DetectNet: Deep Neural Network for Object Detection at DIGITS
Hi Habr. Recently, I really like to read articles on the topic of deep learning, convolutional networks, image processing, etc. Indeed, there are very cool articles here that amaze and inspire you to your own "more modest" feats. So, I want to bring to the attention of the Russian-speaking public a translation of an article from Nvidia, written on August 11, 2016, in which their new tool, DIGITS and DetectNet, for detecting objects in images is presented. The original article, of course, may seem at first a bit of advertising, and DetectNet does not represent anything “revolutionary”, but the combination of the DIGITS tool and the DetectNet network, it seems to me, can be interesting for everyone.
Today, using the NVIDIA Deep Learning GPU Training System (DIGITS), research analysts have at their disposal all the power of deep learning for solving the most common tasks in this area, such as: data preparation, definition of a convolutional network, parallel training of several models , observation of the learning process in real time, as well as the selection of the best model. The fully interactive DIGITS tool relieves you from programming and debugging and you only do network design and training.
Version DIGITS 4 introduces a new approach to object detection, which allows you to train networks to find objects (such as people, vehicles, or pedestrians) in images and define bounding boxes around objects. Read the Deep Learning for Object Detection with DIGITS article for more details on the method.

Figure 1. The result of the DetectNet network for vehicle detection
For quick mastering of the DIGITS method, the tool includes an illustrative example of a neural network model called DetectNet. In fig. Figure 1 shows the result of a DetectNet network trained to detect vehicles in aerial photography.
DetectNet data format
The input data of the training sample for the problem of classifying images are ordinary images (usually small and containing one object) and class labels (usually an integer class identifier or a string class name). On the other hand, for the object detection problem, more information is needed for training. The images from the input to the training sample for DetectNet are larger and contain several objects, and for each object in the image, the label must contain not only information about the class to which the object belongs, but also the location of the corners of its bounding box. In this case, the naive choice of the label format with varying length and dimensionality leads to the fact that the definition of the loss function can be difficult, since the number of objects in the training image can vary.
DetectNet solves this problem using a fixed three-dimensional label format, which allows you to work with images of any size and a different number of objects present. This view of the input to DetectNet was "inspired" by the work of [Redmon et al. 2015] .
In fig. Figure 2 shows a diagram of image processing from a training sample with markup for DetectNet training. At the beginning, a fixed grid with a size slightly smaller than the smallest object that we want to detect is superimposed on the original image. Further, each lattice square is marked with the following information: the class of the object located in the lattice square, and the pixel coordinates of the corners of the bounding box relative to the center of the lattice square. In the event that no object falls into the lattice square, then a special “dontcare” class is used to preserve the fixed data format. An additional value of "coverage" is also added to the input data format, taking the values 0 or 1 to indicate whether the object is present in the grid square or not. In the case when several objects fall into one lattice square, DetectNet selects the object that occupies the largest number of pixels. If the number of pixels is the same, then the object with the smallest ordinate ( OY ) of the bounding box is selected. Such a selection of objects is not critical for aerial photography, but it makes sense for images with a horizon, for example, images from a DVR, where the object with the smallest ordinate of the bounding box is closer to the camera.

Figure 2. DetectNet input view
Thus, the purpose of training the DetectNet network is to predict a similar presentation of data for a given image. Or, in other words, DetectNet must predict for each lattice square whether an object is present in it, and also calculate the relative coordinates of the corners of the bounding box.
DetectNet network architecture
DetectNet's neural network has five parts, defined in the Caffe framework network model file. In fig. Figure 3 shows the architecture of the DetectNet network used during training. It can be divided into 3 important processes:
- Images and tags of the training set are fed to the input of the data layer. Next, the on-the-fly conversion layer produces data addition.
- A fully convolutional network (FCN) produces feature extraction and prediction of object classes and bounding rectangles over lattice squares.
- The loss functions, at the same time, consider the error in the problems of predicting the coverage of the object and the corners of the bounding rectangles by the lattice squares.
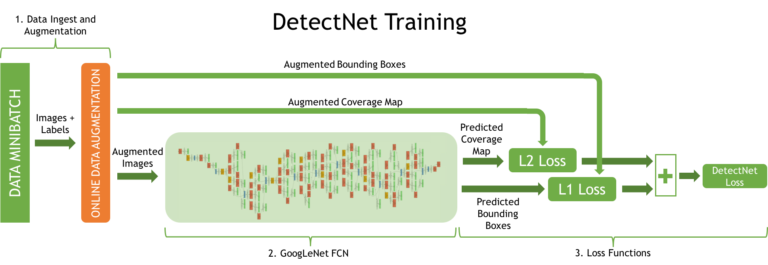
Figure 3. DetectNet network structure for learning
In fig. Figure 4 shows the DetectNet architecture for verification, with two additional important processes:
- Cluster the predicted bounding boxes for the final set.
