Secrets of Progressive Web Apps: Part 1
Hi, Habr! We continue the series of articles on Progressive Web Apps. The last time we introduced you to the experience of developers from Airberlin , well, today we have virtual guests Jan Lehnardt, the man behind such things as Hoodie, Apache CouchDB and Greenkeeper i / o.
And do not be confused by the abbreviation PWA (Progressive Web Apps): despite the fact that the title has Apps, the principles and technologies used in PWA apply generally to the web and to applications. The best entry to the article will be watching videos from Google I / O 2016, in which Jake Archibald talks about PWA.
')
I highly recommend watching it before continuing to read the article, especially if this topic is new to you.

In September, 14, I tweeted this piece: “Friends, CRYPTO, SYNC, DATABASE}.” What did I mean? Well, everything is simple. Making these things right is very difficult. And having made them “somehow”, you will upset a lot of people: as developers who will have to work with these crutches, as well as users, who will then put all this into practice. Simply put, some things are best left to professionals. However ... Sooner or later we will run out of available specialists on these topics, and no one can develop high-quality cryptography, synchronization or a database simply because no one has tried to do this and does not know how to do it, has not crammed and has no experience . This means that there can be exceptions in the rule. For example, you.
Let's try to become experts in one of these areas. Well, since we touch on the topic of PWA, we will work in the field of synchronization ... well, or you can consider these articles not as educational, but, let's say, as analytical - we consider a number of problems and their solutions that fall within the scope of “make data available offline. Something like this. Go?
After watching the introductory video, it may seem to you that PWA is such a “cloudless future” (but with cloud technologies, yeah), and not only for one-page websites and simple services, but also for harsh content providers such as the Guardian . . But if for some reason you do not share our conviction that PWA is how the web will develop in the near future, then at least you may be interested in where the PWA track leads and what technologies will be developed in this direction. And we will also discuss this.
If you are familiar with the post from the AirBerlin developers, you already know how to store the elements of your site in the ServiceWorker cache. Most likely, you also have some ideas on how to store actual content from the server in the index database . You can also guess that user data (entered fields, forms, notes, contacts, coordinates, almost anything) can also be stored in the database or in localStorage to send them to the server as soon as possible. For example, when a smartphone connects to WiFi in a hotel when roaming data is disabled.
A little more I will stay with Cap and highlight the following scenarios:
Before we reinvent the wheel, I propose to analyze all three cases step by step and mentally step on all the rakes that can be collected.
In the introductory video, Jake showed an example of a chat application. Looking ahead, I’m saying that he used Background Sync Api to send new messages “later,” as soon as the browser deems that he actually got access to the Internet connection (and not just connected to a network where the Internet may not be). for example, before authorization in the Moscow metro network).
This is a great example of a good interface. The interaction occurs as soon as the user connects to the network. Up to this point, all messages are marked in a special way: the user understands that they have not yet been delivered to the recipient, but will not be lost and will be sent on the first occasion, and nothing is required from him (the user).
In the same video, Jake explained that mobile OS (and browsers, because they work in these OS) can not always reliably determine whether the device is really connected to the Internet or not. The maximum amount of data they can get is information about connecting to a cell tower or to a WiFi router. Meanwhile, from the tower or router to the web server, there are a lot of network segments, at each of which something can go wrong. Starting with the equipment of your Internet provider, a transparent proxy server or trunk equipment, ending with something like a satellite data channel or a global firewall, like Chinese.
Imagine that you are using Jake's chat and are trying to send a message “I will call at 7:30 pm”, but the train is moving very fast and through a network of long tunnels with small stretches in the open air. Or you are connected to a public hot spot with authorization, but authorization is not passed. Or you are at the hackathon, and with you here are a hundred people. And it’s better at a concert that brought together a whole stadium, and almost everyone has a mobile phone with him who is trying to transmit something through the operator’s network. In general, there are a million situations, but the essence is the same: our phone wants to send or receive something. To do this, he calls the Background Sync service, and he, in turn, is trying to deliver our message. Even if by this time the “window” for the connection is gone, we have nothing to worry about: Background Sync will wait for the next one and retry. As a user, you are no longer interested in what becomes of the message, it’s enough to know that it will be delivered sooner or later. Now let's look under the hood of this technology.
