Freeform real-time speech recognition and call recording recognition

We already wrote about the possibility of creating scripts with speech recognition, but then the functionality of this system was somewhat limited. Not so long ago, Google has opened access to a speech recognition system. And we, of course, took advantage of this. Many companies implement different scenarios of interaction with their customers using Voximplant. Automation using speech recognition and search in an already recognized one allows a business to spend less effort on manual work and more on what is really important. Next, we will describe in detail about several basic cases for which integration was done, and problems encountered in the process, and also give some examples of using the new functionality.
Freeform is hard
To begin with, freeform recognition is a very difficult technical task. If on a limited dictionary (for example, addresses) to get recognition quality in 90 +% is real, then in the case of freeform, this is practically unattainable today. It's one thing when a person dictates something, that is, the output is a structured text. And a completely different thing is a telephone conversation, where, during communication, there is a million extra moments that worsen the quality of recognition: from commonplace interjections, coughing and individual speech characteristics to noise, packet loss and others that have the most different nature. In addition, real-time recognition requires sufficiently decent computing power, and we need all this to scale well and be accessible from the cloud. We can assure you that we have been testing a wide variety of freeform recognition solutions for a long time. Every time something was missing, so when colleagues from Google announced their recognition, we gladly ran to test it.
Google Cloud Speech API Features
Currently, Google Cloud Speech API is in open beta state. There are a number of restrictions on the number and speed of requests that you can feed him. There are several options for working with the API: synchronous mode, asynchronous mode and streaming. Synchronous mode allows you to send pieces of audio data up to a minute in duration and returns a response with the recognition result to the request. Asynchronous mode allows you to handle large files, but for this you need to upload them to Google Cloud Storage. Streaming allows you to transfer data in parts and get the result of recognition in real time, that is, it is well suited for dictation and IVR. For audio format - 8/16 KHz. A number of different codecs are supported depending on the mode: ulaw, flac, amr, or just PCM. The vendor recommends using 16 KHz and not using additional signal processing - this only degrades the quality of recognition. Our experience has shown that the nuances are, in fact, much more. For example, it is better not to try to recognize pieces longer than 20 seconds, if the piece is too small, then you can not get the result at the output, etc. Many of these problems are a consequence of the beta version. We think that they will be corrected for release.
Case №1: Transcribing
One of the most popular cases is the recognition of call recordings. Probably no need to explain for a long time why this is such a useful feature. Search in the text is much simpler than search in audio, so any kind of analysis will be accelerated and simplified after conversion to text. To enable transcribing, an additional transcribe parameter must be passed to the recording function:
')
require(Modules.ASR); //.. call.record({language: ASRLanguage.RUSSIAN_RU, transcribe: true, stereo: true}); //... All call processing scripts in Voximplant are written in JavaScript, so everything is quite transparent here. This code says that after the end of the recording, it will be necessary to send data to a special subsystem that will interact with the Google Speech API. And after some time in the call history, in addition to recording, a text file will appear with the recognition results. The result will look like this:
Left 00:00:00 - 00:00:03 : <Unrecognized> Right 00:00:00 - 00:00:35 : Philips 1 Philips 2 Philips 3 Philips 4 Right 00:00:38 - 00:01:18 : Philips 1 Philips 2 Philips 3 Philips 4 Philips Left 00:01:05 - 00:01:44 : nanosuit Saeco - . - Right 00:01:20 - 00:02:01 : Philips Left 00:01:49 - 00:02:33 : x xxx xxxx Right 00:02:07 - 00:02:30 : 125 Right 00:02:32 - 00:03:17 : 66 67 2 . Left 00:02:34 - 00:03:14 : Left 00:03:14 - 00:03:26 : Right 00:03:17 - 00:03:25 : Philips Unfortunately, while the API does not issue timestamps during recognition, it is therefore not possible to split the time as precisely as possible when and what was said. But even so, it is very good.
