Comparison of analytical in-memory databases
 In the last two months of summer, Tinkoff Bank has a new topic in the management of data warehousing (Data Warehouse, DWH) for kitchen disputes.
In the last two months of summer, Tinkoff Bank has a new topic in the management of data warehousing (Data Warehouse, DWH) for kitchen disputes.All this time we have been conducting large-scale testing of several in-memory DBMSs. Any conversation with the administrators of DWH at this time could begin with the phrase "Well, who is in the lead?", And not miscalculated. In response, people received a long and very emotional tirade about the difficulties of testing, the intricacies of communicating with hitherto unknown vendors and the shortcomings of individual subjects.
Details, results and a kind of conclusions from testing - under the cut.
The purpose of testing is to look at a fast analytical in-memory database that meets our requirements and assess the complexity of its integration with other data warehouse systems.
We also included two DBMS in testing, which are not positioned as an in-memory solution. We expected that the caching mechanisms in them, provided that the data volume was roughly equivalent to the RAM size of the servers, would allow these DBMS to approach the performance in comparison with the classical in-memory solutions.
')
Description of use case
It is assumed that the DBMS selected as a result of testing will work as a front-end storage database for a selective data set (2-4 TB, but the data volume may grow over time): accept requests from the BI system (SAP BusinessObjects) and part ad-hoc requests from some users. Queries, in 90% of cases, are SELECTs with from 1 to 10 join-s according to the conditions of equality and, sometimes, the conditions for the occurrence of dates in the interval.
We need such queries to work much faster than they are now working in the main database of the repository - Greenplum.
It is also important that the number of simultaneous requests being executed does not greatly influence the execution time of each request — it should be approximately constant.
In our opinion, the target database should have the following functionality:
- horizontal scalability;
- the ability to perform local join-s - use the "correct" distribution key in the tables
- column data storage;
- ability to work with a cache and a large amount of available memory.
Downloading data to the target system is assumed from the main storage database - Greenplum, and therefore it is also important for us to have a way to quickly and reliably deliver data (preferably incrementally) from Greenplum to the target database.
The ability to integrate with SAP BO is also important. Fortunately, almost everything that has a stable ODBC driver for Windows works well with this system.
From small but weighty requirements, one can distinguish window functions, redundancy (the ability to store multiple copies of data on different nodes), simplicity of further cluster expansion, parallel data loading.
Test bench
Two physical servers were allocated for each database:
- 16 physical cores (32 with HT)
- 128 GB OP
- 3.9 TB of disk space (RAID 5 of 8 disks)
- Servers are connected by a 10 Gbps network.
- The OS for each database was selected based on the recommendations for installing the database itself. The same applies to the settings of the OS, kernel and other things.
Testing Criteria
- The speed of the test queries
- Ability to integrate with SAP BO
- Have a quick and suitable way to import data
- Stable ODBC driver
- If the product is not distributed freely, it was possible to contact the representatives of the manufacturer’s company in adequate time and obtain the installation (distribution kit) of the database required for testing.
DB, included in testing
Greenplum

Old, kind, well familiar to us Greenplum. About him we have a separate article .
Strictly speaking, Greenplum is not an in-memory database, but it has been experimentally proven that due to the properties of XFS, on which it stores data, it behaves as such under certain conditions.
So, for example, when reading, if the amount of memory is sufficient, and also if the data requested by the request is already in memory (cached), the disks for receiving data will not be affected at all - all data from Greenplum will be taken from memory. It should be understood that this mode of operation is not peculiar to the Greenplum, and therefore specialized in-memory DB should (in theory) cope with such a task better.
For testing, Greenplum was installed by default, without mirrors (primary segments only). All settings are default, tables are compressed zlib.
Yandex Clickhouse

Column DBMS for analytics and real-time reports from a famous search giant.
The DBMS is installed according to the manufacturer's recommendations , the engine for local tables, MergeTree, on top of the local tables were created Distributed tables, which participated in the queries.
SAP HANA

HANA (High performance ANalytics Appliance) is positioned as a universal tool for analytical and transactional load. Able to store data in a column. There are necessary for the product base Disaster recovery, mirroring and replication. HANA allows you to flexibly configure partitions (shards) for tables: both in hash and in range of values.
In the presence of multi-level partitioning, at different levels, you can use different types of partitions. Up to 2 billion records can be written in one partition.
