Briefly about Java MemoryModel for those who have little time, but I wanted to figure it out
This article in some kind of squeeze what you could find out by viewing various videos of Mr. Shipilev, Elizarov, Smirnov. Actually, we even put together a playlist for you if you want to go "the hard way". In the article I will only try to convey to you some basic thoughts / ideas that, if you wish, you can study much more deeply in the original sources.
So now let's move on to the actual subject. Even five years ago, it was possible not to give a lot of single-thread programs that were hardly launched on top-end hardware and know that in a year or two this piece of “program” (sorry for the allegory) will start working normally. Today, this “free lunch” is over.
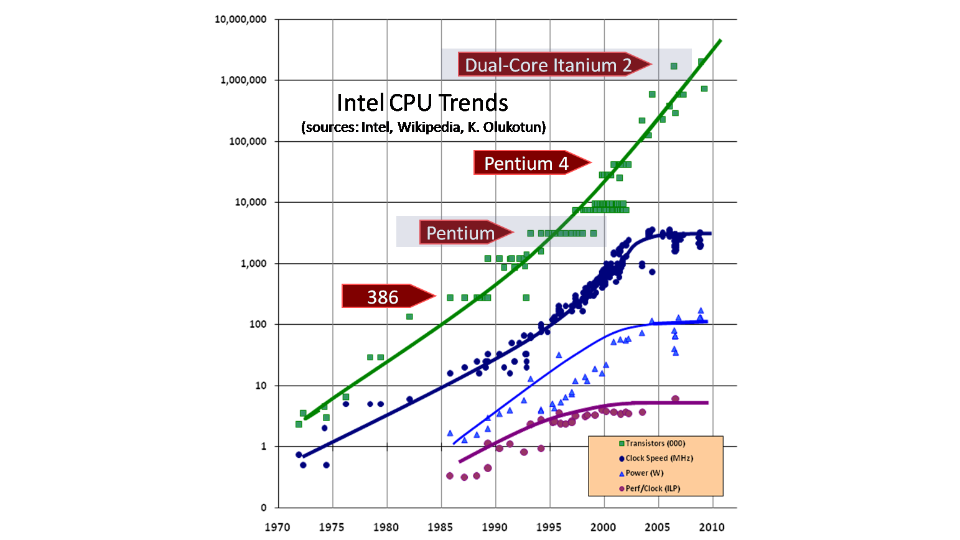
The picture clearly shows that the number of transistors is still growing, but in terms of frequencies, we have almost reached the ceiling. The "curvature" of the hands of developers is difficult to compensate for the fact that in a year the iron will work twice as fast. Although not everything is so sad, processors are still growing, only in terms of the number of cores. As a result, in order for the “program” written by Krivoruk orkom to be able to work at least normally on a new hardware, it is necessary for it to work normally in a multiprocessor environment. And the performance was directly related to the number of cores on the gland. That's actually from that, but what is “normally worked in a multiprocessor environment” we will talk further.
There may be two answers. First, if you write for a specific hardware, for Intel Xeon, or God forbid Itanium or Elbrus, your code will be completely different and tailored for a specific hardware. This code will squeeze everything out of the gland, but will be very weakly scalable. This is suitable when writing 3D games for a specific piece of hardware and you need to squeeze all of today's hardware, PS4 for example, and not wait for a mythical tomorrow. And what do ordinary programmers who darn “Heil Mir” do under abstract platforms in vacuum and do not understand the difference between VLIW CPU architecture and RISC? They also need to somehow program multi-threaded programs so that they work efficiently on today's hardware, and on tomorrow (new hardware) to work even faster. And this piece of the program, which could work on the sewing machine "Singer", still after the "skillful" implementation could be run on the cluster.
')
Not so how to be programmers? Any problem can be solved as? That's right, by adding a new level of abstraction. Of course, this situation is no exception. An abstract machine (AM) comes to the aid of programmers, under which most programmers actually write code. AM is in fact a tradeoff between the desires of engineers to know less and use the most simplistic and high-level concepts (hi FP), in which ponies live and poop with rainbows and a concrete real iron realization. She (AM) says that from now on, you programmers do not write for a specific hardware, you write for an abstract machine (you write everything for an abstract machine!) Which has an abstract memory and this memory works according to the described memory model. And already the compiler, JIT, interpreter, or God knows who else will be responsible for putting in the code / bytecode / etc, created for an abstract machine, on a specific implementation. That is, you write, for example, in C ++ code, I note, under an abstract machine (I mentioned C ++ because in its spec, at least C ++ 11, the memory model is very neat and clearly described), and already the compiler's task will be to translate this into working machine code for a specific hardware, for example, on Inantium (with the VLIW architecture) or on CISC processors. It is clear that different parts of your program will show different performance on different platforms.
