Challenge search cloud. Lecture in Yandex
Internet companies choose and test equipment for data centers not only according to the nominal specifications received from the manufacturer, but also taking into account the real production tasks that will be performed on this equipment. Then, when the data center is already designed, built and launched, exercises are held - the nodes turn off without the knowledge of the services and see how prepared they are for such a situation. The fact is that with such a complex infrastructure it is impossible to achieve full resiliency. In a sense, the ideal data center is one that can be turned off without affecting the services, for example, for Yandex search.
Oleg Fedorov, head of the search runtime examination team, was among the speakers at a large Yandex search meeting that was held in early August. He spoke about all the main aspects of designing data centers for tasks related to processing huge amounts of data. Under the cut - decoding and slides Oleg.
My name is Oleg, I have been working at Yandex for six years. I started as a manager in the search quality department, now I’m more involved in issues related to the operation of our large data centers - I’m following our search to work, etc.
')
Let's try to speculatively design a small data center, 100 thousand machines that can respond with search, other services, etc. We will do it very simply, speculatively, on the tops.
Challenge search cloud. What are we facing? What principles are guided when building our large systems?

As any theater begins with a hanger, you can try to start building a data center with the processor on which we will design our servers, on what equipment it will work, how much it will be, etc. For this we will try to go through three simple steps . We want to test our equipment. We want to calculate how much it will cost us to own such equipment. We want to somehow choose the optimal solution. Picture to attract attention:
In the near future to build our data center, choose an interesting processor for us and be ready for a year and a half, you need to get engineering samples in advance. Many of you know this because you tested the equipment before it appeared on the mass market.
What will we test? Let's take the tasks typical for the cloud that will work on our servers most often: search, a piece of the index that the output draws to us, something else. Take all these samples, look for anomalies.
There was a vivid example: we took the processor model of one of the manufacturers and the rendering time was very bad. Surprise. Understood: indeed, there was a problem with the compiler, but nevertheless an anomaly may occur. Another example: the manufacturer declared a new set of SSE instructions, we rewrote our code a little bit - it became much faster. This is a kind of competitive advantage of our model, all is well.
We dive a little. Suppose we chose a certain set of processors. Here are my favorite pictures to attract attention. This is my iPhone recently overheated.

Geographical location. We all know that a data center can be built for a Russian company in Russia or not in Russia - in different countries, in different climatic and geographical zones. For example, at the equator it will be hot, but you can use solar electricity. In the north, electricity will be more complicated, but with cooling everything is very good, etc. Everywhere there are pros and cons.
It will be necessary to think about the maintenance of our data center. It may be difficult to deliver components to some cold region or to some strange country with an unpredictable administrative resource. It will be possible to get some components only with great difficulty, etc.
Be sure to count for each of our set of processors the rest of the infrastructure. If we take a processor that emits 160 watts of heat, probably we will need to think about cooling, we need a more powerful radiator, a more powerful server.
Where in this place is the industry? We want, like everyone else, to be cooled with outboard air. Take the air temperature outside from the street, blow through our servers, get cooling. In this way, we will ensure that as much energy as possible is spent on our final calculations, and as little as possible on the servicing infrastructure.
Many people know: there is a coefficient of PUE, everyone aspires to one. Suppose we calculated how much the processor is ready to perform standard operations and estimated the cost of ownership approximately. I specifically encrypted the names of the processors, these are all kind of speculative numbers. What is the general approach? As a rule, it looks like the processor of maximum performance starts to push ahead a bit and its conditional cost of ownership of the solution with performance per core increases exponentially. Optima live somewhere along the road.
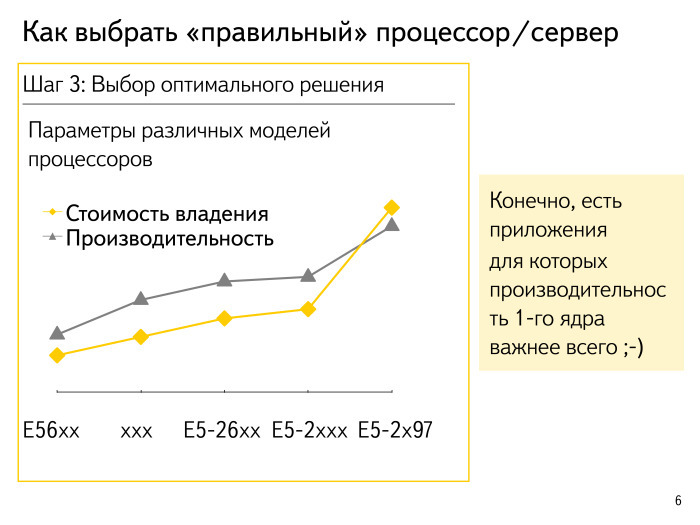
There is always an exception to this rule. We want for some non-mass applications, where latency is very critical, to get maximum performance per core. Or we want to quickly collect, draw, etc. something online - we can afford to take a few percent of exceptional equipment.
