What is special about DBMS for in-memory data?
Konstantin Osipov ( kostja )

How was the idea of the report born? I do not like to speak and talk about features, especially about future features. It turns out that people do not particularly like to listen to it. They love to hear about how things work. This is a report on how everything is arranged or should be, from my point of view, arranged in a modern DBMS.
I will try to make it so that we can go down to the micro level from the macro level, i.e. in which way, by first discarding macro problems, we can create a space for ourselves to choose at the middle level and at the micro level.
')

At the macro level, this is how a modern DBMS should be arranged. Why do we have the opportunity today to create new databases, why it is impossible to take the current one and be satisfied with its performance, podtyunit or write a patch for it? Just pick up and write a patch to speed it up if it's slow? What decision space do we choose from?
Further, after we have fixed some basic architectural principles, we need to go down below and talk about engineering. Besides the fact that there are databases that process transactions using multiversional version control, databases that process transactions using locks, how you implemented this algorithm (relatively speaking, how direct you are) directly affects performance. If the first factor gives you dozens of times the scaling of productivity growth, the second factor gives you 2-3 times, but it is also important, because when later with your decision comes on the scene, you will not be ashamed that the same Redis, although it is structurally simpler, It does not make you like a Tuzik hot-water bottle, because, despite the fact that there are a million features, you do not sag in performance, etc. This is engineering.
The second part of the report is about the algorithm and data structure, i.e. how we fix some basic engineering approaches, work with threads, etc. And we say how we implement the data structures that would be the fastest and would allow to process and store the data fastest and most qualitatively.
The 3rd and 4th parts are the most furious, because there I try to at least tell the top about our algorithms and data structures that we have implemented.
DBMS architecture. Where to start? Why there is a window of opportunity in 2015 for a modern database.

Let me remind you of the basic requirements, this is the space in which we can play. There are ACID requirements that we must meet. Any database that believes that it can skip ACID, in my opinion, is not subject to serious consideration, i.e. this is such an odd job on the knee, because sooner or later it becomes clear that you need not to lose the data you are given, you need to be user friendly, you need to be consistent, etc. This is an academic definition, but in fact, even in ACID, on such a small slide there are abysses, i.e. You can talk about it for 2-3-4 hours.
What is DURABILTY? I always, when I argue about this, say what DURABILTY is in terms of nuclear war. Is your database DURABLE in the event of a possible enemy attack? Or ISOLATION - what is it? Why do we say that we want the visibility of two transactions not to affect each other? And what if I'm a cunning guy, I have 2 laptops, I connected from one laptop and from the other. In one laptop, I told begin, insert, then I looked at what I put in there, on the basis of this I made a decision, in the second I made a begin, insert already the data that I looked at with my eyes. How cunning I am, I deceived ISOLATION. Are there any guarantees? But, nevertheless, these are the rules of the game.
And one of them, the most fundamental, which seriously affects performance, is Isolation. Why? Because isolation of transactions from each other is such a thing that affects so many things at once. Those. you can make it so that someone reads his version of the data and does not interfere with another person (how Postgres, MySQL works with InnoDB). But as soon as it comes to recording, then we have a dilemma. We have no way to ensure the isolation of two participants who are trying to update the same data and at the same time completely isolate each other from an algorithmic point of view.

We need in one form or another to signal to another participant that at the same time someone else is working with this data. This is formalized in theory through the concept of a schedule (I gave an example of a schedule). We have data items, i.e. X and Y are our data, 1 and 2 are our participants, r and w are the designation of operations. Participants read or write data, E is the schedule according to which they work.

Ultimately, the only impressive way to provide isolation is blocking, i.e. The foundation for databases of 20, 30 years ago was that they were based around a two-phase lock theorem.

Those. we say that in order to achieve a serial schedule, participants must lock locks on the objects that they change. At the same time, there is a multi-version competition control, which allows us in some cases to avoid these locks or to postpone their locks, i.e. at the end, at the time of commit, we can already check, validate in some way that integrity has not been violated. Those. locks are not strongly affected by participants, but, nevertheless, even in multiversioned competition control, such algorithms require locking on non-existent objects in certain scenarios. The strictest serialization mode is called serializable in classic DBMSs, you still need to lock locks there.

This is a fundamental mechanism, and it is fixed in the academic community through the two-phase blocking theorem, which is more or less fundamental; we need to accumulate these locks. Classic DBMS built around this scheme.

