Solar JSOC - the experience of building a commercial SOC
This article opens a series of publications dedicated to the operation of the Information Security Incident Monitoring and Response Center - Security Operations Center (SOC). In them, we will talk about what needs to be taken into account when creating a SOC, about the process of preparing monitoring engineers, registering incidents and practical cases that Solar JSOC is facing.
The purpose of these articles is not self-advertisement, but a description of practical aspects in the implementation of a service model for the provision of information security services. The first article will have an introductory character, but it is necessary to dive into a topic that is still fairly new to the Russian information security market.
What is SOC, how does it differ from SIEM, and why is it needed at all, I will not describe it - too many articles have recently been written on this topic. Moreover, in the articles one could meet the view from any side: an expert, a SIEM vendor, an owner or an employee of SOC.
')
As an introductory information, it is worth mentioning the statistics according to research conducted by the IIDF, as well as by Group-IB and Microsoft:
I would also like to mention the statistics on our clients, which is reflected in the quarterly reports of the JSOC Security Flash Report:
If we recall the recent public incidents - “Metallinvestbank”, “Russian International Bank”, the withdrawal of money through the SWIFT vulnerabilities and the attack on the energy sector of Ukraine, the idea that security needs to be monitored and security incidents to identify and analyze becomes completely logical and understandable. .
As one of the most popular solutions of recent years to monitor and detect incidents is the SIEM-system, which becomes the core of SOC. This choice is primarily due to a significant amount of tasks that can be solved with the help of a SIEM system:
According to the model proposed by HP SIOC, there are several levels of SOC-SOMM maturity (Security Operations Maturity Model):
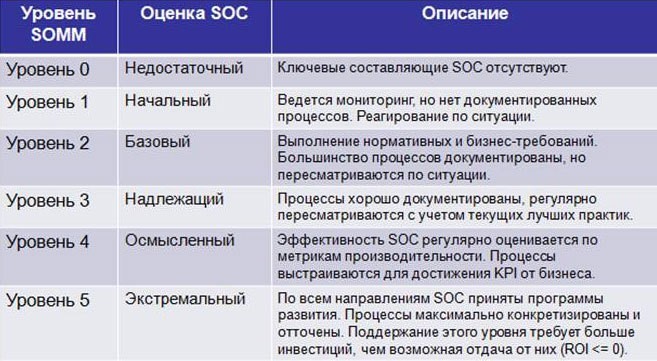
Fig. 1. SOMM levels
Unfortunately, most companies both in Russia and in the world, having taken the first step towards building their own Security Operations Center, stop there. According to HP estimates, 24% SOC in the world do not reach level 1, and only 30% SOC correspond to the base (2) level. Statistics of the distribution of SOMM levels depending on the business area of companies, collected in 13 countries of the world (including Canada, USA, China, UK, Germany, South Africa, etc.) is as follows:

Fig. 2. Distribution of SOMM levels by business area
The most beaten path in Russia is to acquire a SIEM system for monitoring incidents. Practically all large Russian companies passed along this path. At the same time, it is possible, at best, to successfully launch an incident monitoring and response center at 5-10%. What prevents? The main difficulties in building your own SOC are observed in three directions:
Estimating the need for creating SOCs on the market together with the nuances described above led us first to the idea and then to actually build our own commercial SOC.
One of the main issues at the construction stage of the Security Operations Center for us was the choice of a SIEM system. We have formed a number of requirements for it:
We stopped our choice on one of the leaders in the SIEM class - HP ArcSight and, despite various difficulties in the life of the system, we never regretted our decision.
Following the incident monitoring service, Solar JSOC was supplemented with new services:
Technologically, Solar JSOC is no longer just HP ArcSight. SIEM kernel gradually overgrown with various useful addons and features. A traffic monitoring tool and a Security Intelligence Solar inView class solution have been added, which is:
One of the main innovations of the last year is the transition to an external case management system. As a platform, we chose Kayako, which is optimal for our tasks, has a convenient and flexible customization tool and an excellent API.
An important tool for monitoring and detecting incidents is the reputational bases of various domestic and foreign vendors and CERT. The databases can contain both network and host indicators of compromise (IOC) of various malicious programs, or they can describe the behavior of malicious users. Depending on the data supplied, we use various tools for identifying indicators: network ones are entered into ArcSight for retrospective search and control in the future, and the host ones turn into indicators of security scanners. The most important partners in this area are FinCERT and Kaspersky Lab.
Integration with the reputation databases of Kaspersky Threat Intelligence is carried out through an API, developed jointly with Kaspersky Lab. Thanks to this, we get the most up-to-date information - the “feeds” database is updated every few hours, which is comparable to the rate at which new anti-virus signatures are received (sometimes faster). This allows you to quickly identify zero-day viruses that fall into the infrastructure of customers due to their callbacks.