- Calculate a simplified mAP (mean Average Precision) metric to measure the model's performance across the entire test sample.
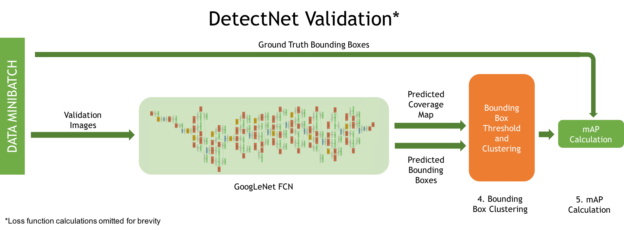
Figure 4. DetectNet network structure for verification
You can change the size of the lattice square for the tutorial marks by setting the stride in pixels for the detectnet_groundtruth_param layer. For example,
detectnet_groundtruth_param { stride: 16 scale_cvg: 0.4 gridbox_type: GRIDBOX_MIN min_cvg_len: 20 coverage_type: RECTANGULAR image_size_x: 1024 image_size_y: 512 obj_norm: true crop_bboxes: false } In the parameters of this layer you can also specify the size of the training images (image_size_x, image_size_y) . Thus, when these parameters are indicated, images that fall into the input of the DetectNet network during training are cropped at random by these sizes. This can be useful if your training sample consists of very large images in which the objects to be detected are very small.
The parameters of the layer that supplements the on-the-fly input data are defined in detectnet_augmentation_param . For example,
detectnet_augmentation_param { crop_prob: 1.0 shift_x: 32 shift_y: 32 scale_prob: 0.4 scale_min: 0.8 scale_max: 1.2 flip_prob: 0.5 rotation_prob: 0.0 max_rotate_degree: 5.0 hue_rotation_prob: 0.8 hue_rotation: 30.0 desaturation_prob: 0.8 desaturation_max: 0.8 } The data augmentation procedure plays an important role in successfully learning a highly sensitive and accurate object detector using DetectNet. The parameters from detectnet_augmentation_param define various random transformations (offset, reflections, etc.) over the training set. Such transformations of the input data lead to the fact that the network never processes the same image twice, and thus becomes more resistant to retraining and the natural change in the shape of objects from the test sample.
The FCN subnetwork in DetectNet has a structure similar to GoogLeNet without an input data layer, a final pool layer and output layers [Szegedy et al. 2014] . This approach allows DetectNet to use the already trained GoogLeNet model, reduce training time and improve the accuracy of the full model. A fully convolutional network (FCN) is a convolutional neural network without fully connected layers. This means that the network can receive images of various sizes as inputs and normally read the response using the sliding window technique in increments. The output is a multidimensional array of real values that can be superimposed on the input image, similar to input labels and a square grid from DetectNet. As a result, GoogLeNet without the final pool layer is a kind of convolutional neural network with a sliding window of size 555 x 555 pixels and a step of 16 pixels [1] .
DetectNet uses a linear combination of two independent loss functions to create the final loss function and optimization. The first loss function coverage_loss is a quadratic error in all squares of the source data grid between the present and the predicted object coverage:
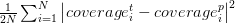
The second function of bbox_loss is the average error between the true and predicted angles of the bounding rectangle over all lattice squares:
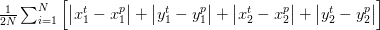
The Caffe framework minimizes the weighted sum of the values of these loss functions.
DetectNet network output
The last layers of the DetectNet network filter and cluster the set of generated bounding boxes for grid squares. To do this, use the groupRectangles algorithm from the OpenCV library. The filtering of the bounding boxes is performed by the threshold method according to the value of the predicted coverage of the object. The threshold value is set by the gridbox_cvg_threshold parameter in the DetectNet model prototxt file. Clustering of bounding boxes is performed using the equivalence criterion of rectangles, which combines figures of similar location and size. The similarity of rectangles is determined by the variable eps : at zero, the rectangles are not merged, and if the value tends to plus infinity, all the rectangles fall into one cluster. After the rectangles are clustered, threshold filtering of small clusters occurs with the threshold specified by the gridbox_rect_thresh parameter, and the remaining clusters are considered to be middle rectangles, which are written to the output list. The clustering method is implemented by a function in Python and is called in Caffe via the “Python Layers“ interface. The parameters of the groupRectangles algorithm are specified through the cluster layer in the DetectNet network model file.