In addition, classic DBMSs were originally built in the universe, where the “disk-memory” ratio is completely different, not the same as it is now. Relatively speaking, it was possible to have 640 KB of memory and a 100 MB disk - and that was good. Those. the ratio is somewhere 1 to 100. Now the ratio is often 1 to 1000, i.e. these relationships have changed. And the speeds have changed even more radically, i.e. if before the RAM was only 100 times faster than the disk, now it is 1000 or 10,000 times faster than the disk. There was a radical change in the ratios from which one had to choose.
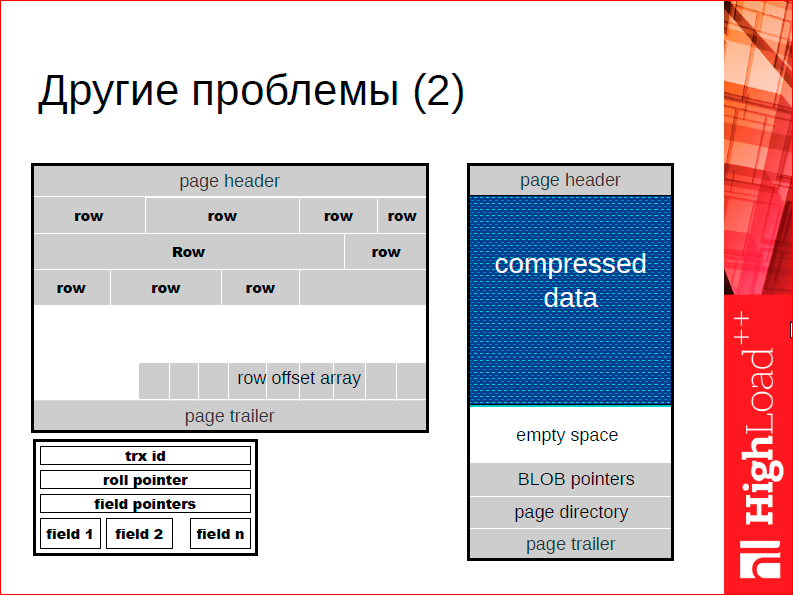
A classic example of why this matters is that classic DBMSs are built on the principle of two-level storage, i.e. you have some kind of data representation on disk and you have a data representation in memory. Memory actually caches your view on disk. You inevitably need to tradeoff between working effectively with the disk and working effectively with the memory.
In particular, to work effectively with the disk ... Pay attention to the white space on the slide - this is a typical page of a typical DBMS that stores lines. Usually the page is under-filled, because our disk space is not expensive, and the cost of writing to a disk does not grow in proportion to the size we write, but in proportion to the number of disk accesses. Accordingly, it makes sense for us to have holes on the disk, because it’s not scary, we will write this hole, and it’s not worth writing a hole.
In memory, the story is completely different. There it is important that the data take up as little space as possible, because the cost of the calls is more or less the same. RAM has a more or less the same price of random access, respectively, it makes sense for us to make things as compact as possible. One of these factors is that if you make a DBMS for RAM from scratch, then it makes sense for you to reconsider more or less fundamental algorithms and data structures you are doing, i.e. you can get rid of these holes - this is just one example.
By the way, if we talk about this example, it turns out an interesting story. Many people say: “Why do we need DBMS X, we use DBMS Y and just add memory to it”. I have seen such scenarios when people take databases that are intended for secondhand storage, i.e. for MySQL, Postgres, Mongo disk base, they give it a certain amount of memory, they all fit into memory, and they are happy. Only economic calculation is immediately flawed here, because if you make a database in memory, then a typical memory footprint, i.e. the amount of memory used can be many times less simply due to the fact that there are not all of the overheads associated with disk storage. Economically, it is wrong to take a DBMS that is designed to be stored on a disk, throw out money and put all the data in memory.

My such inventions are not based on nothing. In 2008, an article of one of the classics of the world of the DBMS was published, with an analysis of the activities that the DBMS carries out in different subsystems, i.e. how many percent of the effort and what accounts for the DBMS. The main blocking subsystems were highlighted, latching is the same blocking, but only at a lower level, when we need to block not data, but processes that interact with each other. And this article concludes that only 12% of modern DBMS spends on useful work, everything else it spends on these magic letters ACID and on interaction with outdated architectures, i.e. to work, built on the principle of outdated architectures. It is from this graph that this window of opportunity comes, which allows you to speed up the DBMS ten times at the same time without losing the functionality or without significant loss of the functionality.
How can we get rid of all these locking, letching, etc. pieces? How can we get rid of the overhead projector on transferring data from memory disks and changing the presentation formats? Here are the bases that I wrote out and which formed the basis of the Tarantool architecture:

In fact, this is not a unique architecture. If you look at Memcached, on Redis, on VoltDB, it turns out that we are not the only ones, i.e. then we take and start to compete, relatively speaking, in our league. We are leaving for our league, in which we say that:
- we have 100% of the data stored in RAM,
- we execute transactions sequentially so that we don’t need to take locks; we do not have the very concept of locking, we just give the amount of RAM that we have allocated for the transaction, it exclusively uses them, then we perform the following transaction.
We, all the same, say that we will shard the data, i.e. we have horizontal scaling - this is the norm, so we are not even trying to make the database work efficiently on one machine. One machine today is still a super computer. 48 cores that have different cost of accessing RAM, i.e. if you are accessing one site from one core - you have one price, to the same site from another core - you have another cost of circulation. This is a supercomputer, and to say that efficient work on one computer is the same task that 10-20 years ago is no longer necessary, therefore we will not solve this problem at all.
There is one interesting point in this whole story. We say that we have in memory a DBMS that performs transactions sequentially. What is going on? If during the execution of a transaction we need not to lose data, we must write them to the log, i.e. this work we can not cancel. We have a log, the log is stored on disk. If we write each transaction to the log, one by one, we will all the same rest on the performance problem, because the disk is slow, i.e. the fact that we use little CPU doesn't give us anything, the disk is slow. We need to figure out how to write a journal in large volumes, 100 each, 1000 transactions at a time, then we will be able to spread this cost of writing to multiple transactions and increase the fragmentation, i.e. bandwidth. We will not increase productivity in this way, i.e. for each latency transaction, we will remain the same and will correspond to the cost of writing to disk, but we can increase the volume and throughput.

There is a problem: how to roll back transactions if a log entry failed? I, in principle, did not encounter these technologies in the literature, but in Tarantool the analogy associated with the film is used. Suppose we have a transaction that is already completed in memory, and we need to write it in a log. This transaction waits for its turn until the slow disk writes it. At this point, another transaction arrived that reads or updates the same data. What to do with it? Prohibit her from running? If we forbid it to run, our performance will drop dramatically. If we allow it to run, it may be that the transaction, which is waiting for its turn, did not register, the disk space has run out. What should we do then? Roll back. \
Rollback in Tarantool is arranged according to the principle of reverse promotion, i.e. all transactions are executed in optimistic mode, one after another, without expecting each other. As soon as some error occurs, the error occurs much later, some time after the transaction has been executed in memory. We stop our conveyor and spin it in the opposite direction. We throw out everything that actually saw the "dirty" data and restart the pipeline. This is an insanely expensive operation. It may be that 10,000 transactions are lost under heavy load, but since it happens extremely rarely (in operation it never happens), you just watch the place on the disk.
Well, “never” is categorical, but in fact, if you follow the equipment, it does not happen. This is the cost to go. And in general, in general, when designing a system, you need to design it around the most likely scenario. If you are trying to make the cost of architectural decisions the same, simply list: what if there is a rollback, what if there is a commit, what if there is something else? .. If the code corresponds to this, then most likely you will not build an effective system, because you will on a worse occasion, evaluate yourself.
Fixing so these basic principles, we turn to the aspects of engineering. What I want to say about engineering.

