101 ways of making RabbitMQ and a bit about pipeline architecture
Pavel Filonov (during his performance he worked at Positive Technologies )

In this report, I want to talk about the intersection of RabbitMQ and Pipeline architecture, and how it relates to the work of our company.
First, a little as a prologue. This is the nice part.
')

The scene, unfolding on a weekday in the office, leads us to a very pleasant reflection. We are faced with a smart task, a new system. Few things so much excite the mind of the engineer, as the request to develop a new system. Not to fix something old, not to adapt something old, but to create something, in a sense, almost from scratch.
Together with this task comes a whole series of problems.
Problem number 1. We continue the scene.
They bring you this:

You look, ask: "Where are the requirements?".
They show you: “Well, here they are!” (See on the slide).
This is sometimes the requirements for a new system. Almost everyone had to work with such formulations, you understand the problem that is connected with it. But sometimes you have to start with this. Let's try to start.
There was a wonderful report on the NLP-processing of natural languages, here it will greatly help us, we need to select the grain from this coherent text. I will try to do it like this:

Highlight something key, something that will help us make the right choice, and build the system we are asked for correctly.
The first thing I would like to emphasize is the word "events." In a sense, I want to contrast them with the word “request” - request, to show the difference. When we talk about request (request), someone who is sitting on the other side, the one who sent it is always connected to the request, a very impatient person, a robot, a browser, a program, he is waiting for an answer from us. He is waiting for an answer from us quickly. This is his greatest desire - to get an answer, get it quickly. This is when we talk about requests.
When we talk about handling events, a slightly different pattern is appropriate here. There is no this impatient robot, the person who sent the request. There is simply a system that sends events, logs, metrics, statistics to us — a large enough volume, network traffic ... We are not required to instantly answer a question. We are asked to manage a lot and quickly process them, process them in different ways. This is the most painful place - we cannot sometimes predict in advance that they will ask us to aggregate something, calculate intensity, sum up something, and most likely ultimately save it somewhere. But the most interesting thing is that many people came up with the fact that they began to solve the problem, there is an active development, and then they resort in the middle: “And also, please add this!”.
When you are immediately warned that this will happen, it is advisable to put this in the architecture of your system as a requirement so that it can flexibly change and be updated to what you will be asked to do.
“From different sources” is such a nuance that we will need to be able to support different input protocols.
“To make a prototype” - they love very much now, they love very much that they should do something quickly and show something quickly. Who agrees that prototypes should be thrown out then? And who then had to let them in production? This is also a problem, and we must be ready for it. And if there is such an opportunity, it is advisable to start this problem right away: you will make a prototype, then you will start throwing it out, but you cannot do it quickly - it is very difficult to take something and quickly rewrite everything to something more solid. Most likely, it will have to be replaced in parts - it was a little non-living system, to tear out some pieces from it and replace them with other functionally fully equivalent, but more substantial ones ...
“It should work well and everywhere” - I don’t even highlight it, this is understandable. About "everywhere" - a difficult moment. Who faced with the development of different operating systems? This is a big problem, it can greatly limit the range of your decisions, and this should also be taken into account immediately when designing.
We tried to isolate the grain, and we will now actively rely on it. Because the next problem arises.

I am often resorted to and asked: "Tell me, how did you come up with it?" I look at the questioner and say: “You know, I generally think up very little myself, practically for any task that they bring to me, I immediately have a whole bunch of solutions - 3, 5, 10 and more. My most important problem is not to come up with a solution, but to choose the most adequate, the most appropriate for this task. ” I usually answer with such a joke that everything is already invented for us, for us as engineers, in my opinion, modern engineers should rather be able to make the right informed choice that we encounter even at the very first step.
We want to create a system. She must have an architecture. Beautiful word. It is usually expressed in pictures, so here I tried to present pictures of some of the most standard architectural patterns from which different systems are built.

