Bagri - NoSQL open source database built on top of distributed cache
Today I want to tell you about an open source project called Bagri . Bagri is a distributed database of documents (document database), or as it is now fashionable to say NoSQL database written in Java and designed to meet the requirements mainly used in the corporate sector, such as high availability, resiliency, scalability and support for transactionality.

The system is good to use in the first place in cases where the workflow is based on XML. These are finance, logistics, insurance, medicine, and other industries where the format of documents exchanged between participants is strictly defined by corporate XSD schemes. The system allows you not to parse each incoming document, but put it into the database as it is, and then efficiently perform any queries on stored documents using the powerful XQuery 3.1 toolkit.
')
Bagri is built on top of products that implement distributed cache, such as Hazelcast, Coherence, Infinispan, and other similar systems. It is due to the capabilities of the distributed cache that Bagri supports the requirements of the corporate sector right out of the box. The distributed cache is used by the system not only as a data warehouse, but also as a distributed system for processing this data, which allows you to efficiently and quickly process any large amounts of weakly structured data. Transactional in the system is solved using an algorithm that implements multi-version concurrency control
The data in the system are supplied as XML or JSON documents. There is also the opportunity to implement its extension to Bagri and register the plugin to work with new document formats, as well as with external document storage systems. The auxiliary project bagri-extensions contains extensions developed by the team (a connector to MongoDB is currently implemented).
XQuery is used as the query language, in the future it is also planned to support SQL syntax, this task is available in the project Github.
Bagri does not require prior knowledge of the data schema, but forms a data dictionary (unique paths in document structures) “on the fly” while parsing incoming documents. So Bagri is completely schemaless and does not need rebuilding tables for new document types, i.e. he does not need create table / add column commands in principle.
For communication between the client and the server, Bagri offers two APIs: the standard XQJ API declared in JSR 225 and its own XDM API, providing additional functionality that is missing in XQJ. In fact, XQJ interfaces are analogous to the functionality provided by the JDBC driver when working with relational databases. Together with the XQJ driver, the system comes with the official XQJ TCK, which you can run and make sure that the driver passes all XQJ tests 100%.
All documents in Bagri are stored in schemas, the closest analogue in a relational database (RDBMS) is database. Currently, Hazelcast is used as the distributed cache on which the system is built, and a separate Hazelcast cluster is allocated for each scheme. Schemes exist independently of each other, i.e. there is no “struggle” for resources between the schemes (in the Hazelcast each cluster is configured separately and has its own pool of resources).
Meta document data (namespaces, document types, unique paths) are stored in the corresponding caches and replicated between all nodes in the cluster. So Access to working nodes to read metadata is as fast as possible. The data of the documents themselves are separated from the metadata and stored in distributed caches, while the data relating to the same document is always stored on the same node. There are also caches for storing indexed values, for compiled queries, for the transaction log, and of course for the results of executed queries.
Bagri client connects to the server using internal cache client software mechanisms. XQuery requests on the client are packed into tasks and executed on server nodes via the distributed ExecutorService provided by the Hazelcast platform.
Results are returned to the client through a dedicated asynchronous channel (Hazelcast queue)
The entire system configuration is stored in two files: access.xml for settings of roles and users, and config.xml with settings for schemes and extensions Bagri. A detailed description of the format of these files and all the parameters used in them can be found in the installation and configuration instructions of the system . You can change schema settings directly in files, or through the JMX schema management interfaces deployed on the Bagri administration server.
Let's now move from theory to practice and consider how we can work with Bagri from our Java code through XQJ interfaces.
Inside the context of the spring, we declare the BagriXQDataSource bin and configure its four main parameters: the address of the remote server, the name of the scheme, the user name and password.
Get the XQJ connection:
Then we read the text file and on the basis of it we create a new document in Bagri:
The request above calls the store-document external function defined in the bgdm namespace. The function accepts 3 parameters as input: uri, under which the document will be saved, the text content of the document and an optional set of options that define additional parameters for the function of saving the document. The request is validated on the client side and then sent to the server along with the parameters.