At the conference there will be a report about the database in memory, it is called ChronicleMap, and ChronicleMap is interesting because the goal that the engineers of this DBMS set for themselves is to achieve microsecond latency for updating the DBMS. The task was primarily to update took much less time. In our case, the situation is slightly different. And we solve this tradeoff in another favor. What is this about? Imagine that you need to get to the conference, and there are no traffic jams, what do you get? You take a taxi and it will be faster. You use public transport - it will be cheap. Why is public transport cheap? Because it smears the cost of many participants. Carriage occurs, i.e. you and everyone share the cost of exploitation. And in our case, the goal is exactly that.
If other DBMSs have the task, for example, to have very low latency, but perhaps not the maximum throughput, i.e. bandwidth, in our situation, we said that the latency that RAM gives us is enough for us - this is, let's say, a few milliseconds to process a single request. This is the parameter we want to access and otherwise we want to optimize throughput, i.e. bandwidth. We make the maximum number of requests share the costs between them. What does this mean from the point of view of engineering?
We have a slow network, and the network is, in fact, expensive. It is expensive to exchange, because we live in the ancient world of operating systems forty years ago, and there is no way to go online without looking into the core. We have a disk, which is also very expensive, the disk recording itself is slow, but we need to write the disk, because this is the only way to save data so that they can survive the power failure. We also have a transaction processor that runs in one thread and performs transactions one by one, i.e. The transaction processor is our pipeline. How can we make this pipeline idle minimally?
If we have a pipeline for each request will go to the network, then go to disk, and most likely it needs to be done 2 times, i.e. he needs to read the request, process it, write to disk, respond, give the result to the client. Those. we access the network 2 times, once on a disk. All this confusion will take a very long time. We need to make sure that we read from the network as quickly as possible, with respect to one request - as cheap as possible. What are we doing for this? We say that our protocol is completely asynchronous, we are working in pipelining mode, i.e. we can read requests from multiple clients from one connection and respond to all customers simultaneously. Those. each client receives his answer, we multiply all of this on one socket and our pipelaying goes on every level, i.e. pipelining at every level of work. And this is a very significant tradeoff around which the database is built. Therefore, we work in the same thread, so we give lower latency than any other solutions that are small-tredad, but due to this we reduce the costs for one request.

From the point of view of implementation, it is necessary to find a way of parallelizing the paradigm in which we will exist, in which we will parallelize all this. This paradigm is one of the following.

We actually have to choose one of these. If we say that we have competitive threads, we somehow exchange information between these threads, we need to choose a way to share.
Why is this especially important in our case? Because the choice of the exchange method between threads affects not only these costs, which are more or less obvious - going to the core, going to the disk, going to the network, but it has such implicit things, for example, how often we flush the cache, the processor's cache, those. do we work well with cache or badly? And given that this happens implicitly, in fact it’s a search in the fog. Something changed - the cache started to work a little better, your performance increased slightly.
In fact, we now live in what world? In addition to this large RAM, which we are dealing with, we have from 16 to 32 MB of cache of the 3rd level, which is divided between all cores, and the more effectively we begin to use the cache of the 3rd level, the better we will work . Thus, our task is to make the 3rd level cache work, work efficiently.
Here, we have such a choice (see the slide above), and if we are talking about paradigms, we have to choose some kind of paradigm in which all of this is coded.
Looking ahead, I will say that we have chosen the last paradigm - this is an actor model, why?

What can be said about lokok? I programmed using mutexes my entire adult life is a great tool. One of the significant problems of mutexes for effective programming is the problem of composability. What is it about? Imagine that you have a critical section that you, for example, insert into a competitive data structure. The data structure works with a bunch of threads. You take this critical section, encapsulate it in some method. You have an insert method in some kind of competitive data structure. Then you have a certain macrostructure that uses this data structure, and it should also work in the critical section, i.e. it must also be competitive. Locks do not allow you to simply take and call one method from another, you have to think 10 times, why? It will not lead to deadlocks or to any other problems that I have described here. Where can it all come from? You simply cannot arbitrarily use code that uses locks from one another; you lose the main programming property, when we can perform encapsulations, add composites to smaller ones. In fact, wait-free algorithms solve one problem - the problem of deadlocks. Wait-free algorithms do not slow down, because they do not wait. But they do not solve other problems? related to algorithms? built around the lock pattern.

Dedlock is a waiting cycle. We use locks in order A, B from some place in the code, we use locks in order B, A. from another place in the code! Opa! And we have all collapsed under load - deadlock.
What are escorts and hotspots? This also applies to wait-free algorithms. What is the problem? You wrote your program under the assumption that this critical section works with two threads. For example, it has a producer-thread, a consumer-thread, these threads access this critical section on average ... Suppose they have a load of 1000 requests per second. Accordingly, they access the critical section 1000 times per second - everything works for you. Then your circumstances change. The iron changes or the work that the threads perform changes, or the environment with which they work, i.e. you have yet unknown in this system. We are talking about composability, i.e. you begin to expand and tune the system, and your critical section suddenly becomes hot. Suppose some small thing, which actually updates two variables under the critical section, but it starts to twitch, not 1000 times a second, as you planned, but 10,000 times a second, 100,000 times a second, and there is a constant struggle around it, threads are removed from management, etc. What could happen next?
You can try to play with priorities or order, i.e. You say that some requests are more priority, some less priority. This may lead to the fact that more priority requests to the critical section begin to crowd out less priority ones. Lower priorities are never fulfilled - this is starvation.
Convoying is just the situation when you have a small critical section nested in a large one and because of this you cannot get through to a small critical section.
There are many different situations that are expressed in one way or another in one conclusion - locks are not composable. The system is written around locks and, if it is the main primitive of programming, scalable systems cannot be built from this.
It was clear not only to me, but also to the creators of Erlang, who made him 30-40 years ago. By and large, if we talk about the tool on which Tarantool should be written, this tool is probably called Erlang.

