Database Performance Testing with tSQLt and SQLQueryStress
I hope it will not be a revelation if I say that testing plays an important role in the development of any software product. The better the testing, the better the final product should end up.
It is often possible to encounter a situation where testing of the program code is very painstaking, and there is no time left for testing the database or it is done according to the residual principle. I emphasize that this formulation is very restrained, in practice everything is even worse ... they remember the base only when problems start with it.
')
As a result, working with the database can be a bottleneck in the performance of our application.
To save myself from this kind of problems, I propose to consider various aspects of database testing. These include load testing and performance testing of SQL Server as a whole with the help of unit tests.
Take some abstract task. For example, we are developing an engine for online stores. Our clients may have different sales, different types of goods ... but in order not to overload we will make the structure base relatively simple.
Database schema
USE [master] GO IF DB_ID('db_sales') IS NOT NULL BEGIN ALTER DATABASE [db_sales] SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE [db_sales] END GO CREATE DATABASE [db_sales] GO USE [db_sales] GO CREATE TABLE dbo.Customers ( [CustomerID] INT IDENTITY PRIMARY KEY , [FullName] NVARCHAR(150) , [Email] VARCHAR(50) NOT NULL , [Phone] VARCHAR(50) ) GO CREATE TABLE dbo.Products ( [ProductID] INT IDENTITY PRIMARY KEY , [Name] NVARCHAR(150) NOT NULL , [Price] MONEY NOT NULL CHECK (Price > 0) , [Image] VARBINARY(MAX) NULL , [Description] NVARCHAR(MAX) ) GO CREATE TABLE dbo.Orders ( [OrderID] INT IDENTITY PRIMARY KEY , [CustomerID] INT NOT NULL , [OrderDate] DATETIME NOT NULL DEFAULT GETDATE() , [CustomerNotes] NVARCHAR(MAX) , [IsProcessed] BIT NOT NULL DEFAULT 0 ) GO ALTER TABLE dbo.Orders WITH NOCHECK ADD CONSTRAINT FK_Orders_CustomerID FOREIGN KEY (CustomerID) REFERENCES dbo.Customers (CustomerID) GO ALTER TABLE dbo.Orders CHECK CONSTRAINT FK_Orders_CustomerID GO CREATE TABLE dbo.OrderDetails ( [OrderID] INT NOT NULL , [ProductID] INT NOT NULL , [Quantity] INT NOT NULL CHECK (Quantity > 0) , PRIMARY KEY (OrderID, ProductID) ) GO ALTER TABLE dbo.OrderDetails WITH NOCHECK ADD CONSTRAINT FK_OrderDetails_OrderID FOREIGN KEY (OrderID) REFERENCES dbo.Orders (OrderID) GO ALTER TABLE dbo.OrderDetails CHECK CONSTRAINT FK_OrderDetails_OrderID GO ALTER TABLE dbo.OrderDetails WITH NOCHECK ADD CONSTRAINT FK_OrderDetails_ProductID FOREIGN KEY (ProductID) REFERENCES dbo.Products (ProductID) GO ALTER TABLE dbo.OrderDetails CHECK CONSTRAINT FK_OrderDetails_ProductID GO Also suppose that our thin client will work with the database through pre-written stored procedures. They are all quite simple. Insert a new user or get an existing ID :
