How we made even load balancing on the frontend cluster
Yuri Nasretdinov ( youROCK , Badoo )

Deciphering the report of Yuri Nasretdinov at the HighLoad ++ 2015 conference. Yuri will tell you about how Badoo (the largest social network for meeting new people) made an almost perfectly smooth load balancing on our cluster. Give him the word ...
To serve the number of users, the number of requests per second that we receive, we have about three thousand servers, and PHP-FPM specifically accounts for 70 thousand at the peak.
About how we distribute these requests across our cluster, I will tell.
')

Briefly - about what I will tell. First of all, I will tell you how “from a bird's eye view” the routing of requests on our site is arranged. Then I will tell you what, in general, there are algorithms for balancing; about how we did the balancing before we made the automatic system. I'll tell you about this automatic system, well, there will be some conclusions. I also wanted to say that this system will be posted in open-source after this report.
Let's start with architecture.

This slide shows the path that the query passes when you type badoo.com and, accordingly, get on our website. To begin with, since we have more than one data center, there is a system from the company “F5”, which is called “Global Traffic Manager”. It is able for different continents to resolve DNS queries to the corresponding data center. Then, when the IP address has already been received, the traffic arrives at the Local Traffic Manager system of the same company. It's just a “piece of hardware” that can take on all the traffic and distribute it according to the rules that you set, distribute it to different clusters. And we have two types of traffic - this is mobile traffic and traffic on websites. For mobile traffic, we still have a separate proxy that accepts connections from mobile clients and holds them. It is not shown on the slide, but it is he who communicates with Nginx, which in turn distributes requests for PHP-FPM. For a website, LTM can balance such requests directly.

Thus, all this is served by either PHP-FPM, or in the case of the web, this is Nginx + PHP-FPM.
Why, in general, need balancing and what is it?

If the number of requests you have on the site is more than one server can handle, then, in principle, you need load balancing in order to distribute traffic across multiple servers. And also, in principle, quite obvious, but it is still worth noting that the more evenly distributed the load is on those servers that are in the backend, the less servers you need to maintain traffic peaks, and the better is User Experience, because As a rule, the response time depends on the server load, and the higher, the smaller the server is loaded.
What, in general, are the algorithms?

I consider frequently used algorithms that are used to balance web traffic. I divided them into four categories.
The first type of balancing I classified as "stupid."

The simplest balancing algorithm is not to balance the load at all, i.e. Your load is perfectly supported by one server, and you transfer the entire load to this server.
Further, a very simple algorithm is Sticky sessions, when requests from the same IP address or from the same client go to the same server. This is an easy-to-implement algorithm and, in principle, it has a lot of advantages, especially if your application is not in PHP. But he also has a lot of pitfalls, which I wouldn’t like to talk about now, this is a topic for a separate report.
And, of course, there is a very simple way of balancing - this is a random choice of server. He, in principle, works well, especially if you do not have a lot of servers and simple requests. But there may be bursts of loading on some specific servers due to the fact that you choose them randomly, and 10 requests may come to the same server, and the second server will not get anything.

And, more commonly, this is the Round-robin algorithm. This algorithm is more complex than random balancing, but has the most important advantage in comparison with it - it is the load uniformity, i.e. if you have the same server and you have the same requests, then you will get a perfectly even balancing with this algorithm. Those. this algorithm is that you send each next request to the next server, and thus it is easy enough to show that the load will be uniform, there will be no bursts.
But life is a bit more complicated and in practice such an algorithm is used, but with some modification.

We also use it, this is a weighted Round-robin, when servers are not the same, and you have to somehow make it so that more requests fall on those servers that are more powerful and can hold a large load. This can be implemented in different ways, for example, repeating the same server several times in a regular Round-robin. Thus, the greater the weight of the machine, the more repetitions.