No matter how many hops on the servers and other network elements your packages have done (and something can go wrong on each one, and you get one of the HTTP errors), in the general case only two significant processes remain. Request and reply. Both can break, so we have two scenarios:
And if the first case is almost completely covered by the possibilities of Background Sync, then what to do with the second? Imagine a case like this: you sent a message, the server accepted it and sent it to the final recipient. And your device was informed that everything is in order and the message is processed.
And now think about what will happen if at the stage from “the server has accepted and forwarded” to the very end, a disconnection occurs somewhere. What then? Background Sync will not receive confirmation that the message has gone away correctly and will try to resend it again at the earliest opportunity. The server will accept it again, forward it to the recipient again. And now the recipient has two such messages. Badly left. Well, if we are fabulously lucky, and the answer did not have time / could not get through this time, then BS will send a message yet. And further. And further. And your interlocutor will have an endless stream of identical messages (because of what he might think of something bad about you, or ban it altogether).
Now let's think about how to avoid this trouble.
In fact, the simplest solution will be some kind of server verification, but we will introduce it later. In the meantime, just see how to solve this problem at a more general level. So we will be able to apply the resulting solution not only to text messages, but in general to any issues of desynchronization.
Again, I will work a little cap. In programming such pieces, there has long been a strong trend towards the use of OOP. In general, everything is an object, and all data is moved inside object containers. And if we want to re-refer to a particular object, we need to be able to uniquely identify it. Sometimes this means assigning a name to an object (for example, an automatically generated ID with an increasing number), and sometimes we can get the name of an object directly from its properties.
A commonplace example is your phone’s contact list. Suppose people never have the same full name (assumption is so-so, but for a good example it will come down). The identifier (ID'shnik, if in simple terms) can be a bunch of "First Name". Among DB developers, this phenomenon is known as “natural key”.
The advantages of natural keys are that you do not need to store any additional data. Part of the object is its identifier. There are drawbacks too. Firstly, there may be problems with uniqueness (the example above with the “conditionality” of the non-repeatability of the full name is evidence of this), secondly, the keys can sometimes change, and something must be done about it.
Suppose you selected a field with an email address as the natural key. The user changes the email in his profile, and on your server the user's ID changes. On the one hand, everything is fine, automation, information relevance ... And on the other, other objects (for example, a repository of documents attached to this mail) still contain links to the old ID, which means they need to update the dependencies. If such changes occur relatively infrequently - there will not be any special problems, but there are natural keys that are updated much more often, and the load on updating dependencies in the database can be at least noticeable.
Let's go back to the phonebook example. There may be several people with the full name “Ivanov Vasily Petrovich”, and which of the objects by ID Vasiliy_Ivanov will return to us upon request?

To get rid of all these problems, surrogate keys are invented. They can be simple (even with an increasing natural number), they can be complex (a hash from a number of initial parameters of an object when creating + salt), they have no problems with uniqueness or change. The lack of surrogate keys is their opacity. Without calling an object, you can find out what is hidden behind ID 43135, even if all the same data is recorded inside as in the object Vasiliy_Ivanov. The computer doesn’t give a damn, it will make the request, and decodes the object, if necessary. The trouble is that surrogate keys sometimes break through into our world with you, and people have to interact with them. Memorizing them, transmitting, processing ... You don’t have to go far for an example: a phone number is a typical surrogate key for you as a subscriber. Or a series and number of the passport.
Another disadvantage of surrogate keys is difficulty in debugging or logging. Imagine that you have 20 missed calls from different numbers on your phone. A notebook only on paper. To find out who called you and when, you will have to create a table of correspondence between phones and subscribers, and then analyze the data. And now extrapolate the received experience on crash reports with megabytes of data and such “opaque” keys. It is difficult to identify patterns in them without decoding keys to human-readable values ... to say the least.
With theory, we more or less figured out, back to our problem. Since we want to make our data available offline, this automatically means that the data will be located both on the server and on the client device. That is, we will have several copies of the same data, and we must be sure that any operations with this data can uniquely identify the object with which the manipulations are performed.
When we create a new object, we assign it a unique ID. As we already discussed above, natural keys cannot provide us with uniqueness: there can be two Vasily_Ivanov objects on the server and client, and this will create a lot of problems when communicating, especially if one of them has a connection to the network. Therefore, natural keys are used when their shortcomings can not cause us inconvenience. But in all other cases, we use surrogate keys, or to be more precise, universal unique identifiers (UUID).
