What is such a Data? Or again about MapReduce
If you spent the last 10 years on a remote island, without the Internet and in isolation from civilization, then especially for you, we will try to tell you again about the MapReduce concept. The introduction will be small, in sufficient volume, for the implementation of the MapReduce concept in the InterSystems Caché environment. If you are not very far removed the last 10 years, then immediately go to the second part, where we create the foundations of infrastructure.
Let's immediately decide, I am not a big fan of MapReduce, which could be guessed from my previous articles / translations - Michael Stonebriker - "Hadoop at the Crossroads" and "Command Line Utilities can be 235 times faster than your Hadoop cluster" [If to be more precisely, I am not a fan of Java implementations of Hadoop MapReduce, but this is already personal]
In any case, despite all these reservations and shortcomings, there are many more reasons that force us to return to this topic and try to implement MapReduce in a different environment and in another language. We will announce all this later, but before that we'll talk about BigData ...
When is Data big and when is it small?
A few years ago, everyone began to go crazy over BigData, no one really knew when his small data became large, and where was the limit, but everyone understood that it was fashionable, youth and “so” to do. As time went on, some people announced that BigData was no longer a buzzword (this is pretty funny, but Gartner actually removed BigData with a willful decision from the basewords for 2016, justifying it by the fact that the term was split into others). Regardless of the desire of Gartner, the term BigData is still among us, very much alive, and I think it's time to decide on his understanding.
For example, do we fully understand when our “not very big data” turns into “BIG DATA”?
The most specific (of the reasonable) answers were given by David Kanter, one of the most respected experts on processor architecture in general and x86 in particular1:
FWIW, when I, while working at Intel, switched to a hardware team working on a “next generation processor” (don'task), I started by studying materials about the Nehalem processor architecture on the David Kanter website, and not from HAS and MAS internal docks . Because as David was better and clearer.
Those. if you have “only a couple of terabytes” of data, then you will most likely be able to find the hardware configuration of the server machine sufficient for all data to fit in the server’s memory (with enough money and motivation, of course) and your data not really big.
BigData starts when this approach with vertical scaling (finding a “better” machine) stops working, because with a certain size of data you can no longer buy a larger configuration, for any (reasonable) money. And we must begin to grow in breadth.
Easier - better
Ok, having decided on what size our data has grown to the BigData term, we need to decide on the approaches that work on big data. One of the first approaches that began to be massively applied to big data was MapReduce . There are many alternative software models working with big data that may even be better or more flexible than MapReduce, but it can definitely be considered the most simplified, although it may not be the most effective.
Moreover, as soon as we begin to consider some kind of software platform, or database platform, for BigData support, we assume by default that the MapReduce script is supported on this platform by internal or external utilities.
In other words - without MapReduce, you cannot claim that your platform supports BigData!
ALARM - if you have not been on the moon for the last 10 years, you can safely skip the story about the basics of the MapReduce algorithm, most likely you already know. For the rest, we will try (once again) to tell about how it all began, and how you can use it all at the end of 2016. (Especially on platforms where MapReduce is not supported out of the box.)
It has often been observed that the simplest approach to solving a problem allows one to obtain the best results, and it remains to live in a product for a long time. Outside of the original plan of the authors. Even if, as a result, he is not the most effective, but due to the fact that the community has already widely recognized him and studied everything, and he is simply good enough and solves problems. Approximately this effect is observed with the MapReduce model - being very simple at its core, it is still widely used even after the original authors declared its death .
Scaling in Caché
Historically, InterSystems Caché had enough tools in its arsenal, both for vertical and horizontal scaling. As we all know (sad smile) Caché is not only a database server, but also an application server that can use ECP (Enterprise Cache Protocol) for horizontal scaling and high availability.
The peculiarity of the ECP protocol - being a highly optimized protocol for the coherence of access to the same data on different cluster nodes, strongly rests on the write daemon performance on the central node of the database server. ECP allows you to add additional counting nodes with processor cores, if the write-daemon load is not very high, but this protocol does not help scale your application horizontally, if each of the nodes involved generates more write activity. The disk subsystem on the database server will still be a bottleneck.
In fact, when working with big data, modern applications involve the use of a different, or even orthogonal approach, voiced above. You need to scale the application horizontally using the disk subsystem on each of the cluster nodes. Unlike ECP, where data is brought to a remote node, we, on the contrary, bring a code, the size of which is assumed small, to data on each node, the size of which is assumed to be very large (at least relative to the size of the data). A similar type of partitioning, called sharding, will be implemented in the future in the Caché SQL engine in one of the future products. But even today , using the tools available in the platform , we can implement something simple that would allow us to design a horizontally scalable system using modern, “fashionable, youth” approaches. For example, using MapReduce ...