On the server side, a unique identifier is assigned to the incoming document. Further, the contents of the document are parsed in accordance with the specified document format and divided into path / value pairs, while all unique paths are stored in the replicated directory of document paths. At the end of the parsing procedure, the entire contents of the document, divided into such pairs, is stored in the distributed caches of the system, and the document header with service information is also cached. If indexes are registered in the schema, all indexed values are also stored in the index cache. The confirmation of the successful saving of the document is transmitted back to the client side.
After we have successfully saved our document in Bagri, let's look at how we can make requests to documents stored in the system.
Get the XQJ connection:
Prepare an XQuery query:
Set the value of the search parameter:
Execute the request on the server:
And review the results:
I think it will be just as interesting to talk about what happens on the server when executing this code:
The query passes through the XQuery processor (currently Saxon ), in which the query execution tree (compiled query, XQueryExpression) is formed. Then it is translated into a set of simple queries to the cached data along the specified paths:
These simple queries are executed in parallel on all nodes of the distributed system cache. Found documents are delivered to the processor for further processing. Indexes are used whenever possible if the requested paths have been indexed. After final processing of the received documents by the processor, the results are transmitted back to the client through a dedicated asynchronous channel.
Bagri provides rich opportunities to expand the behavior of the system. For example, you can connect a trigger to any document status changes (before / after insert / update / delete) and execute additional business logic at these points. To do this, it is enough to implement the interface com.bagri.xdm.cache.api.DocumentTrigger, as shown in one of the examples supplied with the system (see samples / bagri-samples-ext):
And then register the trigger in the schema in the config.xml file:
As shown above, we registered the library (bagri-samples-ext-1.0.0-EA1.jar) containing the trigger implementation. Libraries can also contain additional functions written in Java that can be called from XQuery queries, as well as extensions for processing new data formats or connecting to external document storage systems.
Bagri can be deployed in the following ways:
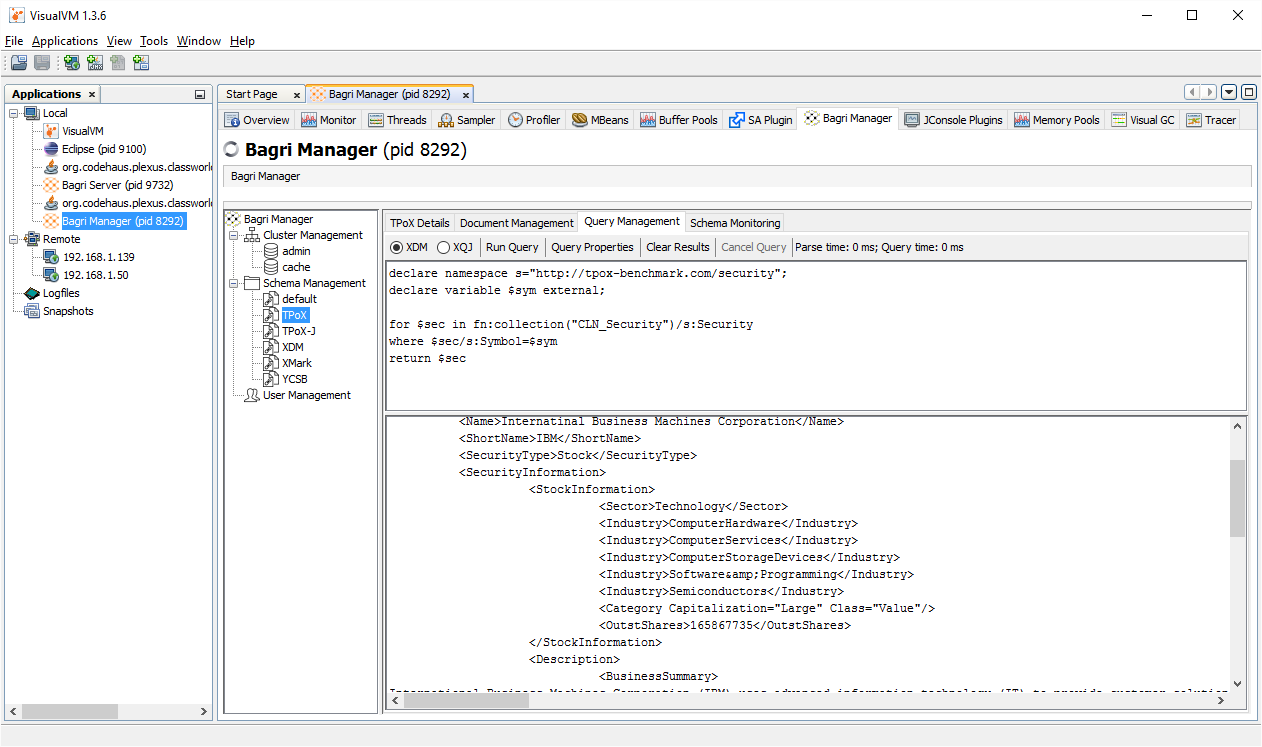
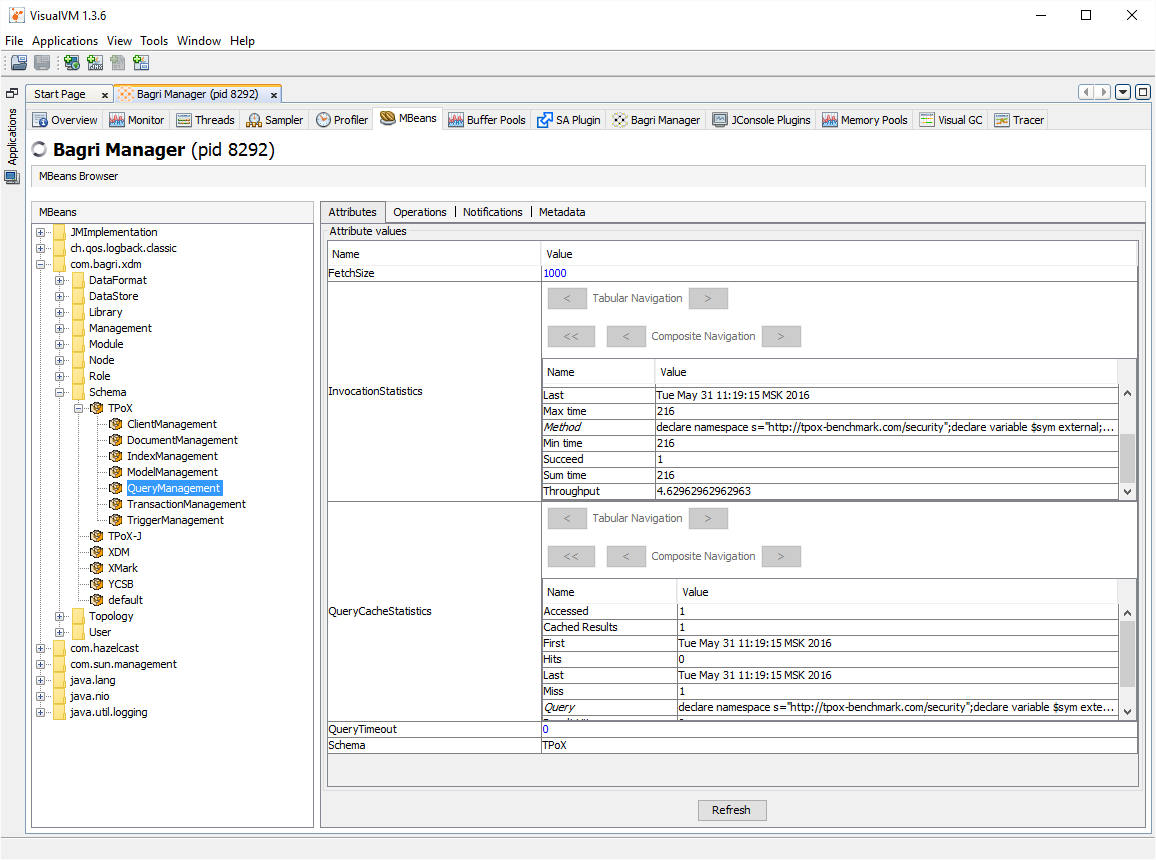
At present, Bagri’s visual administrative interface is implemented as a VisualVM plugin and allows you to:
This module is still under active development, the functionality of the plugin is constantly increasing. In the case of errors, as well as in the case of proposals for the missing functionality, they can always (and need!) Put in the issues of the project.
Screenshots of the administrative console - see below.
So, we have considered the most basic capabilities of the distributed database of documents Bagri. We hope that you are interested in this project and you will try to use it in your daily work.