Of course, if you want to squeeze the maximum performance out of your code, then anyway, you have to throw all these levels of abstraction to hell and rewrite everything as close as possible to the gland at a given time. Of course, this works if the problems are at the level close to the hardware, because if you have a slow algorithm, then adding complications to it by rewriting it at a low level is unlikely to save the situation. But it’s just not about those tasks where such “rem metal” is necessary. It's still about “abstract programmers”. Returning to abstraction, the question is why in the abstract machine we select MM, and why did it suddenly become relevant in recent years? It was a long time ago to describe an abstract machine, and work on these topics was carried out, but few were needed. The fact is that earlier with the predominance of single-threaded environment, all programs, one way or another, were determined. In the words of Shipilev, for a pragmatic programmer, MM should answer only one question: if I read variable A in the stream, then which result (if the record was not one) can I see?
In a deterministic single-threaded program, all this is simply enough to determine without even knowing the MM language in which you write. The program can be completely broken for multi-core architecture, but who cares if the yard is harsh in the nineties, and machines with more than one processor are supercomputers? Moreover, when the first opportunities to parallelize the P4HT program appeared, they gave their own and their vision of parallelism and, accordingly, the pioneers, as a rule, wrote the code not under 2-3 abstract streams, but under P4HT, which by itself was not scalable.
Let's get closer to the body. If we are going to give answers to questions about what we can read from memory, then we will look at the naive MM, as many of us imagine.
This system does not take into account how slowly the light propagates! It is slowly, despite the fact that we have always been taught that the light is fast enough, there are a couple of conditions. It is not so fast, but if we are not talking about ideal conditions in a vacuum, then ...
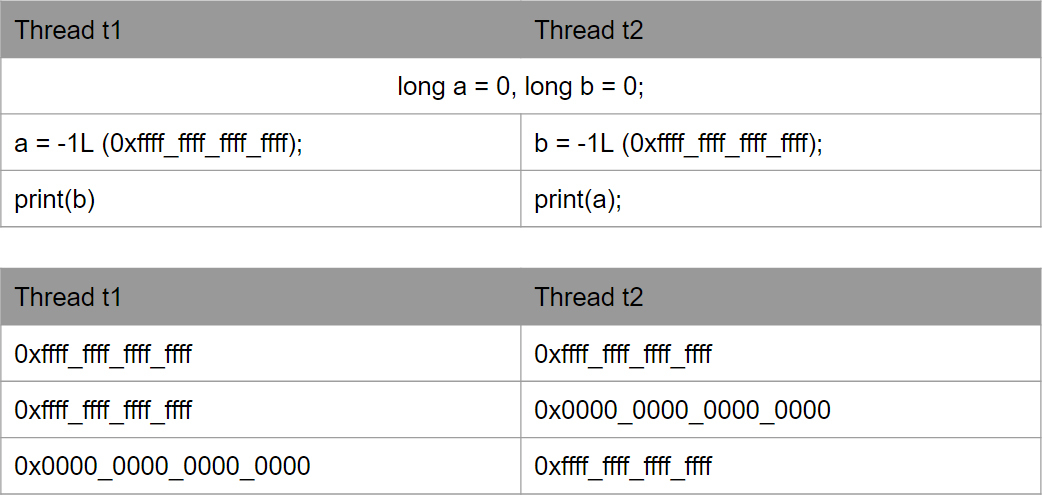
If you have a 3 GHz processor, the light for its one clock cycle passes 10 cm, in conductors and even less. As a result, processors are not physically capable of making changes from a variable to convey information about these changes to other processors. In practice, we can get the following options (this is without past options, but they are also valid). The most commonly confusing option is 0x0.