CREATE PROCEDURE dbo.GetCustomerID ( @FullName NVARCHAR(150) , @Email VARCHAR(50) , @Phone VARCHAR(50) , @CustomerID INT OUT ) AS BEGIN SET NOCOUNT ON; SELECT @CustomerID = CustomerID FROM dbo.Customers WHERE Email = @Email IF @CustomerID IS NULL BEGIN INSERT INTO dbo.Customers (FullName, Email, Phone) VALUES (@FullName, @Email, @Phone) SET @CustomerID = SCOPE_IDENTITY() END END Place a new order:
CREATE PROCEDURE dbo.CreateOrder ( @CustomerID INT , @CustomerNotes NVARCHAR(MAX) , @Products XML ) AS BEGIN SET NOCOUNT ON; DECLARE @OrderID INT INSERT INTO dbo.Orders (CustomerID, CustomerNotes) VALUES (@CustomerID, @CustomerNotes) SET @OrderID = SCOPE_IDENTITY() INSERT INTO dbo.OrderDetails (OrderID, ProductID, Quantity) SELECT @OrderID , tcvalue('@ProductID', 'INT') , tcvalue('@Quantity', 'INT') FROM @Products.nodes('items/item') t(c) END Suppose we are faced with the task of ensuring a minimum response when executing queries. On an empty base of performance problems, even if desired, can hardly be expected. Therefore, to check the performance of our procedures, we need at least some test data. As an option, use the script to generate test data for the Customers table:
Script
DECLARE @obj INT = OBJECT_ID('dbo.Customers') , @sql NVARCHAR(MAX) , @cnt INT = 10 ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) SELECT @sql = ' DELETE FROM ' + QUOTENAME(OBJECT_SCHEMA_NAME(@obj)) + '.' + QUOTENAME(OBJECT_NAME(@obj)) + ' ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) INSERT INTO ' + QUOTENAME(OBJECT_SCHEMA_NAME(@obj)) + '.' + QUOTENAME(OBJECT_NAME(@obj)) + '(' + STUFF(( SELECT ', ' + QUOTENAME(name) FROM sys.columns c WHERE c.[object_id] = @obj AND c.is_identity = 0 AND c.is_computed = 0 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ') SELECT TOP(' + CAST(@cnt AS VARCHAR(10)) + ') ' + STUFF(( SELECT ' , ' + QUOTENAME(name) + ' = ' + CASE WHEN TYPE_NAME(c.system_type_id) IN ( 'varchar', 'char', 'nvarchar', 'nchar', 'ntext', 'text' ) THEN ( STUFF(( SELECT TOP( CASE WHEN max_length = -1 THEN CAST(RAND() * 10000 AS INT) ELSE max_length END / CASE WHEN TYPE_NAME(c.system_type_id) IN ('nvarchar', 'nchar', 'ntext') THEN 2 ELSE 1 END ) '+SUBSTRING(x, (ABS(CHECKSUM(NEWID())) % 80) + 1, 1)' FROM E8 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1, '') ) WHEN TYPE_NAME(c.system_type_id) = 'tinyint' THEN '50 + CRYPT_GEN_RANDOM(10) % 50' WHEN TYPE_NAME(c.system_type_id) IN ('int', 'bigint', 'smallint') THEN 'CRYPT_GEN_RANDOM(10) % 25000' WHEN TYPE_NAME(c.system_type_id) = 'uniqueidentifier' THEN 'NEWID()' WHEN TYPE_NAME(c.system_type_id) IN ('decimal', 'float', 'money', 'smallmoney') THEN 'ABS(CAST(NEWID() AS BINARY(6)) % 1000) * RAND()' WHEN TYPE_NAME(c.system_type_id) IN ('datetime', 'smalldatetime', 'datetime2') THEN 'DATEADD(MINUTE, RAND(CHECKSUM(NEWID())) * (1 + DATEDIFF(MINUTE, ''20000101'', GETDATE())), ''20000101'')' WHEN TYPE_NAME(c.system_type_id) = 'bit' THEN 'ABS(CHECKSUM(NEWID())) % 2' WHEN TYPE_NAME(c.system_type_id) IN ('varbinary', 'image', 'binary') THEN 'CRYPT_GEN_RANDOM(5)' ELSE 'NULL' END FROM sys.columns c WHERE c.