WaveNet: a new model for generating human speech and music
 Our cloud platform Voximplant is not only telephone and video calls. It is also a set of "batteries", which we are constantly improving and expanding. One of the most popular features: the ability to synthesize speech by simply calling the JavaScript say method during a call. Developing your own speech synthesizer - for the best idea, we still specialize in a telecom backend written in pluses and capable of processing thousands of simultaneous calls and supplying each of them with JavaScript logic in real time. We use partner solutions and closely monitor everything new in the industry. I would like to move away from the “Iron Woman” meme in a few years :) An article, an adapted translation of which we made this weekend, talks about WaveNet, a model for generating sound (sound waves). In it, we look at how WaveNet can generate speech that is similar to the voice of any person, and also sounds much more natural than any existing Text-to-Speech system, improving the quality by more than 50%.
Our cloud platform Voximplant is not only telephone and video calls. It is also a set of "batteries", which we are constantly improving and expanding. One of the most popular features: the ability to synthesize speech by simply calling the JavaScript say method during a call. Developing your own speech synthesizer - for the best idea, we still specialize in a telecom backend written in pluses and capable of processing thousands of simultaneous calls and supplying each of them with JavaScript logic in real time. We use partner solutions and closely monitor everything new in the industry. I would like to move away from the “Iron Woman” meme in a few years :) An article, an adapted translation of which we made this weekend, talks about WaveNet, a model for generating sound (sound waves). In it, we look at how WaveNet can generate speech that is similar to the voice of any person, and also sounds much more natural than any existing Text-to-Speech system, improving the quality by more than 50%.We will also demonstrate that the same network can be used to create other sounds, including music, and show some automatically generated examples of musical compositions (pianos).
Talking machines
Allowing people and cars to communicate in a voice is people's long-held dream of interaction between them. The ability of computers to understand human speech has improved significantly over the past few years thanks to the use of deep neural networks (a good example is Google Voice Search ). However, speech generation - a process commonly referred to as speech synthesis or text-to-speech (TTS) - is still based on the use of so-called concatenative TTS . It uses a large database of short fragments of speech recorded by one person. The fragments are then combined to form phrases. With this approach, it is difficult to modify the voice without recording a new database: for example, change to the voice of another person, or add an emotional coloring.
This has led to a large demand for parametric TTS, where all the information needed to create speech is stored in the model parameters and the nature of speech can be controlled through the model settings. However, the parametric TTS still doesn’t sound as natural as the concatenative option, at least in the case of languages like English. Existing parametric models usually generate sound, driving the output signal through special handlers, called vocoders .
')
WaveNet changes the paradigm by generating a sound signal by sample. This not only leads to a more natural sound of speech, but also allows you to create any sounds, including music.
WaveNets
Usually, researchers avoid modeling audio samples, because they need to be generated a lot: up to 16,000 samples per second or more, of a strictly defined form on any time scale. Building an autoregressive model in which each sample depends on all previous samples is not an easy task.
Nevertheless, our models PixelRNN and PixelCNN , published earlier this year, showed that it is possible to generate complex natural images not only one pixel at a time, but also one color channel at a time, which requires thousands of image predictions. This inspired us to adapt 2-dimensional PixelNets to the one-dimensional WaveNet.

The animation above shows the WaveNet device. This is a convolutional neural network , where the layers have different dilatation factors and allow its receptive field to grow exponentially with depth and cover thousands of time segments.
During training, incoming sequences are sound waves from voice recording examples. After training, you can use the network to generate synthetic phrases. At each sampling step, the value is calculated from the probability distribution calculated by the network. This value is then returned to the input and a new prediction is made for the next step. Creating samples in this way is quite a resource-intensive task, but we found that it is necessary to generate complex, realistic sounds.
Improving the State of the Art
We trained WaveNet using Google TTS datasets, so we were able to evaluate the quality of its work. The following graphs show the quality on a scale from 1 to 5 in comparison with the best TTS from Google (parametric and concatenative) and in comparison with the real speech of a living person, using MOS (Mean Opinion Scores). MOS is a standard way to do subjective tests of sound quality, 100 sentences were used in the test and 500 more grades were collected. As we can see, WaveNets significantly reduced the gap between the quality of synthesized and real speech for English and Chinese (the difference from previous synthesis methods is more than 50%).
For both Chinese and English, Google’s current TTS is considered one of the best in the world, so such a significant improvement for both languages with one model is a great achievement.