In general, one of the approaches that can solve the problem of composability is the functional programming approach, where critical sections are not explicitly defined, and during execution, parallelisms are determined based on functional dependencies. In other words, you never take any locks anywhere, but if you have the same function is a functional dependence on another, then you can parallelize its execution transparently for the author.
This is used by all sorts of functional languages that can do this quite well. You do not have shared data, and therefore you do not have conflicts over common data, i.e. functional programming, sort of, fits.
But, unfortunately, if we talk about system programming, i.e. To marry a functional approach and system programming, we do not have the environments on which to base ourselves.
Thus, we come to the model, which I started at the very beginning, which is exactly what we need to stop at, which allows us to make a composite system and make it cheap.

What is attractive about the Actor model? messaging model between independent participants? We have a single-track system, this system already has cooperative multitasking, i.e. at the level of a single thread, we created microflows, which are linearly executed, and they can interact with each other as if through common memory, because there are no problems there, but they can also interact with each other through sending messages.
It remains for us to solve the problem for interaction between threads. Let's return to the picture “Mass Message System”:
We have a Network thread, a Transaction Processor thread, a Write Ahead Logging thread, and for each request, each thread conceptually has some kind of entity - actor, actor. The task of an actor in a network thread is to take a request, parse it, analyze its correctness and send a message “execute this request” to the Transaction processor. The transaction processor takes a request, checks if there is a duplicate key there, if there is any other constraint violation, performs some triggers, inserts it everywhere, and says: “Ok” to its corresponding badi in write ahead log - write this request to disk. He takes the request and writes to disk.
In the literal sense, if we did that, we would exchange messages for each request. We want to reduce this, i.e. we in this paradigm want the entities in our program to really exchange messages, but the costs for this exchange are minimal, i.e. we need some way to multiplex the exchange. And the Actor model, because it encapsulates the exchange of messages, allows messages to be transmitted in batches. Those. we take the Actor model, we say that in order to do something, you need to send messages between the corresponding Actors in different threads, and under the hood every time a message is sent, we will correspond to the corresponding Actor, i.e. . remove it from control and transfer control to the next Actor. Thus, on the basis of corutin, in each thread, we constantly work, but also constantly switch between Actors.
Why is this central to me? I even drew a beautiful hypercube on the “Actor model” slide (see above), in which I try to emphasize the importance of just such a paradigm. What is the property of the hypercube? The fact that the number of links there grows in proportion to the number of nodes, i.e. not square, but proportional.
If we take Tarantool, then individual threads can be considered as vertices in this hypercube. We want to make the connectivity between threads low, so that we form links between threads through links between vertices. And our task is to maintain a low number of links so that the exchange is cheap.
If you recall some ancient supercomputers such as Crea, and you look at the design, it turns out that they were actually built on the principle of hypercubes. Generally, if you look at ordinary mechanical telephone switches, they are trying to solve the same problem — how to fit the multiplexing of many interacting entities into our three-dimensional space and do it efficiently. It turns out to be some kind of spatial thinking, not engineering.
Why is a 4-dimensional hypercube drawn? I spoke only about one thread and interaction in one thread, but when sharding occurs, the same problem arises - the request arrives at any node in the cluster, and this node must interact with all the nodes in order for this request to be processed. We have the same problem of quadratic growth in the number of bonds, i.e. we have n squared connections based on the number of participants. And the only way to control the number of connections is to somehow drive him into such a space.
Why is this model good in terms of a modern system? Look, if you take a typical chip, this little thing in the center is a level 3 cache:

In this sense, a dispute between fans of CISC and RISC architectures in 2015 is very interesting. I stand for ARM processors with both hands - they have better energy saving, etc., but the architecture debate makes me laugh, because, by and large, modern CPU is a huge level 3 cache, everything else is 15% of chip. The argument about which processor is more efficient in this story - the one who works with the 3rd-level cache is better, and that is effective.
Why is the Actor model good for modern iron too? If you look at access to the level 3 cache, then the less we go there, the better.Every time we have to send some message, i.e. To synchronize two competitive processes, we must somehow lock this exchange bus to ensure the consistency of the data. For example, in Intel, you change data in one process, and they will eventually change in all. Therefore, it is best for us to rarely change shared data. The idea of messaging multiplexing is exactly this — to share this cost, lock the exchange bus from 1,000 to 10,000 times per second. This is normal performance, it gives us acceptable latency of 1-2 ms to process the request, thus reducing the costs of the exchange.
Part 3 is dedicated to memory, after all, we are a DBMS in memory, and we should devote a lot of attention to memory.

Why were parts 1 and 2? I tried to show how we get down from the whole solution space to the level below.
Now we have simplified our problem - we do not have competition, we have a memory that one thread should handle. There is no memory shared between threads; all exchanges between threads occur due to the exchange of messages.
What to do next? How to make memory work efficient in one thread?
On the slide, I showed what a classic manager doesn't fit. Suppose we have our own, what are our requirements for it?

Our unique requirements, first of all, are quota support. We guarantee the user that we do not go beyond the memory allocated to us. If an error occurs, the question often arises: “do you crash if you run out of memory?”. We can, if there is an error in the code, but in general, if the memory runs out, the system stops saving data, but continues to work - give the current data. This is one of the goals.
The second goal. There is such a thing as compactification magazine. We need to periodically flush all our snapshot, all our memory to disk in order to speed up the recovery, i.e. for this we need consistent snapshots of memory. Moreover, we need consistent snapshots if we want to support so-called interactive transactions, i.e. The transaction that started on the client works, if we want to do the classic multiversion concurrency control, then we also need consistent snapshots.