An interesting format of the information provided is APT Reports, in which the vendor or CERT describes the attack history, the toolkit, the associated exploitation of vulnerabilities, and, of course, the target of the attackers. This format allows us to take a fresh look at the points of control and detection of incidents, tweak existing or create new correlation rules.
Using the above tools, we have formed the following areas of the provision of information services:

After the selection of the main technological platform, it was necessary to solve the problems of creating the infrastructure and determine the location of the location. The experience of our Western colleagues shows that the target accessibility of the architecture should be at least 99.5% (and with maximum disaster recovery).
At the same time, the question of geography remained fundamental: collocation is possible only within the borders of the Russian Federation, which ruled out the possibility of using popular western providers. Natural security issues of infrastructure at all levels of access were superimposed here. Therefore, it was decided to contact our partner Jet Infosystems, and within the framework of a large colocation, JSOC was allocated several racks in a fragment physically isolated from other servers, where we were able to deploy our architecture, while tightening the security profiles that already exist within ITSC. The IT infrastructure is deployed in the Tier 3 data center, and its accessibility is 99.8%. As a result, we were able to reach the target indicators of the availability of our service and received substantial freedom of action in the work and adaptation of the system for ourselves.
At the initial stage, the JSOC team consisted of 3 people: two monitoring engineers closing the time interval from 8 to 22 hours, and one analyst / administrator who was involved in the development of the rules. The SLA for the service, indicated to the clients, was also quite mild: the reaction time to the detected incident was up to 30 minutes, the time for analysis, preparation of analytical information and informing the client up to 2 hours. But, after the first months of work, we made some very significant conclusions:
These findings significantly influenced the structure of the JSOC department at Solar Security and helped form a three-tier incident response model. Now the division has more than 40 people, has a formed structure (see Fig. 4) and includes:

Fig. 4 - JSOC Organizational Structure
This organizational structure allowed us to reach the SLA targets:

Over the past 4 years of development, our Security Operations Center has gone through the following important stages:
year 2012
year 2013
year 2014
2015
This concludes the first introductory article from the series. In the near future - materials on the technical aspects of the work of Solar JSOC:
Stay with us!
The purpose of these articles is not self-advertisement, but a description of practical aspects in the implementation of a service model for the provision of information security services. The first article will have an introductory character, but it is necessary to dive into a topic that is still fairly new to the Russian information security market.
Why do we need SOC
What is SOC, how does it differ from SIEM, and why is it needed at all, I will not describe it - too many articles have recently been written on this topic. Moreover, in the articles one could meet the view from any side: an expert, a SIEM vendor, an owner or an employee of SOC.
')
As an introductory information, it is worth mentioning the statistics according to research conducted by the IIDF, as well as by Group-IB and Microsoft:
- The loss of the Russian economy from cybercrime in 2015 is estimated at 123.5 billion rubles.
- 60% of Russian companies noted a 75% increase in the number of cyber incidents, and the amount of damage doubled.
I would also like to mention the statistics on our clients, which is reflected in the quarterly reports of the JSOC Security Flash Report:
- The double increase in the number of information security incidents in the first quarter of 2016 compared to the same period of 2015.
- Significant increase in incidents involving confidential information leaks.
- Increase critical incidents from 26% to 32% in relation to the total skoupu.
- Growth in the number of different cyber-groups operating according to known fraud schemes.
If we recall the recent public incidents - “Metallinvestbank”, “Russian International Bank”, the withdrawal of money through the SWIFT vulnerabilities and the attack on the energy sector of Ukraine, the idea that security needs to be monitored and security incidents to identify and analyze becomes completely logical and understandable. .
As one of the most popular solutions of recent years to monitor and detect incidents is the SIEM-system, which becomes the core of SOC. This choice is primarily due to a significant amount of tasks that can be solved with the help of a SIEM system:
- to close incidents recorded by other systems on their own, within the framework of a single core incident management;
- get a handy tool for finding necessary events, handling incidents, storing the collected data;
- identify statistical deviations and slowly developing incidents by analyzing large intervals and amounts of information from specific remedies;
- compare and correlate data from different systems, and, as a result, build complex chains of incident detection scenarios, “enrich” information in the logs of some systems with data from others.