I think each of you will now send yourself to some of the parts of this scheme. Someone will say: we are in the upper left corner, and we work in the upper right corner, someone works in the middle, everyone associates himself with this or that picture.
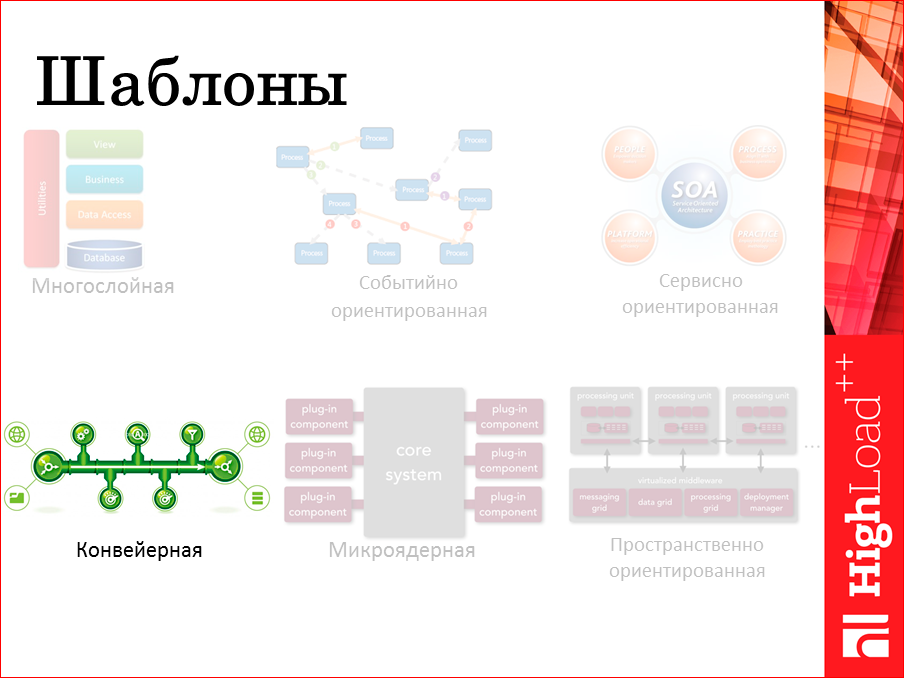
Specifically, in this report I will talk about the pipeline architecture as an interesting way and approach to event handling. When there is no other side that is eager to respond to a request, when in some very abstract sense, all we need to take is to drive our data through a whole series of processing and eventually save it somewhere. And it is advisable to do it as quickly as possible. Here, "as soon as possible" requires a detailed analysis.
Where do we usually slow down? Where usually our bottlenecks? There are two most basic criteria - CPU-bound processor and I / O-bound output. And, surprisingly, often we do not rest on the network, sometimes we do not rest on gigabits, sometimes even at 10 gigabits, we just rest on what we need to wait. This is especially well seen on architectures built on the basis of "request-response" - we sent a request, we are waiting for an answer. In a bad case - we just relax, in a good way - we try to somehow switch to another task, work on it, then go back. Now, if you don’t have to wait, it would be great - don’t even have to switch to another task, you just made a piece of your work and passed it on. No expectations, no delays associated with this, trying to maximally rest against the actual processor, just turn it into such a pan for cooking scrambled eggs.
If we remember where it came from ... For example, from the automotive industry, where there is just the same idea for someone to wait for as little as possible. Each section performs its role and transmits the result further. Suppose you made such a choice, we considered that this template is best suited for solving our problem, for building our architecture.
Question number 2: how are we going to implement this architecture? What means? What kind of middleware will we need to link disparate handlers together.

Here the choice rolls over. This is not all that is, this is all that climbed on the slide.
I’m hardly likely to have time to tell about the advantages and disadvantages of each of these systems and specifically substantiate why the choice was made in the direction of RabbitMQ, this will partially be seen later from the report, with specific examples. Having considered various options, even the funniest, topmost left - take it and write everything manually, just on the sockets - there were also such experiments. But in the end, during all the experiments, the choice was made in the direction of this message broker.