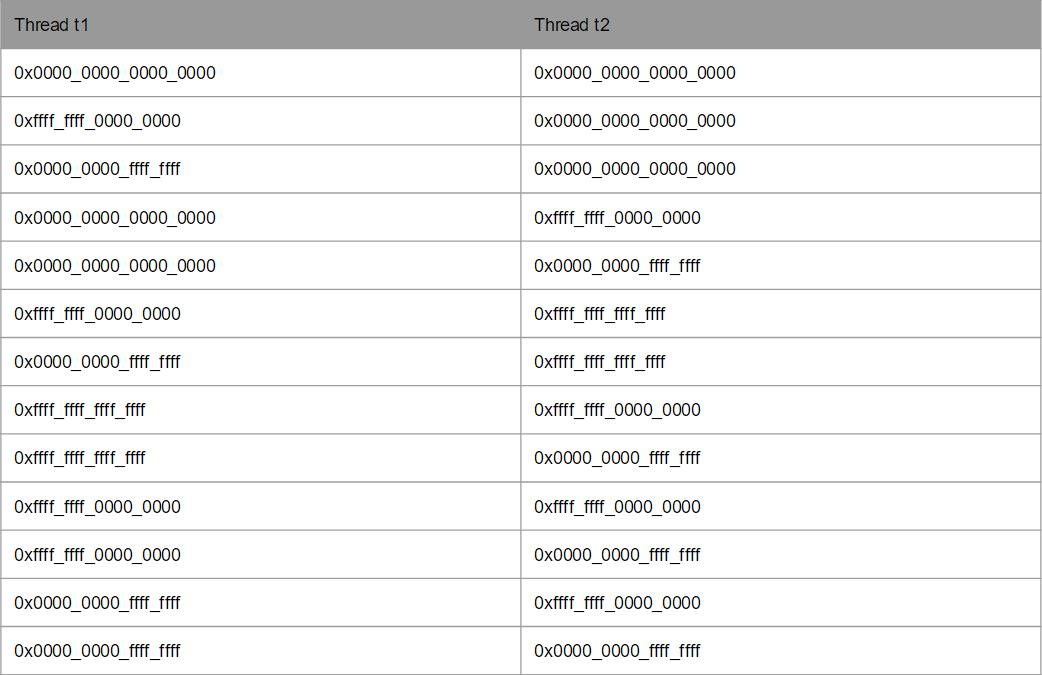
This is generally super funny as we, in fact, see in some sophisticated form the effect of time distortion at high speeds. Needless to say, strange results appear because of how the processor cores synchronize data with each other. But how cool it is to realize that we, programmers have their own processes, which in some way resemble relativistic physics =) We have two CPUs, they seem to be independent of each other and there is a physical exchange of data inside them and due to different restrictions they see each other in different ways, that one sees as the present (the variable “a” is zero, the second CPU sees it as the past, since for it this variable is already -1). Of course, out-of-sync is not caused by such speeds, such problems appeared due to the complexity of the processors. Indeed, if We think from this side, it is very easy for us to visualize all these paradoxes in a slightly modified example.