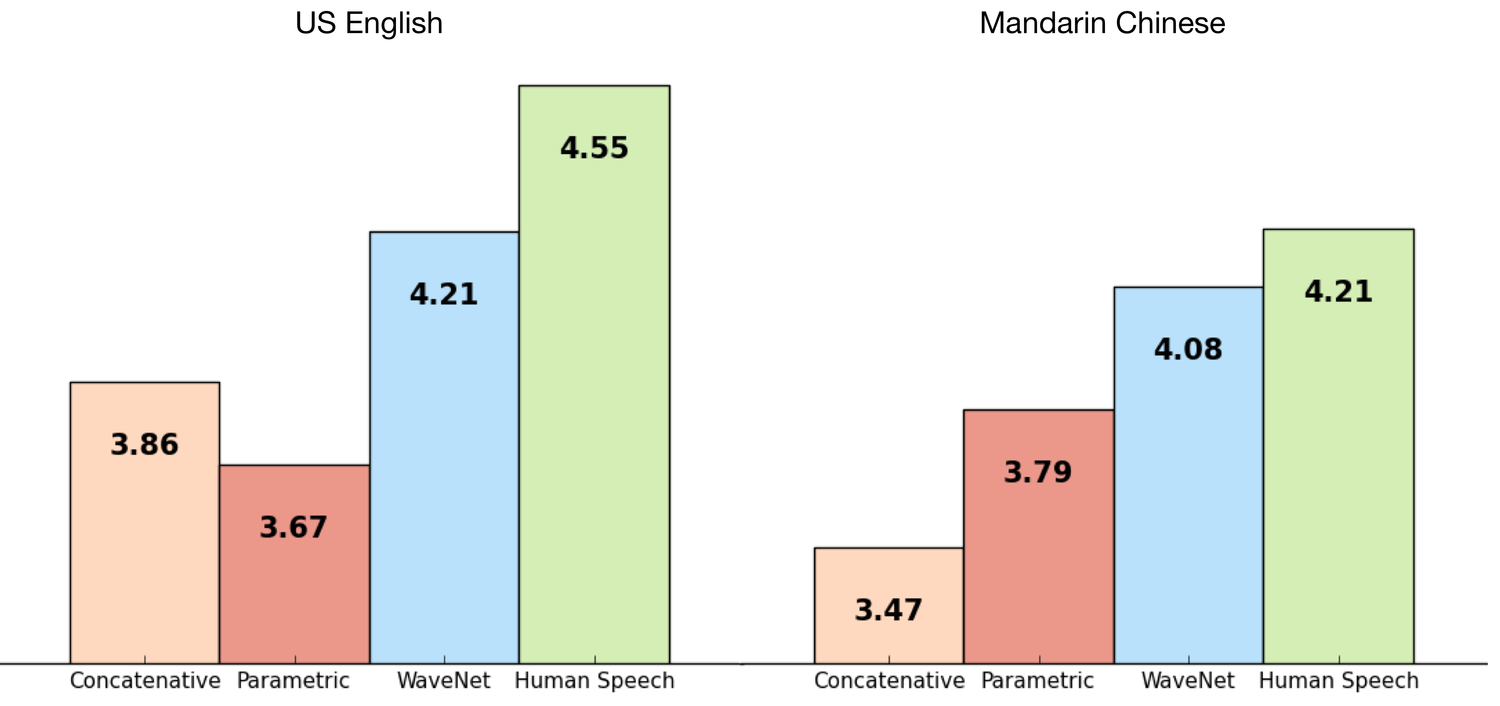
Here are a few examples so you can listen and compare:
English (US English)
Parametric
Example №1
Example 2
Concatenative
Example №1
Example 2
WaveNet
Example №1
Example 2
Mandarin Chinese
Parametric
Example №1
Example 2
Concatenative
Example №1
Example 2
WaveNet
Example №1
Example 2
Understand what to say
To use WaveNet for text-to-speech, you need to clarify what the text is. We do this by transforming the text into a sequence of linguistic and phonetic characteristics (each contains information about the current phoneme, syllable, word, etc.) and send them to WaveNet. This means that network predictions depend not only on previous audio samples, but also on the text that we want to convert to speech.
If we train the network without textual data, it will still be able to generate speech, but in this case, it will need to come up with something to say. As can be seen from the examples below, this leads to some similarity of chatter, in which real words are interspersed with generated sounds similar to words:
Example №1
Example 2
Example number 3
Example 4
Example number 5
Example 6
Notice that sounds that are not speech, such as breathing and mouth movements, are also occasionally generated by WaveNet; This shows the greater flexibility of the model for generating audio data.
Also, as you can see from these examples, one WaveNet network is able to study the characteristics of different voices, male and female. To give her the opportunity to choose the right voice for each statement, we set the condition for the network to use the identity of the person speaking. What is even more interesting, we found that training in many different speaking people improves the quality of modeling for one specific voice, compared to training only with the voice of this one person, which implies some form of knowledge transfer during training.
By changing the personality of the speaker, we can make the network say the same things with different voices:
Example №1
Example 2
Example number 3
Example 4
Similarly, we can transmit additional information to the model input, for example, about emotions or accents to make speech even more diverse and interesting.
Music Creation
Since WaveNets can be used to simulate any audio, we decided that it would be interesting to try generating music. Unlike the scenario with TTS, we did not configure the network to play something specific (by notes), we, on the contrary, made it possible for the network to generate what it wants. After training the network on the input from classical piano music, she created several charming pieces:
Example №1
Example 2
Example number 3
Example 4
Example number 5
Example 6
WaveNets offer many new features for TTS, automatic music creation and audio modeling in general. The fact that the approach to creating 16KHz audio using step-by-step creation of samples using a neural network in general works already amazing, but it turned out that this approach allowed achieving the result of surpassing the most advanced modern TTS systems. We are enthusiastic about other possible uses.
For more detailed information we recommend reading our written work on this topic.
Picture to attract attention taken from the movie Ex Machina
Source: https://habr.com/ru/post/309648/
All Articles