Allocators of memory in this one thread are arranged according to a certain hierarchy, and the top of the hierarchy is the supplier of memory a level lower. Our approach is that we try to encapsulate as little as possible when working with memory, i.e. we provide a DBMS programmer with a set of tools suitable for the respective situations. At the top of the hierarchy is an object that is global, in principle, there may be a lot of them, we now have two of them - a memory (quota) for data and a quota for runtime.
The quota for runtime is not limited now, but it can be set. The global object at the top of the hierarchy is the quota. A quota is a very simple object in which two quantities are stored — the amount allowed to users and the current volume consumed. This is a competitive object, and it is divided between these three threads.
The quota user is the so-called arena. The arena looks like this:

In fact, this is a memory manager that can only work with very large chunks of 4 MB of memory. In this case, the task of the arena is to supply the memory levels below. The arena is designed so that you can also work with it from a variety of threads, i.e. one arena can be a source of memory for many threads. She is competitive. And, in fact, the main function that is performed is the management of the address space. We want the address space to be aligned and not fragmented, so at the start, we will attach a certain amount of address space, but we can also go beyond this attached volume, if the quota has been increased after the start.
The next level (and this is the first level that works at the level of each thread) is the slab cache. The arena can only work with slabs of the same size, and in fact this is the maximum size. Such a variable as the maximum amount of data that you can put into the system depends on the size of the arena. Those.If you have a tapl takes 8 MB, then you need to increase this thing. The current restriction is not very beautiful, I will tell you how we are going to remove it.
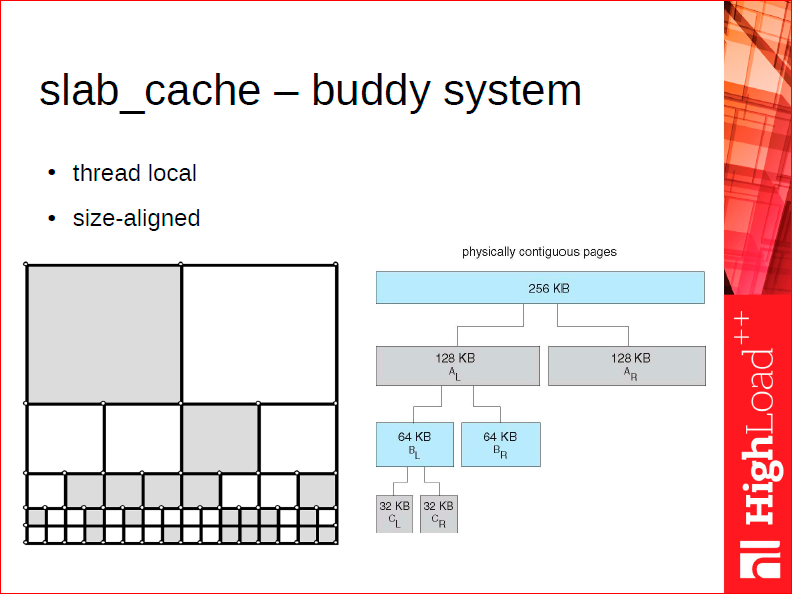
Often, such large chunks of memory are not needed; small pieces are needed for some lower level allocators. To do this, we have a thread local allocator, which calls slab_cache, and which works on the so-called buddy system.
The principle of the buddy allocator is as follows. During allocation, a very serious problem is the problem of memory fragmentation after we allocated a bunch of memory, then it was freed, i.e. we have partially filled pieces. Let's say here is our big 4 MB slab, which we are starting to use. Buddy slab_cache can only return chunks that are a 2-kb power from 2 Kb to 4 Mb in the default case. Its advantage is that when you return a piece, i.e. You used it and returned it, he knows how to find his neighbor - buddy. If the neighbor is also free, he unites the two neighbors, i.e. he can find and defragment memory after a deallocation in a cheap way. Thus, in general, your memory will remain defragmented for quite a long time, because while working with slab cache,we know how to slam it back.
An important point that helps in this is that we prefer addresses in a lower range of address space during allocation, i.e. when allocating, in general, at all levels, we try to find the first smallest free address. If your system has been working for a long time, after that it freed some memory, then it starts allocating more memory, we try to make the data move down the address space. This also resolves issues with fragmentation.

The lower level allocator is a classic pool allocator - object pool, which simply takes objects from the slab cache, slabs, say, 2 Kb, 4 Kb, places these slabs, and is able to allocate objects of the same size without any overhead . Its main limitation is that it does not know how to allocate objects of different sizes.
Suppose we have a connection object, or a fiber object, or a user object, which are quite hot — often localized and distributed. We want the allocation of such objects to be comparable to their allocation on the stack, and for this we use selected mempools. It is not always possible to do with the selected mempool, because it is not always the system that we know the size of the object in advance.

And specifically for the data, we use a classic slab-based allocator based on mempool, but in fact it is quite amusingly hooked up. In the classic slab allocator, the size of the object is not known at the time of distribution. We have no such limitation, we know the size of the data that we are deploying. Due to this, we can use slabs of different sizes for different sizes of the object. Look at the picture - there are objects of size 24 bytes or up to 24 bytes - for them we use, let's say, slabs for 4 Kb. Objects of size 32 are still slabs for 4 Kb, 40 are still slabs for 4 Kb, 48 are for us already using slabs for 8 Kb. Thus, we can have a lot of such size-mapping, which do not eat off the memory.
The classic problem of a regular slab allocator is that it is forced for each size to have at least one slab. Those.if you have, say, 200 standard sizes, then the size of the slab is 4 MB, you have been allocated one object in each standard size - you already have a figak! - 800 MB in memory is occupied by something, but it is not occupied, it has begun to be used. Then this system is scaled, but overall this is not a good story. Therefore, usually with classic slab allocators, these are tradeoffs between the fragmentation of the inner and the outer — how many dimensions to have are many or few. We have this tradeoff much less, we can afford to make a growth step for every 8 bytes, i.e. there is practically no internal fragmentation. For every 8 bytes we have our own slab.
Next, we made the library available regardless of tarantool. Her url - github.com/tarantool/small, please, can see the codes, it is very small, which is also, in my opinion, an advantage. Contained in itself and everything that I have not told here, you can simply rtfs.