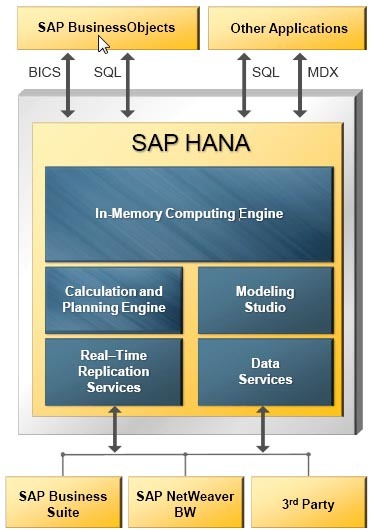
Solution architecture based on SAP HANA
One of the interesting features of this DBMS is the common setting “unload priority” - the priority of unloading from memory, from 1 to 10. It allows you to flexibly manage memory resources and access speeds to tables: if the table is rarely used, then it is set to the lowest priority. In this case, the table will rarely be loaded into memory and will be one of the first to be unloaded when there is a shortage of resources.
Exasol

The product in Russia is almost unknown, dark horse. Of the large companies, only Badoo (of which there is an article on Habré) work with this DBMS and a couple of non-IT companies whose name is known - the full list is on the official website.
Vendor promises enchanting fast analytics, the stability of the stone in the forest and the ease of administration at the level of the coffee grinder.
Exasol runs on its OS - ExaOS (its own GNU / Linux distribution based on CentOS / RHEL). Installing a DBMS is at least unusual, since it is not installing a separate piece of software on a ready OS, but installing the OS on a separate licensed machine (virtual in our case) from the downloaded image and minimal configuration (partitioning of drives, network interfaces, allow PxE boot) for workers nod.
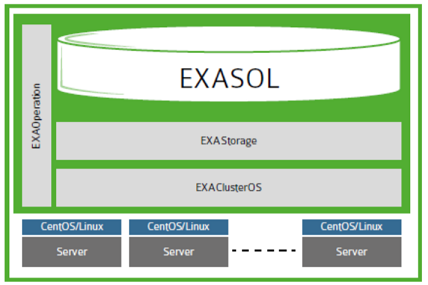
Exasol Simplified Architecture
The beauty of this system is that, since it is not necessary to install anything on the nodes (OS, kernel parameters, and other joys), adding a new node to the cluster happens very quickly. From the moment the server is installed and connected (bare-metal, without OS), you can enter the node into the cluster in less than half an hour. All base management is done via a web console. It is not overloaded with functionality, but it cannot be called a trimmed one.
The data is stored in memory by collation and compressed well (the compression settings could not be detected).
If, when processing a request, you need more data than there is RAM, the base will start to use swap (spill) on the disks. The request will not fall (hello to Hana and memSQL), it will just work slower.
Exasol automatically creates and removes indexes. If you make a query for the first time and the DBMS decides that the query will work faster with the index, then the index will be created during the query processing. And if this index of 30 days was not needed by anyone, then the base itself will remove it.
Memsql

In-memory DBMS based on mySQL. Cluster, there are analytic functions. By default, it stores data line by line.
To make stonework storage, you need to add a special index when creating the table:
KEY `keyname` (`fieldaname`) USING CLUSTERED COLUMNSTORE In this case, rowstore data is always stored in memory, but columnstore data, in case of low memory, can be automatically flushed to disk.
Distribution key is called SHARD KEY. An automatic btree index is created for each field in the shard key.
The basic version is completely free, with no restrictions on the amount of data and RAM. In the paid version there are high availability, online backups and restorers, replication between data centers and user rights management.
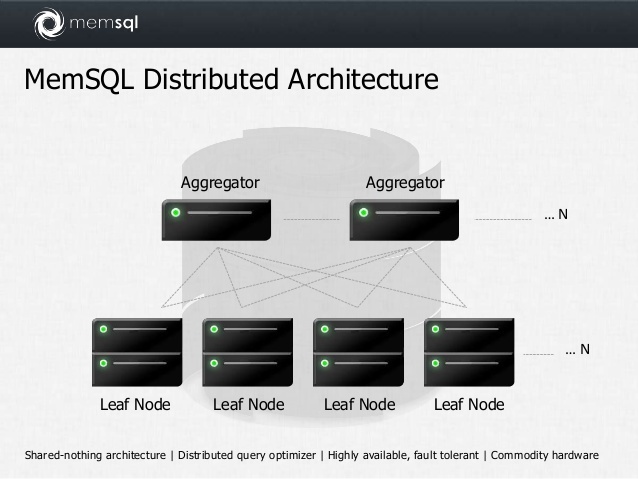
Simplified Memsql Architecture
Impala

The Cloudera product, an SQL engine developed in C ++, is part of the Apache Hadoop ecosystem. Works with data stored in HDFS and HBase. As a metadata repository uses HiveMetastore, which is part of the database Hive. Unlike Hive, does not use MapReduce. Supports caching of frequently used data blocks.