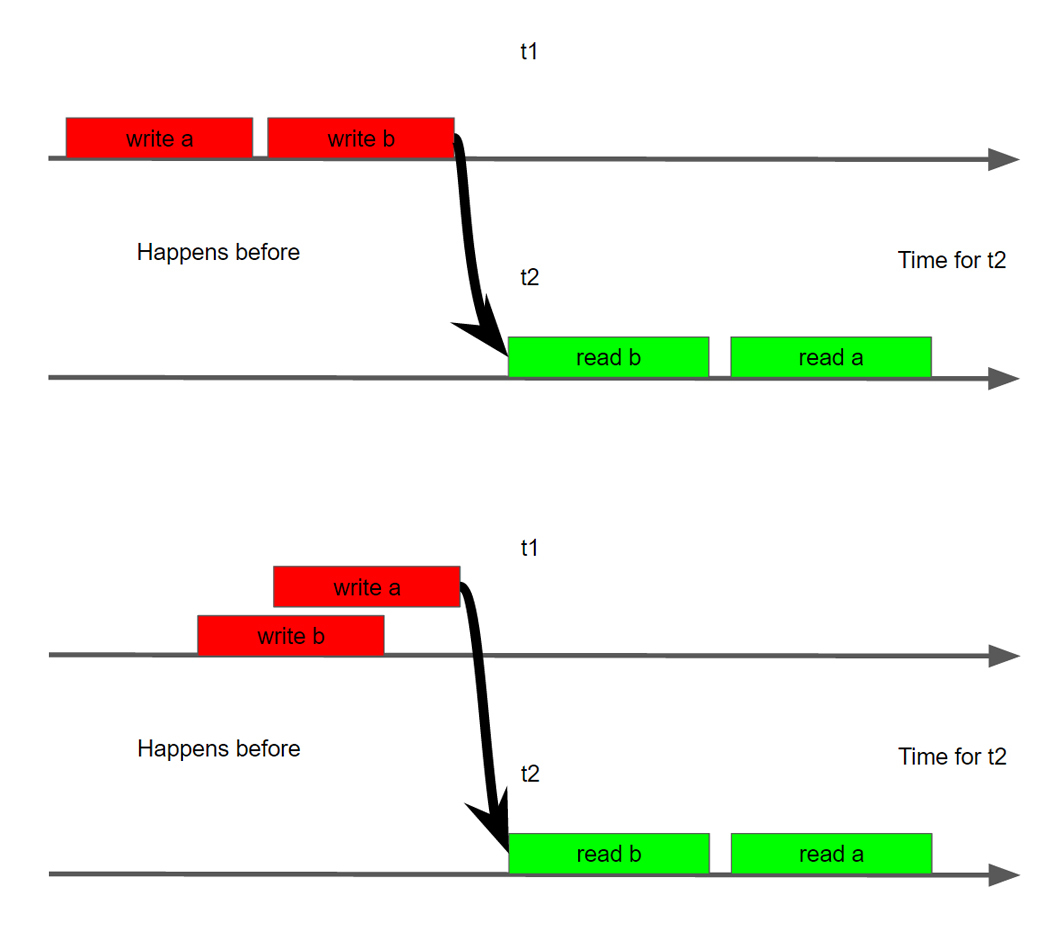
If you look at how stream 2 sees stream 1, then it can see anything. In the universe of thread 2, thread 1 can, for example, only do write a, i.e. write b may not occur at all. Can only see write b, write a can not come at all. May see write a write b, but their sequence may be completely different, not the same as inside stream 1.
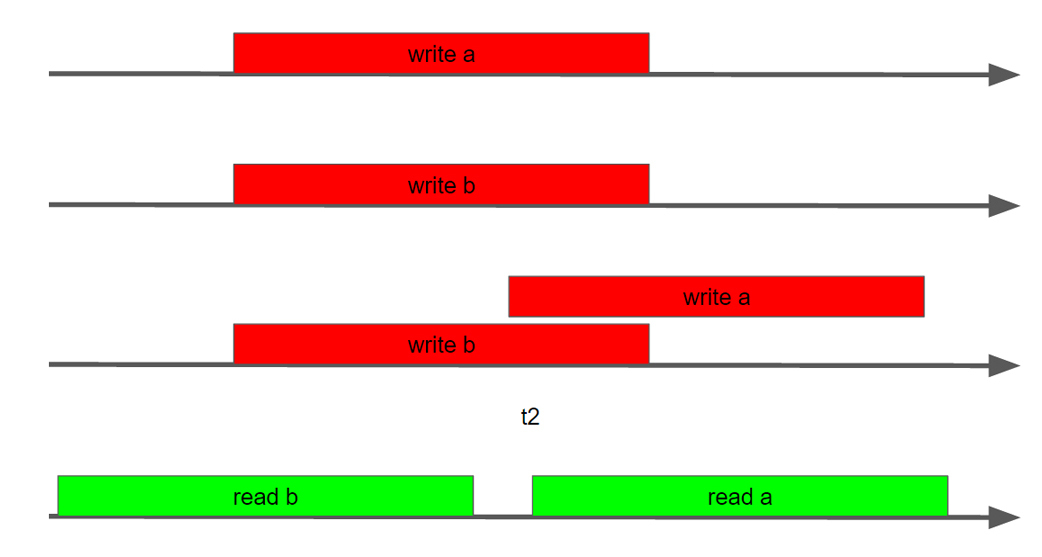
As it is not difficult to guess, the results will be completely unpredictable.

In earlier versions of Java, there was quite a lot of what was called “bugs.” In fact, the crowds of naive lemmings completely misunderstood the limitations of MM wrote the code, which in practice went into perpetual cycles. But in fact, Java simply used a number of optimizations, since it was naive to think that the developer knows what he is writing.