To be honest, the UUID is not quite unique. Replay can happen, but its probability is so small that it is easier to win a million in a lottery or an apartment by buying a single ticket than to stumble upon two identical UUIDs in an array of 10 15 keys. This probability can be safely neglected and assume that data with different UUIDs on devices are uniquely identifiable.
Well, we have dealt with the problem of identification, but we are faced with another one: we have several data sets that may or may not differ from each other. And the differences may be different for all sets on different devices. Let's see what to do in such a situation, what to synchronize, how to do it and in what direction to synchronize so that everything works like a clock.
Turn on our fantasy again. Suppose we have a mobile application for reading news and the server on which they are stored. In reality, there are blogs and RSS - they are also a good example, if anyone has a so-so fantasy. So, let's say the user launches our application for the first time, and no data is stored on the device - there’s nothing to read. The application accesses the server: "Send me a selection of fresh articles." As a result, the user gets the content he wanted.
After some time, the application is restarted, it again asks the server a fresh serving, and then, if we are a good developer and we do everything according to our mind, we have the first interesting task: we need to make sure that the existing articles are not sent to the user device again. Why do we do that? There are several reasons for this:
In general, all these reasons lead to two not very desirable things - costs and expectations. By the way, one of the unwritten rules of usability sounds like this: "Do not allow users to be in aimless waiting, otherwise they will be upset and stop using your product." So what will we do?
Well, speaking in simple language, you need to make a request to the server, which will be understood by them as follows: “I have all the articles for such and such a time, so send me something NEW”. The difference between "all articles" and "all articles that are on the user device" we will call the delta (that is, in fact, the difference). In this case, the delta will be the desired content that we want to get from the server.
To efficiently calculate the delta, we need two components:
The simplest implementation of the server part will look something like this: the server collects articles from the database, and before sending them to the device, it sorts them by date of publication in RAM. If the request from the device contains a bookmark - then we send only those materials that come after it.
It will work, but I don’t even want to talk about the effectiveness of such a decision. It is as rough as an ax. And we need something like a good chef's knife, and better - a scalpel. Optimizations are obvious. It would be nice if the articles in the database were initially sorted as they should, and not loaded with the whole volume into memory and sorted into it. Because a clumsy solution will work fine on small articles with a dozen users, and if you have articles of many kilobytes and tens of thousands of users? In general, we need a scalable, reliable and efficient approach. So, like all normal developers, we will add an index to the database of articles as well.
Bonuses from indexing articles are obvious. First, they can be ordered. If the articles will be stored on disk in an orderly manner (by date of publication, from old to new) - we will access the disk faster and perform sequential reading without unnecessary movements of the disk head, and generally speed up the work significantly. Well, secondly, we will have access to the sample. It is much better to read only part of the articles, say, from such and such date to such and such, than to load the entire database into memory and then poke around with each article separately.
Most likely, the database already has an automatically increasing number as the primary key. That is, each new article in the database will have a number that is one higher than the previous one. Perfect as an ID's: easy to store, convenient to use.
With such an ID and a properly organized database, the algorithm for the application becomes much easier. The device makes the first request to the server with a bookmark equal to 0, and receives all relevant articles. Only the ID of the last entry received is stored as a bookmark . The next request to the server includes the ID stored in the tab (let it be article 5), and the server sends us only what is newer than the fifth article. Here is a pictorial diagram:

There are typos in the articles. Or unverified facts. Or in general it is necessary to add an update or refutation. We can fix them on the server, and users already have articles on the devices. With our previous system, they will not be updated - since the tab will indicate that they already exist, and the server will not send new versions of old materials to us. In order to correctly resolve the situation, some autoincreasing IDs are few. We will add to the database not only a list of articles, but also a separate table containing only two values - the article ID and the last update time, converted into another simple number. The bookmark will not be the article ID, but the update ID. And if you have five articles, and you have made changes to the third, then its update ID will already be 6, so the next time you request a client will receive the current version along with new articles, if any. In general, everything just works and does not contain the critical flaws that the first versions had:

At first glance, everything is good - the client receives new materials, updates to old ones, nobody touches the immutable articles ... And what will happen if we take the same article number 3 and update it twice? Her update ID will also grow twice:

It turns out that the calculated delta contains article 3 twice? One actual, and the other not very relevant, but still better than the one that the user has on the device? In the case of five articles, of course, uncritically, but we have already said that the architecture should be planned so that it scales well. There can be many thousands of users, like articles, tens of updates and our articles (let it be live reports from the places of events). And we will send irrelevant versions and waste server resources, load networks and force users to pay for traffic and wait for what has already lost relevance? This is not good.