Positioned as a DBMS for processing analytical queries that require a quick response. Able to work with basic BI-tools. Full ANSI SQL support, window functions present.
Impala is available as a package and a package in the Cloudera repository. During testing, the distribution kit was used: Cloudera CDH 5.8.0. For installation, the minimum set of services was chosen for Impala operation: Zookeeper, HDFS, Yarn, Hive. Most of the settings were used by default. For Impala, a total of 160 GB of memory was allocated from both servers. To control the utilization of server resources by containers, cgroups were used.
All the optimizations recommended in the article were performed, namely:
- Parquet was chosen as the format for storing tables in HDFS;
- optimized data types, where it could be done;
- preliminary statistics were collected for each table (compute stats);
- data of all tables were recorded in the HDFS cache (alter table ... set cached in ...);
- optimized joines (as far as possible).
At the initial planning stage, testing and determining the DBMS for the participation of Impala was discarded because we already worked with it several years ago and at that time it did not look production-ready. Once again, we were persuaded by our industry colleagues to look in the direction of "Antelope", convincing that over time it has become much prettier and has learned how to work with memory correctly.
More information about Impala
Composition:
Impala Daemon is a basic service that serves to accept, process, coordinate, distribute across a cluster and execute a query. Supports ODBC and JDBC interfaces. It also has a CLI interface and an interface for working with Hue (Web UI for analyzing data in Hadoop). It is executed as a daemon on each of the cluster workers.
Impala Statestore - used to check the status of Impala Daemon instances running in a cluster. If Impala Daemon fails on any worker, then the State store notifies instances on the other workers so that requests to the instance that has gone offline are not transmitted. As a rule, works on the master node of the cluster, is not required.
Impala Catalog Server - this service is used to receive and aggregate metadata from HiveMetastore, HDFS Namenode, HBase as a structure supported by Impala Daemon. This service is also used to store metadata used exclusively by Impala itself, such as, for example, user-defined functions. As a rule, works on the master node of the cluster.
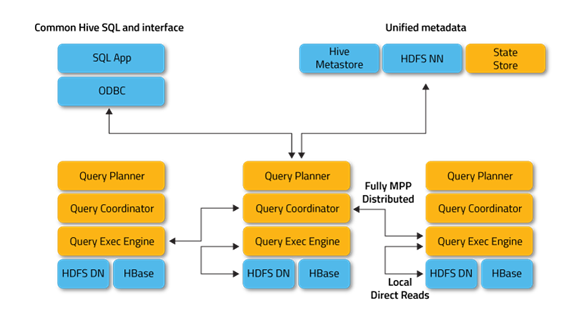
Impala Daemon is a basic service that serves to accept, process, coordinate, distribute across a cluster and execute a query. Supports ODBC and JDBC interfaces. It also has a CLI interface and an interface for working with Hue (Web UI for analyzing data in Hadoop). It is executed as a daemon on each of the cluster workers.
Impala Statestore - used to check the status of Impala Daemon instances running in a cluster. If Impala Daemon fails on any worker, then the State store notifies instances on the other workers so that requests to the instance that has gone offline are not transmitted. As a rule, works on the master node of the cluster, is not required.
Impala Catalog Server - this service is used to receive and aggregate metadata from HiveMetastore, HDFS Namenode, HBase as a structure supported by Impala Daemon. This service is also used to store metadata used exclusively by Impala itself, such as, for example, user-defined functions. As a rule, works on the master node of the cluster.