I really liked the report of Dmitry, who compared the In-memory database. He talked about the right engineering approach - measure, do not believe advertising, you definitely need to measure. He mentioned another important fact, before measuring, you need to initially narrow down and choose which databases you will measure between you, you need to initially narrow the search. Usually they repel, proceeding from the functional, who does what.
I want to raise another problem here and say that it is also worth paying attention to it - how much will this technology survive? Looking at how the modern technology market is developing, I am getting a little scared, I am afraid that one morning I will open a news line and see an article “7 new SQL databases that you should study this week”. If they appear so quickly, they will begin to die at about the same speed. Hence there is a desire when choosing to rely on technology, which with some probability, with some degree of confidence, will live a little longer. From this point of view, RabbitMQ is interesting not as a product, but as a technology that relies on the AMQP protocol, a lower layer, which has already found quite a good use.

Here from the official site of the AMQP protocol official users. It is very interesting to see Microsoft Azure Service Bus and Google.
Google, in general, publishes an official announcement that it simply builds its SQS-database service on the basis of RabbitMQ.
Microsoft Azure just implements the AMQP protocol, their implementation obviously seems to have its own.
VMware is one of the pioneers of the AMQP protocol and the RabbitMQ system, and uses it very actively within its solutions.
Those. This is such an advertising slide. Do you know when he helps? Imagine that I am also standing on the stage, and you are stakeholders, you are owners of companies, investors, you are now going to give money for this, and you need to be convinced that you will give money. These slides really help, they immediately see familiar names and they like them. Therefore, you can use it for promotional purposes.
A couple of pictures that I need further, as the basic definitions and terminology.
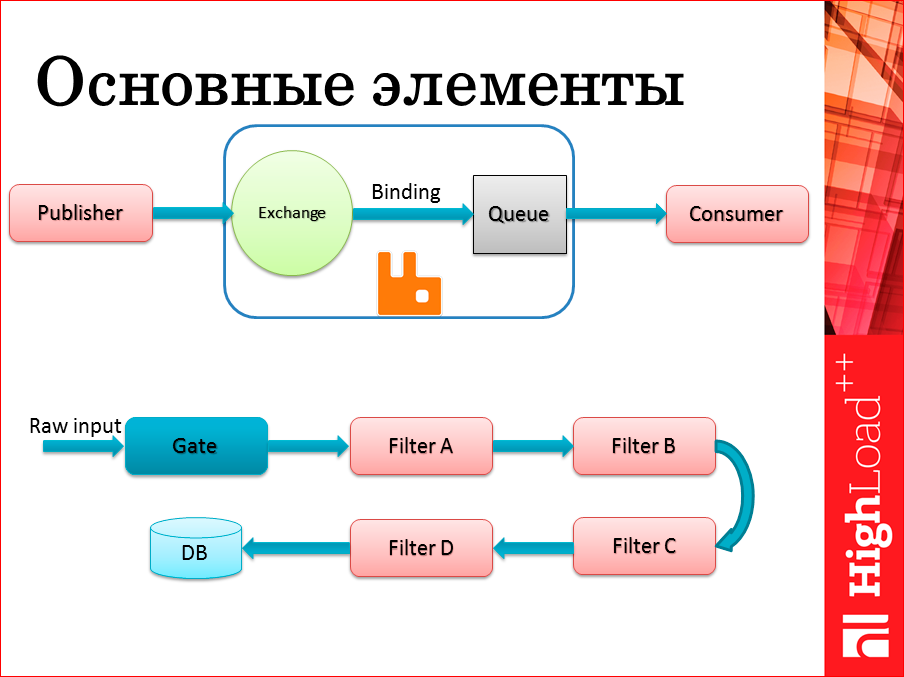
The first picture is for those who are simply not familiar with the main entities inside the AMQP protocol and in the RabbitMQ system. On the left - Publisher - writer - a system that writes something in this queue. There are two separate entities inside RabbitMQ itself: the first is a circle - exchanger - Exchange is an entry point, usually all messages of the systems are published there. The second important element is the queue, where these messages are then stored and the link between them - Binding, which allow you to rather quite flexible and interesting way to route your messages between different queues.
In the future, a little more talk about what methods of routing are available and which ones can be used in this or that case. For now, just dwell on the fact that there is such a binding. From this point of view, Publisher does not always even know in which queue he writes, he knows: we write to events, we write in statistics, we write in metrics, we write in the log, how many there are really behind this queue, he doesn’t really need to know. From the point of view of the writer, this is very convenient.
The reader, on the other hand, it is desirable to know where he will specifically read, so he is tied to one or another queue.
And if we use these Q-queues as buffers that link different handlers to each other, we get a picture at the bottom of the slide. This is a very simple way to portray the Pipeline architecture, a “pipeline” type architecture, when there is a stream of raw data that passes through different processors, between each of the processors, in fact there is this queue, and they, each performing their own piece of work, run the data up to, say, , Database. To this picture and designations on it, I will continue to return.
Let's concisely try to walk. What good we get:
- Asynchronous processing - do not expect anything - did your job, sent the result further - very nice.
- Simple add handlers, almost on the fly. Yes, actually, on the fly. Reconfiguring the system on the fly is easy. Need to insert
In the middle of the pipeline is something new. You do this even without rebooting, moreover, sometimes neither the writers nor the readers may not notice. Writer can
notice that he started writing to another place. - Flexible routing. In fact, since the writer doesn’t really know where he is writing, we can set up to write in one queue, immediately in two, with
some kind of scaling, with some kind of sharding strategy between these lines. We will definitely talk about some strategies. - Convenient debugging is a very important factor. If you are an architect, while writing code, then when designing a system, you will try to take into account what later
people will have to program it, it means they will have to debug it, it means they need to provide convenient ready-made tools. One of the most
convenient tools - that you can take on the fly and copy all messages from the queue, just take a copy. This makes it very easy to
reproduce almost any situation, as an example of convenient debugging. - Scalable readers and writers - from the queue can read a few, write to the queue can a few, almost always add on the fly.
Very pleasant and important fact, especially for loaded systems. - Do not forget that in addition to useful work, now there is some additional load - you need to transfer data between different processors
and you can rest on the fact that the queue broker itself will not cope with the load. An important factor is that he himself at least could
scale, and this RabbitMQ provides very well. - Another nice moment - resistance to reboots and failures. Since there is a mode of recording the entire contents of the queues on the disc with a certain period,
you can protect yourself from such an unpleasant situation, for example, that the node accidentally rebooted, or you have a lot of data in the system, and you are asked to
reboot for some manteins. The fact that you do not lose data at the same time is a very pleasant moment.
If you were stakeholders, most likely this would be the end of my report. I told everything, I said what we would do, then I want to ask for a few person-years, an unlimited amount of coffee, cookies, and we will make it for you. But here, after all, a conference of a slightly different type. Here, first of all, the engineers gathered, and the words that I said before, you listen carefully and think: “So, where is the catch? Where are the problems? There can be no problems. ”
If these are highly loaded systems that actually function with users, there should be problems there, so I’m ready to move on to the second part of my report.
What to do when they come running to you with problems: “Chief, nothing works! What we came up with is nonsense! ”?
First, do not panic. If you have made your choice, it was originally realized, hold it to the end. We must look at the engineer, looking up from a cup of your favorite coffee, and begin to solve problems.