The update index we used is called incremental. This means that more than one item defines both an index range and a sort in it. In our case, we have an automatically increasing update ID and a static ID with the article number.
To solve multiple updates of the same article, we only need to make one simple change - to make the article ID a unique key for the table. That is, every time we write a bunch of change ID + article ID into the table, we will perform a check, but do we have anything else related to this article? If there is such a string, we delete it. Thus the ID of the update will be only one - with the most recent version of the article. Here is a pictorial diagram:
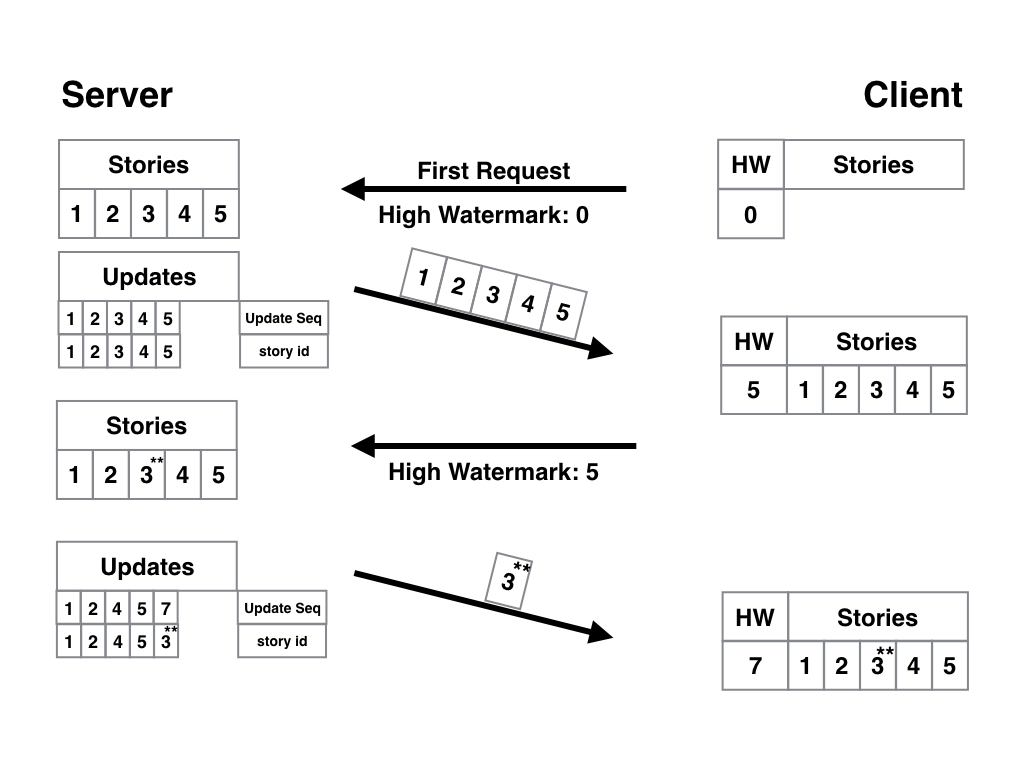
In principle, everything is clear about it, but I will explain just in case. Between the first and second request, the editor twice corrected article 3. Since its ID is unique, there can be only one entry in the update table with such an article, which means the first row that was relevant at the time of this writing, and the second, with the first update, disappeared and only the row with the update ID remained == 7 and the article with two revisions. PROFIT! Well, for complete satisfaction, it remains for us to deal with the last aspect of the operation of such an algorithm - the removal of articles from the database and from the user device.
Suppose some pseudo-prankster in a business intelligence newsletter added an article with a selection of funny kittens. The editor decided that this thing should be quickly wiped, until no one noticed, and ... what should the programmer implement?