Some important for us characteristics of all databases, collected in one table on Google Docs
For the brave - the same table in the Habr format (cautiously, the Habr redesign made the more or less wide tables unreadable)
| Greenplum | Exasol | Clickhouse | Memsql | SAP Hana | Impala | |
| Vendor | EMC | Exasol | Yandex | Memsql | SAP | Apache / Cloudera |
| Used in version | 4.3.8.1 | 5.0.15 | 1.1.53988 | 5.1.0 | 1.00.121.00.1466466057 | 2.6.0 |
| Master nodes | Master segment. Reserved. | The entry point is any node. There is a license-node, reserved. | Entry point - any node | Entry point - any node | There is a master node. Reserved. | The entry point is any node. However, you need a Hive metastore server. |
| OS used | RHEL 6.7 | EXA OS (proprietary) | Ubuntu 04/14/4 | RHEL 6.7 | RHEL 6.7 | RHEL 6.7 |
| Possible iron | Any | Anyone with PXE Boot support | Any | Any | Only from SAP list | Any |
| Import from Greenplum | External http tablesPipes | External http tablesJDBC import | External http tables | CSV from SPARK local server | CSV from local server | External GPHDFS tables |
| Integration with SAP BO (source for universes) | Yes, ODBC | Yes, ODBC | No data | No data | Yes | Yes, ODBCSIMBA |
| SAS integration | Yes, SAS ACCESS | Yes, ODBC | No data | No data | No data | Yes, SAS ACCESS |
| Window functions | there is | there is | Not | there is | there is | there is |
| Distribution by node | Across the field / fields | Across the field / fields | Across the field / fields | Across the field / fields | Across the field / fieldShards spread manually on the nodes | Randomly |
| Column storage | there is | there is | there is | There is a diskNo in memory | there is | There is (parquet) |
| When there is insufficient memory when executing the request | The data is split to disk | The data is split to disk | Request falls | Request falls | Request falls | The data is split to disk |
| fault tolerance | Yes, the mechanism of mirrors | Yes, the mechanism of mirrors | Yes, at the table level | there is | there is | Yes, by HDFS |
| Mode of distribution | Open source, APACHE-2 | Closed code, paid | Open source, APACHE-2 | Closed code, free | Closed code, paid | Open source, APACHE-2 |
Test results
Description and text of test queries used in testing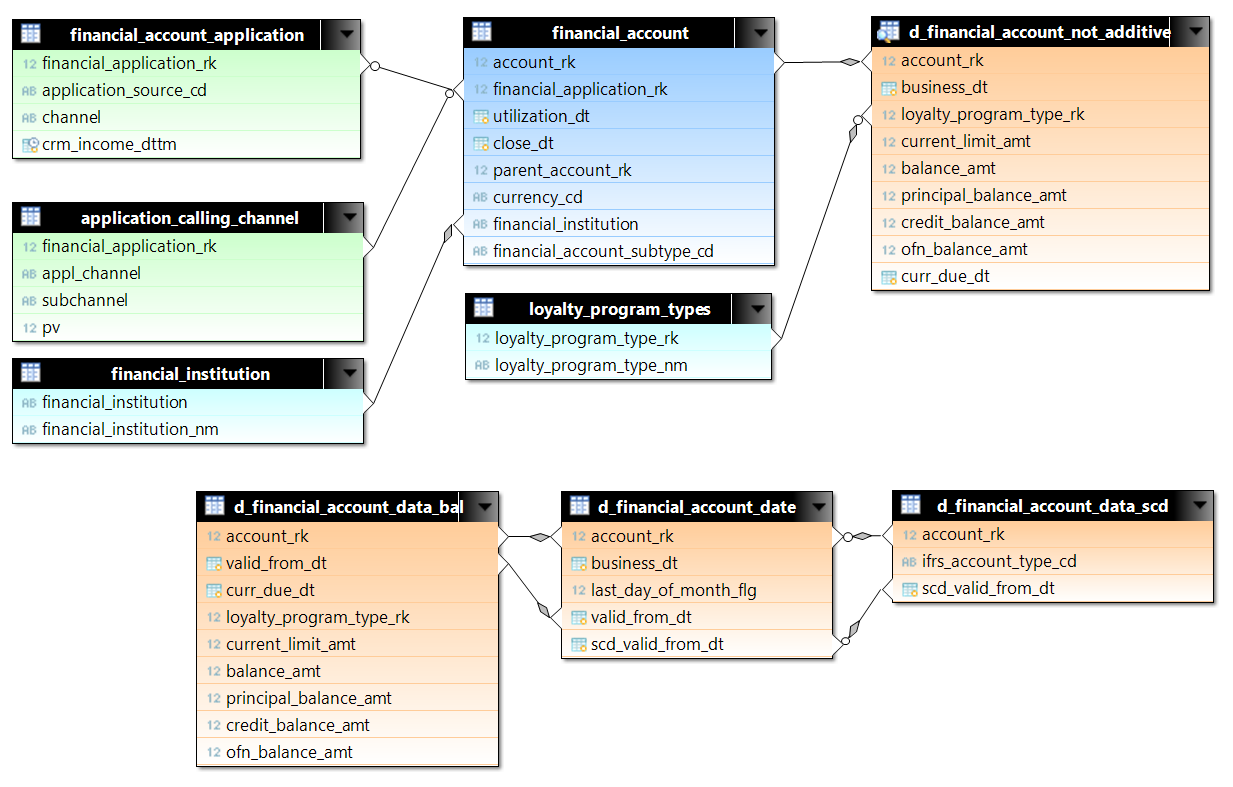
Queries with d_financial_account_not_additive were selected for testing. d_financial_account_not_additive is a view with data for each account for each day. View is made on the basis of three tables in order to optimize disk space, and, accordingly, read from disk. For testing, a part of the data on the first million accounts from the beginning of 2015 was selected. This is a little over 522 million lines. To not_additive, we attach the data on the accounts (financial_account) and on applications (financial_account_application and application_calling_channel). In Greenplum (for example), distribution tables for segments are set for tables: for accounts, this is account_rk, for applications - financial_application_rk. In queries, joins between the main tables occur in equality, so we can expect hash join, without a nested loop, when we need to compare line by line a large number of rows from different tables.