Case №2. IVR
Keyword "automation". Now only the lazy does not write and does not tell about how the world will change thanks to machine learning, AI and so on. Probably, we do not agree with everything in these stories. Especially about AI. But the fact that automation allows us to speed up and improve a number of processes, we know very well, since we actively offer our clients to automate the processes of interaction with their clients, for which we had to spend our time dearly on our employees. Intelligent speech recognition IVRs will be avalanche-propagated in the near future precisely because of progress in machine learning and in speech recognition. In the US, if you call the Department of Motor Vehicles, you will have a long and exciting conversation with their IVR, where it’s almost impossible to get to a living person. Maximum - you can ask to call you back later. If you're lucky somewhere next week. We do not believe that such an extreme option is right. Still, you need to give people the opportunity to get on a living person, if communication does not add up. But the trend has long been clear.
In the case of Voximplant, we have long been able to implement such scenarios. Previously, the recognition accuracy in some cases was insufficient. In the case of APIs from Google, you can set speech_context , which allows you to implement a script with a choice from a predefined list of phrases and options. And if a person says something out of context, recognition will still work. But if he says something out of context, then it will work with much higher accuracy. You can use this feature in a VoxEngine script as follows:
require(Modules.ASR); //.. mycall.say(" ", Language.RU_RUSSIAN_FEMALE); mycall.addEventListener(CallEvents.PlaybackFinished, function (e) { mycall.sendMediaTo(myasr); }); //... var myasr = VoxEngine.createASR( ASRLanguage.RUSSIAN_RU, ["", "", "", " ", " "]); myasr.addEventListener(ASREvents.Result, function (e) { if (e.confidence > 0) mycall.say(" " + e.text + " " + e.confidence, Language.RU_RUSSIAN_FEMALE); else mycall.say(" ", Language.RU_RUSSIAN_FEMALE); }); myasr.addEventListener(ASREvents.SpeechCaptured, function (e) { mycall.stopMediaTo(myasr); }); //... Case number 3. Streaming