[object_id] = @obj AND c.is_identity = 0 AND c.is_computed = 0 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 8, ' ') + ' FROM E8 CROSS APPLY ( SELECT x = ''0123456789-ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz'' ) t' EXEC sys.sp_executesql @sql The script was created in order to generate random test data for tables with arbitrary structure. As a result, we won in universality, but lost in realism:
CustomerID FullName Email Phone ----------- ------------------------------------ ---------------- --------------- 1 uN9UiFZ9i0pALwQXIfC628Ecw35VX9L i6D0FNBuKo9I ZStNRH8t1As2S 2 Jdi6M0BqxhE-7NEvC1 a12 UTjK28OSpTHx 7DW2HEv0WtGN 3 0UjI9pIHoyeeCEGHHT6qa2 2hUpYxc vN mqLlO 7c R5 U3ha 4 RMH-8DKAmewi2WdrvvHLh w-FIa wrb uH 5 h76Zs-cAtdIpw0eewYoWcY2toIo g5pDTiTP1Tx qBzJw8Wqn 6 jGLexkEY28Qd-OmBoP8gn5OTc FESwE l CkgomDyhKXG 7 09X6HTDYzl6ydcdrYonCAn6qyumq9 EpCkxI01tMHcp eOh7IFh 8 LGdGeF5YuTcn2XkqXT-92 cxzqJ4Y cFZ8yfEkr 9 7 Ri5J30ZtyWBOiUaxf7MbEKqWSWEvym7 0C-A7 R74Yc KDRJXX hw 10 D DzeE1AxUHAX1Bv3eglY QsZdCzPN0 RU-0zVGmU Of course, no one bothers us to write a request to generate more approximate data for the same Customers table:
DECLARE @cnt INT = 10 DELETE FROM dbo.Customers ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) INSERT INTO dbo.Customers (FullName, Email, Phone) SELECT TOP(@cnt) [FullName] = txt , [Email] = LOWER(txt) + LEFT(ABS(CHECKSUM(NEWID())), 3) + '@gmail.com' , [Phone] = '+38 (' + LEFT(ABS(CHECKSUM(NEWID())), 3) + ') ' + STUFF(STUFF(LEFT(ABS(CHECKSUM(NEWID())), 9) , 4, 1, '-') , 7, 1, '-') FROM E8 CROSS APPLY ( SELECT TOP(CAST(RAND(N) * 10 AS INT)) txt FROM ( VALUES (N'Boris_the_Blade'), (N'John'), (N'Steve'), (N'Mike'), (N'Phil'), (N'Sarah'), (N'Ann'), (N'Andrey'), (N'Liz'), (N'Stephanie') ) t(txt) ORDER BY NEWID() ) t This became a little more realistic:
FullName Email Phone --------------- -------------------------- ------------------- Boris_the_Blade boris_the_blade1@gmail.com +38 (146) 296-33-10 John john130@mail.com +38 (882) 688-98-59 Phil phil155@gmail.com +38 (125) 451-73-71 Mike mike188@gmail.com +38 (111) 169-59-14 Sarah sarah144@gmail.com +38 (723) 124-50-60 Andrey andrey100@gmail.com +38 (193) 160-91-48 Stephanie stephanie188@gmail.com +38 (590) 128-86-02 John john723@gmail.com +38 (194) 101-06-65 Phil phil695@gmail.com +38 (164) 180-57-37 Mike mike200@gmail.com +38 (110) 131-89-45 However, do not forget that we have foreign keys between the tables and it is already an order of magnitude more difficult to generate consistent data for all other entities. In order not to invent solutions to this problem, I suggest using one of the date generators, which allows you to create meaningful test data for tables in the database.
