Reverse engineering of visual stories (part 2)
 We continue our series of articles about how to get into the insides of game engines and pull out all sorts of content from them. For those who have just joined us, let me briefly remind you that we have studied such a funny genre as visual novels.
We continue our series of articles about how to get into the insides of game engines and pull out all sorts of content from them. For those who have just joined us, let me briefly remind you that we have studied such a funny genre as visual novels.
Much time has passed since we learned how to parse the archives of the Yuka visual novel engine , it is time to take on the most interesting thing that we found there - the script itself. Running a little ahead, I’ll warn you right away that the script is, of course, much more complicated matter than just an archive with files, so we don’t understand it in one article, but today we will try to understand what parts it consists of and get access to text resources.
Before diving into the depths of binary dumps, let's estimate how most of the visual novel engines work. A visual novel in itself consists of text (heroes' replicas, dialogues, intermediate narration), graphics and sounds. In order to reproduce it to the user, it is clearly necessary to bring it all together with the help of some kind of control action. In theory, it would be possible to sew it all directly into an exe-file, but in 99% of cases (okay, I'm lying, I’m not 100% seen by me personally), but they still do not store such instructions separately as a separate script program. As a rule, the script is written in a special programming language (specific to the engine), which looks something like this:
$ tarot = 0 $ memory = 0 scene bg01_1 with dissolve play music "bgm/8.mp3" fadein (2.0) play ambience "amb/forest.mp3" fadein (3.0) "Morning." "Not my favourite time of the day." "The morning is when you're not awake enough to do anything..." This is a fragment of the script source from one VN to Ren'Py - one of the most popular free / free engines. Leaving beyond the scope of this article, the question of how good Ren'Py is in itself is, for the time being, just note what is usually included in the script of the visual novel and what we will need to find:
- the text - it is still either not assigned to any character (ie, the text "from the narrator" - as in our example), or it is pronounced by someone
- commands to show graphics - background / sprite (
scene bg01_1), sometimes with some special effect (with dissolve) - commands to start playing music or sounds (
play music,play ambience), sometimes also with some additional parameters, most often lengths of fade-in and fade-out (smoothly increasing volume) - working with variables: setting (
$ tarot = 0, check, branch) there are still commands:
- for reproduction of the speech made by heroes
- for management
- service things like comments, tags, macros
Of course, in the real world, we often will not have access to the source code of the script. People have already learned how to write compilers for 50 years (as opposed to interpreters), so usually the script source code is compiled into some binary code (byte code), which is then executed by the virtual machine inside the visual novel engine. Sometimes lucky and for some popular engines there are legally or not so legally available tools - debuggers, compilers, decompilers, script validators, etc., but more often life is not so simple.
So, back to our visual novel, which we began to explore in the last article - Koisuru Shimai no Rokujuso . We have already unpacked its archives and found inside both graphics, and sounds, and music, and, most importantly and incomprehensible so far - a handful of files with the extension .yks. Presumably, they constitute the script novels. By the way, there are a lot of files:
YKS/ScriptStart.yks YKS/trial/Yoyaku.yks YKS/trial/trial_00100.yks YKS/trial/trial_00200.yks YKS/all/all_00010.yks ... YKS/all/all_02320.yks Total 103 files in YKS / all /. Let me remind you, we absolutely honestly downloaded and investigated the trial version - but, apparently, the developers were a bit lazy and, apparently, in the trial / lies the script for the trial version, and in all / - for the full one.
Generally, based on the minimum experience, the builders of the visual story engines have 2 approaches: either everything is packaged in one giant file, or there are many files and each has its own scene or event. Here it seems that the second. In addition, there is still a separate ScriptStart.yks - but as such it will most likely be practically uninteresting to us: the fact is that developers often want to make the engine as versatile as possible and implement all sorts of user interfaces, load-save menus, and more .d also using your own scripting language. It is possible to deal with this, but rather boring and unproductive: therefore, I suggest taking the bull by the horns and starting with the actual game scenario.
