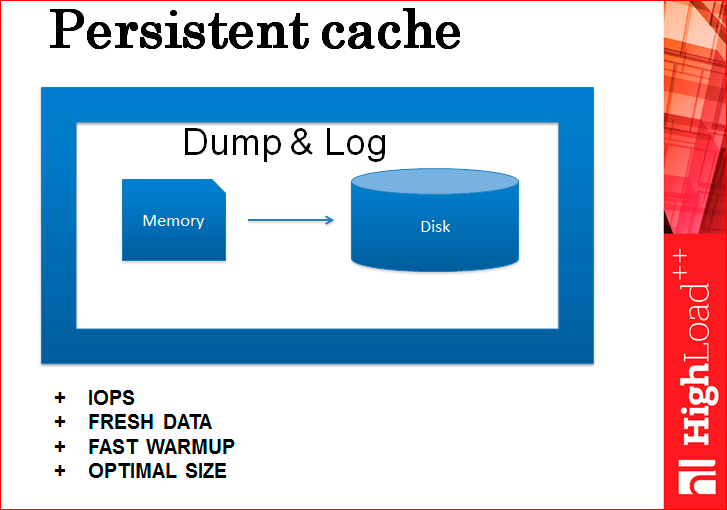
It is necessary to combine these two methods - Dump and Log together. Those. we dump once a week, or when we want it, and the rest of the time we just write a log. In the dump, we still remember the id of the last applied record from the log or the last record from the log, which is still in this snapshot. And when our server reboots, we bring up the dump from the disk, restore it in memory and roll above the piece of log that is after this recording. All cache restored and warmed up immediately.
By the way, this warming up is faster than from the database. This kind of warming up during a reboot will then completely fall into the disk, because this linear reading of the file is 100 MB / s. Even on magnetic disks it is very fast.
Everything, the problem of cold start is solved, but this is only one problem, unfortunately. Although the cache is warm, there are 3 more problems.