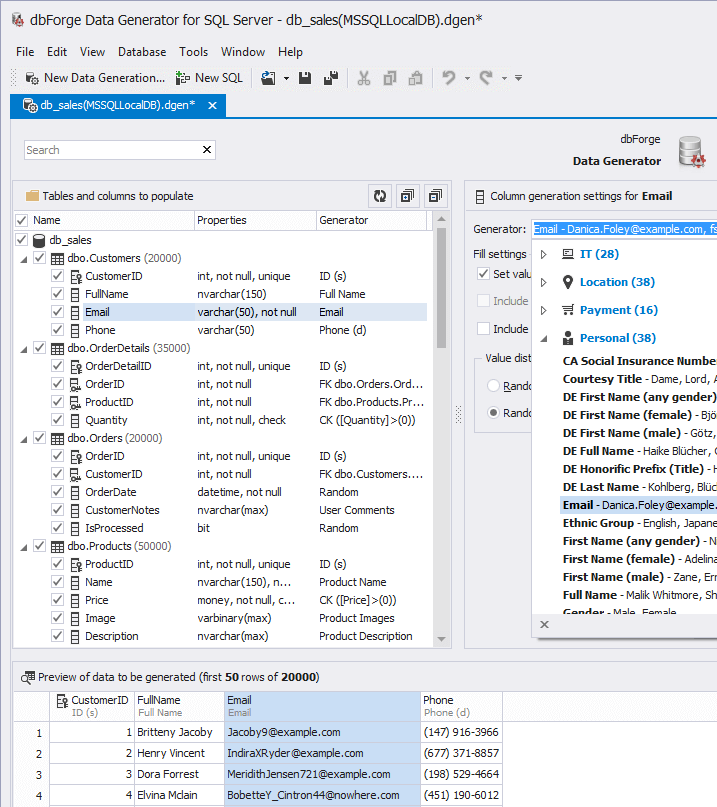
SELECT TOP 10 * FROM dbo.Customers ORDER BY NEWID() CustomerID FullName Email Phone ----------- -------------- ----------------------------------- ----------------- 18319 Noe Pridgen Doyle@example.com (682) 219-7793 8797 Ligia Gaddy CrandallR9@nowhere.com (623) 144-6165 14712 Marry Almond Cloutier39@nowhere.com (601) 807-2247 8280 NULL Lawrence_Z_Mortensen85@nowhere.com (710) 442-3219 8012 Noah Tyler RickieHoman867@example.com (944) 032-0834 15355 Fonda Heard AlfonsoGarcia@example.com (416) 311-5605 10715 Colby Boyd Iola_Daily@example.com (718) 164-1227 14937 Carmen Benson Dennison471@nowhere.com (870) 106-6468 13059 Tracy Cornett DaniloBills@example.com (771) 946-5249 7092 Jon Conaway Joey.Redman844@example.com (623) 140-7543 Test data is ready. Let's move on to testing the performance of our stored procedures.
We have a GetCustomerID procedure that returns a customer ID , if not, then creates the corresponding entry in the Customers table. Let's try to do it beforehand by enabling the display of the actual execution plan:
DECLARE @CustomerID INT EXEC dbo.GetCustomerID @FullName = N'' , @Email = 'sergeys@mail.ru' , @Phone = '7105445' , @CustomerID = @CustomerID OUT SELECT @CustomerID On the execution plan, you can see that a full scan of the cluster index is happening:

And to do this, SQL Server has to do 200 logical reads from a table, and all this takes about 20 milliseconds:
Table 'Customers'. Scan count 1, logical reads 200, physical reads 0, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 20 ms. But we are talking about the execution time of a single request. What if this stored procedure is very active with us? Continuous index scans will slow down server performance.
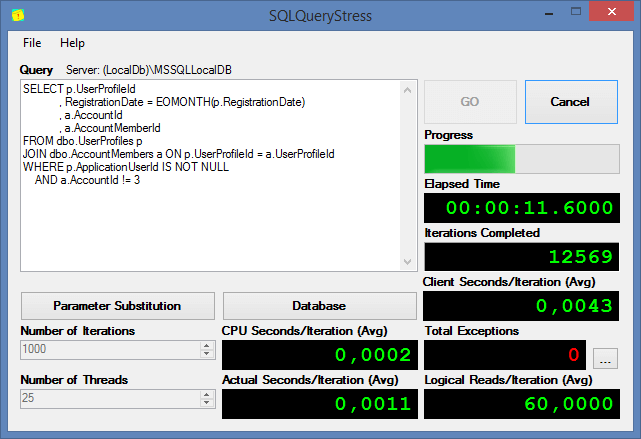
Let's try performing the stress tests of our stored procedure using one interesting SQLQueryStress open source tutor , which was developed by Adam Machanic (link to GitHub ).