What can we say from the surface visual inspection? First, because Since the game runs under Windows, it’s quite realistic to run it and see how it looks. We spend the n-th amount of time, we find the Windows machine, we start, we see what happens immediately after pressing the button to start the new game:

We seem to meet the beginning of the story. Here is the background (after a brief search in BG / there is a file bg01_01.png with this background), and there is text. We still need this text, so it is worth rewriting it from the screen:
恋する姉妹の六重奏「セクステット」体験版Ver2をダウンロード頂きありがとうございます。 Two notes:
If there are problems with typing Japanese text, I can recommend to learn three or four techniques that greatly simplify this matter and with a certain patience give the opportunity to type Japanese texts to those who absolutely have no idea what kind of squiggles are. Each icon is viewed separately:
- check whether this is a punctuation mark on the following table: 「...」 、 ()。 - if we are lucky, then copy; Pay attention to the fact that "commas", and "points", and the brackets here are specific.
- if not, look in this table: あ い う え お か き く け こ さ し す せ そ た ち つ て と な に ぬ ね ろ は ひ め も わ ゆ ゆ よ り る を れ ま ま み む め も
- Then we look for this: イ ウ エ オ カ キ ク コ サ シ ス セ ソ タ チ ツ テ ト ナ ニ ヌ ネ ノ ハ ヒ フ ヘ ホ マ ミ ム メ メ モ ヤ ユ ワ ワ ホ マ ミ ミ
- if it didn't help - for example, got caught 恋 - then this is kanji; then we increase the font by 300-500% so that all the fine details can be clearly seen and go to jisho.org in the "search by radicals" section ; there we look at the table of constituent parts (radicals) and look for similar ones to what we see; using as an example - after a short meditation we find that it has an integral part of it from below - we hold down the button with this component and from many thousands we have only a couple of dozen icons; we look through their eyes and find the fifth sign from the beginning in the section "10" - this will be the required.
- I'm not sure if there will be Ver2 or Ver2 there - note, these are not different fonts, but suddenly so-called full-width characters - in Unicode they are somewhere in the U + FF01..U + FF5E region).
We will need the text for two things. First, actually, as a text, understand what is happening (even if you don’t speak Japanese, you can insert it into Google translator and understand that we are thanked here for downloading the trial version of this game => i.e. this is not a real start plot, and a kind of introduction, "from the author"). Secondly, we can take this text or a piece of it, convert it to ShiftJIS (and most likely, as we found out in the previous article, everything will be exactly in this encoding) and search it in files. Take a piece from the end and prepare what we look for:
$ echo 'ダウンロード頂きありがとうございます' | iconv -t sjis | hd 00000000 83 5f 83 45 83 93 83 8d 81 5b 83 68 92 b8 82 ab |._.E.....[.h....| 00000010 82 a0 82 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2 |................| 00000020 82 dc 82 b7 |....| We are looking for this line in all our .yks files and, of course, we do not find it. Not so simple.
Let us make another lyrical digression: let's take a look at how ShiftJIS encoding works. In Japanese, obviously, there are much more icons than in European ones: in ShiftJIS, each of the icons is encoded with at least 1 byte, at most 2. As can be seen from this label, the values of bytes 00..7F coincide with ASCII, but bytes 81..9F and E0..EA means that this is a two-byte combination, and again for compatibility with binary reading, the second byte will not have any desired value , but something between 40 and FF.
Microexcursion into Japanese: 3 groups of icons are used in the language:
- hiragana - it looks something like this: あ り が と う ご ざ い ま す - i.e. rounded simple written forms; ~ 50 icons, but there are all sorts of variations like "big i = い, small i = ぃ"; 1 syllable = 1 character.
- katakana - it looks something like this: ダ ウ ン ロ ー ド - i.e. chopped square, simple printing plates; the sounds are about the same as hiragana, but used to write mostly borrowed words (ダ ウ ン ロ ー ド = da-un-lo: -do = download).
- kanji - look something like this: 体 験 版 - i.e. as a rule, complex square structures from a heap of different parts and nooks; with them the hardest thing, here are just many thousands of them.
