Work with Apache Ignite topology
 In the previous article, I talked about how to build the simplest topology for Apache Ignite . It consisted of one client and one server, the client sent a message to the server and the server displayed it. It was told about how to configure the product and monitor its livelihoods. Now it's time for a more complex example. The construction of a complex topology and more interesting interaction scenarios will be demonstrated. It is assumed that the reader is familiar with the basic operations with Apache Ignite, described in the first article. As a result of reading these two articles, the reader may have some assumptions about how to apply this, without exaggeration, a powerful product in their projects. Also, the article will be useful to those who are interested in building high-performance systems, and want to peep a ready-made solution for their bike.
In the previous article, I talked about how to build the simplest topology for Apache Ignite . It consisted of one client and one server, the client sent a message to the server and the server displayed it. It was told about how to configure the product and monitor its livelihoods. Now it's time for a more complex example. The construction of a complex topology and more interesting interaction scenarios will be demonstrated. It is assumed that the reader is familiar with the basic operations with Apache Ignite, described in the first article. As a result of reading these two articles, the reader may have some assumptions about how to apply this, without exaggeration, a powerful product in their projects. Also, the article will be useful to those who are interested in building high-performance systems, and want to peep a ready-made solution for their bike.Topology setup
Recall that the topology Ignite consists of two types of nodes, clients and servers. Clients, in general (but not necessarily), execute send requests, and servers process them. The node's behavior is determined by its configuration, which is the Spring configuration for the corresponding Ignite object. The main points related to the configuration of the nodes are described in the previous article . We will now create two xml server-type configurations that differ in the “gridName” property and are otherwise the same. In this example, these will be the names "testGrid-server" and "testGrid-server1". Let's run, for example, two nodes with the first configuration and one with the second. Since each of them will be launched in a separate JVM, you should take care of configuring the memory of the nodes, for which you can reduce the values of the -Xms and -Xmx parameters in ignite.bat. Use the ignitevisorcmd. (Bat | sh) command to run the Visor utility used to monitor the Ignite topology. At startup we must specify one of the configs, specify any, the result will be the same.
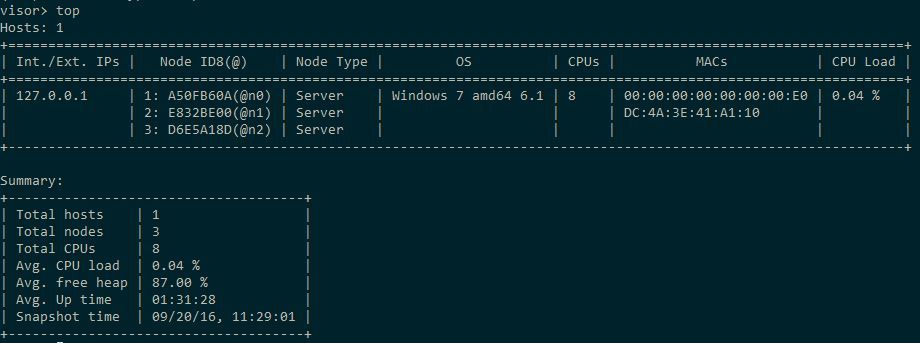
Since we now have such a complex topology, it's time to get acquainted with the main features of the visor. He lists the complete list of his commands with help . A complete list of them with brief explanations can be seen on the product documentation page . In addition to what has been said in the documentation, I note that you can write plug-ins to the visor, and it is written in Scala . In the context of this article, you should pay attention to the visor config command, which displays all the relevant details about the specified node. This is a very large amount of information, so I will not give it here.
Although this by the way was not necessary, the nodes are also non-Java, currently there is support for C ++ and .NET. I also did not mention that you can define lifecycle handlers for a node. In short, there are 4 events before / after starting / stopping a node. What is there to do is not clear, logging is provided by standard means, perhaps some kind of security checks or server settings. The only implementation of the LifecycleBean interface that comes with Ignite is used when initializing .NET nodes. At first glance, nothing useful can be done with this feature.