We see that a call 2,000 times of the GetCustomerID procedure in two threads took a little less than 4 seconds on the server. Now let's try to see what will happen if we add an index to the field by which our search takes place:
CREATE NONCLUSTERED INDEX IX_Email ON dbo.Customers (Email) Index Seek appeared on the execution plan instead of Index Scan :

Logical reads and overall execution times have been reduced:
Table 'Customers'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 8 ms. If we repeat our stress test in SQLQueryStress , then we will be able to see that now our procedure with a multiple call will load the server less and run faster:

Now, let's try using SQLQueryStress to emulate a mass order placement:
DECLARE @CustomerID INT , @CustomerNotes NVARCHAR(MAX) , @Products XML SELECT TOP(1) @CustomerID = CustomerID , @CustomerNotes = REPLICATE('a', RAND() * 100) FROM dbo.Customers ORDER BY NEWID() SELECT @Products = ( SELECT [@ProductID] = ProductID , [@Quantity] = CAST(RAND() * 10 AS INT) FROM dbo.Products ORDER BY ProductID OFFSET CAST(RAND() * 1000 AS INT) ROWS FETCH NEXT CAST(RAND() * 10 AS INT) + 1 ROWS ONLY FOR XML PATH('item'), ROOT('items') ) EXEC dbo.CreateOrder @CustomerID = @CustomerID , @CustomerNotes = @CustomerNotes , @Products = @Products 
Performing the procedure 100 times in two threads simultaneously took 2.5 seconds. Let's clear the statistics of expectations:
DBCC SQLPERF("sys.dm_os_wait_stats", CLEAR) Restart SQLQueryStress and see what the expectations were when executing our stored procedure:
wait_type wait_time --------------------------------- ----------- WRITELOG 2.394000 PARALLEL_REDO_WORKER_WAIT_WORK 0.264000 PAGEIOLATCH_SH 0.157000 ASYNC_NETWORK_IO 0.125000 PAGEIOLATCH_UP 0.097000 PREEMPTIVE_OS_FLUSHFILEBUFFERS 0.049000 IO_COMPLETION 0.048000 PAGEIOLATCH_EX 0.043000 PREEMPTIVE_OS_WRITEFILEGATHER 0.037000 LCK_M_IX 0.033000 We see that in the first place is WRITELOG , which in time roughly corresponds to the total time of our stress test. What does this delay mean? Since we have every command for insertion is atomic, then after it is executed, there is a physical fixation of changes in the log. When we have a large number of short transactions, there is a queue, because operations with the log occur synchronously, unlike data files.
In SQL Server 2014 , the ability to set up a delayed write to the Delayed Durability log has been added, which is enabled at the database level:
ALTER DATABASE db_sales SET DELAYED_DURABILITY = ALLOWED And then we just need to slightly change the stored procedure:
ALTER PROCEDURE dbo.CreateOrder ( @CustomerID INT , @CustomerNotes NVARCHAR(MAX) , @Products XML ) AS BEGIN SET NOCOUNT ON; BEGIN TRANSACTION t DECLARE @OrderID INT INSERT INTO dbo.Orders (CustomerID, CustomerNotes) VALUES (@CustomerID, @CustomerNotes) SET @OrderID = SCOPE_IDENTITY() INSERT INTO dbo.OrderDetails (OrderID, ProductID, Quantity) SELECT @OrderID , tcvalue('@ProductID', 'INT') , tcvalue('@Quantity', 'INT') FROM @Products.nodes('items/item') t(c) COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON) END Clean up the statistics and rerun the stress test:

We see that the total execution time has been reduced by half, and the delays of the WRITELOG have become minimal:
wait_type wait_time -------------------------- ---------- PREEMPTIVE_OS_WRITEFILE 0.027000 PAGEIOLATCH_EX 0.024000 PAGELATCH_EX 0.020000 WRITELOG 0.014000 Now consider another situation when you need to periodically check the performance of a particular query. Using SQLQueryStress for this will not be so convenient, because you will have to open the application, copy the query there and wait for the execution.