Plus, there are still punctuation marks, plus or minus are the same as in European languages: dot, comma, ellipsis … , quotes 「」 , exclamation and question marks, etc. But there are usually no gaps. The trick is that the text constantly alternates "important" words that are written kanji and particles that are written hiragana, as a result of which this mixture is obtained can be somehow disassembled. For example, take the name of the game 恋 す る 姉妹 の 六 重奏:
- 恋 - kanji
- す る - hiragana
- 姉妹 - kanji
- の - hiragana
- 六 重奏 - kanji
What does this give us in the dry residue? Very simple: frequency table. We take the ready-made script of the first visual novel in Japanese that we’ve got, and we quickly look at the boundaries of the ranges of all three groups in Unicode and run such a script on it (sorry for the pun):
stats = {} $stdin.each_char { |c| t = case c.ord when 0x3041..0x309F then :hiragana when 0x30A0..0x30FF then :katakana when 0x4E00..0x9FCC then :kanji end stats[t] ||= 0 stats[t] += 1 } p stats and we get something like:
{nil=>72384, :kanji=>5731, :hiragana=>15377, :katakana=>2241} those. in a typical text, it would be ~ 25% kanji, 65% hiragana and 10% katakana.
It seems time to uncover the tools and dive headlong into the work. Let me briefly remind you that we use the new open source tool Kaitai Struct for analyzing binary files with an incomprehensible structure - it allows you to describe templates in the markup language, which you can then apply to the files and quickly visualize their contents, arranged in the form of a tree, and as a mega-bonus then - compile a template directly into the source in virtually any popular programming language (since the previous article, Kaitai Struct began to support not only Java, JavaScript, Python and Ruby, but also C ++, C #, Perl and PHP). That is, if you look at all the lists of top-languages - the top 10 is covered completely, from top 20, if you don’t take domain-specific things, you don’t have enough Delphi, Visual Basic (although I’m little one to imagine someone to do reverse engineering on Old Visual Basic is not .NET), Swift and Go.
We studied the basic syntax of Kaitai Struct templates in the first part of the article, therefore, who missed / forgot about what it was about - it 's time to familiarize yourself with / refresh it in memory .
So, we quickly look at the dumps of 3-4 files and we understand that as a starting point we can use this pattern:
meta: id: yks application: Yuka Engine endian: le seq: - id: magic contents: ["YKS001", 1, 0] - id: magic2 contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0] - id: unknown1 type: u4 - id: unknown2 type: u4 - id: unknown3 type: u4 - id: unknown4 type: u4 - id: unknown5 type: u4 - id: unknown6 type: u4 - id: unknown7 type: u4 You can immediately draw an analogy with the format YKC. Since there at the beginning there was a description of the "header", starting from its length, then most likely the fixed 0x30 found in magic2 everywhere is the length of the original header, so I suggest reading all to 0x30 at once. It turns out 7 numbers, now it will try to guess what it is.
For Yoyaku.yks (the file itself is 27741 bytes):
[.] @unknown1 = 1845 [.] @unknown2 = 7428 [.] @unknown3 = 795 [.] @unknown4 = 20148 [.] @unknown5 = 7593 [.] @unknown6 = 25 [.] @unknown7 = 0 For trial_00100.yks (file 91267 bytes):
[.] @unknown1 = 6433 [.] @unknown2 = 25780 [.] @unknown3 = 2376 [.] @unknown4 = 63796 [.] @unknown5 = 27471 [.] @unknown6 = 5 [.] @unknown7 = 0 And, for comparison, any file from all, for example all_00010.yks (12968 bytes):
[.] @unknown1 = 933 [.] @unknown2 = 3780 [.] @unknown3 = 353 [.] @unknown4 = 9428 [.] @unknown5 = 3540 [.] @unknown6 = 1 [.] @unknown7 = 0 What is visible? First, it’s all epic like shifts or sizes in a file, because with a file size of 91K, the numbers float around 25-63K, and when the size of 12K is around 3-9K. On closer inspection, offsets and sizes are most likely just unknown2, unknown4, unknown5 - they are divided into 4 and fairly large. Secondly, unknown7 seems to always be 0. Thirdly, unknown6 seems to be asking for something very piece-like. This may be, for example, the size of the virtual machine's reserved memory space for variables, the number of changing scenes / sprites / backgrounds or something else.