For my part, I will soon try to write for you some more articles on how Bagri compares with other similar products, such as BaseX, MongoDB, Cassandra, and system expansion options by using the built-in API (DataFormat API and DataStore API).
Bagri, like any other open source project, requires Java developers interested in this topic, so if after reading this article you are interested in the project, welcome to Githab Bagri , there are many really interesting tasks.
When it makes sense to use bagri
The system is good to use in the first place in cases where the workflow is based on XML. These are finance, logistics, insurance, medicine, and other industries where the format of documents exchanged between participants is strictly defined by corporate XSD schemes. The system allows you not to parse each incoming document, but put it into the database as it is, and then efficiently perform any queries on stored documents using the powerful XQuery 3.1 toolkit.
')
Bagri is built on top of products that implement distributed cache, such as Hazelcast, Coherence, Infinispan, and other similar systems. It is due to the capabilities of the distributed cache that Bagri supports the requirements of the corporate sector right out of the box. The distributed cache is used by the system not only as a data warehouse, but also as a distributed system for processing this data, which allows you to efficiently and quickly process any large amounts of weakly structured data. Transactional in the system is solved using an algorithm that implements multi-version concurrency control
The data in the system are supplied as XML or JSON documents. There is also the opportunity to implement its extension to Bagri and register the plugin to work with new document formats, as well as with external document storage systems. The auxiliary project bagri-extensions contains extensions developed by the team (a connector to MongoDB is currently implemented).
XQuery is used as the query language, in the future it is also planned to support SQL syntax, this task is available in the project Github.
Bagri does not require prior knowledge of the data schema, but forms a data dictionary (unique paths in document structures) “on the fly” while parsing incoming documents. So Bagri is completely schemaless and does not need rebuilding tables for new document types, i.e. he does not need create table / add column commands in principle.
For communication between the client and the server, Bagri offers two APIs: the standard XQJ API declared in JSR 225 and its own XDM API, providing additional functionality that is missing in XQJ. In fact, XQJ interfaces are analogous to the functionality provided by the JDBC driver when working with relational databases. Together with the XQJ driver, the system comes with the official XQJ TCK, which you can run and make sure that the driver passes all XQJ tests 100%.
How distributed cache functionality is used in Bagri
All documents in Bagri are stored in schemas, the closest analogue in a relational database (RDBMS) is database. Currently, Hazelcast is used as the distributed cache on which the system is built, and a separate Hazelcast cluster is allocated for each scheme. Schemes exist independently of each other, i.e. there is no “struggle” for resources between the schemes (in the Hazelcast each cluster is configured separately and has its own pool of resources).
Meta document data (namespaces, document types, unique paths) are stored in the corresponding caches and replicated between all nodes in the cluster. So Access to working nodes to read metadata is as fast as possible. The data of the documents themselves are separated from the metadata and stored in distributed caches, while the data relating to the same document is always stored on the same node. There are also caches for storing indexed values, for compiled queries, for the transaction log, and of course for the results of executed queries.
Bagri client connects to the server using internal cache client software mechanisms. XQuery requests on the client are packed into tasks and executed on server nodes via the distributed ExecutorService provided by the Hazelcast platform.
Results are returned to the client through a dedicated asynchronous channel (Hazelcast queue)
System configuration
The entire system configuration is stored in two files: access.xml for settings of roles and users, and config.xml with settings for schemes and extensions Bagri. A detailed description of the format of these files and all the parameters used in them can be found in the installation and configuration instructions of the system . You can change schema settings directly in files, or through the JMX schema management interfaces deployed on the Bagri administration server.
Examples of working with data
Let's now move from theory to practice and consider how we can work with Bagri from our Java code through XQJ interfaces.
Inside the context of the spring, we declare the BagriXQDataSource bin and configure its four main parameters: the address of the remote server, the name of the scheme, the user name and password.