In DetectNet, the “Python Layers” interface is also used to calculate and display a simplified mean-metrics mAP (calculated from the final set of bounding boxes). For the predicted and present bounding rectangles, the Intersection over Union (IoU) value is calculated - the ratio of the intersection area of the rectangles to the sum of their areas. When using a threshold value (default 0.7) for IoU, the predicted rectangle can be categorized as true positive or false positive predictions. In the case when the IoU value for a pair of rectangles does not exceed the threshold value, the predicted rectangle falls into the category of false-negative predictions - the object was not detected. Thus, DetectNet's simplified mAP metric is calculated as the product of accuracy (precision is the ratio of true-positive to the sum of true-positive and false-positive) by the measure of completeness (recall is the ratio of true-positive to the sum of true-positive and true-negative).
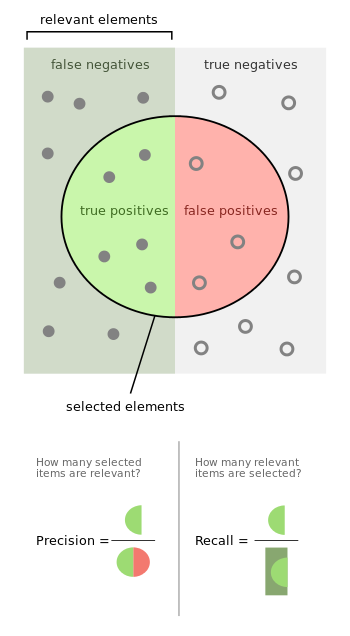
This metric is a convenient characteristic of DetectNet's sensitivity to the detection of training sample objects, discarding false results, and the accuracy of the resulting bounding rectangles. More information about the analysis of object detection errors can be found in the article [Hoiem et al. 2012] .
Learning effectiveness and results
The main advantage of the DetectNet network for the object detection problem is the efficiency with which objects are detected, and the accuracy of the generated bounding rectangles. The presence of a fully convolutional network (FCN) allows DetectNet to be more effective in comparison with the use of a neural network based classifier on a sliding window. This avoids unnecessary computation associated with overlapping windows. This approach with a single neural network architecture is also simpler and more elegant for solving detection tasks.
Learning the DetectNet network in DIGITS 4 with Nvidia Caffe 0.15.7 and cuDNN RC 5.1 on a sample of 307 training and 24 test images, measuring 1536 x 1024 pixels, takes 63 minutes using a single Titan X graphics card.
DetectNet's object detection time on images 1536 x 1024 pixels, with a grid size of 16 pixels, in the previous configuration (one TitanX, Nvidia Caffe 0.15.7, cuDNN RC 5.1) takes 41 ms (approximately 24 fps).
First steps with DetectNet
If you want to try DetectNet on your own data, you can download DIGITS 4 . A step-by-step demonstration of the process of detecting objects in DIGITS is presented here .
Read also the post Deep Learning for Object Detection with DIGITS for an introduction to the method of using the object detection functionality in DIGITS 4.
If you are interested in the pros and cons of various approaches using deep learning in the object detection task, see the Jon Barker presentation at GTC 2016
Other in-depth training materials, including webinars, etc., can be found at the NVIDIA Deep Learning Institute .
Links
Hoiem, D., Chodpathumwan, Y., and Dai, Q. 2012. Diagnosing Error in Object Detectors. Computer Vision - ECCV 2012, Springer Berlin Heidelberg, 340–353.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A. 2015. You Only Look Once: Unified, Real-Time Object Detection. arXiv [cs.CV]. http://arxiv.org/abs/1506.02640 .
Szegedy, C., Liu, W., Jia, Y., et al. 2014. Going Deeper with Convolutions. arXiv [cs.CV]. http://arxiv.org/abs/1409.4842 .
Additional information and links from the translator
The original article can be found here . The DIGITS project is open source and can be found here . The DetectNet prototxt file can be found here or as an image here .
About installing DIGITS
Detailed installation instructions can be found here .
The DIGITS application needs Caffe to run it, or rather NVidia fork , where the Python layers needed for DetectNet are added. This "no problem" fork can be installed on Mac OSX and Ubuntu. With Windows, the problem is that the windows branch from BVLC / Caffe is missing from the fork, so as the authors themselves write: DIGITS for Windows does not support DetectNet . Thus, on Windows, you can install BVLC / Caffe and run "standard" networks.
Notes
[1] CNN with a receptive field of 555 x 555 pixels and a stride of 16 pixels.
')
Source: https://habr.com/ru/post/310332/
All Articles