A group of algorithms, which, roughly speaking, I referred to the category of "smart", which somehow must monitor the state of the system and balance the load, based on this. For example, a very common algorithm that is used a lot where - Least Connections, when your balancer sends the following requests to the server with which the least connections are established. This also allows you to achieve a uniform load, because it is assumed that while the connection is open, the requester is processed.
Since the servers are not identical, there is a modification of this algorithm, which takes into account the weights - Weighted Least Connections.
Weighted Round-robin assumes static weights for servers that are set once and do not change after that. But strictly speaking, you can change them over time. And this is what I will discuss next.
There are some other algorithms that can also be mentioned.

How did we distribute the load before we wrote the automatic system? This was done by administrators' hands - roughly speaking, the system administrator comes, adds 10, 20, some servers to our cluster and “see” what weight to assign to him based on processor frequency, number of cores, memory timings, etc. He edits a config that looks like this in Nginx:

It can be understood that here it is quite difficult to see something and even more difficult to do something so that the download is smooth. Here is a load chart for several months on different servers:
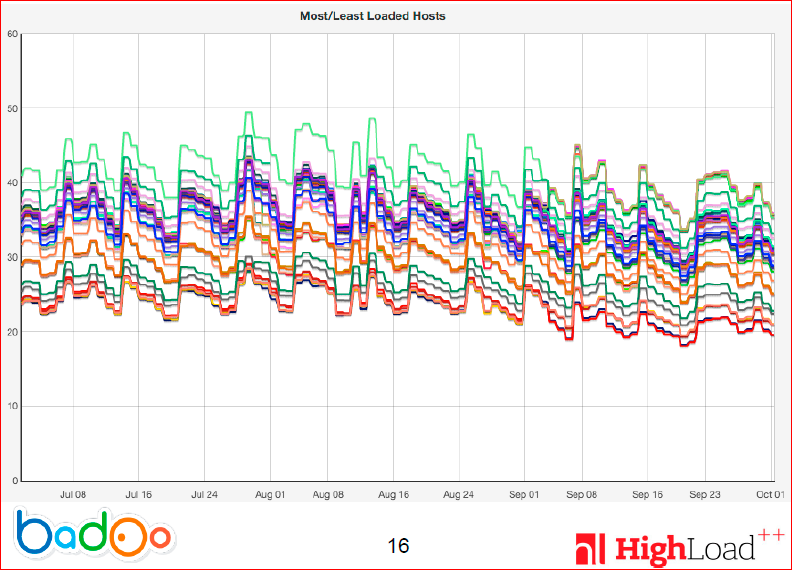
For different servers, CPU usage is shown in different colors. You can see that the lines of different colors are strictly above each other. Those. the load is stable, but it differs quite significantly from different servers. It differs somewhere by 20-30%.

You probably ask: why admins could not tat weight with their hands? In fact, there are a lot of reasons. The main reason is that a very large amount of time passes between making changes and getting some result. Those. You can align each line separately, but you will need to do 200 iterations and the update should not be done too often, for example, we do it no more than once every 15 minutes. In general, this is a very big effort and manual work that I would not like to do. Therefore, we decided to do it differently.

When traffic began to grow on our website, especially on a mobile cluster, we decided to do automatic balancing, which allowed, in addition to load balancing, to have fewer servers in order to serve traffic at the peak, and not to run into 100% of the processor, and and it is desirable to keep the load less than 75% (conditionally).

