About new successes of confrontation (SR UHF! *)
A couple of days ago there was an article that almost no one covered. In my opinion, she is wonderful, so I will tell about her to the best of my abilities. An article about what has not yet happened: the car was taught to play a shooter using only a picture from the screen. Instead of a thousand words:
Not perfect, but for me - very cool. A 3D shooter that is played in real time is the first time.
The approach that was used overlaps with both the way the GO bot made it and the Atari games. In fact, it is “Deep reinforcement learning”. The most detailed article on this topic in Russian, perhaps here .
')
In a nutshell. Let there be some function Q (s, a). This function determines the profit that will be returned by our system from performing the action a in the state s. The neural network is trained so that at the outputs it gives an approximation of the function Q. As a result, we know the price of any action in each situation. To understand in more detail it is better to read one of the above texts.
The classic approach used in Atari games for 3D shooters does not work. Too much information, too much uncertainty. In Atari games, the optimal action could be performed in a sequence of 3-4 frames, which they used extensively, feeding them to the input. In Alpha Go, the authors used an additional system that went and went over the best options according to the Go rules.
How did the authors do it here? After all, you will not be able to burn your internal engine? It turns out that everything is very simple and interesting. Globally, 3 improvements have been made:
Now a little more detail.
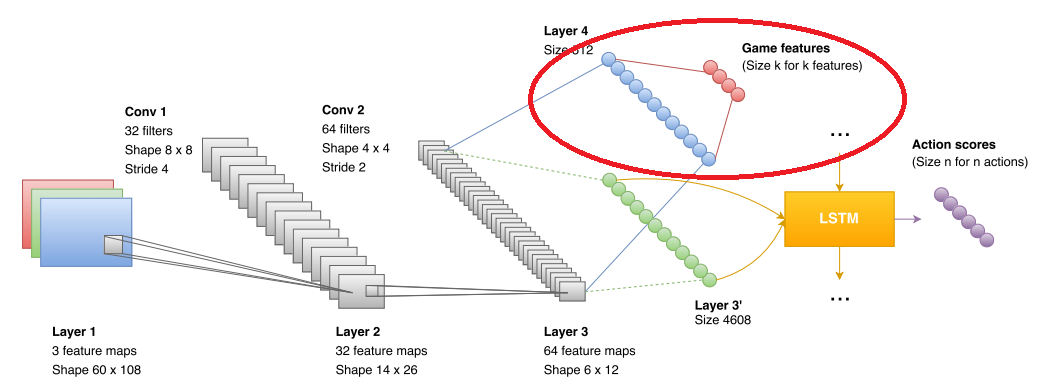
When a person first gets behind DOOM, he is told: this is a bad monster, he needs to be killed. A person has an understanding of what a monster is => he quickly mastered. The neural network has never seen a monster. I never saw the kit and never saw the barrels. She does not know how to distinguish one from the other.
In-depth training with reinforcements implies that the system should learn only according to its objective function. But often this is not possible. It is impossible to understand from the objective function that the array of moving pixels is the enemy. Well, it is possible, but long and dreary. Man has a priori information. It is necessary to upload it to the network.
Therefore, the authors have introduced an additional block that is used in the training. They submit to the block what the network sees (in the figure it is marked with a red ellipse). The data format is boolean in the style of “see a monster”, “see a first aid kit”, “see ammunition”. As a result, the convolutional network is clearly trained to recognize enemies, first-aid kits and ammunition. In the game phase, this block is not used at all. More precisely used, but more on that below. But how many features improve the accuracy of the network:
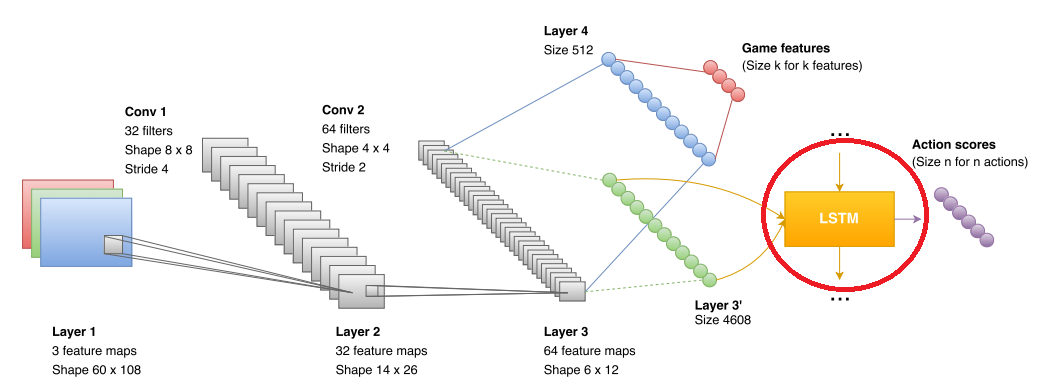
LSTM is a recurrent network that can quite well combine the data that a convolutional network receives. In the original articles on Atari and Alpha GO, there were no such networks, but they were already used in other DQR projects (for example, with the same Atari games). So there was nothing really new here.