Let's try to look at other aspects. We have a very complex multidimensional space: processor, memory, SSD, disks, network, a number of undiscovered measurements. We are constantly expanding. All this has to be thought of. The model is complex, multidimensional, the Internet is slowly changing, our approaches to search are changing. All of this we are laying in the model and be sure to calculate.
The second picture to attract attention:
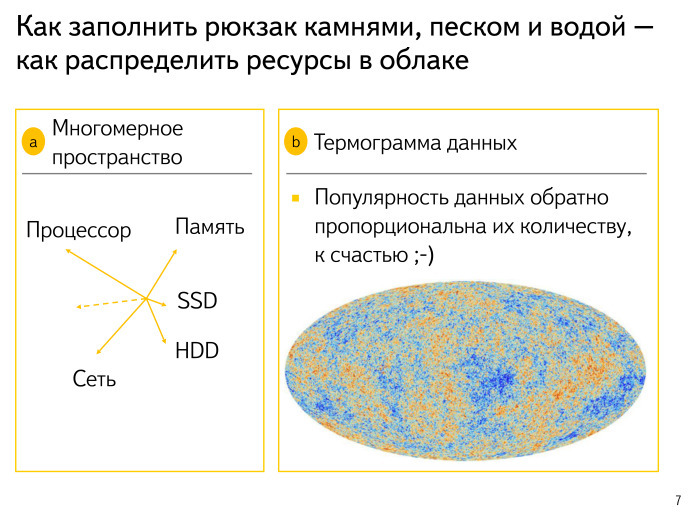
Many probably learned the distribution in relic radiation - this is how we try to computer simulate what our Universe looks like. Data looks about the same. There are very hot sites. For example, for some reason everybody is looking for VKontakte, I don’t know why. Or some kittens. This data is very hot, often used, I really want to put it in memory somewhere closer to the processor, etc. And there are some drivers. My previous laptop is already 10 years old, and for it, under the old Ubuntu, drivers were needed. For some reason, no one, except me, this request did not arise for a long time. I tried to search the logs - no one is interested. This data is probably not needed by anyone - I will put it somewhere far away, on cold disks with a little complicated replication, etc.
Fortunately, we have everything exponentially. The hottest data is very small, you can try to reach it to the memory. And the most uninteresting and unnecessary Korean spamming sites can be put somewhere on the discs and forget about them.
A picture of how complex requirements are in various applications in our cloud. Let's try a little to classify the applications that we have. There is an analogy: I bought an empty aquarium, I want to run the fish there, but before that I have to put some beauty in there — put large pebbles, buttons, that's all. In addition, the aquarium needs sand and water. If I just pour water and only then begin to place everything, it will be dirty for me, it will be difficult to move the stones, etc.
Approach such: we will select the application in our cloud which demands some specific iron, for example GPU. It is clear that the GPU to put in every server is a dream, but rather expensive. Let's place our applications demanding specific iron, on those servers where such iron is. This is step number one.
Step number two: take and sift hard, prostandartize our sand and our main applications — find out how much memory they will consume, how much processor they need, what time of day, how much network they need, how they will deliver data, etc. We clearly plan and understand, for example, that these applications are massive, ready to run anywhere, and it is important to comply with their requirements.
Further, when we made a kind of placement of our sand, in all the free sites we fill in our typical batch tasks - machine learning tasks. As we know, at night most of the people in Russia are asleep. Therefore, there are fewer requests to the search, the processor is released, and I would like to use it. Night is the heyday of batcha, the renaissance of various tasks that are not so closely related to the user's response.
Next step. We have planned our applications in the cloud, but how do we avoid interference between them? How to make so that those wolves who have planned the correct amounts of RAM and processor for themselves, correctly consumed this volume? How to make sure that they are not harmed by poor innocent lambs, who should not consume anything, but who have had some kind of memory leak, an explosion in the number of requests, and who are starting to fill the processor with neighboring tasks? We need borders, bulkheads.