The total amount of data was about 200 GB in uncompressed form (we expect that all this volume with a small margin fits into memory).
Number of rows in used tables:
Queries with d_financial_account_not_additive were selected for testing. d_financial_account_not_additive is a view with data for each account for each day. View is made on the basis of three tables in order to optimize disk space, and, accordingly, read from disk. For testing, a part of the data on the first million accounts from the beginning of 2015 was selected. This is a little over 522 million lines. To not_additive, we attach the data on the accounts (financial_account) and on applications (financial_account_application and application_calling_channel). In Greenplum (for example), distribution tables for segments are set for tables: for accounts, this is account_rk, for applications - financial_application_rk. In queries, joins between the main tables occur in equality, so we can expect hash join, without a nested loop, when we need to compare line by line a large number of rows from different tables.
The total amount of data was about 200 GB in uncompressed form (we expect that all this volume with a small margin fits into memory).
Number of rows in used tables:
| Table | Number of lines |
| d_financial_account_date | 522726636 |
| d_financial_account_data_bal | 229255701 |
| financial_account_application | 52118559 |
| application_calling_channel | 28158924 |
| d_financial_account_data_scd | 3494716 |
| financial_account | 2930425 |
| currency_rates | 3948 |
| dds_calendar_date | 731 |
| loyalty_program_types | 35 |
| financial_institution | five |
Request N1
SELECT date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm, d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, case when d_financial_account_not_additive.ofn_balance_amt <0 then 1 else 0 end, loyalty_program_by_day.loyalty_program_type_nm, financial_account.currency_cd, sum(d_financial_account_not_additive.balance_amt*Table__14.rate), sum(d_financial_account_not_additive.balance_amt) FROM prod_emart.loyalty_program_types loyalty_program_by_day RIGHT OUTER JOIN prod_emart.d_financial_account_not_additive d_financial_account_not_additive ON (d_financial_account_not_additive.loyalty_program_type_rk=loyalty_program_by_day.loyalty_program_type_rk AND loyalty_program_by_day.valid_to_dttm > now()) INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk) INNER JOIN ( SELECT r.currency_from_cd, r.currency_to_cd, r.rate, r.rate_dt FROM prod_emart.currency_rates r WHERE ( r.currency_to_cd='RUR' ) union all SELECT 'RUB', 'RUR', 1, d.calendar_dt FROM prod_emart.dds_calendar_date d ) Table__14 ON (Table__14.currency_from_cd=financial_account.currency_cd) WHERE ( Table__14.rate_dt=d_financial_account_not_additive.business_dt ) AND ( d_financial_account_not_additive.business_dt >= to_date(( 2016 - 2)::character varying ||'-01-01', 'YYYY-MM-DD') AND d_financial_account_not_additive.business_dt <= (current_date-1) AND financial_account.financial_account_subtype_cd IN ( 'DEP','SAV','SVN','LEG','CUR' ) ) GROUP BY date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt), d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, case when d_financial_account_not_additive.ofn_balance_amt <0 then 1 else 0 end, loyalty_program_by_day.loyalty_program_type_nm, financial_account.currency_cd Request N2
select count(*) from (SELECT date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm, d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, loyalty_program_by_day.loyalty_program_type_nm, application_calling_channel.appl_channel, case when ( financial_account_application.application_product_type )='010222' then 'Y' else 'N' end , case when ( financial_account_application.application_product_type )='020202' then 'Y' else 'N' end, case when financial_account.parent_account_rk is null then 'N' else 