Some methodology
According to the model proposed by HP SIOC, there are several levels of SOC-SOMM maturity (Security Operations Maturity Model):
Fig. 1. SOMM levels
Unfortunately, most companies both in Russia and in the world, having taken the first step towards building their own Security Operations Center, stop there. According to HP estimates, 24% SOC in the world do not reach level 1, and only 30% SOC correspond to the base (2) level. Statistics of the distribution of SOMM levels depending on the business area of companies, collected in 13 countries of the world (including Canada, USA, China, UK, Germany, South Africa, etc.) is as follows:
Fig. 2. Distribution of SOMM levels by business area
Problems of own SOC
The most beaten path in Russia is to acquire a SIEM system for monitoring incidents. Practically all large Russian companies passed along this path. At the same time, it is possible, at best, to successfully launch an incident monitoring and response center at 5-10%. What prevents? The main difficulties in building your own SOC are observed in three directions:
- Quantitative and qualitative shortage of staff . The reasons are various: from personnel shortage and the lack of specialized universities to the difficulty of obtaining the required competencies. In the framework of the average information security department (department), today there are 3-5 people who must carry out the entire cycle of work to ensure the security of the company (from administering protection tools and ensuring compliance with regulatory requirements to continuous risk analysis and developing a development strategy for the company). Naturally, with such a load, it is almost impossible to devote the proper time to SOC tasks.
- The impossibility of building an effective monitoring process with internal SLAs . In addition to the need to allocate staff, the launch of SOC implies the creation of a full-fledged duty shift operating in the IT-security unit operating in 12/5 or 24/7 mode, and this is from 2 to 5 new staff members. At the same time, the allocation of personnel is directly related to the need for constant monitoring of personnel routine (extremely rarely IB specialists are ready to work in the night shift), building processes and internal quality control of the work performed.
- SOC development should be carried out on an ongoing basis : the development of new scenarios for threat vectors, the connection of new information sources, the aggregation and use of reputation databases. Static SOC is completely ineffective, and for dynamic development, an analyst is needed. The presence in the state of a person who is an SOC architect in full time mode is a great luxury even for a large company.
Estimating the need for creating SOCs on the market together with the nuances described above led us first to the idea and then to actually build our own commercial SOC.
Platform Selection
One of the main issues at the construction stage of the Security Operations Center for us was the choice of a SIEM system. We have formed a number of requirements for it:
- SIEM should have the ability to build the most complex chains and patterns of interconnection between events, use various reference books and lists (including those loaded according to a schedule) to supplement the incident with important information. At the same time, we were less interested in the set of rules, scenarios and categories out of the box; we needed a platform for building content on our own.
- The system should allow physically and logically to separate the accumulated data across different storage groups (in our case, different customers) with the possibility of separation of access rights, as well as independent repositories of events and incidents of different customers.
- The system should have both a sufficient number of ready-made connectors (with the possibility of changing the mapping), and have a convenient mechanism for developing additional connectors to any system that, at least in some form, can give information to the outside. The API was also important for connecting with external incident management, reporting and visualization systems.
- One of the most important tasks that the SIEM should solve is stability of work under heavy load both in the flow of events and in the operation of a large number of correlation rules, retrospective searches and reporting.
- The SIEM system should allow customization of internal resources for SOC changing tasks. In particular, the creation of an internal profile of monitoring sources (System Health), the use of external scripts at various stages of work with fixed incidents, the maintenance and customization of their incident management, etc.
We stopped our choice on one of the leaders in the SIEM class - HP ArcSight and, despite various difficulties in the life of the system, we never regretted our decision.
SOC components
Following the incident monitoring service, Solar JSOC was supplemented with new services:
- WAF as a service;
- Anti-DDoS;
- Vulnerability Assessment, where we chose Qualys as the main solution due to the rich functionality and user-friendly interface, including for writing signatures;
- Scanner software code for vulnerabilities and NDV Solar inCode.
Technologically, Solar JSOC is no longer just HP ArcSight. SIEM kernel gradually overgrown with various useful addons and features. A traffic monitoring tool and a Security Intelligence Solar inView class solution have been added, which is:
- a tool for high-level search for anomalies at the client and tracking general trends in activities and incidents;
- control system and visualization of our performance of SLA to the customer;
- an effective visual dashboard and reporting system for customer business management.
One of the main innovations of the last year is the transition to an external case management system. As a platform, we chose Kayako, which is optimal for our tasks, has a convenient and flexible customization tool and an excellent API.
An important tool for monitoring and detecting incidents is the reputational bases of various domestic and foreign vendors and CERT. The databases can contain both network and host indicators of compromise (IOC) of various malicious programs, or they can describe the behavior of malicious users. Depending on the data supplied, we use various tools for identifying indicators: network ones are entered into ArcSight for retrospective search and control in the future, and the host ones turn into indicators of security scanners. The most important partners in this area are FinCERT and Kaspersky Lab.
Integration with the reputation databases of Kaspersky Threat Intelligence is carried out through an API, developed jointly with Kaspersky Lab. Thanks to this, we get the most up-to-date information - the “feeds” database is updated every few hours, which is comparable to the rate at which new anti-virus signatures are received (sometimes faster). This allows you to quickly identify zero-day viruses that fall into the infrastructure of customers due to their callbacks.