Immediately after 0x30, even with the naked eye, a table of increasing (or almost always increasing numbers) is visible in the human hex editor. It is unlikely that the byte code itself: for a byte code is characterized by just a constant repetition of the same sequences. This is also most likely some offsets - for example, it can be offsets that determine the beginnings of commands in bytecode, or some beginnings-ends of lines of variable length or something else. We have 7 unknown values, this is not so much - let's look and see if one of them looks like:
- either the length of this section
- or the absolute offset of the end of this section = the beginning of a new
- or on the number of 4-byte integers in the region
Almost the very first attempt fits very well: unknown1 turns out to be the number of elements in this section, and unknown2 turns out to be a pointer to the beginning of the next section. And, thus, it seems that in practice unknown2 = 0x30 + unknown1 * 4. Add the description immediately, at the same time transferring the header to the explicitly selected type header, and starting to open the sections we call sect1..sectX:
seq: - id: header type: header - id: sect1 size: header.sect2_ofs - 0x30 type: sect1 types: header: seq: - id: magic contents: ["YKS001", 1, 0] - id: magic2 contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0] - id: sect1_qty type: u4 - id: sect2_ofs type: u4 - id: unknown3 type: u4 - id: unknown4 type: u4 - id: unknown5 type: u4 - id: unknown6 type: u4 - id: unknown7 type: u4 sect1: seq: - id: entries type: u4 repeat: expr repeat-expr: _root.header.sect1_qty As a result, trial_00100 begins to look like this:
[-] @header [.] @magic = 59 4b 53 30 30 31 01 00 [.] @magic2 = 30 00 00 00 00 00 00 00 30 00 00 00 [.] @sect1_qty = 6433 [.] @sect2_ofs = 25780 [.] @unknown3 = 2376 [.] @unknown4 = 63796 [.] @unknown5 = 27471 [.] @unknown6 = 5 [.] @unknown7 = 0 [-] @sect1 [-] @entries (6433 = 0x1921 entries) [.] 0 = 6 [.] 1 = 7 [.] 2 = 3 [.] 3 = 3 [.] 4 = 4 ... [.] 6425 = 2371 [.] 6426 = 2372 [.] 6427 = 34 [.] 6428 = 1 [.] 6429 = 2373 [.] 6430 = 2374 [.] 6431 = 1 [.] 6432 = 2375 In fact, now it is already noticeable that these are not just increasing values — this may well be a bytecode. In this file, noticeable increasing numbers apparently go from 0 or 1 and eventually increase to 2375. Suddenly, unknown3 = 2376 is very similar to the number of these very values. Those. bytecode refers to another table of some kind, in which there are 2376 different values (apparently, from 0 to 2375 inclusive). What could it be?
We look at the next section, looking at what happens on the screen 3-4 ahead:

In my opinion, it is more or less obvious that these are 16-byte records (1 line) in length, and there is again something strikingly similar to the clearly constantly unevenly increasing displacements or indices. Will such records be 2376? Check, rename unknown3 to sect2_qty and add a trivial piece to assemble sect2 from 16-byte records:
- id: sect2 size: 16 repeat: expr repeat-expr: header.sect2_qty and, it seems, bingo, this is it very precisely:

It is clearly visible to the naked eye that these slender 16-byte entries really end exactly after the sect2_qty pieces and then something completely different begins. What do we see here? These are clearly not long 4-byte numbers, just about all non-zero. Some obviously periodic structure is also not visible, at least at first glance. Abundance 0xaa. Many 0x28, alternating through time. We look at the end of the file, trying to find some more sections - it seems, no, at the end there is approximately the same texture:
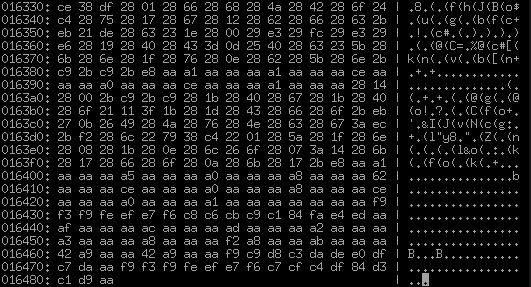
That is, this is the third and last section of the file, nothing else will be in it. And what we have not seen? Text and lines. Apparently, this is what they are, but obviously somehow encoded. Compressed? No, it doesn't. There would be no such number of repeating 0x28 and 0xaa. Yes, and repeating 0x28 in everyones there 28 08 28 1b 28 0e 28 6c 26 6f 28 07 3a 14 28 6b look terribly suspicious. For comparison, let us recall what the average Japanese text looks like in ShiftJIS: 82 a0 82 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2 . Immediately, the hypothesis suggests itself that this is the simplest substitution cipher, where each byte is always converted to the same other byte. What can it be, how to get from 0x82 => 0x28? Humanity has not really come up with so many options:
- addition / subtraction - add (or subtract the same) to each byte the same number, overflow simply does not take into account
- rol / ror - cyclic shift for some number of bits, in the most stupid variant, shift by 4 bits to the right or left changes 2 hexadecimal digits
- exclusive "or" (xor) - with each byte, perform the operation xor with some other fixed byte; one of the most stupid, banal, somehow acting and therefore popular ways
In general, there is even "heavy" artillery in the form of programs like XORSearch , which try to guess such transformations by brute force, but here it is still more banal and I manage to guess the second time. The abundance of 0xaa suggests that there are a lot of zeros, which are XORs with 0xaa, which gives 0xaa. And suddenly 0x82 ^ 0xaa is just equal to 0x28. 0xaa is generally one of the most banal assumptions that should be checked for good in the first place, because 0xaa = 0b10101010, i.e. xor with him stupidly turns every second bit.