For some technical reasons related to the work of the backend from Google, we had to decently poshamanit for the implementation of the streaming mode. We hope in the near future this need will disappear. So, to recognize the whole conversation in real time (or just large parts of speech) you need to modify the script:
require(Modules.ASR); var full_result = "", ts; //.. mycall.say(" ", Language.RU_RUSSIAN_FEMALE); mycall.addEventListener(CallEvents.PlaybackFinished, function (e) { mycall.sendMediaTo(myasr); }); //... // - freeform ( ) var myasr = VoxEngine.createASR(ASRLanguage.RUSSIAN_RU); myasr.addEventListener(ASREvents.Result, function (e) { // full_result += e.text + " "; // 5 CaptureStarted, ts = setTimeout(recognitionEnded, 5000); }); myasr.addEventListener(ASREvents.SpeechCaptured, function (e) { // /*mycall.stopMediaTo(myasr);*/ }); myasr.addEventListener(ASREvents.CaptureStarted, function() { // clearTimeout(ts); }); function recognitionEnded() { // myasr.stop(); } //... I would like to note one nuance: the CaptureStarted event arises based on the feedback from the Google API. There now VAD is good enough, and these events can occur not only on speech, but also on background noise. In order to know exactly when it is time to stop recognition in streaming mode with silence, you can use our built-in VAD in addition:
mycall.handleMicStatus(true); mycall.addEventListener(CallEvents.MicStatusChange, function(e) { if (e.active) { // } else { // } }); Demo
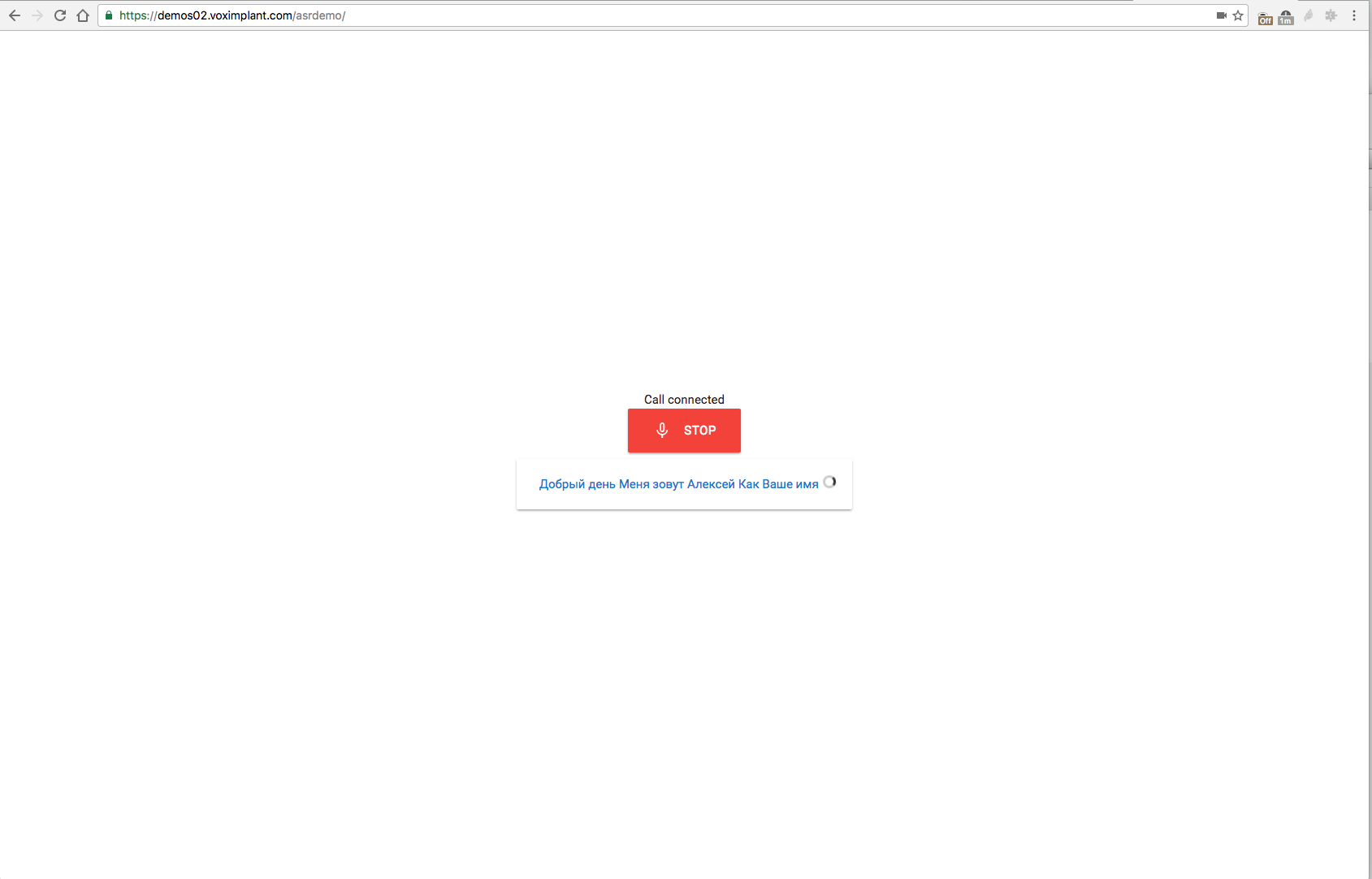
It would be strange not to let you test this whole farm without any extra movements (although we, of course, highly recommend starting to develop using Voximplant :) The demo is available at https://demos02.voximplant.com/asrdemo/ . You need a browser that supports WebRTC / ORTC (Chrome / Firefox / Edge) and a microphone. The source of this wonderful demo is available on Gist .
Source: https://habr.com/ru/post/310684/
All Articles