<bean id="xqDataSource" class="com.bagri.xqj.BagriXQDataSource"> <property name="properties"> <props> <prop key="address">${schema.address}</prop> <prop key="schema">${schema.name}</prop> <prop key="user">${schema.user}</prop> <prop key="password">${schema.password}</prop> </props> </property> </bean> <bean id="xqConnection" factory-bean="xqDataSource" factory-method="getConnection“/> Get the XQJ connection:
context = new ClassPathXmlApplicationContext("spring/xqj-client-context.xml"); XQConnection xqc = context.getBean(XQConnection.class); Then we read the text file and on the basis of it we create a new document in Bagri:
String content = readTextFile(fileName); String query = "declare namespace bgdm=\"http://bagridb.com/bagri-xdm\";\n" + "declare variable $uri external;\n" + "declare variable $content external;\n" + "declare variable $props external;\n" + "let $id := bgdm:store-document($uri, $content, $props)\n" + "return $id\n"; XQPreparedExpression xqpe = xqc.prepareExpression(query); xqpe.bindString(new QName("uri"), fileName, xqc.createAtomicType(XQBASETYPE_ANYURI)); xqpe.bindString(new QName("content"), content, xqc.createAtomicType(XQBASETYPE_STRING)); List<String> props = new ArrayList<>(2); props.add(“xdm.document.data.format=xml"); //can be “json” or something else.. xqpe.bindSequence(new QName("props"), xqConn.createSequence(props.iterator())); XQSequence xqs = xqpe.executeQuery(); xqs.next(); long id = xqs.getLong(); The request above calls the store-document external function defined in the bgdm namespace. The function accepts 3 parameters as input: uri, under which the document will be saved, the text content of the document and an optional set of options that define additional parameters for the function of saving the document. The request is validated on the client side and then sent to the server along with the parameters.
On the server side, a unique identifier is assigned to the incoming document. Further, the contents of the document are parsed in accordance with the specified document format and divided into path / value pairs, while all unique paths are stored in the replicated directory of document paths. At the end of the parsing procedure, the entire contents of the document, divided into such pairs, is stored in the distributed caches of the system, and the document header with service information is also cached. If indexes are registered in the schema, all indexed values are also stored in the index cache. The confirmation of the successful saving of the document is transmitted back to the client side.
After we have successfully saved our document in Bagri, let's look at how we can make requests to documents stored in the system.
Get the XQJ connection:
XQConnection xqc = context.getBean(XQConnection.class); Prepare an XQuery query:
String query = "declare namespace s=\"http://tpox-benchmark.com/security\";\n" + "declare variable $sym external;\n" + "for $sec in fn:collection(\“securities\")/s:Security\n" + "where $sec/s:Symbol=$sym\n" + "return $sec\n"; XQPreparedExpression xqpe = xqc.prepareExpression(query); Set the value of the search parameter:
xqpe.bindString(new QName("sym"), “IBM”, null); Execute the request on the server:
XQResultSequence xqs = xqpe.executeQuery(); And review the results:
while (xqs.next()) { System.out.println(xqs.getItemAsString(null)); } I think it will be just as interesting to talk about what happens on the server when executing this code:
The query passes through the XQuery processor (currently Saxon ), in which the query execution tree (compiled query, XQueryExpression) is formed. Then it is translated into a set of simple queries to the cached data along the specified paths:
[PathExpression [path=/ns2:Security/ns2:Symbol/text(), param=var0, docType=2, compType=EQ]], params={var0=IBM} These simple queries are executed in parallel on all nodes of the distributed system cache. Found documents are delivered to the processor for further processing. Indexes are used whenever possible if the requested paths have been indexed. After final processing of the received documents by the processor, the results are transmitted back to the client through a dedicated asynchronous channel.