They wrote an excellent program, tested it on x86_64, then you run it on a 32-bit ARM (or PowerPC) and you get situations with surprises. And all because our Vasya Pupkin wrote for a specific iron on which he tested, although in fact he did not understand he wrote under Abstract Machine, the specification of which gives other guarantees (weaker) than the specific machine under which he wrote his code . Of course, the realization that he is writing to an abstract machine, the specs of which you need to know, will come after such breakdowns, but it will come very late when your code suddenly stops working on the client’s machine.
How can we help MM actually deal with this created porridge and lawlessness? One of the most fundamental concepts in MM is the concept of Happens Before being introduced by Lamport back in 1978. In simple terms, he says, yes, we have porridge, chaos and masturbation, but let's select from this disarray and vacillation several operations that will be ordered among themselves. This means that we will have two operations between threads in which we can say for sure that one operation will be strictly ordered with the second operation in the second stream. For clarity, this operation can be returned to our fake example.
And finally, in order to more clearly understand how often such examples occur and on what platforms, see exactly the situation I was talking about when you work on your local machine and everything works, simply because you are not writing for abstract machine, and for a particular iron, I recommend to see the report of Gleb Smirnov: “Multithreading under the hood” . Although before that, take a look at the general theoretical report of Roman Elizarov and of course Shipileva. We have carefully compiled all of these reports for you in the playlist so that you can simply view it all. We even sorted out reports for you.
So now let's move on to the actual subject. Even five years ago, it was possible not to give a lot of single-thread programs that were hardly launched on top-end hardware and know that in a year or two this piece of “program” (sorry for the allegory) will start working normally. Today, this “free lunch” is over.
The picture clearly shows that the number of transistors is still growing, but in terms of frequencies, we have almost reached the ceiling. The "curvature" of the hands of developers is difficult to compensate for the fact that in a year the iron will work twice as fast. Although not everything is so sad, processors are still growing, only in terms of the number of cores. As a result, in order for the “program” written by Krivoruk orkom to be able to work at least normally on a new hardware, it is necessary for it to work normally in a multiprocessor environment. And the performance was directly related to the number of cores on the gland. That's actually from that, but what is “normally worked in a multiprocessor environment” we will talk further.
There may be two answers. First, if you write for a specific hardware, for Intel Xeon, or God forbid Itanium or Elbrus, your code will be completely different and tailored for a specific hardware. This code will squeeze everything out of the gland, but will be very weakly scalable. This is suitable when writing 3D games for a specific piece of hardware and you need to squeeze all of today's hardware, PS4 for example, and not wait for a mythical tomorrow. And what do ordinary programmers who darn “Heil Mir” do under abstract platforms in vacuum and do not understand the difference between VLIW CPU architecture and RISC? They also need to somehow program multi-threaded programs so that they work efficiently on today's hardware, and on tomorrow (new hardware) to work even faster. And this piece of the program, which could work on the sewing machine "Singer", still after the "skillful" implementation could be run on the cluster.
')
Not so how to be programmers? Any problem can be solved as? That's right, by adding a new level of abstraction. Of course, this situation is no exception. An abstract machine (AM) comes to the aid of programmers, under which most programmers actually write code. AM is in fact a tradeoff between the desires of engineers to know less and use the most simplistic and high-level concepts (hi FP), in which ponies live and poop with rainbows and a concrete real iron realization. She (AM) says that from now on, you programmers do not write for a specific hardware, you write for an abstract machine (you write everything for an abstract machine!) Which has an abstract memory and this memory works according to the described memory model. And already the compiler, JIT, interpreter, or God knows who else will be responsible for putting in the code / bytecode / etc, created for an abstract machine, on a specific implementation. That is, you write, for example, in C ++ code, I note, under an abstract machine (I mentioned C ++ because in its spec, at least C ++ 11, the memory model is very neat and clearly described), and already the compiler's task will be to translate this into working machine code for a specific hardware, for example, on Inantium (with the VLIW architecture) or on CISC processors. It is clear that different parts of your program will show different performance on different platforms.
Of course, if you want to squeeze the maximum performance out of your code, then anyway, you have to throw all these levels of abstraction to hell and rewrite everything as close as possible to the gland at a given time. Of course, this works if the problems are at the level close to the hardware, because if you have a slow algorithm, then adding complications to it by rewriting it at a low level is unlikely to save the situation. But it’s just not about those tasks where such “rem metal” is necessary. It's still about “abstract programmers”. Returning to abstraction, the question is why in the abstract machine we select MM, and why did it suddenly become relevant in recent years? It was a long time ago to describe an abstract machine, and work on these topics was carried out, but few were needed. The fact is that earlier with the predominance of single-threaded environment, all programs, one way or another, were determined. In the words of Shipilev, for a pragmatic programmer, MM should answer only one question: if I read variable A in the stream, then which result (if the record was not one) can I see?