For some problems, not for all of course, I want to go through, to tell what specific solutions we have chosen.
The first problem is bandwidth. It turns out that the system capacity depends on its configuration. Exchange types that provide different routing:

Some allow you to just do publish subscribe - scatter in all queues. Some allow, depending on the routing keys, just strings, to say: “So, red - in this queue, green - in this queue, debug logs - in this queue, warning logs - in this queue”, etc. This, for example, Direct.
Topic - more flexible routing, more complex, it allows you to route by masks, for example, asterisks, lattice use. It works very well in terms of functionality. Does not work well in terms of bandwidth. There's just a more complex data structure inside.
There is an interesting article by the creators of RabbitMQ, how they chose long prefix trees, or non-deterministic finite automata. They chose what they considered to be the best, it still turns out that, focusing on such flexible routing, we can not reach the characteristics that we need, so it is necessary to take this into account.
The fourth exchange is Consistent-Hash. He behaves even better than the rest. Although it would seem more difficult. Some kind of segmentation, sharding, complex queue selection algorithm will be obvious ... The advantage is that it works with numbers. The first three work with strings as routing keys, and the last one works with numbers. This allows him to win some extra bars.
I made these measurements ... I would consider that this is an average machine, I didn’t configure anything extra, this after apt-get install works like this. Generally speaking, not very good. 35 thousand messages per second (messages per second), well, somehow I would like a little bit faster.
What could be the reason for such low numbers? In fact, with a technique that many people know, but for some reason very few people use it. Batch processing.