Let's think about how to solve the first two - problems of inconsistency and sharding?
The idea of using a cache as a database is a very good direction. Indeed, why do we have our main database in this place? MySQL or Oracle - why do we need it? Let's think about it.
Need, probably, for 2 things:
- we believe that the database reliably stores data, not as a cache, but reliably, i.e. there must be some magic there;
- That there is replication in the database. Caches do not usually have replication. Accordingly, the server's cache failed or simply rebooted, and until it picks up everything from the disk, it is faster than warming up, but it will still be down time - this is also bad, and there is no replication there.
On the first point - reliable storage. If you figure out what the database stores? The database stores hot and cold data — essentially all that it stores. Hot data is usually small, small, and very, very hot, with 10-100 thousand RPS, and cold data are so large and cold, and there are very few references to them.
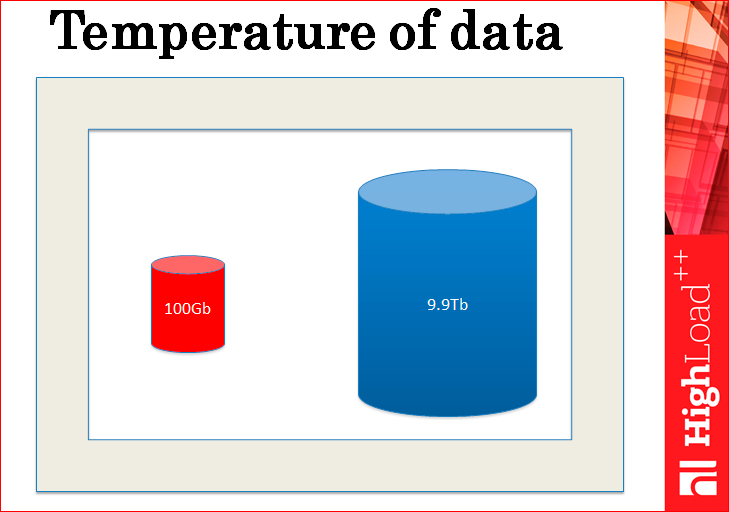
It always happens that the cold data is big and the hot data is small. This is the law of life.
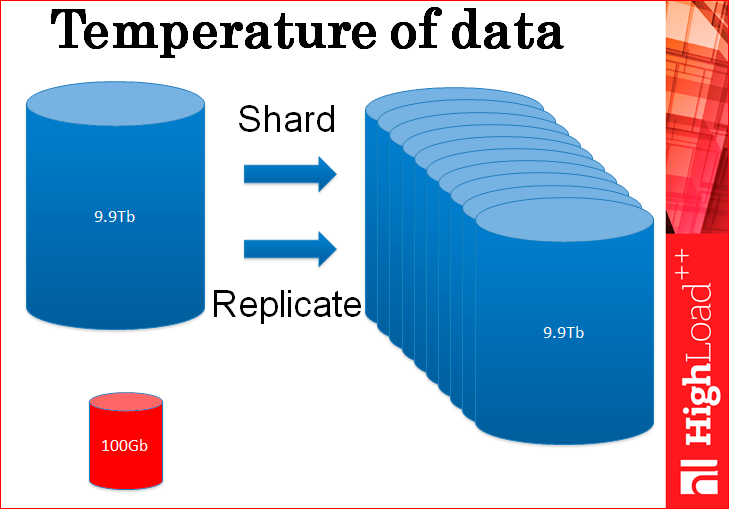
In fact, you replicate and shard your database in a large number of copies only to process this small piece of hot data, because there is not a lot of queries to the rest of the cold data, it feels fine. But you only replicate all this for the sake of hot data.
Why do we do all this copying? Can we probably copy only hot data?
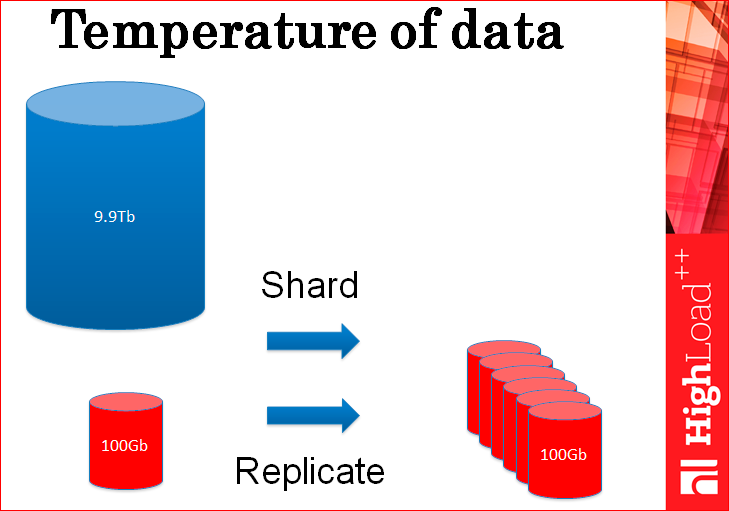
But even here, the same problem - because the load goes exactly to the hot data and therefore, if you replicate and shard only them, the problem will not disappear anywhere, you need exactly the same number of servers to handle all this huge load.
And your boss is still angry because you still have sharding.
In fact, we say that databases reliably store data, but our cache now also reliably stores data, because it has a transaction log file in which all changes are written. This is nothing more than a transaction log, this is the same as any database, it is exactly what ensures reliable storage in any database, no magic, and the cache has the same thing.
No replication. This, of course, is bad, but let's think about why a cache cannot be the primary source of data? Because there is no replication? Well, we will do it.
Why can't the cache be the primary data source? Because it does not have database properties? We can also do this, we can support all these properties of databases, and the cache will have them. Remember the picture “Cache is not a database”?
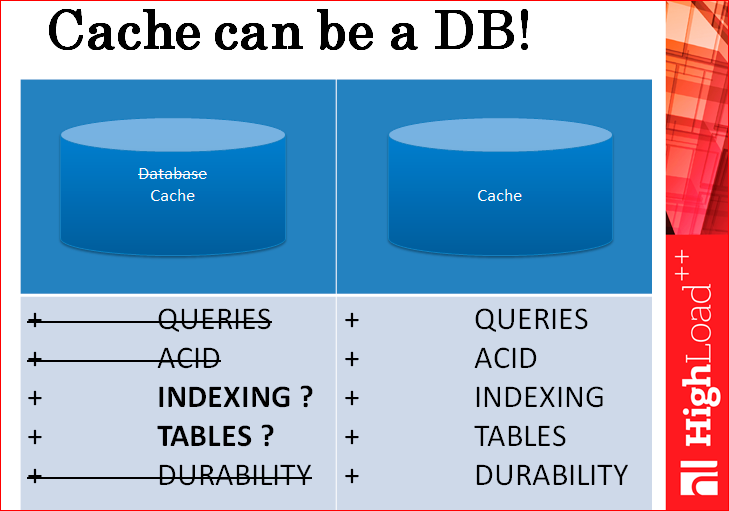
Cache can be a database. He can have all these properties.
You need to keep only hot data in the cache, where there are many, many hits, because you shard and replicate this cold data along with the entire database just to serve the hot data. But if you only shard hot data, this will not solve the problem, because it all the same rests on the number of requests for hot data, that is, the cache can be a database.
Actually, what we did and called this database Tarantool.