In a deterministic single-threaded program, all this is simply enough to determine without even knowing the MM language in which you write. The program can be completely broken for multi-core architecture, but who cares if the yard is harsh in the nineties, and machines with more than one processor are supercomputers? Moreover, when the first opportunities to parallelize the P4HT program appeared, they gave their own and their vision of parallelism and, accordingly, the pioneers, as a rule, wrote the code not under 2-3 abstract streams, but under P4HT, which by itself was not scalable.
Let's get closer to the body. If we are going to give answers to questions about what we can read from memory, then we will look at the naive MM, as many of us imagine.
This system does not take into account how slowly the light propagates! It is slowly, despite the fact that we have always been taught that the light is fast enough, there are a couple of conditions. It is not so fast, but if we are not talking about ideal conditions in a vacuum, then ...
In one cycle of a 3GHz processor, the light in vacuum passes 10cm!
Roman Elizarov
If you have a 3 GHz processor, the light for its one clock cycle passes 10 cm, in conductors and even less. As a result, processors are not physically capable of making changes from a variable to convey information about these changes to other processors. In practice, we can get the following options (this is without past options, but they are also valid). The most commonly confusing option is 0x0.
This is generally super funny as we, in fact, see in some sophisticated form the effect of time distortion at high speeds. Needless to say, strange results appear because of how the processor cores synchronize data with each other. But how cool it is to realize that we, programmers have their own processes, which in some way resemble relativistic physics =) We have two CPUs, they seem to be independent of each other and there is a physical exchange of data inside them and due to different restrictions they see each other in different ways, that one sees as the present (the variable “a” is zero, the second CPU sees it as the past, since for it this variable is already -1). Of course, out-of-sync is not caused by such speeds, such problems appeared due to the complexity of the processors. Indeed, if We think from this side, it is very easy for us to visualize all these paradoxes in a slightly modified example.
If you look at how stream 2 sees stream 1, then it can see anything. In the universe of thread 2, thread 1 can, for example, only do write a, i.e. write b may not occur at all. Can only see write b, write a can not come at all. May see write a write b, but their sequence may be completely different, not the same as inside stream 1.
As it is not difficult to guess, the results will be completely unpredictable.
In earlier versions of Java, there was quite a lot of what was called “bugs.” In fact, the crowds of naive lemmings completely misunderstood the limitations of MM wrote the code, which in practice went into perpetual cycles. But in fact, Java simply used a number of optimizations, since it was naive to think that the developer knows what he is writing.
They wrote an excellent program, tested it on x86_64, then you run it on a 32-bit ARM (or PowerPC) and you get situations with surprises. And all because our Vasya Pupkin wrote for a specific iron on which he tested, although in fact he did not understand he wrote under Abstract Machine, the specification of which gives other guarantees (weaker) than the specific machine under which he wrote his code . Of course, the realization that he is writing to an abstract machine, the specs of which you need to know, will come after such breakdowns, but it will come very late when your code suddenly stops working on the client’s machine.
How can we help MM actually deal with this created porridge and lawlessness? One of the most fundamental concepts in MM is the concept of Happens Before being introduced by Lamport back in 1978. In simple terms, he says, yes, we have porridge, chaos and masturbation, but let's select from this disarray and vacillation several operations that will be ordered among themselves. This means that we will have two operations between threads in which we can say for sure that one operation will be strictly ordered with the second operation in the second stream. For clarity, this operation can be returned to our fake example.
And finally, in order to more clearly understand how often such examples occur and on what platforms, see exactly the situation I was talking about when you work on your local machine and everything works, simply because you are not writing for abstract machine, and for a particular iron, I recommend to see the report of Gleb Smirnov: “Multithreading under the hood” . Although before that, take a look at the general theoretical report of Roman Elizarov and of course Shipileva. We have carefully compiled all of these reports for you in the playlist so that you can simply view it all. We even sorted out reports for you.
Source: https://habr.com/ru/post/310130/
All Articles