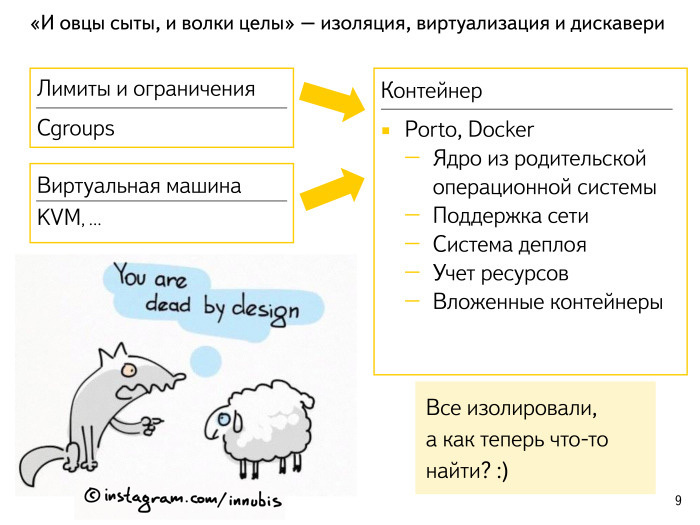
What are the approaches in the industry? Everyone has heard, and someone who has a laptop on Linux, tried to cheat, set up cgroups for himself in some way to shield the application, set limits for it and make everything more or less good.
What is the second common approach? Let's run each application simply in separate virtuals. We get overhead, of course: nothing happens for free. The processor will consume more, a little memory - the fact is that the memory pages, we sometimes will be considered several times. Many modern solutions are already less sick of it, but a specific processor is required, and so on.
What all come to? To a small thin layer - the container enclosing the application.
When we started this story in our cloud, Docker was not so advanced. Its modern binding is impressive - a lot of work has been done. We did our very similar thing. Called Porto. We wanted to easily manage hundreds - already thousands - of applications: so that they do not interfere with each other, so that the configuration process is very simple and in some sense we describe all application limits, understand how it will work, what it needs, where it you need to store data, what is this application dedicated IP-address. That is, it was necessary to describe everything that binds us to multidimensional space, run this container and forget about it.
On the other hand, from the point of view of the application itself, it is practically in the virtual machine. He has his own little chroot, not the entire processor and not the entire RAM is visible. Received advantages in its simplicity in the deployment system, received accounting for resources. We are not very interested in what the application does inside of itself, what subroutines it starts, what it does with data, etc. We are interested in what was happening around this application, that is, the counters from the container. And as another nice bonus, we got the opportunity to run sub-containers nested. We allocated a set of resources for some task or problem and gave the name of this container everything. Then the application can inside itself somehow redistribute the space and run subroutines also in subcontainers, also in isolation. As a result, we get our beautiful submarine, where each compartment is isolated. If someone has a leak somewhere, something exploded, then it exploded only there - locally.
So, we insulated everything, planned everything into clusters. And how to find where application instances work?
How do we solve the discovery problem? There are several approaches. One of the most typical: the application starts, knocks somewhere in the central point, says - I'm here, I will serve such and such traffic, I am of a certain type, I'm fine. Our approach is very similar to this. We have integration with the monitoring system. When the system sees that an application of a certain kind is running on the machine, it saves some meta description of it. When other applications will then look for a list of backends for themselves, they will be able to use this description.

Everything is fine with us. We are on a submarine, everything is insulated, and so on. But then everything begins to break. Imagine that we work in a taxi company. We have a hundred taxis. It will always be like this: one car has a flat tire, no one can drive another, a strange steering wheel, etc. Some cars will always be broken. We need to get used to the fact that a few percent of our applications — system nodes — will always be broken. This should be laid at the stages of calculating replications, loads on each node, etc.
What can break? If we wrote a not quite good version of the application - it, of course, falls. Handles a certain number of requests and drops. The test was not found - they saw it in the cloud. OS crashes. Let's take a new super security update, which does not affect anything in runtime. Let 's release it - applications will start to fall, because we have touched something in the core. Our server will break. He worked in uptime for two years, everything was fine, but the RAM started to get lost, disks began to fall out, etc.
Servers in the data center are in racks. Power is centrally supplied to the rack, a network is locally supplied, several veins. This all can refuse, break. We must be prepared for the fact that the entire stand breaks down. It is necessary that the critical parts of our index or application, which are not very much running in our cloud, should not be placed in one rack, but should be kept as blurred as possible.