From the data point of view, deletion may differ not much from the record update - just mark as deleted, but not actually destroy it. Well, for us, deleting in general can be tantamount to editing the article - we can at least write the line “sorry, the article has been deleted” instead of the text. Technically everything works identically - a new ID appears in the table of updates, with which the article “Remote 4” is associated. The next time the client device receives an update, it says that article 4 has been deleted. And there is already the question "how to handle" - on your conscience. The simplest thing you can do (though not all users will definitely like it) is to delete the article from the local repository. Something like this:

Today we have everything, in the second part of the article we will look at a more complicated situation: the two-way work of such a service for content synchronization, when not only the server, but also the client can work with content. On the one hand, this can all be attributed to basic knowledge, and on the other, without such knowledge, it is impossible to build a competent architecture from scratch. In general, here is a task for you - think about what problems can be with such a service and how to solve them, and then check yourself: have you found everything and are we thinking the same or not?
In addition, many interesting things await you at the PWA Day online conference, which will be held on October 11.
Sources:
And do not be confused by the abbreviation PWA (Progressive Web Apps): despite the fact that the title has Apps, the principles and technologies used in PWA apply generally to the web and to applications. The best entry to the article will be watching videos from Google I / O 2016, in which Jake Archibald talks about PWA.
')
I highly recommend watching it before continuing to read the article, especially if this topic is new to you.
In September, 14, I tweeted this piece: “Friends, CRYPTO, SYNC, DATABASE}.” What did I mean? Well, everything is simple. Making these things right is very difficult. And having made them “somehow”, you will upset a lot of people: as developers who will have to work with these crutches, as well as users, who will then put all this into practice. Simply put, some things are best left to professionals. However ... Sooner or later we will run out of available specialists on these topics, and no one can develop high-quality cryptography, synchronization or a database simply because no one has tried to do this and does not know how to do it, has not crammed and has no experience . This means that there can be exceptions in the rule. For example, you.
Become an exception to the rule
Let's try to become experts in one of these areas. Well, since we touch on the topic of PWA, we will work in the field of synchronization ... well, or you can consider these articles not as educational, but, let's say, as analytical - we consider a number of problems and their solutions that fall within the scope of “make data available offline. Something like this. Go?
The future is here
After watching the introductory video, it may seem to you that PWA is such a “cloudless future” (but with cloud technologies, yeah), and not only for one-page websites and simple services, but also for harsh content providers such as the Guardian . . But if for some reason you do not share our conviction that PWA is how the web will develop in the near future, then at least you may be interested in where the PWA track leads and what technologies will be developed in this direction. And we will also discuss this.
Little obvious
If you are familiar with the post from the AirBerlin developers, you already know how to store the elements of your site in the ServiceWorker cache. Most likely, you also have some ideas on how to store actual content from the server in the index database . You can also guess that user data (entered fields, forms, notes, contacts, coordinates, almost anything) can also be stored in the database or in localStorage to send them to the server as soon as possible. For example, when a smartphone connects to WiFi in a hotel when roaming data is disabled.
A little more I will stay with Cap and highlight the following scenarios:
- Data is sent only by the server (for example, news);
- Only the client sends data (notes to the cloud, yeah);
- The client and server exchange data (yes, the same email, services like Dropbox or Google Drive, in general, you understand).
Before we reinvent the wheel, I propose to analyze all three cases step by step and mentally step on all the rakes that can be collected.
In the introductory video, Jake showed an example of a chat application. Looking ahead, I’m saying that he used Background Sync Api to send new messages “later,” as soon as the browser deems that he actually got access to the Internet connection (and not just connected to a network where the Internet may not be). for example, before authorization in the Moscow metro network).
This is a great example of a good interface. The interaction occurs as soon as the user connects to the network. Up to this point, all messages are marked in a special way: the user understands that they have not yet been delivered to the recipient, but will not be lost and will be sent on the first occasion, and nothing is required from him (the user).
In the same video, Jake explained that mobile OS (and browsers, because they work in these OS) can not always reliably determine whether the device is really connected to the Internet or not. The maximum amount of data they can get is information about connecting to a cell tower or to a WiFi router. Meanwhile, from the tower or router to the web server, there are a lot of network segments, at each of which something can go wrong. Starting with the equipment of your Internet provider, a transparent proxy server or trunk equipment, ending with something like a satellite data channel or a global firewall, like Chinese.