Is it possible to automate it? ..
In 2014, I first met tSQLt , which turned out to be quite a wonderful free framework for unit testing. Let's try to install tSQLt and create an autotest using it to check the performance of our stored procedure.
Download the latest version of tSQLt , configure an instance of SQL Server to work with the CLR :
EXEC sys.sp_configure 'clr enabled', 1 RECONFIGURE GO ALTER DATABASE [db_sales] SET TRUSTWORTHY ON GO After that, we will execute the tSQLt.class.sql script from the archive on our database. The script will create its own tSQLt scheme, CLR assembly and many scripted objects. Some of the procedures will contain the prefix Private_ which are intended for internal use by the framework itself.
If everything is set correctly, then in Output we will receive the following message:
+-----------------------------------------+ | | | Thank you for using tSQLt. | | | | tSQLt Version: 1.0.5873.27393 | | | +-----------------------------------------+ Now we will create a scheme in which we will create autotests:
USE [db_sales] GO CREATE SCHEMA [Performance] GO EXEC sys.sp_addextendedproperty @name = N'tSQLt.Performance' , @value = 1 , @level0type = N'SCHEMA' , @level0name = N'Performance' GO It should be noted that the Extended Property determines whether an object belongs to the tSQLt functionality.
Create a test in the Performance schema by specifying the test prefix in the test name:
CREATE PROCEDURE [Performance].[test ProcTimeExecution] AS BEGIN SET NOCOUNT ON; EXEC tSQLt.Fail 'TODO: Implement this test.' END We try to execute the created autotest. For this we can either perform:
EXEC tSQLt.RunAll Or explicitly specify the scheme:
EXEC tSQLt.Run 'Performance' or a specific test:
EXEC tSQLt.Run 'Performance.test ProcTimeExecution' If you want to run the last test run, you can call Run without parameters:
EXEC tSQLt.Run After executing one of the commands above, we obtain the following information:
[Performance].[test ProcTimeExecution] failed: (Failure) TODO: Implement this test. +----------------------+ |Test Execution Summary| +----------------------+ |No|Test Case Name |Dur(ms)|Result | +--+--------------------------------------+-------+-------+ |1 |[Performance].[test ProcTimeExecution]| 0|Failure| Let's try to change the content in the AutoTest to something more useful. For example, take the GetUnprocessedOrders procedure, which returns a list of unprocessed orders:
CREATE PROCEDURE dbo.GetUnprocessedOrders AS BEGIN SET NOCOUNT ON; SELECT o.OrderID , o.OrderDate , c.FullName , c.Email , c.Phone , OrderSum = ( SELECT SUM(p.Price + d.Quantity) FROM dbo.OrderDetails d JOIN dbo.Products p ON d.ProductID = p.ProductID WHERE d.OrderID = o.OrderID ) FROM dbo.Orders o JOIN dbo.Customers c ON o.CustomerID = c.CustomerID WHERE o.IsProcessed = 0 END and create an autotest that will perform the procedure n-th number of times and fail with an error if the average execution time is greater than the specified threshold value.