I, again, highlighted two main approaches to the selection of weights for the balancer:
- This is the calculation of some kind of performance index and the task of static weight servers;
- And the opposite of the first - based on the state of the system, evaluate which weights should be given, and, accordingly, give out weights in the process of work, watching how it behaves.
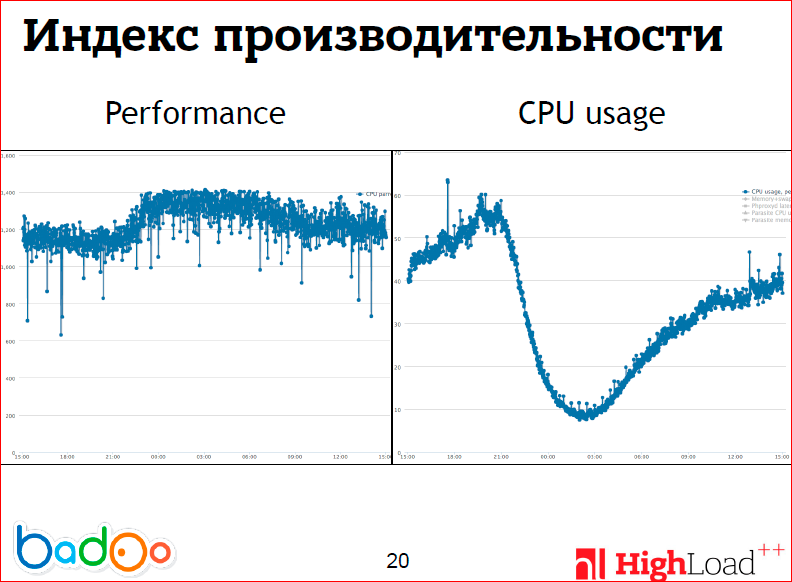
On these two graphs, I tried to portray the problems with the first approach. The left graph shows the daily performance of the machine, i.e. we wrote a script that runs a certain number of cycles of our application and measures how many were per unit of time (per second), and it runs on one core. You can see that the performance per se, at least for one core, depends on the load on the system, and this is very strange. For example, on AMD processors you will not see this, but we use Intel processors, which include hyper-threading. The slides are not very well seen, but the performance drawdown starts somewhere after 50%, while the server continues to serve the increasing load and does it quite successfully, and in our case, hyper-threading works very well, we leave it turned on. Those. I wanted to say that to give out one weight is actually quite problematic, because the performance of the machine changes with time.

And do not forget about the fact that many use virtual machines, which have the concept of performance is a very floating quantity, i.e. It is not very clear what weight to take.
Unfortunately, this approach, despite the fact that it is very reliable (that is, there is nothing to break, nothing to break down), it did not work very well in our conditions. And, actually, this algorithm is no different from the manual selection of weights, which admins should do. Therefore, after many iterations, we have come up with the following algorithm.

Assume that the processor load depends linearly on the weight, which, in principle, should be performed in most cases. Those. your application starts proportionately more “is” processor, the more requests per second it receives, if it is able to process them. And then we get a very simple formula - we multiply the current weight by the ratio of the average load across the cluster by the average load of the machine. It turns out a very simple linear formula. Thus, we try to bring such a signal into the system that would bring it to a steady state, i.e. reduced the difference. It is clear that when there is no difference, the coefficient will be one, and the weights will not change.
Let me remind you how the graph looked like (albeit 3-month, we, unfortunately, do not have more accurate data to give daily charts) before we implemented this system:

And this is how the graph began to look after:

This is a daily schedule.
You can see that, with the exception of a couple of servers, the load on which is more like a sine than something else, almost all servers (and there are about 200 of them) have merged into one line. In principle, this was observed gradually - as soon as we switched on this system, it began to converge in a very thin gap, and the difference between the most loaded and most unloaded server is very difficult to see on the graph.

This approach, in fact, has a lot of problems, i.e. Despite the fact that it gives good results, it would be strange to finish the report on this and not tell you what is “wrong” with this system.
First, it is clear that since you adjust the weight dynamically, you can accidentally set the weight on the machine such that the machine does not cope with the load, and it will be turned off from the cluster. If there are any problems in this algorithm, then you can cut down the cluster, despite the fact that it is able to handle the load.
Then, there is an interesting problem - the fact that this algorithm is quite problematic to embed Nginx itself into LTM, i.e. probably, in Nginx it is possible, and LTM is just a closed “piece of hardware”, which can be used to communicate new weights in some external way.
And there is such a problem - these weights can, in principle, not be applied, i.e. you give the system some new weights, but it continues to work with the old ones, you continue to apply your formula, but nothing happens.
Then a separate problem - how to remove cars? It is, in principle, not directly related to even balancing, it’s just a problem that cannot be solved here.
Also, LTM has restrictions on a maximum weight of 100, and perhaps this also has some problems.