')
Connect to servers
In the previous article, we connected the client to the server and sent the message “Hello World!”. By slightly modifying the code from the previous example, we will create in our test two nodes, client and server; because of the way they are created, they will be created in one JVM. They are configured with different xml configurations, and the gridName for the server will be “testGrid-server0”. The test code is:
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = {"/ignite/providerConfig.xml"}) public class IgniteHelloWorld { @Autowired @Qualifier("clientProvider") private IgniteProvider igniteClient; @Autowired @Qualifier("serverProvider") private IgniteProvider igniteServer; @Test public void sendHelloTest() { try (Ignite server = igniteServer.getIgnite(); Ignite client = igniteClient.getIgnite()) { client.compute().broadcast(() -> System.out.println("Hello World from client!")); server.compute().broadcast(() -> System.out.println("Hello World from server!")); } } } Please note that Ignite objects that implement the AutoCloseable interface will close with a good tone after use. So, we now have three server nodes running via the command line. After executing the test in each of their three consoles, and in the console of our IDE, we will see approximately the same thing:

Another client and server joined the three existing servers, said hello and disconnected. How is this behavior ensured? The compute () method, which determines the group of servers on which the task will be executed, has two implementations. The implementation without parameters, which we call in the test, looks like this:
@Override public IgniteCompute compute() { return ((ClusterGroupAdapter)ctx.cluster().get().forServers()).compute(); } Let's see what's going on here. On the ctx object of the GridKernalContextImpl type (the developers use the word “ Kernal ” because of some tradition that is significant for them) the cluster () method is called, which returns the ClusterProcessor object symbolizing, apparently, our node in terms of its interactions with the topology. Actually, the node as a single-element cluster is obtained by further calling the get () method, which is given to us by the IgniteClusterImpl object, which can do a lot. First of all, build a subset of nodes based on the application of a predicate to them, that is, a certain condition that is calculated on a set of objects and thus filters it. In this case, the forServers () method returns a predicate that returns true for nodes that have the ATTR_CLIENT_MODE property == false. A complete list of attributes can be found . In addition to attribute-based predicates, Ignite comes with a number of other interesting implementations of predicates. For example, you can filter by cache content, which it makes sense to introduce later, and a number of other, more exotic ones.
Armed with this knowledge, it is not difficult to modify our test so that the message is sent to the selected nodes. For identification, we have the gridName parameter, try sending servers with gridName == "testGrid-server", which we have 2. Having made calls
client.compute(client.cluster() .forAttribute(ATTR_GRID_NAME, "testGrid-server") .forServers()) .broadcast(() -> System.out.println("Hello World from client!")); server.compute(server.cluster() .forAttribute(ATTR_GRID_NAME, "testGrid-server1") .forServers()) .broadcast(() -> System.out.println("Hello World from server!")); as expected, we will receive two messages from the client and one from the server. If the predicate returns anything, the exception “ClusterGroupEmptyCheckedException: Cluster group is empty” will be thrown. In addition to forServers (), there are a number of other interesting standard predicates, for example forRemotes (), forRandom (), forOldest () and forYoungest ().
Finally, the broadcast () call is not the only thing we can do. To execute here is to pass the IgniteCallable object for execution. There are also several versions of the call () method, which, unlike broadcast (), returns the result.
And what's inside?
It will be curious to know how it works. In order to find out, we will perform such an experiment: from our client, send a message to the server created in the test, with which gridName == "testGrid-server0" and see in the debag what is going to happen. For more insight, let's change our test a bit:
int param = 1; Integer clientResult = client.compute(client.cluster() .forAttribute(ATTR_GRID_NAME, "testGrid-server0") .forServers()) .call(() -> { System.out.println("Hello World from client!"); return param + 1; }); The first thing that happens when calling the call () method is setting a read-write lock on our client. Interestingly, Ignite uses its own implementation of this mechanism in the GridSpinReadWriteLock class, based on sun.misc.Unsafe. On the one hand, this is good, Ignite developers care about performance, but on the other hand, what happens when they unclean in Java 9? With anxiety, I will follow the development of events ... Even without surprise, one may find that, in the care of performance, the developers of Ignite rejected the standard java.util.concurrent.Future class in favor of their own implementation of the IgniteFuture interface. I don’t know if they are much better, but one thing is clear - those who want to contribute to Apache Ignite should have a very deep knowledge of concurrency ... Then, based on our lambda, a task is formed, which is sent to execution. This task is entrusted to the startTask method of the GridTaskProcessor class. There is a security check here, but the security check is not implemented, it is likely to appear in future versions. The next essential step is the distributed deployment of classes, but for now we will not go into this powerful feature, referring to the original documentation . Let me remind you that Ignite must take steps to ensure that the executable code is on all the nodes where the task will be executed. The task can be set to a timeout equal to the default Long.MAX_VALUE, in fact infinity, it can be overridden. You can also customize the start-up task logging. Traces of enterprise features — load balancing, resiliency, and transactional settings — are listed below. If at some point in the task's processing time it turns out that the server or servers to which the task has dumped have fallen off, the processing is interrupted with an exception. If we didn’t collapse anywhere along the road, then a job is generated, which is passed to the I / O dispatcher GridIoManager. It forms the message and sends it using TcpCommunicationSpi . Let me remind you that this object can be specified in the xml-configuration of the node, that is, we can influence the process of sending messages by implementing the heir TcpCommunicationSpi. Next is also not easy, but finally using the NIO message leaves. And our server gets it. And calculates, and similarly sends the answer. And he comes to the place of the call, in this case, the number 2.