We have developed a special database for hot data, which is a cache, but it also has persistents, transactions (the same as adult databases), replication, it even has stored procedures. Those. Tarantool has all the basic properties of the database. And so we use it as the primary source for hot data. We do not duplicate this data anywhere. We have Tarantool, it has a replica, this data is backed up, as well as for any database, but they are not duplicated anywhere, in any other databases. This is always a hot cache with a persistent and with database properties, i.e. He solves all these problems.
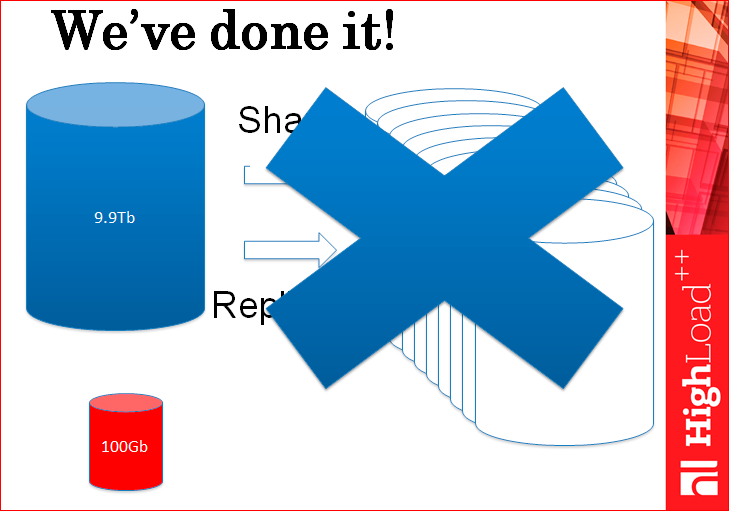
In fact, we do not need now all these hundreds of servers with sharding and replicas, we just have our task divided,
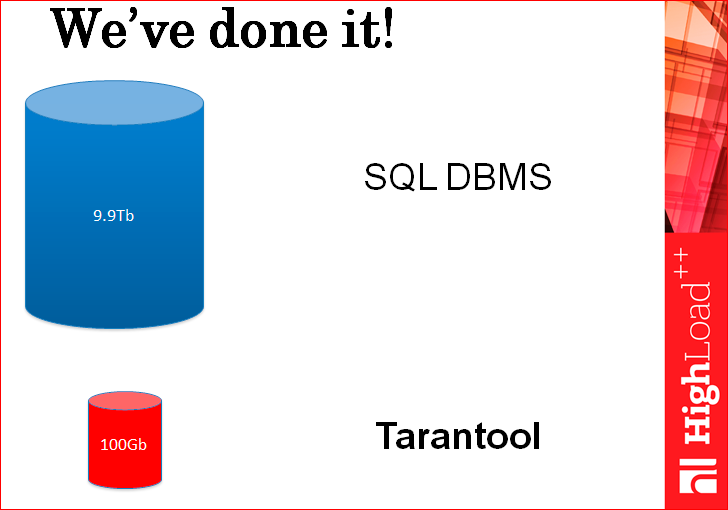
We simply use the right tool for the right task, i.e. cold data is stored in storage. For example, in SQL repositories that were created decades ago for cold data, because then there were no such number of requests per second for data, no one thought about it. And the hot data is stored in the storage, which is specially designed for hot data in Tarantool.