'Y' end, prod_emart.financial_institution.financial_institution_nm, sum(d_financial_account_not_additive.principal_balance_amt), sum(d_financial_account_not_additive.interest_balance_amt), sum(d_financial_account_not_additive.f2g_balance_amt), sum(d_financial_account_not_additive.f2n_balance_amt), sum(d_financial_account_not_additive.overdue_fee_balance_amt), sum(d_financial_account_not_additive.pastdue_gvt_balance_amt), sum(d_financial_account_not_additive.annual_fee_balance_amt), sum(d_financial_account_not_additive.sim_kke_balance_amt) FROM prod_emart.loyalty_program_types loyalty_program_by_day RIGHT OUTER JOIN prod_emart.d_financial_account_not_additive d_financial_account_not_additive ON (d_financial_account_not_additive.loyalty_program_type_rk=loyalty_program_by_day.loyalty_program_type_rk AND loyalty_program_by_day.valid_to_dttm > now()) INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk) LEFT OUTER JOIN prod_emart.financial_account_application ON financial_account.financial_application_rk=financial_account_application.financial_application_rk LEFT OUTER JOIN prod_emart.application_calling_channel on financial_account.financial_application_rk=application_calling_channel.financial_application_rk LEFT OUTER JOIN prod_emart.financial_account parent_account ON (financial_account.parent_account_rk=parent_account.account_rk) LEFT OUTER JOIN prod_emart.financial_institution ON (financial_account.financial_institution=financial_institution.financial_institution) WHERE ( d_financial_account_not_additive.business_dt >= to_date('2014-01-01', 'YYYY-MM-DD') AND d_financial_account_not_additive.business_dt <= (current_date-1) AND ( financial_account.financial_account_subtype_cd IN ( 'CCR','INS','CLN','VKR','EIC' ) OR ( financial_account.financial_account_subtype_cd IN ( 'PHX' ) AND ( parent_account.financial_account_subtype_cd Is Null OR parent_account.financial_account_subtype_cd NOT IN ( 'IFS' ) ) ) ) ) GROUP BY date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt), d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, loyalty_program_by_day.loyalty_program_type_nm, application_calling_channel.appl_channel, case when ( financial_account_application.application_product_type )='010222' then 'Y' else 'N' end , case when ( financial_account_application.application_product_type )='020202' then 'Y' else 'N' end, case when financial_account.parent_account_rk is null then 'N' else 'Y' end, financial_institution.financial_institution_nm) sq Request N3
SELECT date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm, d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, case when ( prod_emart.financial_account_application.application_product_type )='010222' then 'Y' else 'N' end , d_financial_account_not_additive.risk_status_cd, case when financial_account.utilization_dt<=d_financial_account_not_additive.business_dt then 1 else 0 end, case when ( d_financial_account_not_additive.current_limit_amt) > 0 then 1 else 0 end, prod_emart.financial_institution.financial_institution_nm, --sum(d_financial_account_not_additive.credit_balance_amt), sum(d_financial_account_not_additive.principal_balance_amt), sum(d_financial_account_not_additive.current_limit_amt), count(d_financial_account_not_additive.account_rk), sum(case when d_financial_account_not_additive.current_limit_amt > 0 then d_financial_account_not_additive.principal_balance_amt / d_financial_account_not_additive.current_limit_amt end) FROM prod_emart.d_financial_account_not_additive INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk) LEFT OUTER JOIN prod_emart.financial_account_application on financial_account.financial_application_rk=prod_emart.financial_account_application.financial_application_rk LEFT OUTER JOIN prod_emart.financial_institution ON (financial_account.financial_institution=prod_emart.financial_institution.financial_institution) WHERE ( d_financial_account_not_additive.business_dt >= to_date(( 2016 - 2)::character varying ||'-01-01', 'YYYY-MM-DD') AND d_financial_account_not_additive.business_dt <= (current_date-1) AND financial_account.financial_account_subtype_cd IN ( 'CCR','CLN','VKR','INS','EIC' ) AND case when