When you know that you need to do about the same work many times, why don't you handle not one event, but whole packages, whole blocks, whole packs? For example, how does Kafka from ZeroMQ. For this they smiley. They are great, they do batch processing unnoticed by customers. You think that you are posting messages one by one, and if you look at how they fly over the data bus, they are already flying in batches. Therefore, we immediately get a fairly good bandwidth criterion.
Smiley in the opposite direction, because not our choice. For them, we are happy, but it gives us nothing.
Let's do it yourself - this is not very difficult, this time. And second, by making the implementation of the packages ourselves, we begin to better manage it - how many messages we want in the package, how long we want them to be typed. If in the case of Kafka from ZeroMQ this is deep in the driver and it is not always possible to climb there, then, having our own implementation, we can manage it quite flexibly and well.
And a very negative smiley - we increase our delays.We begin to collect packets, do not send further messages that are already ready, which means we increase their delay.
As I already said, maybe this is not very critical for the event processing system, we are still talking about delays of the order of tens of milliseconds. For a system of the type, the response response is critical, but if we then look at event reports once every 10 minutes, or once an hour, then a delay of a couple of tens of milliseconds can probably be tolerated for our system.
Here is a small measurement, the result - what will happen if we start to increase the size, here - just bytes in each message that we send to the bus.

The blue graph is the bandwidth in messages per second, it drops. We start with 35 and quietly leave below, when we are already starting to send such healthy messages, one MB at a time. But if we look at the bandwidth schedule in bytes per second, they are easy to convert to messages per second. Suppose you have a message on average 256 bytes, or 1 Kbyte, it begins to grow. Grow starts very well.
I scaled the red graph here, it is divided into 30 thousand so that they somehow look together. Let me help you with the calculation: if now all this is multiplied back, then this peak reaches 10 Gbit per second. This is a loopback interface, this is not a real network, a little bit here is an artificial example in this regard. One writer, one reader - is also artificial. But this is how the system works out of the box. Those.already on the loopback interface, you can immediately achieve a throughput of 10 Gbps. Without making any particularly detailed tuning, perhaps, in terms of the size of the packages that we will process. A smart decision, I strongly advise you to remember that if the system does not do it itself, we can do it for it.
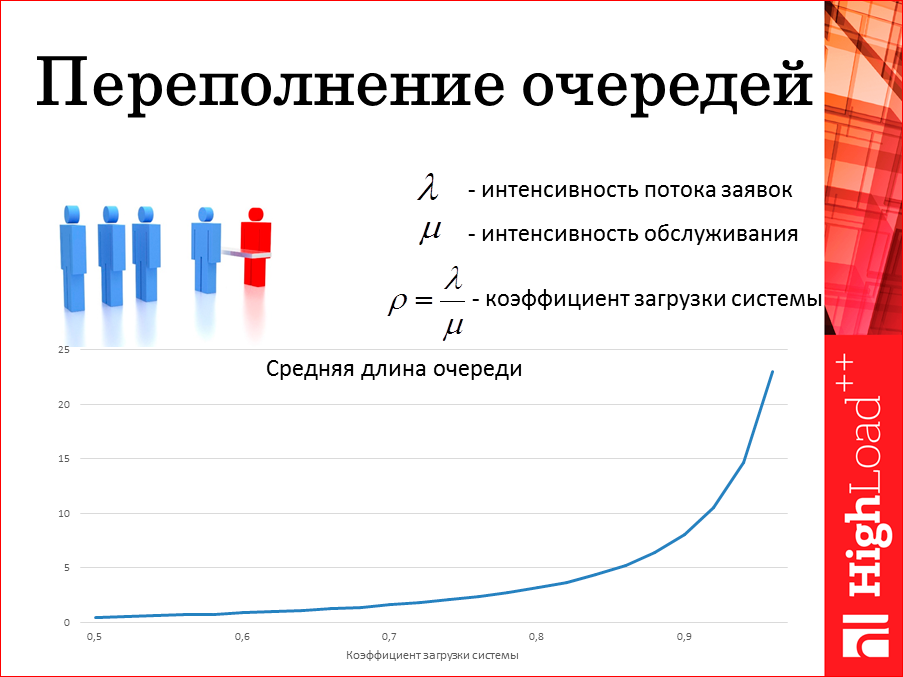
Next problem. It usually occurs in systems with queues. You just have to be ready for it. You need to know what you will do and admit to yourself. When will the line start to overflow? Well, everyone remembers these queues in stores, the big ones don't stand up. Here I drew a theoretical graph. The theory tells us that if you have a service intensity, how much time do you have to process in a second, if you have a message flow rate? How much do you write per second? You have a system load ratio. When he is a unit - this is very bad. A very interesting fact that gives the theory. When he is not even a unit, when he is even very small, the queue is non-zero. There will always be something there. This is not to be afraid. There, most likely, there will be something on average not very large, there will be append,it will be deducted from there, assume that these queues between the system should always be zero-based, i.e. messages should fly through them instantly - they would not be needed then as buffers. The only thing that should be tried is not to reach the right border.
True, we cannot predict the future ... What if a moment begins when a surprising amount of data is suddenly poured into us, i.e. the system is not ready for such peak loads, how will it behave in this case? Those.we do not have time to deliver the server and launch new nodes.