Load management
What happens when a task can be executed on multiple servers? We can verify this by sending a request to the servers with the gridName == "testGrid-server", of which 2. If taking into account the predicates, information about the availability of nodes, more than 1 node is available for the task, they are mixed using the Collections.shuffle (), and This list is transferred to the standard load balancer, which must be selected from the nodes 1 at its disposal. And here comes the interesting. If you left everything by default, the Round-Robbin algorithm provided by the RoundRobinLoadBalancingSpi class will be used. This SPI (in Ignite, all plug-in algorithms are called SPI ) iterates over the nodes using the round-robin method and selects the next node sequentially. There are two working modes, poizadny and global, set by calling setPerTask (boolean). If the task mode is selected, SPI selects the node at the beginning of the task execution randomly, and then cycles through the tasks as they are completed (in our case there is only one task, but the list of tasks can be transferred to execution). The default is exactly this approach. In global mode, a common sequential queue of nodes is used for all tasks. It is clear that the choice of the algorithm in this place may affect the distribution of the load between the nodes. In addition to the Round-Robbin balancer, two more are available: adaptive , which takes into account the performance of nodes based on a custom metric, which by default is the CPU load of the node server, and a random selection based on the weights of the nodes that can be specified during configuration (all are equal to 10 by default) . Finally, you can write your own by implementing the appropriate interface. You can specify the balancing SPI in the node xml-config (here I did not understand a bit, you can specify a list, how does the balancing occur, who exactly is balancing? Judging by the code, the class names are stuck in a string, and then SPI is instantiated by the class name. How Can it work? Judging by the hints in Javadoc's, it will work from version 2.1.)
In addition to balancing, the developer has the ability to manage two more enterprise-level features. Failover can be monitored with fail-over SPI . The reasons for this may be needed include an error during the execution of the task, a target node falling out of the topology and a node refusing to perform the task. The task of SPI of this type is to provide a node in return for a defective one. Three implementations are provided out of the box: NeverFailoverSpi, which never returns, and two more cunning ones - AlwaysFailoverSpi and JobStealingFailoverSpi. AlwaysFailoverSpi gives the node several attempts (by default, 5, you can override) before proposing another node. This takes into account the binding of the task to the node (affinity) - if the task is linked, then after a specified number of attempts a fall occurs, if not, then taking into account the balancer data, a new node is selected and the defective is placed on the black list. The number of attempts and the black list of nodes is stored in the context of the task. JobStealingFailoverSpi is even more cunning, and we will not consider it. The SPI Failover list can also be specified in the config. If nothing is specified, the default is AlwaysFailoverSpi.
And the last SPI from this series, Checkpoint SPI , as it is not difficult to guess, is designed to create save points (checkpoints), that is, intermediate points when performing a long or complex task. This type of SPI provides an API with which you can save, delete, and load a checkpoint. According to the authors of Ignite, this API should be used only by the system. but technically this possibility is not closed for application developers. We will not dive into the frightening bowels of this feature, by default the implementation is connected, which does nothing.
Traces
Finally, let's try to find traces of all these calls. Ignite provides total logging. If you do nothing to change the default state of affairs, a default logger will be created that will write messages to the console. This is a regular Java logging , for which you can configure the config / java.util.logging.properties config. If this does not suit you, you can implement the IgniteLogger interface and connect it via the xml config.
And you can also ask the visor. Using the node command, you can request detailed statistics on a node (if you know what to ask, and you may know, since we added the output to the console to our calculation). As a result, you can see something like this after several launches:
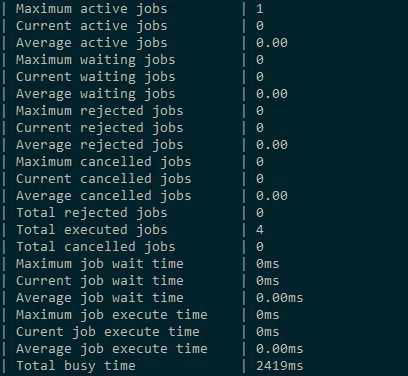
However, I may tell you about monitoring the topology another time.
findings
It is quite obvious that inside Ignite there are good, fit entrails. It is intuitively clear that, on the basis of Ignite nodes, it is possible to build quite interesting solutions of the scale of a large enterprise or, at a minimum, borrow interesting ideas from it. I hope that after reading this article, the reader has formed an idea of how to build a really complex, vital topology using the tools provided by Ignite.
Links
" GitHub Test Case Code
Source: https://habr.com/ru/post/310464/
All Articles