financial_account.close_dt<=d_financial_account_not_additive.business_dt then 1 else 0 end IN ( 0 ) ) GROUP BY date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt), d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, case when ( prod_emart.financial_account_application.application_product_type )='010222' then 'Y' else 'N' end , d_financial_account_not_additive.risk_status_cd, case when financial_account.utilization_dt<=d_financial_account_not_additive.business_dt then 1 else 0 end, case when ( d_financial_account_not_additive.current_limit_amt) > 0 then 1 else 0 end, prod_emart.financial_institution.financial_institution_nm T1 Request
SELECT count(*) FROM ( SELECT * FROM prod_emart.d_financial_account_data_bal ) ALL INNER JOIN ( SELECT * FROM prod_emart.d_financial_account_date ) USING account_rk, valid_from_dt T2 Request
SELECT count(*) FROM prod_emart.d_financial_account_data_bal a JOIN prod_emart.d_financial_account_date b ON a.account_rk = b.account_rk AND a.valid_from_dt = b.valid_from_dt LEFT JOIN prod_emart.d_financial_account_data_scd sc ON a.account_rk = sc.account_rk AND b.scd_valid_from_dt = sc.scd_valid_from_dt; D1 (Cartesian product of one column)
-- - 291 157 926 408 select count(*) from (SELECT * FROM WRK.D_FINANCIAL_ACCOUNT_DATE) t1 INNER JOIN (SELECT * FROM WRK.D_FINANCIAL_ACCOUNT_DATE) t2 on t1.account_rk = t2.account_rk; D2 (Cartesian product of several columns)
select count(*) ,sum(t1.last_day_of_month_flg - t2.last_day_of_month_flg) as sum_flg ,sum(t1.business_dt - t2.valid_from_dt) as b1v2 ,sum(t1.valid_from_dt - coalesce(t2.scd_valid_from_dt,current_date)) as v1s2 ,sum(coalesce(t1.scd_valid_from_dt,current_date) - t1.business_dt) as s1b2 from prod_emart.D_FINANCIAL_ACCOUNT_DATE t1 INNER JOIN prod_emart.D_FINANCIAL_ACCOUNT_DATE t2 on t1.account_rk = t2.account_rk; Results are in seconds.
| Request | Greenplum | Exasol | Clickhouse | Memsql | SAP Hana | Impala |
| N1 | 14 | <1 | - | 108 | 6 | 78 |
| N2 | 131 | eleven | - | - | 127 | Error |
| N3 | 67 | 85 | - | - | 122 | 733 |
| T1 | 14 | 1.8 | 64 | 70 | 20 | 100 |
| T2 | 17 | 4.2 | 86 | 105 | 20 | 127 |
| D1 | 1393 | 284 | - | 45 | 1500 | - |
| D2 | > 7200 | 1200 | - | > 7200 | Error | - |
Identified nuances in the database
Yandex Clickhouse
During testing, it turned out that this database is not suitable for our tasks - joins are represented only nominally in it. For example:
- only JOIN is supported with the subquery as the right side;
- conditions in join-e are not thrown inside the subquery;
- distributed join-s are performed inefficiently.
It turned out to be almost impossible to rewrite the "heavy" queries (N1-N3) on the Clickhouse syntax. It also saddens the memory limit - the result of any of the subqueries in any query should fit into memory on one (!) Server from the cluster.
Despite the fact that this database was unsuitable for BI tasks, according to test results, it found application in a repository in another project.
Separately, I would like to highlight the very detailed and user-friendly documentation available on the official website (unfortunately, so far it does not cover all aspects of using the database), as well as to thank Yandex developers for the prompt answers to our questions during testing.
SAP HANA
The main part of setting up servers and query optimization was made by colleagues from one consulting company, which are representatives of SAP in Russia. Without them, we would not be able to look at the base and evaluate its advantages: as experience has shown, experience with HANA requires experience.
HANA showed itself very interestingly when counting the number of rows for the join itself on the table itself:
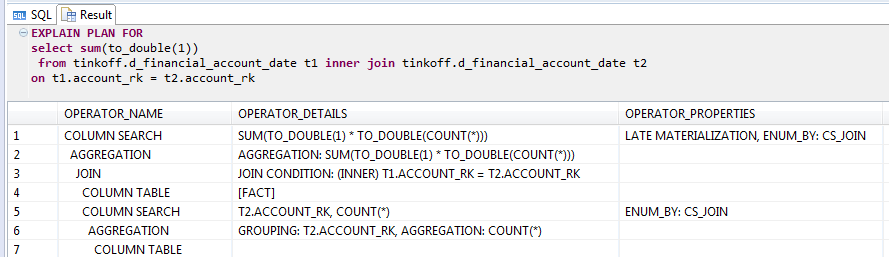
EXPLAIN query with join table with itself at HANA
The optimizer calculates the result using statistics without even joining. Not a bad trick, but if in a where to add a condition that is always True, for example “1 = 1”, the trick will not work and we will get 25 minutes, almost as many as in Greenplum.