Racks, several tens or hundreds, are combined into modules. A fireproof piece of the data center is formed, so that in the event of a malfunction, not the entire data center was damaged, and the module could be insulated.
But also entirely, happens, the data-center breaks. What do you think, at what time of year data centers often fall off the network and communication channels suffer?
- ...
- Why is spring? No, modern optics expands and shrinks perfectly. Spring is right, but why? Sowing. Agricultural industry wakes up, begins to demolish optics in those places where it does not exist. Builders wake up and start doing the work that they could not do in the winter. In the spring, communication channels are affected, etc.
Let's try to classify the problems of our accident. Here the guys dropped the satellite to the floor, trouble.

We have broken one or two percent of our nodes, equipment, whatever. This is a routine task: in our taxis one or two or three cars will always be laid up, you have to be ready for this.
A serious problem is when we have 5-7% of the nodes failed. Probably, some release of the infrastructure component did not go as we expected. Maybe we broke something in the network, maybe in something else. We need to understand this problem, but it is not critical - our services continue to work, it is in this fragment of our infrastructure that everything is fine.
Disaster - when 15-20% of nodes are out of order. There was clearly something wrong here, it makes no sense to release the program, roll out something, reconfigure it. It is necessary to remove the load, to take more active steps. This is not a viable situation. Probably, many are familiar with this approach.
What can you do in such cases? Let's start with the simple. We have broken cars. They can break just programmatically. Hung server. You must be able to detect this, be able to try to communicate with this server over IPMI in order to do something with it. We present the work of our monitoring systems, the detection of faults and attempts to fix it; we present the application in the data center as a cartoon about the WALL-E robot. Such robots travel around the cluster, everyone is trying to fix it, and they report to a certain central point about what is happening here. So, the first approach is auto repair.
How else can you deal with the fact that everything breaks all the time? There is a pessimization of backends. Suppose we have application A, it goes to 10 backends of applications B. One of the backends suddenly begins to respond noticeably slower, to 100 ms. We can calmly pessimize this backend, start asking a lot of requests into it — continue to ask to monitor its state, but translate requests to the remaining 9 healthy and alive backends. Nothing will happen - all is well. We teach our applications to be careful, to be able to understand that under us is a backend and that something has happened to it.
Here is a different approach. Appendix A has become an attachment B to send traffic many times more than we expected. It is convenient to be able to turn off some of its functionality and start responding, perhaps even quite correctly, but at a much lower cost in terms of the CPU. For example, a little less deep search, if we are talking about the search. We are not raising 1000 documents, but 900, slowly pushing the line aside. It seems to be imperceptible, but we significantly increase our throughput at the moment when we really need it. This is a degradation.
When a serious catastrophe has already happened, the understandable step is to balance, deflect the load. We must be able to isolate any site, including the entire data center. It may be necessary to divert traffic from there and then divert the node to maintenance to do something with it.
How to understand that all our applications are able, working and designed according to this scheme? It is necessary to conduct regular exercises: disconnect nodes, disconnect a large number of servers, disconnect data centers. This should happen unexpectedly for the teams of these applications - so that there are no stories, as if we are manipulating a load or something else. This should be an honest normal accident, but with the ability to quickly return everything to its original state. We are not waiting for spring to come and one of the canals will move us with an excavator. We will turn it off ourselves and see what happens. We cut our infrastructure - see what happens.

Houston, we have a problem. We diagnosed the problem to the point where it is no longer a routine, but the problem — 5-7% or a catastrophe. This is a must understand. What are typical search engineers looking for? Is some release or launch coming now? Probably, if the application worked well for weeks, for weeks, and everything was fine, but now suddenly, at one o'clock, the response time sank, then something changed. Probably a release was launched.
What are we trying to look at? , . , , . 8:30 8:30 . 20% — , - .
. , , . . , , .
. , . , , , , , .
. . Netscape Navigator, , . . , . ? ? , ? . .
. , . , , , . , . .
. 15 , . . , . - . , , - — . — - .