Imagine that you are using Jake's chat and are trying to send a message “I will call at 7:30 pm”, but the train is moving very fast and through a network of long tunnels with small stretches in the open air. Or you are connected to a public hot spot with authorization, but authorization is not passed. Or you are at the hackathon, and with you here are a hundred people. And it’s better at a concert that brought together a whole stadium, and almost everyone has a mobile phone with him who is trying to transmit something through the operator’s network. In general, there are a million situations, but the essence is the same: our phone wants to send or receive something. To do this, he calls the Background Sync service, and he, in turn, is trying to deliver our message. Even if by this time the “window” for the connection is gone, we have nothing to worry about: Background Sync will wait for the next one and retry. As a user, you are no longer interested in what becomes of the message, it’s enough to know that it will be delivered sooner or later. Now let's look under the hood of this technology.
Cyclicity (web) of being
No matter how many hops on the servers and other network elements your packages have done (and something can go wrong on each one, and you get one of the HTTP errors), in the general case only two significant processes remain. Request and reply. Both can break, so we have two scenarios:
- Request failed;
- The request has passed, but the answer has not passed.
And if the first case is almost completely covered by the possibilities of Background Sync, then what to do with the second? Imagine a case like this: you sent a message, the server accepted it and sent it to the final recipient. And your device was informed that everything is in order and the message is processed.
And now think about what will happen if at the stage from “the server has accepted and forwarded” to the very end, a disconnection occurs somewhere. What then? Background Sync will not receive confirmation that the message has gone away correctly and will try to resend it again at the earliest opportunity. The server will accept it again, forward it to the recipient again. And now the recipient has two such messages. Badly left. Well, if we are fabulously lucky, and the answer did not have time / could not get through this time, then BS will send a message yet. And further. And further. And your interlocutor will have an endless stream of identical messages (because of what he might think of something bad about you, or ban it altogether).
Now let's think about how to avoid this trouble.
In fact, the simplest solution will be some kind of server verification, but we will introduce it later. In the meantime, just see how to solve this problem at a more general level. So we will be able to apply the resulting solution not only to text messages, but in general to any issues of desynchronization.
Identification
Again, I will work a little cap. In programming such pieces, there has long been a strong trend towards the use of OOP. In general, everything is an object, and all data is moved inside object containers. And if we want to re-refer to a particular object, we need to be able to uniquely identify it. Sometimes this means assigning a name to an object (for example, an automatically generated ID with an increasing number), and sometimes we can get the name of an object directly from its properties.
A commonplace example is your phone’s contact list. Suppose people never have the same full name (assumption is so-so, but for a good example it will come down). The identifier (ID'shnik, if in simple terms) can be a bunch of "First Name". Among DB developers, this phenomenon is known as “natural key”.
The advantages of natural keys are that you do not need to store any additional data. Part of the object is its identifier. There are drawbacks too. Firstly, there may be problems with uniqueness (the example above with the “conditionality” of the non-repeatability of the full name is evidence of this), secondly, the keys can sometimes change, and something must be done about it.
Change keys
Suppose you selected a field with an email address as the natural key. The user changes the email in his profile, and on your server the user's ID changes. On the one hand, everything is fine, automation, information relevance ... And on the other, other objects (for example, a repository of documents attached to this mail) still contain links to the old ID, which means they need to update the dependencies. If such changes occur relatively infrequently - there will not be any special problems, but there are natural keys that are updated much more often, and the load on updating dependencies in the database can be at least noticeable.
Uniqueness
Let's go back to the phonebook example. There may be several people with the full name “Ivanov Vasily Petrovich”, and which of the objects by ID Vasiliy_Ivanov will return to us upon request?
Surrogate keys
To get rid of all these problems, surrogate keys are invented. They can be simple (even with an increasing natural number), they can be complex (a hash from a number of initial parameters of an object when creating + salt), they have no problems with uniqueness or change. The lack of surrogate keys is their opacity. Without calling an object, you can find out what is hidden behind ID 43135, even if all the same data is recorded inside as in the object Vasiliy_Ivanov. The computer doesn’t give a damn, it will make the request, and decodes the object, if necessary. The trouble is that surrogate keys sometimes break through into our world with you, and people have to interact with them. Memorizing them, transmitting, processing ... You don’t have to go far for an example: a phone number is a typical surrogate key for you as a subscriber. Or a series and number of the passport.
Another disadvantage of surrogate keys is difficulty in debugging or logging. Imagine that you have 20 missed calls from different numbers on your phone. A notebook only on paper. To find out who called you and when, you will have to create a table of correspondence between phones and subscribers, and then analyze the data. And now extrapolate the received experience on crash reports with megabytes of data and such “opaque” keys. It is difficult to identify patterns in them without decoding keys to human-readable values ... to say the least.