At the current time, HANA does not know how to place intermediate results of queries on disk during the execution of a query. Therefore, if there is not enough memory, the session ends and the user is left without results.
As it turned out during the testing process, even if the data of the two tables participating in the join-e are distributed among the nodes of the cluster correctly, the join in fact is executed only on one node of the cluster. Before executing the request, data from the entire cluster is simply poured into one node, and the join-a is already there. For the time allotted for testing, this logic could not be overcome and the join could not be executed locally.
By the way, the manufacturer recommends, if possible, to use the single-mode configuration of the database, which is confirmed by the results of our testing - making the configuration of two machines work optimally many times more difficult than from one.
Exasol
The main impression of working with the base is very fast and surprisingly stable, right out of the box. Almost all of our tests show an advantage in speed compared to other DBMS. However, unlike many other DBMSs, this is a black box - you cannot even connect to the ssh node and run iotop, htop, and so on.
The lack of control of their own servers, of course, forces to strain. Although in fairness it should be noted that all the necessary data on the operation of the base and the load on iron is in the system view inside the base.
There are JDBC, ODBC drivers, excellent support for ANSI SQL and some specific features of Oracle (select 1 from dual, as an example). JDBC-drivers for connecting to external databases (Oracle, PostgreSQL, MySQL and others) are already built into the database, which is very convenient for loading data.
EXASOL allows you to see the plan only completed requests. This is due to the fact that the plan is created on the fly during execution due to the analysis of intermediate results. The lack of a classic explain does not interfere with the work, but is more familiar with it.
Fast, comfortable, stable, does not require long tuning - set and forget. In general, some kind of all correct. But the black box is alarming.
Separately, I would like to note the adequacy of support, which promptly answered absolutely all of our questions.
Memsql
Put simply and quickly. Admin is beautiful, but not very clever. Examples: you can add nodes to the cluster, but you cannot / remove / unclear from the admin panel; You can see the current and completed requests, but no details about them can be seen.

You can tweet the number of records per second in the admins memsql
When working, MemSQL loves to load processors, there were almost no memory overflow errors.
MemSQL, before joining two tables, does repartitioning (redistributing data across nodes) using the join join key.
In our case, we can store the data_bal table and date with a complex shard key (account_rk, valid_from_dt), for the scd table, the sharding key will be (account_rk, scd_valid_from_dt). In this case, the connection between data_bal and date will occur quickly, then when the query is executed, the data will be redistributed to account_rk and scd_valid_from_dt, and in the next step, by account_rk to connect to the financial_account table. As support says, repartitioning is a very time consuming operation.
Thus, our requests were heavy for the database due to the large number of diverse join-s. In Greenplum, joins between the listed tables occur locally, and, accordingly, faster, without redistribution over the nodes, the so-called Redistribute Motion.
In general, MemSQL seems to be an excellent database for migrating from MySQL and not the most complicated analytics.
Impala
The installation of the Cloudera cluster, which includes Impala, is fairly simple and well documented.
However, it is worth noting that the performance of Impala relative to other databases did not differ - for example, a query that counted count (*) in d_financial_account_not_additive, worked in Impala for 3.5 minutes, which is significantly more than that of rivals whose results are tens of seconds and less.
We also conducted an interesting experiment: as was written earlier, in view d_financial_account_not_additive there are two join-a. In each of them, the account_rk is connected with the integer data type, and also along the date data type fields. Impala does not have date data type, so we used timestamp. For the sake of interest, a timestamp was replaced with a bigint in which the unix timestamp was stored. The result of the query immediately improved for a minute. In the next step, the data from the account_rk and the date fields, this is valid_from_dt and scd_valid_from_dt, were combined to provide a join for only one field. This was done in an uncomplicated way:
account_valid_from = account_rk * 100000 + cast(unix_timestamp(valid_from_dt)/86400 as int) Join one field gave us about half a minute more gain, but in any case it is several times more than other DBMS.
Basic queries worked several times longer. N2 request fell due to lack of memory, so there are no results for it.
Impala hash-, .
Instead of conclusion
« - -, —
, , , BI-.
, :
—
— (aka 4etvegr)
—
— (aka kapustor)
, , Virtua Hamster ( Sega 32).
Source: https://habr.com/ru/post/310620/
All Articles