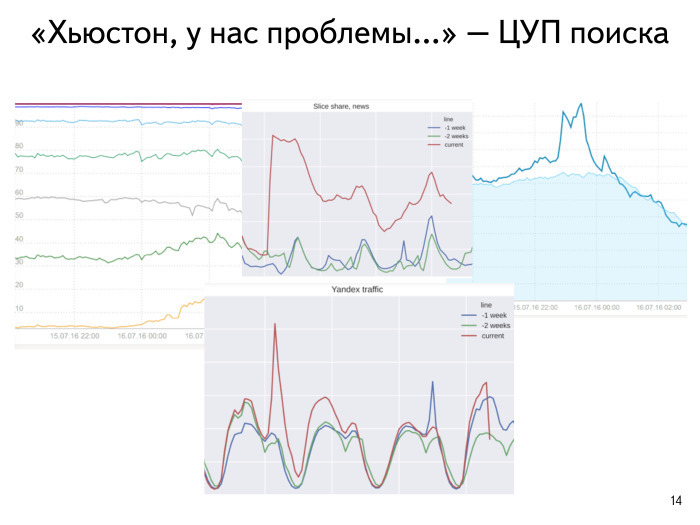
. : 100 , 200 . . , . - . , . , . , , . , .
, . : , - , , , , , . — , .
, -, , , , , , , , .
:
— , ?
:
— , . , , - .
, :
— , . — , , . , . , - — .
:
— , Startup Makers. Google open source solution — Kubernetes. Porto. ?
:
— , , . . - - .
:
— , . , NIH — not invented here. , , . open source , .
Porto — , Docker. .
:
— Docker .
:
— , , , , . , , , — open source.
:
— , Kubernetes. , , , , Google. Service discovery — . , , , — ? , - etcd-, key value, - ?
:
— , , . . — -, , , . — push, call.
:
— , . . - ? ?
:
— . — . .
:
— Kubernetes Kube Dash, , - . . CoreOS, , . - UI- , AWS , , ?
:
— , . , . : , , , . .
UI . , , , UI . 100 , , , , . .
— , .
:
— , . : « , , ?» , , -, , .
:
— , .
:
— . , , «».
:
— , . . , , , . . , — ?
:
— , . , . . , .
:
— .
:
— . . … , . .
:
— , ?
:
— , .
:
— , . Porto. overhead Porto , ?
:
— Porto , - cgroups . cgroups — Porto.
:
— , « ». . , , ? , — , - , ?
:
— . , , , . .
, , . . , , - .
:
— . , - — - , - … , - , , , . -. .
:
— , , . , 24/7/365, - . - . .
:
— . - ?
:
— . : , . , - , - . : - - 90% , , , 90% - , - . .
:
— — . , , , : - , , , , , — - , . — - . , «». , . - , , - .
:
— . , , , SSD . : , SSD — , , — , .
:
— , « ». , ?
:
— . - , — . — , . .
, , , . — , 50% , , , , 50% .
Oleg Fedorov, head of the search runtime examination team, was among the speakers at a large Yandex search meeting that was held in early August. He spoke about all the main aspects of designing data centers for tasks related to processing huge amounts of data. Under the cut - decoding and slides Oleg.
My name is Oleg, I have been working at Yandex for six years. I started as a manager in the search quality department, now I’m more involved in issues related to the operation of our large data centers - I’m following our search to work, etc.
')
Let's try to speculatively design a small data center, 100 thousand machines that can respond with search, other services, etc. We will do it very simply, speculatively, on the tops.
Challenge search cloud. What are we facing? What principles are guided when building our large systems?
As any theater begins with a hanger, you can try to start building a data center with the processor on which we will design our servers, on what equipment it will work, how much it will be, etc. For this we will try to go through three simple steps . We want to test our equipment. We want to calculate how much it will cost us to own such equipment. We want to somehow choose the optimal solution. Picture to attract attention:
In the near future to build our data center, choose an interesting processor for us and be ready for a year and a half, you need to get engineering samples in advance. Many of you know this because you tested the equipment before it appeared on the mass market.
What will we test? Let's take the tasks typical for the cloud that will work on our servers most often: search, a piece of the index that the output draws to us, something else. Take all these samples, look for anomalies.
There was a vivid example: we took the processor model of one of the manufacturers and the rendering time was very bad. Surprise. Understood: indeed, there was a problem with the compiler, but nevertheless an anomaly may occur. Another example: the manufacturer declared a new set of SSE instructions, we rewrote our code a little bit - it became much faster. This is a kind of competitive advantage of our model, all is well.
We dive a little. Suppose we chose a certain set of processors. Here are my favorite pictures to attract attention. This is my iPhone recently overheated.