There are several ways, depending on your specific task, you can choose one or the other:
- The first is to flush messages from memory to disk. Well, it's nice, though, until the disc is over.
- The second point - you start to block writers. This is very good, you try to write a little less, to enable readers to do their work.
- An unpleasant moment - as soon as we connect the disk to the entire system, active work with the disk, everything slows down very much and
we most likely will not achieve high bandwidth . - But a nice moment - no one is falling. Once in many years of operation, we managed to fill up the whole system. RAM is over, then the
disk is over. She did not fall, we turned it off, she could not get up. It took to clear the data from the hard drive and that's it, it took off and went further. The data,
unfortunately, was lost during the experiment.

An interesting strategy is how to prevent this?
- : ? . , ?
, , - , … , ,
. , . . - Second moment. . , , ,
. , , ? -
2 , , , . - . RabbitMQ flow control. ,
. «, !».

At the beginning of time, when everything is fine, we have Filter A. One writer. He writes to the queue. There is a reader from this queue, the queue is small, let's say 10,000 messages.
The situation is changing, the queue grows grows grows. 10 million is no longer very small, somehow I want to do something about it. The fingers RabbitMQ flow control strategy is as follows. Let's hold it. The implementation, if I understand correctly, is very simple, the system begins to insert random waiting, specially selected when reading the socket from the publisher, in a sense, even reducing the intensity of network packets coming from it even at the network level.
I tried to portray here that lambda has become small. She starts to write more slowly. We give the reader an opportunity to have a little breath, to quickly clean it up. As soon as the queue returns to its frame, this stop signal is removed, the writer begins to work as before. If it was something peak, temporary, here on this temporary trajectory, it will save us. If not, and this situation is constant, we postpone it to the very border of the system - to the point of entry. It already depends on who writes us. If a UDP stream comes to us, there is simply nothing to control - everything is by. If there is a TCP stream, you can take your strategies. The fact that inside the system this balancing takes place automatically between readers and writers is a very pleasant moment.
To the next problem. Scaling.