What is another kind of allocation? We have a wonderful allocator that can not free up memory. Very nice, do not think about it - you allocate the memory and that's it. In fact, you can simply free up all the memory that has ever been allocated in this allocator - this is called a region allocator, regional, i.e. it works on the obj-stack principle. JCC has a lot of similar allocators in different systems, including open source. An important advantage of ours is that it is all built into a single hierarchy. Those.region allocator also uses slab cache as a provider for its slabs.
Why it is impossible to write such a good string class, why does each programmer write his own string class? Because many aspects are brought together: the aspect of working with memory, one of the important aspects - copying, which copying semantics, the aspect of working with symbols, etc. Those.many problems are solved by one class. Naturally, if you make such a universal tool, you cannot make it ideal for all cases.
If we look at this whole story only from the point of view of memory allocation, then how does the line, or just the buffer, differ from the allocator? Yes, nothing. How is the allocator different from the container? The container has an iteration, for some reason, the default allocator does not have it. With our allocators, you can iterate over objects, what's the problem? We know which objects are alloted and which are not. The allocator is a container, the allocator region is a string. This is a dynamically growing buffer. And in this sense, if we talk about allocation strategies, there are more or less of them a finite number, i.e. when your line is full, you can double the size of the allocated buffer, or you can use something like a rope, i.e. your string may consist of segments.Or you can never bother about freeing your memory - just copy the memory to a new place and take it easy. So does realloc - he discovers that “I still have a“ tail ”that is defragmented overhead, and which I can use, and I will not do any reallocation.” Those.you have a fixed number of strategies. And for this fixed number of strategies for working with buffers, we just made three structures. This is all done in C, which implements these strategies, i.e. doubling with growth, segments and just copying to a new place.
Thus, we have such a foundation. We come to the fact that on this foundation we can build the structures in which we will store data and proceed to the 4th part of our report. The most subtle, highlight, as you can see, is present. What is it going to be about here?
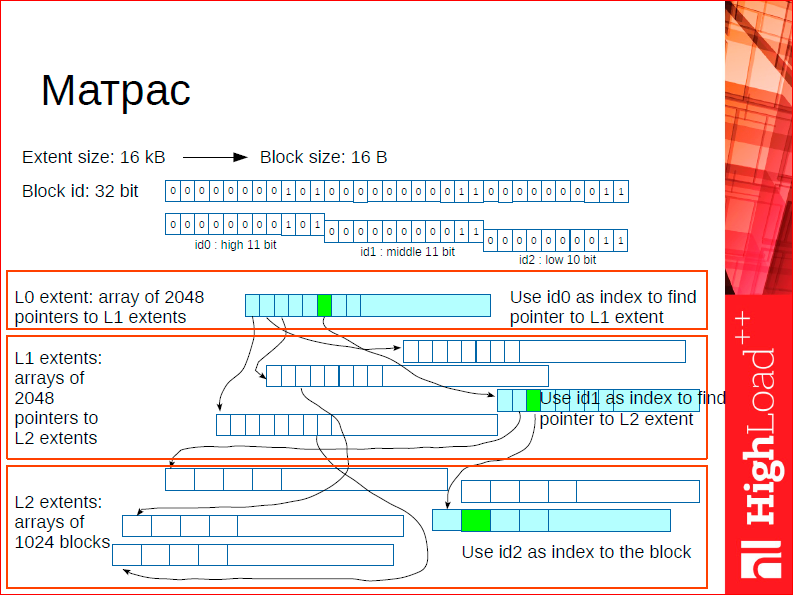
There is one data structure that is located on the border between the container, the allocator, and the tree — for some reason, this data structure is called the mattress. Why mattress? This is such a clever abbreviation (you will see that we are greedy for this kind of thing). The system itself is called small - this is a small object allocation. The mattress is a memory address translation. Those.The mattress is such a user space tlb. This is a kind of system that allocates memory and is engaged in translating addresses into 32-bit space. And what is important, if we would just have a translator, we have, conditionally speaking, an 8-byte address, and we want to give it 32-bit identifiers. Inevitably, we need to store this map somewhere, we need to store addresses somewhere. We use extra memory. We get rid of this at the expense of the mattress. The mattress is simultaneously an allocator and a translation system. It allocates an object that must be aligned in size, it can be either 16 bytes, or 32, or 64, etc. - must be a power of two. And returns its 32-bit identifier. How does he work?
In fact, it is a 3-level tree. At the first level, there is a root block, and pointers to the first level extents are stored in the root block. The total number of such degrees is 2048, because we use the first 11 bits of the 32-bit number for addressing in the root block. Getting to the extent, i.e. in the second level of the tree, we define the place where our address is specifically stored - for this our memory, i.e. for this we use the second 11 bits of the address. This allows us to jump even lower, and in this particular place is our memory, i.e. there is not a pointer, but the memory itself, which was allocated.
In case of deallocation, we work with this system as with a classical tree, i.e. we have a list of free objects. In fact, here the final release never happens, but naturally released blocks are folded into free sheets and can always be reused. The performance of such a data structure is 10 million operations per second on more or less average hardware. It is because of this that we are fighting for good work with caches, because we want such a thing to completely fit into the l-3 cache, then it will work efficiently.
What is another important feature of this system? We made it multi-version, i.e. it is possible to support multiple versions of the same data structure. In order to make snapshots, we can freeze the mattress. Have you tried to freeze your mattress? We freeze the data structure, all updates occur with its new version, we freeze it according to the classical principle of multi-version trees - when we go to change a certain extent of the mattress, we make a copy, we have a copy on write classic when it is frozen. After defrosting occurs, i.e. we made snapshots, we add unfrozen segments in the free sheet and that's it. And we begin to reuse it. Returning, we freeze this data structure, we obtain a consistent iteration over all the memory that was allocated through it.
What is important here? In this structure, we are already allocating objects of our indices, i.e. Our indexes are designed so that they are always allocated through the mattress. We are asked how fast Tarantool is std :: map? Generally, faster, I'll tell you about it. But it is important that we also scale better than std :: map through this thing.
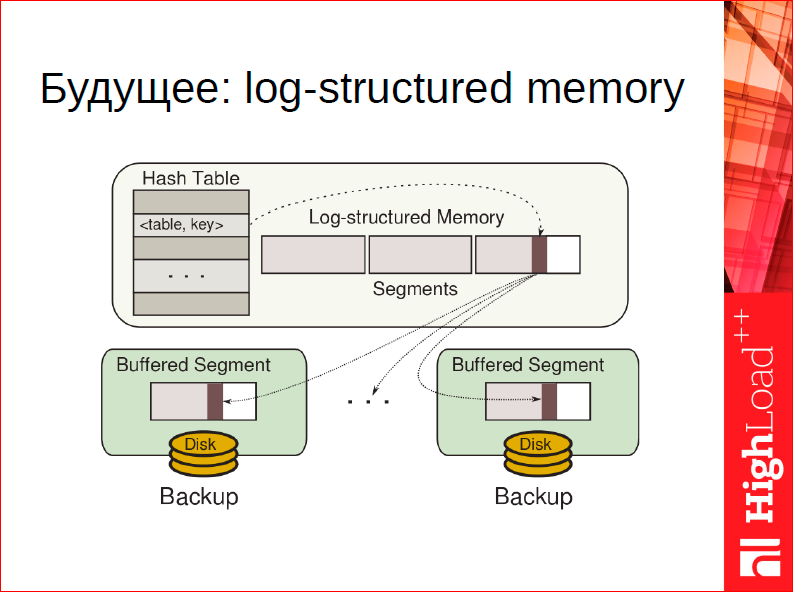
If we recall this tedious story about multilevel allocators, the mattress as a concept will allow us to throw out (we are going to do this in release 1.7), at least for storing data, this whole hierarchy and this whole slab allocator is entirely. Because if there is an opportunity to broadcast addresses, i.e. to substitute addresses on the fly, you can simply make an allocator based on the garbage collection, which is geared for our needs specifically for data.
How can such an allocator be arranged? Imagine that your allocation is arranged according to the log principle, i.e. for you, allocation is just an entry in some kind of endless magazine. It always happens at the end of the magazine. You always allocate by writing to the end: they took 10 bytes - fine, they took 15 - fine, you have no overhead, no fragmentation, you always have the most you need to align the word boundaries, you do not have another fragmentation. The magazine is completely compact. Gorgeous.
What to do when the memory is released? The memory is released, which means that somewhere some extent of the journal becomes fragmented, i.e. there are both occupied pieces, and liberated ones. What can be done?You can take the most defragmented extent and completely rewrite it, copy it completely to the end, throw out all the free space, throw all the freed blocks, fill the blocks, replace the addresses in the mattress - everything works.
We have already done a prototype of such a thing, unfortunately, in practice it works slower than manual memory management, but the beautiful side of this business is that there are no pens at all, i.e. we now have a slab allocator that the user has to twist. Here you have no fragmentation, the maximum handle for the user that we can give in this situation is how actively we want to defragment the old memory. We are going to do it. Thus, the mattress is a fundamental piece in architecture, we are going to build further structures based on it.
What have we built?
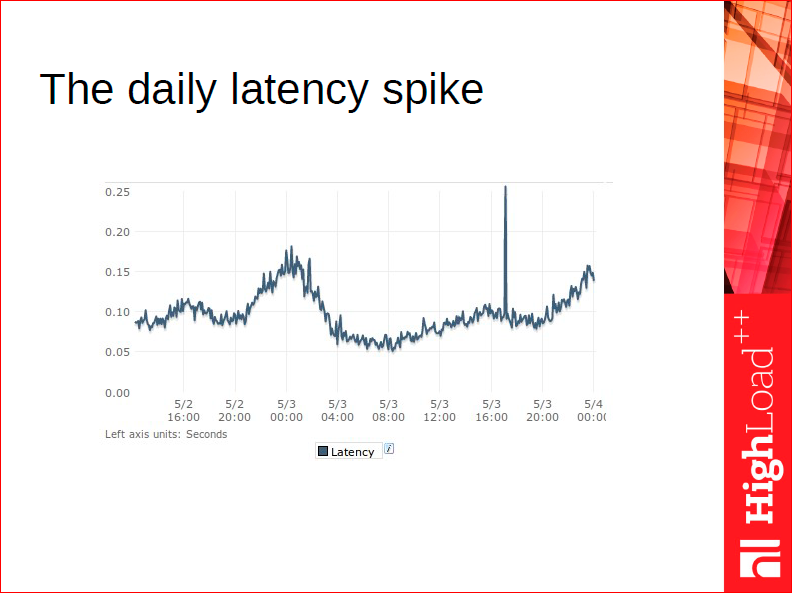
Before I talk about our hashes, let's talk about classic hashes. What is typical for a novice web programmer? We all know that the hash is the fastest data structure — it has an asymptotically constant search cost. Fine, we are starting to use hash absolutely for everything. We cut down our little system, it goes into production, and then we start looking for witches. Witches in the form of such jumps in response time, which happen once a day, once every two, once a week, when the cleaning lady has watered the flowers, we do not know where they come from, why they do not happen on our tests? We cannot model this system, they only happen in production.
I talk about it with such sarcasm, because in my life I have seen it repeatedly, when a C ++ programmer takes a hash, stores in it, for example, all users. Then in the evening the people will be added to the site, the number of users will increase, and the hash will be resized. While the resize hash happens, everyone smokes, everyone waits, we see it like this on the chart, so the classic hashes are simply not suitable for the DBMS, because if you have a huge amount of data, you cannot afford to do the resize.