Geographical location. We all know that a data center can be built for a Russian company in Russia or not in Russia - in different countries, in different climatic and geographical zones. For example, at the equator it will be hot, but you can use solar electricity. In the north, electricity will be more complicated, but with cooling everything is very good, etc. Everywhere there are pros and cons.
It will be necessary to think about the maintenance of our data center. It may be difficult to deliver components to some cold region or to some strange country with an unpredictable administrative resource. It will be possible to get some components only with great difficulty, etc.
Be sure to count for each of our set of processors the rest of the infrastructure. If we take a processor that emits 160 watts of heat, probably we will need to think about cooling, we need a more powerful radiator, a more powerful server.
Where in this place is the industry? We want, like everyone else, to be cooled with outboard air. Take the air temperature outside from the street, blow through our servers, get cooling. In this way, we will ensure that as much energy as possible is spent on our final calculations, and as little as possible on the servicing infrastructure.
Many people know: there is a coefficient of PUE, everyone aspires to one. Suppose we calculated how much the processor is ready to perform standard operations and estimated the cost of ownership approximately. I specifically encrypted the names of the processors, these are all kind of speculative numbers. What is the general approach? As a rule, it looks like the processor of maximum performance starts to push ahead a bit and its conditional cost of ownership of the solution with performance per core increases exponentially. Optima live somewhere along the road.
There is always an exception to this rule. We want for some non-mass applications, where latency is very critical, to get maximum performance per core. Or we want to quickly collect, draw, etc. something online - we can afford to take a few percent of exceptional equipment.
Let's try to look at other aspects. We have a very complex multidimensional space: processor, memory, SSD, disks, network, a number of undiscovered measurements. We are constantly expanding. All this has to be thought of. The model is complex, multidimensional, the Internet is slowly changing, our approaches to search are changing. All of this we are laying in the model and be sure to calculate.
The second picture to attract attention:
Many probably learned the distribution in relic radiation - this is how we try to computer simulate what our Universe looks like. Data looks about the same. There are very hot sites. For example, for some reason everybody is looking for VKontakte, I don’t know why. Or some kittens. This data is very hot, often used, I really want to put it in memory somewhere closer to the processor, etc. And there are some drivers. My previous laptop is already 10 years old, and for it, under the old Ubuntu, drivers were needed. For some reason, no one, except me, this request did not arise for a long time. I tried to search the logs - no one is interested. This data is probably not needed by anyone - I will put it somewhere far away, on cold disks with a little complicated replication, etc.
Fortunately, we have everything exponentially. The hottest data is very small, you can try to reach it to the memory. And the most uninteresting and unnecessary Korean spamming sites can be put somewhere on the discs and forget about them.
A picture of how complex requirements are in various applications in our cloud. Let's try a little to classify the applications that we have. There is an analogy: I bought an empty aquarium, I want to run the fish there, but before that I have to put some beauty in there — put large pebbles, buttons, that's all. In addition, the aquarium needs sand and water. If I just pour water and only then begin to place everything, it will be dirty for me, it will be difficult to move the stones, etc.
Approach such: we will select the application in our cloud which demands some specific iron, for example GPU. It is clear that the GPU to put in every server is a dream, but rather expensive. Let's place our applications demanding specific iron, on those servers where such iron is. This is step number one.
Step number two: take and sift hard, prostandartize our sand and our main applications — find out how much memory they will consume, how much processor they need, what time of day, how much network they need, how they will deliver data, etc. We clearly plan and understand, for example, that these applications are massive, ready to run anywhere, and it is important to comply with their requirements.
Further, when we made a kind of placement of our sand, in all the free sites we fill in our typical batch tasks - machine learning tasks. As we know, at night most of the people in Russia are asleep. Therefore, there are fewer requests to the search, the processor is released, and I would like to use it. Night is the heyday of batcha, the renaissance of various tasks that are not so closely related to the user's response.
Next step. We have planned our applications in the cloud, but how do we avoid interference between them? How to make so that those wolves who have planned the correct amounts of RAM and processor for themselves, correctly consumed this volume? How to make sure that they are not harmed by poor innocent lambs, who should not consume anything, but who have had some kind of memory leak, an explosion in the number of requests, and who are starting to fill the processor with neighboring tasks? We need borders, bulkheads.
What are the approaches in the industry? Everyone has heard, and someone who has a laptop on Linux, tried to cheat, set up cgroups for himself in some way to shield the application, set limits for it and make everything more or less good.