ALTER PROCEDURE [Performance].[test ProcTimeExecution] AS BEGIN SET NOCOUNT ON; DECLARE @time DATETIME , @duration BIGINT = 0 , @cnt TINYINT = 10 WHILE @cnt > 0 BEGIN SET @time = GETDATE() EXEC dbo.GetUnprocessedOrders SET @duration += DATEDIFF(MILLISECOND, @time, GETDATE()) SET @cnt -= 1 END IF @duration / 10 > 100 BEGIN DECLARE @txt NVARCHAR(MAX) = 'High average execution time: ' + CAST(@duration / 10 AS NVARCHAR(10)) + ' ms' EXEC tSQLt.Fail @txt END END Carry out autotest:
EXEC tSQLt.Run 'Performance' And we get the following message:
[Performance].[test ProcTimeExecution] failed: (Error) High execution time: 161 ms +----------------------+ |Test Execution Summary| +----------------------+ |No|Test Case Name |Dur(ms)|Result| +--+--------------------------------------+-------+------+ |1 |[Performance].[test ProcTimeExecution]| 1620|Error | Let's try to optimize the query and make the test pass. First, look at the execution plan:

We see that the problem is often referring to the clustered index of the Products table. A large number of logical readings also confirm this statement:
Table 'Customers'. Scan count 1, logical reads 200, ... Table 'Orders'. Scan count 1, logical reads 3886, ... Table 'Products'. Scan count 0, logical reads 73607, ... Table 'OrderDetails'. Scan count 1, logical reads 235, ... How can the situation be corrected? You can add a nonclustered index and include the Price field there, make a preliminary calculation of the values in a separate table, or alternatively create an aggregated index view:
CREATE VIEW dbo.vwOrderSum WITH SCHEMABINDING AS SELECT d.OrderID , OrderSum = SUM(p.Price + d.Quantity) , OrderCount = COUNT_BIG(*) FROM dbo.OrderDetails d JOIN dbo.Products p ON d.ProductID = p.ProductID GROUP BY d.OrderID GO CREATE UNIQUE CLUSTERED INDEX IX_OrderSum ON dbo.vwOrderSum (OrderID) And change the stored procedure:
ALTER PROCEDURE dbo.GetUnprocessedOrders AS BEGIN SET NOCOUNT ON; SELECT o.OrderID , o.OrderDate , c.FullName , c.Email , c.Phone , s.OrderSum FROM dbo.Orders o JOIN dbo.Customers c ON o.CustomerID = c.CustomerID JOIN dbo.vwOrderSum s WITH(NOEXPAND) ON o.OrderID = s.OrderID WHERE o.IsProcessed = 0 END It is advisable to specify the NOEXPAND hint to make the optimizer always use the index from our view. In addition, to reduce the number of logical reads from Orders, you can create a filtered index:
CREATE NONCLUSTERED INDEX IX_UnProcessedOrders ON dbo.Orders (OrderID, CustomerID, OrderDate) WHERE IsProcessed = 0 Now when executing our stored procedure, a simpler plan will be used:

Logical readings will be less:
Table 'Customers'. Scan count 1, logical reads 200, ... Table 'Orders'. Scan count 1, logical reads 21, ... Table 'vwOrderSum'. Scan count 1, logical reads 44, ... The execution of the stored procedure is reduced and our test will be executed successfully:
|No|Test Case Name |Dur(ms)|Result | +--+--------------------------------------+-------+-------+ |1 |[Performance].[test ProcTimeExecution]| 860|Success| We can say that we managed. Optimized all bottlenecks and made a really cool product. But let's face it. Data tend to accumulate, and SQL Server generates an execution plan based on the expected number of rows. Now we have conducted testing for growth, however, there is no guarantee that after a year of work the implementation plan will be just as effective, the scheme will not change, someone will not mistakenly delete the necessary index, and so on ... Therefore, it is extremely important to run such tests on a regular basis to quickly identify problems.
Now let's see what else such useful can be done with the help of unit tests.