System expansion options
Bagri provides rich opportunities to expand the behavior of the system. For example, you can connect a trigger to any document status changes (before / after insert / update / delete) and execute additional business logic at these points. To do this, it is enough to implement the interface com.bagri.xdm.cache.api.DocumentTrigger, as shown in one of the examples supplied with the system (see samples / bagri-samples-ext):
public class SampleTrigger implements DocumentTrigger { private static final transient Logger logger = LoggerFactory.getLogger(SampleTrigger.class); public void beforeInsert(Document doc, SchemaRepository repo) { logger.trace("beforeInsert; doc: {}; repo: {}", doc, repo); } public void afterInsert(Document doc, SchemaRepository repo) { logger.trace("afterInsert; doc: {}; repo: {}", doc, repo); } public void beforeUpdate(Document doc, SchemaRepository repo) { logger.trace("beforeUpdate; doc: {}; repo: {}", doc, repo); } public void afterUpdate(Document doc, SchemaRepository repo) { logger.trace("afterUpdate; doc: {}; repo: {}", doc, repo); } public void beforeDelete(Document doc, SchemaRepository repo) { logger.trace("beforeDelete; doc: {}; repo: {}", doc, repo); } public void afterDelete(Document doc, SchemaRepository repo) { logger.trace("afterDelete; doc: {}; repo: {}", doc, repo); } } And then register the trigger in the schema in the config.xml file:
<schema name="sample" active="true"> <version>1</version> <createdAt>2016-09-01T15:00:58.096+04:00</createdAt> <createdBy>admin</createdBy> <description>sample schema</description> <properties> ……… </properties> <collections/> <fragments/> <indexes/> <triggers> <trigger xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ns2:javatrigger"> <version>1</version> <createdAt>2016-09-01T15:00:58.096+04:00</createdAt> <createdBy>admin</createdBy> <docType>/{http://tpox-benchmark.com/security}Security</docType> <synchronous>false</synchronous> <enabled>true</enabled> <index>1</index> <actions> <action order="after" scope="delete"/> <action order="before" scope="insert"/> </actions> <library>trigger_library</library> <className>com.bagri.samples.ext.SampleTrigger</className> </trigger> </triggers> </schema> </schemas> <libraries> <library name="trigger_library"> <version>1</version> <createdAt>2016-09-01T15:00:58.096+04:00</createdAt> <createdBy>admin</createdBy> <fileName>bagri-samples-ext-1.0.0-EA1.jar</fileName> <description>Sample extension trigger Library</description> <enabled>true</enabled> <functions/> </library> </libraries> As shown above, we registered the library (bagri-samples-ext-1.0.0-EA1.jar) containing the trigger implementation. Libraries can also contain additional functions written in Java that can be called from XQuery queries, as well as extensions for processing new data formats or connecting to external document storage systems.
System Deployment Options
Bagri can be deployed in the following ways:
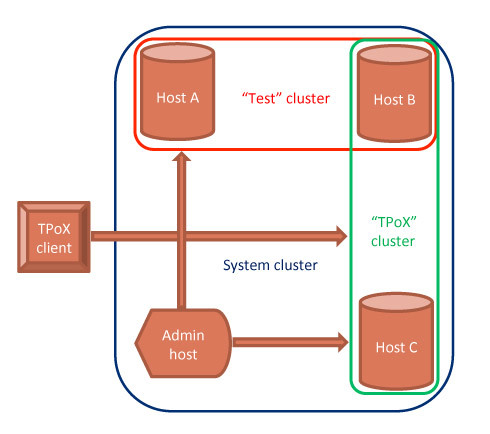
- Standalone Java app - suitable for small applications that need to handle a limited set of data. Everything works within one JVM with one schema, providing maximum performance on limited (by memory of one JVM) data volumes.
- Client-server, distributed database — clients communicate with the distributed storage system via the XDM / XQJ driver. Distributed processing of requests in memory, the possibility of on-line processing of an unlimited amount of data
- Administration server - provides additional functionality for collecting statistics and monitoring the status of system work nodes. Usually it is deployed as a separate node, but this is not a required component, the system can work without it.
Visual administrative interface
At present, Bagri’s visual administrative interface is implemented as a VisualVM plugin and allows you to:
- configure users and roles
- connect external libraries of Java functions and XQuery add-ons for use in queries
- configure schemas and their components: collections, metadata dictionaries, indexes and triggers, user and role access to schemas
- visually view documents and collections
- perform XQuery queries and get results through the built-in console
This module is still under active development, the functionality of the plugin is constantly increasing. In the case of errors, as well as in the case of proposals for the missing functionality, they can always (and need!) Put in the issues of the project.
Screenshots of the administrative console - see below.
So, we have considered the most basic capabilities of the distributed database of documents Bagri. We hope that you are interested in this project and you will try to use it in your daily work.
For my part, I will soon try to write for you some more articles on how Bagri compares with other similar products, such as BaseX, MongoDB, Cassandra, and system expansion options by using the built-in API (DataFormat API and DataStore API).
Bagri, like any other open source project, requires Java developers interested in this topic, so if after reading this article you are interested in the project, welcome to Githab Bagri , there are many really interesting tasks.
Source: https://habr.com/ru/post/310110/
All Articles