What is the second common approach? Let's run each application simply in separate virtuals. We get overhead, of course: nothing happens for free. The processor will consume more, a little memory - the fact is that the memory pages, we sometimes will be considered several times. Many modern solutions are already less sick of it, but a specific processor is required, and so on.
What all come to? To a small thin layer - the container enclosing the application.
When we started this story in our cloud, Docker was not so advanced. Its modern binding is impressive - a lot of work has been done. We did our very similar thing. Called Porto. We wanted to easily manage hundreds - already thousands - of applications: so that they do not interfere with each other, so that the configuration process is very simple and in some sense we describe all application limits, understand how it will work, what it needs, where it you need to store data, what is this application dedicated IP-address. That is, it was necessary to describe everything that binds us to multidimensional space, run this container and forget about it.
On the other hand, from the point of view of the application itself, it is practically in the virtual machine. He has his own little chroot, not the entire processor and not the entire RAM is visible. Received advantages in its simplicity in the deployment system, received accounting for resources. We are not very interested in what the application does inside of itself, what subroutines it starts, what it does with data, etc. We are interested in what was happening around this application, that is, the counters from the container. And as another nice bonus, we got the opportunity to run sub-containers nested. We allocated a set of resources for some task or problem and gave the name of this container everything. Then the application can inside itself somehow redistribute the space and run subroutines also in subcontainers, also in isolation. As a result, we get our beautiful submarine, where each compartment is isolated. If someone has a leak somewhere, something exploded, then it exploded only there - locally.
So, we insulated everything, planned everything into clusters. And how to find where application instances work?
How do we solve the discovery problem? There are several approaches. One of the most typical: the application starts, knocks somewhere in the central point, says - I'm here, I will serve such and such traffic, I am of a certain type, I'm fine. Our approach is very similar to this. We have integration with the monitoring system. When the system sees that an application of a certain kind is running on the machine, it saves some meta description of it. When other applications will then look for a list of backends for themselves, they will be able to use this description.
Everything is fine with us. We are on a submarine, everything is insulated, and so on. But then everything begins to break. Imagine that we work in a taxi company. We have a hundred taxis. It will always be like this: one car has a flat tire, no one can drive another, a strange steering wheel, etc. Some cars will always be broken. We need to get used to the fact that a few percent of our applications — system nodes — will always be broken. This should be laid at the stages of calculating replications, loads on each node, etc.
What can break? If we wrote a not quite good version of the application - it, of course, falls. Handles a certain number of requests and drops. The test was not found - they saw it in the cloud. OS crashes. Let's take a new super security update, which does not affect anything in runtime. Let 's release it - applications will start to fall, because we have touched something in the core. Our server will break. He worked in uptime for two years, everything was fine, but the RAM started to get lost, disks began to fall out, etc.
Servers in the data center are in racks. Power is centrally supplied to the rack, a network is locally supplied, several veins. This all can refuse, break. We must be prepared for the fact that the entire stand breaks down. It is necessary that the critical parts of our index or application, which are not very much running in our cloud, should not be placed in one rack, but should be kept as blurred as possible.
Racks, several tens or hundreds, are combined into modules. A fireproof piece of the data center is formed, so that in the event of a malfunction, not the entire data center was damaged, and the module could be insulated.
But also entirely, happens, the data-center breaks. What do you think, at what time of year data centers often fall off the network and communication channels suffer?
- ...
- Why is spring? No, modern optics expands and shrinks perfectly. Spring is right, but why? Sowing. Agricultural industry wakes up, begins to demolish optics in those places where it does not exist. Builders wake up and start doing the work that they could not do in the winter. In the spring, communication channels are affected, etc.
Let's try to classify the problems of our accident. Here the guys dropped the satellite to the floor, trouble.
We have broken one or two percent of our nodes, equipment, whatever. This is a routine task: in our taxis one or two or three cars will always be laid up, you have to be ready for this.
A serious problem is when we have 5-7% of the nodes failed. Probably, some release of the infrastructure component did not go as we expected. Maybe we broke something in the network, maybe in something else. We need to understand this problem, but it is not critical - our services continue to work, it is in this fragment of our infrastructure that everything is fine.
Disaster - when 15-20% of nodes are out of order. There was clearly something wrong here, it makes no sense to release the program, roll out something, reconfigure it. It is necessary to remove the load, to take more active steps. This is not a viable situation. Probably, many are familiar with this approach.