For example, we can see in all execution plans whether there is a MissingIndexGroup section. If it is, then SQL Server considers that there is not enough index for a specific query:
CREATE PROCEDURE [Performance].[test MissingIndexes] AS BEGIN SET NOCOUNT ON DECLARE @msg NVARCHAR(MAX) , @rn INT SELECT t.text , p.query_plan , q.total_worker_time / 100000. FROM ( SELECT TOP 100 * FROM sys.dm_exec_query_stats ORDER BY total_worker_time DESC ) q CROSS APPLY sys.dm_exec_sql_text(q.sql_handle) t CROSS APPLY sys.dm_exec_query_plan(q.plan_handle) p WHERE p.query_plan.exist('//*:MissingIndexGroup') = 1 SET @rn = @@ROWCOUNT IF @rn > 0 BEGIN SET @msg = 'Missing index in ' + CAST(@rn AS VARCHAR(10)) + ' queries' EXEC tSQLt.Fail @msg END END You can also automate the search for unused indexes. This is all done quite simply - just find out the statistics of the use of an index in dm_db_index_usage_stats :
CREATE PROCEDURE [Performance].[test UnusedUndexes] AS BEGIN DECLARE @tables INT , @indexes INT , @msg NVARCHAR(MAX) SELECT @indexes = COUNT(*) , @tables = COUNT(DISTINCT o.[object_id]) FROM sys.objects o CROSS APPLY ( SELECT s.index_id , index_usage = s.user_scans + s.user_lookups + s.user_seeks , usage_percent = (s.user_scans + s.user_lookups + s.user_seeks) * 100. / NULLIF(SUM(s.user_scans + s.user_lookups + s.user_seeks) OVER (), 0) , index_count = COUNT(*) OVER () FROM sys.dm_db_index_usage_stats s WHERE s.database_id = DB_ID() AND s.[object_id] = o.[object_id] ) t WHERE o.is_ms_shipped = 0 AND o.[schema_id] != SCHEMA_ID('tSQLt') AND o.[type] = 'U' AND ( (t.usage_percent < 5 AND t.index_usage > 100 AND t.index_count > 1) OR t.index_usage = 0 ) IF @tables > 0 BEGIN SET @msg = 'Database contains ' + CAST(@indexes AS VARCHAR(10)) + ' unused indexes in ' + CAST(@tables AS VARCHAR(10)) + ' tables' EXEC tSQLt.Fail @msg END END When developing large and complex systems, it is often possible to come across situations when a table was added to the system, data was inserted there and the existence of it was forgotten.
How to identify such tables? For example, they are not referenced; selection from these tables has not taken place since the server was started, provided that the server has been running for more than a week. The conditions are relative and can be modified for each specific task.
CREATE PROCEDURE [Performance].[test UnusedTables] AS BEGIN SET NOCOUNT ON DECLARE @msg NVARCHAR(MAX) , @rn INT , @txt NVARCHAR(1000) = N'Starting up database ''' + DB_NAME() + '''.' DECLARE @database_start TABLE ( log_date SMALLDATETIME, spid VARCHAR(50), msg NVARCHAR(4000) ) INSERT INTO @database_start EXEC sys.xp_readerrorlog 0, 1, @txt SELECT o.[object_id] , [object_name] = SCHEMA_NAME(o.[schema_id]) + '.' + o.name FROM sys.objects o WHERE o.[type] = 'U' AND o.is_ms_shipped = 0 AND o.[schema_id] != SCHEMA_ID('tSQLt') AND NOT EXISTS( SELECT * FROM sys.dm_db_index_usage_stats s WHERE s.database_id = DB_ID() AND s.[object_id] = o.[object_id] AND ( s.user_seeks > 0 OR s.user_scans > 0 OR s.user_lookups > 0 OR s.user_updates > 0 ) ) AND NOT EXISTS( SELECT * FROM sys.sql_expression_dependencies s WHERE o.[object_id] IN (s.referencing_id, s.referenced_id) ) AND EXISTS( SELECT 1 FROM @database_start t HAVING MAX(t.log_date) < DATEADD(DAY, -7, GETDATE()) ) SET @rn = @@ROWCOUNT IF @rn > 0 BEGIN SET @msg = 'Database contains ' + CAST(@rn AS VARCHAR(10)) + ' unused tables' EXEC tSQLt.Fail @msg END END And such tests, as I quoted above, you can create many more ...
As a conclusion, I honestly do not know what else can be added to what was written earlier. Probably only one. Try tSQLt and SQLQueryStress . These products are completely free and in practice they helped me out more than once with SQL Server load testing and performance optimization on the server.
Source: https://habr.com/ru/post/310328/
All Articles