First, how to make something more stable from such a very simple formula that is not subject to overloads, i.e. If your server had a 50% load 15 minutes ago, you gave it twice the load, then this most likely means that it has 100% load, but not the fact that it will serve all requests correctly at that.
The idea is very simple: do not change the weight too much per unit of time. In our case, we get a more or less flat line of server load, if we build one point in 15 minutes. Those. Weights should be updated no more than in 15 minutes in our conditions, otherwise there are very large temporary errors due to uneven user load. Accordingly, we impose restrictions on the coefficient by which we multiply the weight. This, again, is chosen empirically - we add no more than 5% to the weight each time, and since this is an integer, it means that the minimum weight should be 20, i.e. 5% of it is one. And also, to avoid situations where the cluster is not loaded, for example, servers temporarily make mistakes in requests or some other problems, do not drop the load from those servers that are able to service something that is too fast ...

What to do if your feedback is broken, i.e. weights do not apply? It's pretty easy to understand that the formula I give will increase the difference between the processor load the more, the more time has passed. The point is that if the weights do not apply, you will see a difference, which is not there, and you will further and further increase the load on weak servers and, on the contrary, not enough load on the strong ones. This is not what is needed.
In our case, we solved the problems by the fact that we put restrictions on the minimum weight, which falls on one core of the machine, and on the maximum. Those. we believe that the difference between the cores — the most powerful machine and the weakest — will be no more than three times. It seems that this is quite logical, i.e. Why keep servers that are three times different in performance? And so we limit the problems that will arise in case of violation of feedback. Those. This does not solve the problem, but if you have, for example, less than 30% load, then this approach will work.
Also on the total weight and on the number of cores - simply because they should not be too large.

Another question: what to do if you need to remove a machine from a cluster, i.e. the machine no longer responds to requests, but this is possible in two cases - if the machine is overloaded, i.e. there are too many requests for it, and the second problem is that the car really “died”. The fact is that when you reach the peak of traffic, and if you suddenly at this moment have any problems on the cluster, then most likely they will be on all servers. And simply, because the servers do not respond by heartbeat, you should not delete the server, because You can cascade off the entire cluster in this way.
In our case, we decided to use just the information that we have about the CPU load at the peak. We are looking to see if the system will cope if this server is removed from the balancer and if it can handle the traffic peak load. If not, then we leave the server. In principle, this logic should be enough so that you do not have problems with processor overload.

And finally, briefly about what I wanted to say.
For web requests, weighted round-robin works very well. At least for our requests, i.e. when your requests are more or less the same, you don’t need to invent anything else, it works.
Again, in our case, to pick up the weights statically, you need to put a lot of effort, and this approach does not always work well. I did not give the figures, how much the spread actually amounted to after we did everything. This is 2.5%. For two hundred servers, I think this is a very good figure, i.e. the difference between the maximum and minimum load is very small.
We also solved the problem that admins have to edit configs manually. And due to the number of servers that we have in order to serve at the peak of traffic, we now need about 50 servers less, which seems to be quite significant.

This balancer will be posted on the address on the slide.
We also have a very large number of other projects that you may have heard about. These are PHP-FPM, Pinba and Blitz. There are many small ones that you may not have heard about - for example, our code formatter, analytics tools on the client called Jinba. A tool for running a lot of parallel through SSH called GoSSHa (written in the Go language, respectively). And various other things, for example, a library for Android, which allows you to avoid memory leaks.
Contacts
y.nasretdinov@corp.badoo.com
youROCK
Badoo company blog
This report is a transcript of one of the best speeches at the conference of developers of high-loaded HighLoad ++ systems. Now we are actively preparing for the conference in 2016 - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
This year, Yuri will also speak at HighLoad ++ with the report " 5 ways of PHP code deployment in highload conditions ". In this report, he will talk about how Badoo has been deployed for 10 years, what new system for PHP code deployment has been developed and implemented in production, and will review solutions for large-scale PHP code deployment and analysis of their performance .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/310366/
All Articles