An interesting format of the information provided is APT Reports, in which the vendor or CERT describes the attack history, the toolkit, the associated exploitation of vulnerabilities, and, of course, the target of the attackers. This format allows us to take a fresh look at the points of control and detection of incidents, tweak existing or create new correlation rules.
Using the above tools, we have formed the following areas of the provision of information services:
- Protection of external web resources of the company - here, first of all, we provide a service for the proactive use of WAF and Anti-DDoS solutions;
- Comprehensive security for business applications - incident monitoring + source code analysis;
- Infrastructure monitoring of information security incidents;
- Complete security control and compliance control;
- Detection of targeted attacks and zero-day malware - a comprehensive approach that includes regular infrastructure scans using a security scanner + monitoring incidents + using targeted feeds + parsing and analyzing malware instances;
- Operation of intelligent GIS - DAM, Sandbox, NGFW, traffic analyzers.
Architecture
After the selection of the main technological platform, it was necessary to solve the problems of creating the infrastructure and determine the location of the location. The experience of our Western colleagues shows that the target accessibility of the architecture should be at least 99.5% (and with maximum disaster recovery).
At the same time, the question of geography remained fundamental: collocation is possible only within the borders of the Russian Federation, which ruled out the possibility of using popular western providers. Natural security issues of infrastructure at all levels of access were superimposed here. Therefore, it was decided to contact our partner Jet Infosystems, and within the framework of a large colocation, JSOC was allocated several racks in a fragment physically isolated from other servers, where we were able to deploy our architecture, while tightening the security profiles that already exist within ITSC. The IT infrastructure is deployed in the Tier 3 data center, and its accessibility is 99.8%. As a result, we were able to reach the target indicators of the availability of our service and received substantial freedom of action in the work and adaptation of the system for ourselves.
Team
At the initial stage, the JSOC team consisted of 3 people: two monitoring engineers closing the time interval from 8 to 22 hours, and one analyst / administrator who was involved in the development of the rules. The SLA for the service, indicated to the clients, was also quite mild: the reaction time to the detected incident was up to 30 minutes, the time for analysis, preparation of analytical information and informing the client up to 2 hours. But, after the first months of work, we made some very significant conclusions:
- The monitoring shift must necessarily work in the 24 * 7 mode. Despite the fact that the volume of incidents in the evening and night hours is reduced, the most important and critical events (the launch of DDoS attacks, the final phases of slow attacks on penetration through the outer perimeter, malicious actions of counterparties, etc.) occur at night, and by the time of the start of the morning shift they are no longer relevant.
- The time to resolve a critical incident should not exceed 30 minutes. Otherwise, the chances of preventing it or minimizing damage fall dramatically.
- To ensure the required parsing time, for each incident, a full-fledged investigation toolkit must be prepared within ArcSight: active channels with filtered target events for parsing, trends, dashboards, showing statistical changes in suspicious activities, and targeted analytic reports that allow you to quickly analyze activities and take operational solutions, active / session lists for quick access to information about hosts, users, etc.
- The administration team for the protection of our customers should be separated from the monitoring and incident detection team. Otherwise, the risk of the influence of the human factor in the chain "made configuration changes - recorded the incident - noted a false response" could significantly affect the quality of our service.
These findings significantly influenced the structure of the JSOC department at Solar Security and helped form a three-tier incident response model. Now the division has more than 40 people, has a formed structure (see Fig. 4) and includes:
- Two duty shifts that work 24 * 7: one is engaged in monitoring and analysis of incidents, the other - the administration of the system.
- Personal analysts and service managers for JSOC clients. By experience, one analyst is able to lead 3-4 companies.
- Dedicated development team that allows us to maintain the relevance of the service and the threat monitoring profile.
Fig. 4 - JSOC Organizational Structure
This organizational structure allowed us to reach the SLA targets:
Results
Over the past 4 years of development, our Security Operations Center has gone through the following important stages:
year 2012
- the emergence of the idea of cloud SOC.
year 2013
- formation of a JSOC team consisting of 2 monitoring engineers in 12/5 mode, one analyst and a head of the direction;
- 1 customer and 3 pilot projects;
- SLA: reaction to the incident - 30 minutes, analysis - 2 hours.
year 2014
- the formation of two sites: Moscow and Nizhny Novgorod;
- the first line of monitoring and operation 24/7;
- SLA performance - 98.5%;
- 10 customers.
2015
- the staff reached 30 people;
- a significant increase in the number of customers - 20+, 4 public projects
- SLA performance - 99.2%
This concludes the first introductory article from the series. In the near future - materials on the technical aspects of the work of Solar JSOC:
- SOC availability: indicators, measurement.
- Solar JSOC: Incident Recording. How and why to live in an external ticket system.
- Solar JSOC: RULING Kitchen, etc.
- and etc.
Stay with us!
Source: https://habr.com/ru/post/310470/
All Articles