Here we come to the most insubstantial history in the whole presentation - exactly how our hash with linear growth works. Those.our hash is never resized. More precisely, it is always resized, it is resized for each insert. How it works?
To begin with, the base object of the hash is a 16-byte structure. The value of 8 bytes is either a key or a pointer to the data, and two 32-bit numbers are a hash of the key and a pointer to the next item. It is in the top right of the slide.
Further, the key parameter of the hash is the mask. A mask is a power of two that covers the current size. Those.if we have the current size of the hash, in which there are now 3 elements, then the mask will be 4, if in the hash there are 4 elements - 4, 5 elements - mask 8. Thus, we have a virtual size of the hash. And the virtual size of the resize hash is classically, but this is only a number, in fact, we do not have this directory with the hash table. Each time we insert, we add 1 item to the hash.
Another important element is a pointer to the current batch, which can be resized. Suppose we have a number of elements in the hash - 2, a pointer to the current bake will be 0. We added a new element, we split the zero bake and move the pointer to the next, we add the next element, we split the first batch, and we 4 buckets appear, and we restart our resize counter, we have 4 buckets - the resize counter is on the zero bucket. Add the 5th element, split the zero bucket again. We have 5 elements, the zero bucket is closed, the mask is equal to 8. Thus, we add elements, we reach 4, the first 4 elements are again spread, we have 8 elements. So we reset the counter to 0 again, there is a pointer to the current buck that we will split when inserted, and each insert results in a split.
Next thing can happen next - we can get when pasting to overflow, i.e. we can get on the overflow chain, i.e. on the collision chain. When inserting, we can get exactly on that bucket, which we resize - then everything is generally good, we just insert a new value for the bat, or we can get into the bucket, which we do not resize when hashing, but we have a guarantee that we have There is a place to insert. With each insert, we add 1 item.
You can also look at the whole system as follows: this cover or mask determines the significant bits in the hash, which are taken into account when the value is placed in the hash. When we double it, our next bit becomes significant, and we resize, gradually taking into account this significant bit.
Look in the literature for “linear hashing for two-level storage for a disk.” You will find a fairly clear explanation. I first got to know this system when I was working in MySQL, and we called it Monty Hash, because this is how a hash was made in MySQL. And we used it for a long time.
What is the main point? Make it so that the costs for resize hash tables are evenly distributed, and they do not affect the overall performance.
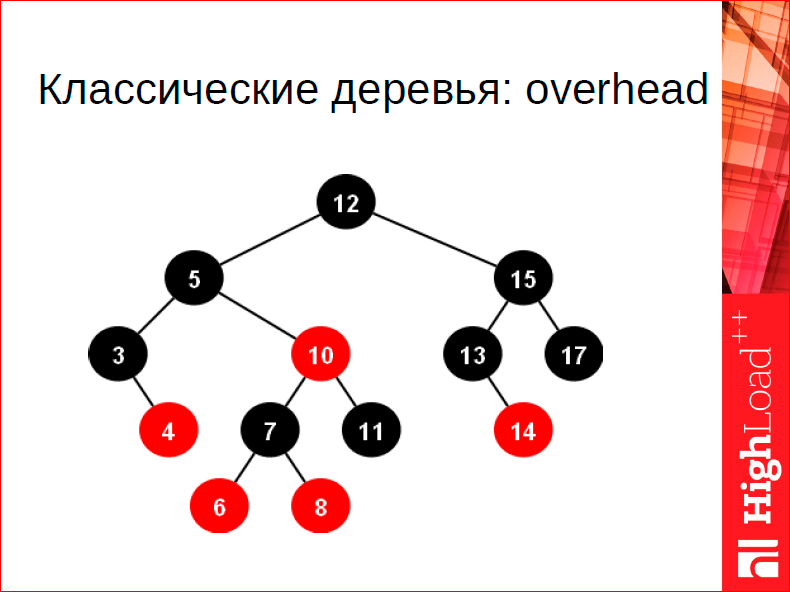
Our trees are special too. What is special about them? In Tarantool 1.3 and 1.4, classic trees were used for RAM, and they are pretty good, but what's wrong with a classic tree? Two things: the first is the overhead on the pointer, each vertex has two pointers, and this is too expensive, 16 bytes to spend on one value that we store in the tree is expensive, we do not want that. The second is balance. Even AVL trees are fairly well balanced, but compared to the B tree, which I will talk about further, the balance is unsatisfactory, I will show the figures later - the balance is insufficient, i.e. it is possible to improve the balance by a significant amount by 30-40%. And as a result of such an organization, they are completely unfriendly to the cache, i.e. Each transition through the tree is most likely to result in the need for a cache line,which you don’t have in the cache, because it’s likely that your nodes are somehow randomly spread over the address space, so you can’t say anything good about the address you call to. Therefore, we made our trees - these are B + * trees:

What is the idea? In the fact that in each block we store not one element, but many - 20 elements, maybe 40 on average. moving along the cache lines so that it all fits into the cache line.
Further, we store elements only in the leaves in order to make this tree header as compact as possible, so that it again fits into the cache. We stitch the sheets through, making iteration through the tree fast. Those.in order to iterate over the tree, we need to go back to the top, we iterate over the leaves. And we use a mattress for allocation, in order to be able to freeze the trees, so that the pointers are 32 bits to the nodes of the tree.
This is approximately as follows:

On average, a 3-level tree, usually with some more or less real table sizes. This is a tree that is very well balanced.
What is the difference between B + tree, B + * tree and classical B trees, which store data at intermediate peaks, etc.? This tree guarantees the fullness of each block by 2/3, the fullness of the elements, in order to guarantee this fullness when rebalancing. This is a classic law. If you want to fill in so that you have the average at 1/2, then when you rebalance, you only have to look at the neighbor and shuffle the elements between the current node and the neighboring node. He has an average of 1/2, you have an average of 1/2 - should fit, if not fit, then you definitely need to do a split, and you will have an average fullness, you will still have 1/2 fullness. When you have an average fullness of 2/3, i.e. If you want to achieve a higher rate, when rebalancing you need to look not at one neighbor, but at two,or even three, depending on the configuration. And, accordingly, you distribute your data between them. Rebalancing such a tree is quite expensive, but the tree is very well balanced.
What are our results?

We have a low overhead per unit of storage, and we have a very good balance, i.e. when searching, we have an average of 1.1 log (N) comparison operations. Moreover, these comparison operations work very well with the cache, because all these tree blocks fit into the cache well.
In fact, the tree is so good that we sometimes do not even understand that it is faster - a hash or tree in 1.6. According to our measurements, the hash is now about 30-40% faster, i.e. there is logarithmic complexity, and there it is constant, and the gain is only 40%, because this logarithm is expressed in fact only in viewing of 2–3 cashlines, and in a hash it can be the average of 2 cashlines of views. Those. The cost of the data structure is measured not in classical operations, but in how well they work with the cache.
Contacts
» Kostja
» Mail.ru company blog
This report is a transcript of one of the best speeches at the conference of developers of high-loaded systems HighLoad ++ . Now we are actively preparing for the conference in 2016 - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
Konstantin is a member of the HighLoad ++ Program Committee and our regular speaker. In 2016, Kostya will talk about the new storage engine in Tarantool in the report “ Data Storage on Vinyl ”.
By the way, the entire HighLoad ++ Program Committee unanimously recommends the Tarantool platform . This is one of our remarkable (Russian) developments and, at least, deserves attention.
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/310560/
All Articles