Here, in principle, everything is written on the slide - our way through which we went, but the fact is that for most tasks 2 instances of the whole Tarantool were enough - one master, the second - a replica, because the load that goes to one of databases, on one instance, it will most likely provide your entire bandwidth, which used to go all your SQL Server cluster.

And here is another psychological point - I don’t really want to leave the cozy world of databases in the uncomfortable new world of caches. In a transaction database, etc. Then, when your boss is angry, you delivered the cache and somehow immediately became uncomfortable. And just Tarantool returns this comfort, i.e. he, moreover, solves the problems of inconstancy and cold start. He, as it were, takes you back to the world of databases for hot data.
Now the case in the mail Mail.ru.
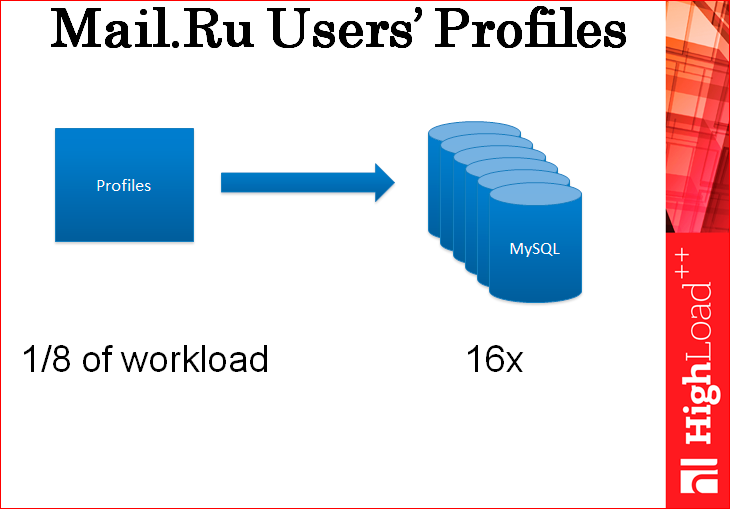
The case was this: we needed to store user profiles. User profiles are such small pieces of information - from 500 bytes to 1 KB per user. We initially began to use MySQL for this business. And they began to duplicate all the load on the profiles that we previously had in the old repository, for reading and writing to the farm from MySQL. We set up a farm of 16 MySQL, we all went ahead and put a load in there. And it turned out that at 1/8 of our entire load, these 16 servers rested on the shelves.Basically, they rested on the shelf on the processor.

We tried to tune them this way and that, but in fact, all that we have achieved is 16 servers at 1/8 of the load, i.e. for the entire cluster, 128 MySQL servers would be required for the entire load. We thought it was a little expensive - more than 1 million dollars. And we just put several servers with Tarantool and let all the load go there. For test purposes, duplicated. And it turned out that they are pulling it all without any problems. Even one server was enough. Put just 4, because the master, replica + a couple more, just in case. We usually relocate always on load.
Actually, here it is saving a million dollars - we just 60 times reduced the number of servers we need. In this case, even the user has become better, because the caches usually work with the best leytensi.

We have a total of more than 120 Tarantool instances in the cloud and mail, servers directly from Tarantool, which are used for different features, for a very large number of features. If we all stored it in MySQL or in any other SQL, then it would be hundreds of millions of dollars, simply if you extrapolate the available figures.
The moral of my entire speech: you need to use the right tool to work properly , i.e. You need to use databases for cold data and persistent caches, like Tarantool, for hot data. And save on this $ 1 million.

Here is a brief summary of what we have done. We sharpened, replicated, rested against money, started caching, lost consistency and one more thing ... We made a persistent cache, it is not a database, but it can be a database, separated hot from cold data, cold in MySQL, hot in Tarantool, saved $ 1 million and, as a bonus, got the best user experience, because everything became faster.
Contacts
» Anikin@corp.mail.ru
» danikin
» Mail.ru company blog
— HighLoad++ . 2016 — HighLoad++ , 7 8 .
" Tarantool ? ". :) — « , !» :) , !
HighLoad++ Tarantool . () , , .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/310690/
All Articles