What can you do in such cases? Let's start with the simple. We have broken cars. They can break just programmatically. Hung server. You must be able to detect this, be able to try to communicate with this server over IPMI in order to do something with it. We present the work of our monitoring systems, the detection of faults and attempts to fix it; we present the application in the data center as a cartoon about the WALL-E robot. Such robots travel around the cluster, everyone is trying to fix it, and they report to a certain central point about what is happening here. So, the first approach is auto repair.
How else can you deal with the fact that everything breaks all the time? There is a pessimization of backends. Suppose we have application A, it goes to 10 backends of applications B. One of the backends suddenly begins to respond noticeably slower, to 100 ms. We can calmly pessimize this backend, start asking a lot of requests into it — continue to ask to monitor its state, but translate requests to the remaining 9 healthy and alive backends. Nothing will happen - all is well. We teach our applications to be careful, to be able to understand that under us is a backend and that something has happened to it.
Here is a different approach. Appendix A has become an attachment B to send traffic many times more than we expected. It is convenient to be able to turn off some of its functionality and start responding, perhaps even quite correctly, but at a much lower cost in terms of the CPU. For example, a little less deep search, if we are talking about the search. We are not raising 1000 documents, but 900, slowly pushing the line aside. It seems to be imperceptible, but we significantly increase our throughput at the moment when we really need it. This is a degradation.
When a serious catastrophe has already happened, the understandable step is to balance, deflect the load. We must be able to isolate any site, including the entire data center. It may be necessary to divert traffic from there and then divert the node to maintenance to do something with it.
How to understand that all our applications are able, working and designed according to this scheme? It is necessary to conduct regular exercises: disconnect nodes, disconnect a large number of servers, disconnect data centers. This should happen unexpectedly for the teams of these applications - so that there are no stories, as if we are manipulating a load or something else. This should be an honest normal accident, but with the ability to quickly return everything to its original state. We are not waiting for spring to come and one of the canals will move us with an excavator. We will turn it off ourselves and see what happens. We cut our infrastructure - see what happens.
Houston, we have a problem. We diagnosed the problem to the point where it is no longer a routine, but the problem — 5-7% or a catastrophe. This is a must understand. What are typical search engineers looking for? Is some release or launch coming now? Probably, if the application worked well for weeks, for weeks, and everything was fine, but now suddenly, at one o'clock, the response time sank, then something changed. Probably a release was launched.
What are we trying to look at? , . , , . 8:30 8:30 . 20% — , - .
. , , . . , , .
. , . , , , , , .
. . Netscape Navigator, , . . , . ? ? , ? . .
. , . , , , . , . .
. 15 , . . , . - . , , - — . — - .
. : 100 , 200 . . , . - . , . , . , , . , .
, . : , - , , , , , . — , .
, -, , , , , , , , .
:
— , ?
:
— , . , , - .
, :
— , . — , , . , . , - — .
:
— , Startup Makers. Google open source solution — Kubernetes. Porto. ?
:
— , , . . - - .
:
— , . , NIH — not invented here. , , . open source , .
Porto — , Docker. .
:
— Docker .
:
— , , , , . , , , — open source.
:
— , Kubernetes. , , , , Google. Service discovery — . , , , — ? , - etcd-, key value, - ?
:
— , , . . — -, , , . — push, call.
:
— , . . - ? ?
:
— . — . .
:
— Kubernetes Kube Dash, , - . . CoreOS, , . - UI- , AWS , , ?
:
— , . , . : , , , . .
UI . , , , UI . 100 , , , , . .
— , .
:
— , . : « , , ?» , , -, , .
:
— , .
:
— . , , «».
:
— , . . , , , . . , — ?
:
— , . , . . , .
:
— .
:
— . . … , . .
:
— , ?
:
— , .
:
— , . Porto. overhead Porto , ?
:
— Porto , - cgroups . cgroups — Porto.
:
— , « ». . , , ? , — , - , ?
:
— . , , , . .
, , . . , , - .
:
— . , - — - , - … , - , , , . -. .
:
— , , . , 24/7/365, - . - . .
:
— . - ?
:
— . : , . , - , - . : - - 90% , , , 90% - , - . .
:
— — . , , , : - , , , , , — - , . — - . , «». , . - , , - .
:
— . , , , SSD . : , SSD — , , — , .
:
— , « ». , ?
:
— . - , — . — , . .
, , , . — , 50% , , , , 50% .
Source: https://habr.com/ru/post/310258/
All Articles