With theory, we more or less figured out, back to our problem. Since we want to make our data available offline, this automatically means that the data will be located both on the server and on the client device. That is, we will have several copies of the same data, and we must be sure that any operations with this data can uniquely identify the object with which the manipulations are performed.
When we create a new object, we assign it a unique ID. As we already discussed above, natural keys cannot provide us with uniqueness: there can be two Vasily_Ivanov objects on the server and client, and this will create a lot of problems when communicating, especially if one of them has a connection to the network. Therefore, natural keys are used when their shortcomings can not cause us inconvenience. But in all other cases, we use surrogate keys, or to be more precise, universal unique identifiers (UUID).
To be honest, the UUID is not quite unique. Replay can happen, but its probability is so small that it is easier to win a million in a lottery or an apartment by buying a single ticket than to stumble upon two identical UUIDs in an array of 10 15 keys. This probability can be safely neglected and assume that data with different UUIDs on devices are uniquely identifiable.
Well, we have dealt with the problem of identification, but we are faced with another one: we have several data sets that may or may not differ from each other. And the differences may be different for all sets on different devices. Let's see what to do in such a situation, what to synchronize, how to do it and in what direction to synchronize so that everything works like a clock.
Let's dig a little deeper
Turn on our fantasy again. Suppose we have a mobile application for reading news and the server on which they are stored. In reality, there are blogs and RSS - they are also a good example, if anyone has a so-so fantasy. So, let's say the user launches our application for the first time, and no data is stored on the device - there’s nothing to read. The application accesses the server: "Send me a selection of fresh articles." As a result, the user gets the content he wanted.
After some time, the application is restarted, it again asks the server a fresh serving, and then, if we are a good developer and we do everything according to our mind, we have the first interesting task: we need to make sure that the existing articles are not sent to the user device again. Why do we do that? There are several reasons for this:
- These articles are ALREADY on the device, so the actions are redundant;
- Sending extra data costs us server time;
- Sending extra data costs traffic users;
- The more data, the more delay. No one likes delays.
In general, all these reasons lead to two not very desirable things - costs and expectations. By the way, one of the unwritten rules of usability sounds like this: "Do not allow users to be in aimless waiting, otherwise they will be upset and stop using your product." So what will we do?
Solve problems
Well, speaking in simple language, you need to make a request to the server, which will be understood by them as follows: “I have all the articles for such and such a time, so send me something NEW”. The difference between "all articles" and "all articles that are on the user device" we will call the delta (that is, in fact, the difference). In this case, the delta will be the desired content that we want to get from the server.
Calculate the delta
To efficiently calculate the delta, we need two components:
- Our application should be able to save information about its state somewhere, that is, know what articles it already has. We will call this information " bookmark " ( note: original: High Watermark, but there is no well-established term, and bookmark in the context of a book thing that marks the last page is quite appropriate) , why it is called that - then you will understand. In the case of a native application, this information can be stored in a local database or simply in a configuration file, but if you have a website or a web application, data can be stored in the browser, in the end, localStorage and IndexDB are invented for this;
- The server needs a list of all articles, sorted by publication date. It is desirable that this list was built as efficiently as possible, and the server could send the client any sample of articles from the specified date to the current one.
The simplest implementation of the server part will look something like this: the server collects articles from the database, and before sending them to the device, it sorts them by date of publication in RAM. If the request from the device contains a bookmark - then we send only those materials that come after it.
Note Per.: In terms of meaning, the result is approximately the same as reading a book that the author is still writing. You have read all the written chapters, forgot about the book, say, for a month. And after asking for more. The server sends you electronic versions of only those chapters that came out after your “bookmark”, and not the entire work.
It will work, but I don’t even want to talk about the effectiveness of such a decision. It is as rough as an ax. And we need something like a good chef's knife, and better - a scalpel. Optimizations are obvious. It would be nice if the articles in the database were initially sorted as they should, and not loaded with the whole volume into memory and sorted into it. Because a clumsy solution will work fine on small articles with a dozen users, and if you have articles of many kilobytes and tens of thousands of users? In general, we need a scalable, reliable and efficient approach. So, like all normal developers, we will add an index to the database of articles as well.