Google MapReduce
The original implementation of MapReduce was written in Google in C ++ , but it turned out that the widespread paradigm began in the industry only with the implementation of Apache's MapReduce, which is in Java. In any case, regardless of the implementation language, the idea remains the same, whether it is implemented in C ++, Java, Go, or Caché ObjectScript, as in our case.
[Although, for the Caché ObjectScript implementation, we will use a couple of tricks available only for operations with multidimensional arrays, known as globals . Just because we can]
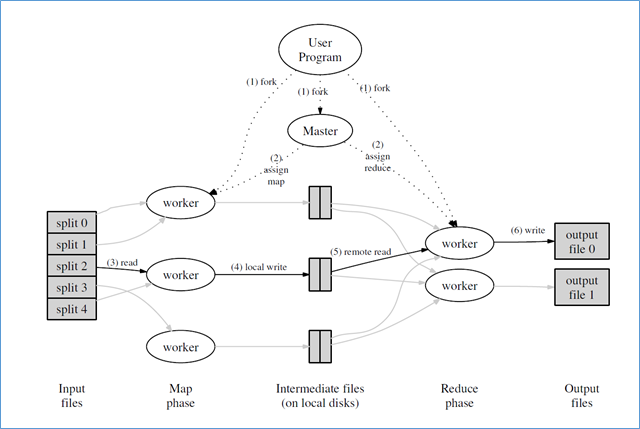
Figure 1. Execution of the MapReduce environment in the “MapReduce: Simplified Data Processing on Large Clusters”, OSDI-2004
Let's go through the stages of the MapReduce algorithm drawn in the picture above:
At the entrance, we have a set of "files", or a potentially infinite stream of data, which we can split (partition) into several independent pieces of data;
We also have a set of parallel executors (local inside the node or may be remote, on other nodes of the cluster) which we can designate as handlers for input data pieces (“map” / “ map ” stage)
These parallel handlers read the input data stream and output key-value pair (s) to the output stream. The output stream can be written to output files or somewhere else (for example, to the cluster file system Google GFS, Apache HDFS, or to some other “magic place” replicating data to several cluster nodes);
- At the next stage, called “convolution” / “ reduce ”, we have another set of handlers that deal with (surprise) ... convolution. They read, for a given key, the entire collection of data, and output the resulting data as successive “key-values”. The output stream of this stage, similarly to the previous stage, is recorded in the magic cluster file systems or their analogues.
Note that the MapReduce approach is batch in nature. It does not handle endless input data streams very well, due to batch implementation, and will wait for the completion of work at each of its stages (“mapping” or “convolution”) before moving further in the pipeline. This is different from the more modern flow algorithms used, for example, in Apache Kafka, which, by their design, are aimed at processing “infinite” input streams.
Knowledgeable people missed this section, and unaware, I think, are still confused. Let's look at a classic example of word-count (counting words in a data stream), which is traditionally used to explain the implementation of MapReduce in different programming languages and in different environments.
So, let's say we need to count the number of words in the input collection (rather large) of files. For clarity, we define that a word will be considered a sequence as a character between whitespace, i.e. numbers, punctuation are also considered part of the word, this is certainly not very good, but in the framework of a simple example, this does not bother us.
Being a C ++ developer in the depths of my soul, for me the algorithm becomes clear when I see an example in C ++. If “you are not like this”, then do not worry, soon we will show it in a simplified form.