And again, the authors rested in an unpleasant moment. The recurrent network provided data analysis and forecasting for several seconds (the work is taught in sequences of about 10 frames long, where the frame is taken several times per second (1/5 fps, fps are not specified)). More global predictions for her were inaccurate. In addition, the network is difficult to teach the concept "we will soon run out of ammunition, it would be good to start looking for something." As a result, the authors dodged and made two independent networks. One network was able to look for kits and cartridges. The second to do frags.
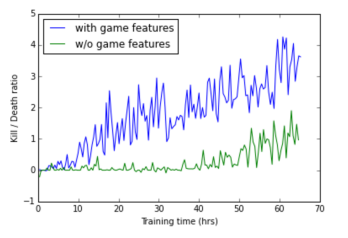
Switching is carried out at the expense of the very “monster selection” that the network generates due to the nature of the training. If the monsters are not visible, then the solutions of the “research network” are used, after the appearance of the monster of the “combat” solution. The effect of the introduction of the research network:
By the way, the research network is killing the bot "camper behavior", which is characteristic of "combat".
The research network during the training wrote out the pluses for the distance traveled.
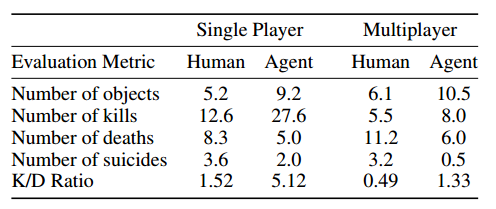
Human network wins with a good margin. I think this is important.
According to DQN I'm not an expert, maybe something is not perfectly told. It would be interesting to hear from experts. But the selection of methods, and especially the result I was very impressed.
PS A few more examples of bloody learning:
* Wed UHF!
Not perfect, but for me - very cool. A 3D shooter that is played in real time is the first time.
The approach that was used overlaps with both the way the GO bot made it and the Atari games. In fact, it is “Deep reinforcement learning”. The most detailed article on this topic in Russian, perhaps here .
')
In a nutshell. Let there be some function Q (s, a). This function determines the profit that will be returned by our system from performing the action a in the state s. The neural network is trained so that at the outputs it gives an approximation of the function Q. As a result, we know the price of any action in each situation. To understand in more detail it is better to read one of the above texts.
The classic approach used in Atari games for 3D shooters does not work. Too much information, too much uncertainty. In Atari games, the optimal action could be performed in a sequence of 3-4 frames, which they used extensively, feeding them to the input. In Alpha Go, the authors used an additional system that went and went over the best options according to the Go rules.
How did the authors do it here? After all, you will not be able to burn your internal engine? It turns out that everything is very simple and interesting. Globally, 3 improvements have been made:
- During the training some additional information from the engine was used.
- Used LSTM at CNN output
- Two networks were trained: "Research" and "Combat"
Now a little more detail.
Information from the engine
When a person first gets behind DOOM, he is told: this is a bad monster, he needs to be killed. A person has an understanding of what a monster is => he quickly mastered. The neural network has never seen a monster. I never saw the kit and never saw the barrels. She does not know how to distinguish one from the other.
In-depth training with reinforcements implies that the system should learn only according to its objective function. But often this is not possible. It is impossible to understand from the objective function that the array of moving pixels is the enemy. Well, it is possible, but long and dreary. Man has a priori information. It is necessary to upload it to the network.
Therefore, the authors have introduced an additional block that is used in the training. They submit to the block what the network sees (in the figure it is marked with a red ellipse). The data format is boolean in the style of “see a monster”, “see a first aid kit”, “see ammunition”. As a result, the convolutional network is clearly trained to recognize enemies, first-aid kits and ammunition. In the game phase, this block is not used at all. More precisely used, but more on that below. But how many features improve the accuracy of the network:
Lstm
LSTM is a recurrent network that can quite well combine the data that a convolutional network receives. In the original articles on Atari and Alpha GO, there were no such networks, but they were already used in other DQR projects (for example, with the same Atari games). So there was nothing really new here.
Two networks
And again, the authors rested in an unpleasant moment. The recurrent network provided data analysis and forecasting for several seconds (the work is taught in sequences of about 10 frames long, where the frame is taken several times per second (1/5 fps, fps are not specified)). More global predictions for her were inaccurate. In addition, the network is difficult to teach the concept "we will soon run out of ammunition, it would be good to start looking for something." As a result, the authors dodged and made two independent networks. One network was able to look for kits and cartridges. The second to do frags.
Switching is carried out at the expense of the very “monster selection” that the network generates due to the nature of the training. If the monsters are not visible, then the solutions of the “research network” are used, after the appearance of the monster of the “combat” solution. The effect of the introduction of the research network:
By the way, the research network is killing the bot "camper behavior", which is characteristic of "combat".
The research network during the training wrote out the pluses for the distance traveled.
What finally came out
Human network wins with a good margin. I think this is important.
According to DQN I'm not an expert, maybe something is not perfectly told. It would be interesting to hear from experts. But the selection of methods, and especially the result I was very impressed.
PS A few more examples of bloody learning:
* Wed UHF!
Source: https://habr.com/ru/post/310638/
All Articles