Indexing
Bonuses from indexing articles are obvious. First, they can be ordered. If the articles will be stored on disk in an orderly manner (by date of publication, from old to new) - we will access the disk faster and perform sequential reading without unnecessary movements of the disk head, and generally speed up the work significantly. Well, secondly, we will have access to the sample. It is much better to read only part of the articles, say, from such and such date to such and such, than to load the entire database into memory and then poke around with each article separately.
Most likely, the database already has an automatically increasing number as the primary key. That is, each new article in the database will have a number that is one higher than the previous one. Perfect as an ID's: easy to store, convenient to use.
With such an ID and a properly organized database, the algorithm for the application becomes much easier. The device makes the first request to the server with a bookmark equal to 0, and receives all relevant articles. Only the ID of the last entry received is stored as a bookmark . The next request to the server includes the ID stored in the tab (let it be article 5), and the server sends us only what is newer than the fifth article. Here is a pictorial diagram:
Updates of old materials
There are typos in the articles. Or unverified facts. Or in general it is necessary to add an update or refutation. We can fix them on the server, and users already have articles on the devices. With our previous system, they will not be updated - since the tab will indicate that they already exist, and the server will not send new versions of old materials to us. In order to correctly resolve the situation, some autoincreasing IDs are few. We will add to the database not only a list of articles, but also a separate table containing only two values - the article ID and the last update time, converted into another simple number. The bookmark will not be the article ID, but the update ID. And if you have five articles, and you have made changes to the third, then its update ID will already be 6, so the next time you request a client will receive the current version along with new articles, if any. In general, everything just works and does not contain the critical flaws that the first versions had:
Further more
At first glance, everything is good - the client receives new materials, updates to old ones, nobody touches the immutable articles ... And what will happen if we take the same article number 3 and update it twice? Her update ID will also grow twice:
It turns out that the calculated delta contains article 3 twice? One actual, and the other not very relevant, but still better than the one that the user has on the device? In the case of five articles, of course, uncritically, but we have already said that the architecture should be planned so that it scales well. There can be many thousands of users, like articles, tens of updates and our articles (let it be live reports from the places of events). And we will send irrelevant versions and waste server resources, load networks and force users to pay for traffic and wait for what has already lost relevance? This is not good.
We correct this misunderstanding
The update index we used is called incremental. This means that more than one item defines both an index range and a sort in it. In our case, we have an automatically increasing update ID and a static ID with the article number.
To solve multiple updates of the same article, we only need to make one simple change - to make the article ID a unique key for the table. That is, every time we write a bunch of change ID + article ID into the table, we will perform a check, but do we have anything else related to this article? If there is such a string, we delete it. Thus the ID of the update will be only one - with the most recent version of the article. Here is a pictorial diagram:
In principle, everything is clear about it, but I will explain just in case. Between the first and second request, the editor twice corrected article 3. Since its ID is unique, there can be only one entry in the update table with such an article, which means the first row that was relevant at the time of this writing, and the second, with the first update, disappeared and only the row with the update ID remained == 7 and the article with two revisions. PROFIT! Well, for complete satisfaction, it remains for us to deal with the last aspect of the operation of such an algorithm - the removal of articles from the database and from the user device.
Purge
Suppose some pseudo-prankster in a business intelligence newsletter added an article with a selection of funny kittens. The editor decided that this thing should be quickly wiped, until no one noticed, and ... what should the programmer implement?
From the data point of view, deletion may differ not much from the record update - just mark as deleted, but not actually destroy it. Well, for us, deleting in general can be tantamount to editing the article - we can at least write the line “sorry, the article has been deleted” instead of the text. Technically everything works identically - a new ID appears in the table of updates, with which the article “Remote 4” is associated. The next time the client device receives an update, it says that article 4 has been deleted. And there is already the question "how to handle" - on your conscience. The simplest thing you can do (though not all users will definitely like it) is to delete the article from the local repository. Something like this:
Today we have everything, in the second part of the article we will look at a more complicated situation: the two-way work of such a service for content synchronization, when not only the server, but also the client can work with content. On the one hand, this can all be attributed to basic knowledge, and on the other, without such knowledge, it is impossible to build a competent architecture from scratch. In general, here is a task for you - think about what problems can be with such a service and how to solve them, and then check yourself: have you found everything and are we thinking the same or not?
In addition, many interesting things await you at the PWA Day online conference, which will be held on October 11.
Sources:
Source: https://habr.com/ru/post/310454/
All Articles