#include "mapreduce/mapreduce.h" // User's map function class WordCounter : public Mapper { public: virtual void Map(const MapInput& input) { const string& text = input.value(); const int n = text.size(); for (int i = 0; i < n; ) { // Skip past leading whitespace while ((i < n) && isspace(text[i])) i++; // Find word end int start = i; while ((i < n) && !isspace(text[i])) i++; if (start < i) Emit(text.substr(start,i-start),"1"); } } }; REGISTER_MAPPER(WordCounter); // User's reduce function class Adder : public Reducer { virtual void Reduce(ReduceInput* input) { // Iterate over all entries with the // same key and add the values int64 value = 0; while (!input->done()) { value += StringToInt(input->value()); input->NextValue(); } // Emit sum for input->key() Emit(IntToString(value)); } }; REGISTER_REDUCER(Adder); int main(int argc, char** argv) { ParseCommandLineFlags(argc, argv); MapReduceSpecification spec; // Store list of input files into "spec" for (int i = 1; i < argc; i++) { MapReduceInput* input = spec.add_input(); input->set_format("text"); input->set_filepattern(argv[i]); input->set_mapper_class("WordCounter"); } // Specify the output files: // /gfs/test/freq-00000-of-00100 // /gfs/test/freq-00001-of-00100 // ... MapReduceOutput* out = spec.output(); out->set_filebase("/gfs/test/freq"); out->set_num_tasks(100); out->set_format("text"); out->set_reducer_class("Adder"); // Optional: do partial sums within map // tasks to save network bandwidth out->set_combiner_class("Adder"); // Tuning parameters: use at most 2000 // machines and 100 MB of memory per task spec.set_machines(2000); spec.set_map_megabytes(100); spec.set_reduce_megabytes(100); // Now run it MapReduceResult result; if (!MapReduce(spec, &result)) abort(); // Done: 'result' structure contains info // about counters, time taken, number of // machines used, etc. return 0; } The program above is called with a list of files that need to be processed, transmitted via standard argc / argv.
The MapReduceInput object is instantiated as a wrapper for accessing each file in the input list and is scheduled for execution by the WordCount class to process its data;
MapReduceOutput is instantiated to redirect output to the GoogleGFS cluster file system (note / gfs / test / *)
The classes Reducer (scroller, hmm) and Combiner (combinator) are implemented by the C ++ class Adder, the text of which is given in the same program;
The Map function in the Mapper class, implemented in our case in the WordCouner class, receives data through the generic MapInput interface. In our case, this interface will deliver data from files. The class implementing this interface must implement the value () method, supplying the following string as string, and the length of the input data in the size () method;
As part of the solution of our task, counting the number of words in a file, we will ignore the whitespace characters and count everything else between spaces as a separate word (regardless of the punctuation marks). We write the found word to the output “stream” by calling the function Emit (word, "1");
The Reduce function in the implementation class of the Reducer interface (in our case, this is Adder) gets its input data through another generalized interface, ReduceInput. This function will be called for a specific key (words from a file, in our case) from the key-value pair recorded at the previous Map stage. This function will be called to handle a collection of values advising this key (in our case for the sequence "1"). As part of our assignment, the responsibility of the Reducer function is to count the number of such units at the input and output the total number to the output channel.
- If we have built a cluster of several nodes, or just launching a lot of handlers within the MapReduce algorithm, then the responsibility of the “master” will split the stream of output key-value pairs into the corresponding collections, and redirect these collections to the input Reduce handlers.
The details of the implementation of such a master node will depend heavily on the implementation protocol of the clustering technology used, including we omit the detailed account of this beyond the current narrative brackets. In our case, for Caché ObjectScript, for some of the algorithms in question (like the current WordCount) the master can be implemented trivially, due to the use of globals and their nature as sorted but sparse arrays. What more later.
- In general, it is often necessary to have several Reduce steps, for example, in cases where it is impossible to process a complete collection of values in one go. And then additional (s) Combiner stage (s) will appear, which will additionally aggregate the results of the data from the previous Reduce stages.
If, after such a detailed description of the C ++ implementation, you still do not understand what MapReduce is, then let's try to portray this algorithm on several lines of the same known scripting language:
map(String key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); reduce(String key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); As we see in this simplified example, the responsibility of the map function will produce a sequence of pairs <key, value>. These pairs are mixed and sorted in the wizard, and the resulting collections of values for a given key are sent to the input of the reduce functions (convolution), which, in turn, are responsible for generating the output <key, value> pair. In our case, it will be <word, counter>
In the classical implementation of MapReduce, the transformation of a collection of pairs <key, value> into separate collections of <key, value (s)> is the time and resource-intensive operation itself. In the case of Caché implementations, both because of the nature of the implementation of the btree * repositories and the ECP interconnect protocol, sorting and aggregation on the wizard does not become such a big task, which is implemented almost on an automatic machine, almost without charge. We will tell about this on occasion in the following articles.
Perhaps this is enough for the introductory part - we have not yet touched upon the actual Caché ObjectScript implementation, although we have provided enough information to start implementing MapReduce in any language. We will return to our implementation of MapReduce in the next article. Stay on the line!
')
Source: https://habr.com/ru/post/310180/
All Articles