There are 2 aspects. The first is what is called Stateless filters. Filters - they are handlers or stateless handlers, something very simple. He is at the entrance of A, he is at the exit of B, without memory, a smart thing. The most convenient primitive that you can work with is scaled with a bang. You just add them, right on the fly, how much you want, how much you need within the same process by threads. Within different processes on the same machine, within different processes on different machines, the main configuration file for them is appropriate, so that they can work with it. This is my favorite part - scaling.
The second part is my least favorite when handlers with states appear - Stateful filters, adders, all sorts of aggregators.
An example from our practice will tell. We consider unsuccessful attempts to log in for Vasya and for Masha. For Vasya, one counter, for Masha - another counter. We are interested in situations where more than one hundred unsuccessful attempts under the same user occur within two minutes. Choosing a strategy like Round-robin — we just scatter along any processors — it's impossible here. We must somehow ensure that all events related to Masha go to one system, to one counter, all events connected to Vasya go to another. Then we need to slightly over-complicate the top picture for the sake of such a good purpose. First, each handler has its own queue. Suppose A1's queue is Vasya's logins, A2's queue is Masha's logins. And there must be some kind of router - Router, which can spread between them.You can build your own. He has a problem, he will have to know then about the number of queues that arise there. You can use the built. In RabbitMQ exchanges, there is just such an exchanger that implements a consistent hashing strategy, which itself will serve as this router.

About Statefull filters. Why I don't like them.
First, you need to write a lot of code, more code than for stateless handlers. Because this state in this handler will need to be able to save somewhere. Something will need to somehow be implemented. At this point, the segmentation, she sharding. It will be necessary to complicate this picture, to enter each turn, somehow to scatter on these lines, somehow plan it, think it over. If this work did not need to be done, in general, it is advisable not to do it.
If you encounter such a situation that you cannot make a handler without a state, you will have to deal with this problem. One of my most important thoughts in the whole report - if you can do without them, try to do it. Otherwise, you will come across an extra pile of problems that can be avoided. If you cannot do without it, you cannot transfer this problem to the database. If we needed network locks, network locks are very expensive. And at high speed with network locks to process data - we could not think of such an architecture. We were able to come up with a standard way, when each processor has its own state, it is right in its memory, it is exclusive, it owns it, no one bothers it, it completely processes it.

If we have come to the conclusion that we need to do segmentation (sharding), then what paths can we go?
By the way, in general, this problem is very well described in the last year’s report by Alexey Rybak and Konstantin Osipov, there is a more detailed description, and I’ll tell you about some points.
The first way of such a sharding is very simple - we take the key m, we calculate the hash function, we take the remainder of the division N - the number of our handlers. All we know his number, let's go. For the same keys will go to the same handler. Why emoticon down? When N changes, everything becomes very bad. All these counters just go astray. Events are sent in a completely random order, and somehow we cannot control this process at all. They said many times, I will not repeat what it is, just on the fingers - this is also similar to the hash function, but it tries to solve the problem of the first hash function. As soon as you change the number of handlers, something will go not where it went before, but not so big, this algorithm will try to do this data migration much less.
You can use your own, but you can use ready. In RabbitMQ there are as many as 2 Sharding plugin. One allows you to say which of the handlers with which area is ready to work - let's do more with this, let's less with this. Unfortunately, this plugin has to be installed separately, it is not always convenient, because you need to compile Erlang code, on the production system it is not always convenient to do it.
What is nice, the fourth method - consistent-hash-exchange - goes straight to the default installation, it actually implements this consistent hashing algorithm, allowing dynamically when changing the number of processors, and therefore the number of queues, to choose which of the processors to send the data to. But when their number changes dynamically, it tries to make the resharing go as gently as possible.
Thus, I come to the conclusion of the report. 2 main ideas that, I hope, I reported:

No need to invent anything, almost everything has already been invented, you need to choose, but you should not assume that choosing is simple. It is very difficult to choose. In my opinion, it is more difficult to choose than to invent, it should be done with great care.
And when you made your choice, there will be problems. My experience shows problems will be. But do not be afraid of them, be confident in your decision and try to overcome all these problems with your solution.
— HighLoad++ . 2016 — HighLoad++ , 7 8 .
, , :
, , , , — !
- HighLoad.Guide — , , , . 30 . !
Source: https://habr.com/ru/post/310418/
All Articles