Fortunately, Kaitai Struct has built-in support for such transformations, activated through process: Enough to write like this:
- id: sect3 size-eos: true process: xor(0xaa) after which we will finally be able to observe the rich inner world of the string constants of our client scripts:
000000: 69 66 00 c8 00 00 00 47 6c 6f 62 61 6c 46 6c 61 | if.....GlobalFla 000010: 67 00 3d 00 ff ff 00 00 01 00 00 00 3d 00 7b 00 | g.=.........=.{. 000020: 0d 00 00 00 57 69 6e 64 6f 77 4e 61 6d 65 53 65 | ....WindowNameSe 000030: 74 00 97 f6 82 b7 82 e9 8e 6f 96 85 82 cc 98 5a | t........o.....Z 000040: 8f 64 91 74 28 83 66 83 6f 83 62 83 4f 29 81 7c | .dt(.fobO).| 000050: 46 69 6c 65 20 3a 20 74 72 69 61 6c 68 5f 6d 61 | File : trialh_ma 000060: 79 75 2e 79 6b 73 00 7d 00 09 00 00 00 44 72 61 | yu.yks.}.....Dra 000070: 77 53 74 6f 70 00 47 72 61 70 68 69 63 48 69 64 | wStop.GraphicHid 000080: 65 00 0a 00 00 00 54 72 61 6e 73 69 74 69 6f 6e | e.....Transition 000090: 00 02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 | .....d.......... 0000a0: 00 47 72 61 70 68 69 63 4c 6f 61 64 00 00 00 00 | .GraphicLoad.... Fortunately, there among other things there is a cloud of ASCII lines, which greatly simplifies life. At first glance, it seems that these are just C-style lines terminated by zeros, but upon closer examination it turns out that this is not quite the case. There are lines and any incomprehensible inclusions of constants, for example: ff ff 00 00 01 00 00 00 , or 02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 00 , which, despite the presence of one printed ASCII character in the center ( d = 0x64) most likely the lines are not. In addition, the most valuable - here they are - these are the lines in Japanese in ShiftJIS from 82 .
Let's summarize what we got:
- sect1, consisting of 4-byte integers (presumably this is bytecode), partially referring to 16-byte entries in sect2 by these numbers
- sect2, consisting of 16-byte entries with increasing numbers inside (presumably, some offsets)
- sect3, consisting mainly of null-terminated lines in ShiftJIS, but not quite (presumably - string resources and all other constants referenced by bytecode)
On this small victory, I think we will complete our today's research, since the article once again turns out indecently large. To some extent - if, for example, the task is to translate a visual novel - what has been achieved today is enough to tear out the texts and give them to the translators. Take sect3, find in it everything that looks like SJIS, carefully throw away everything else - voila:
恋する姉妹の六重奏(デバッグ)-File : trialh_mayu.yksまゆ「きゃっ……!!」教育的指導を兼ねて、お望み通りメチャクチャにしてやろうじゃないか!! 「あっ……お、おにぃっ……」自分から誘っておきながら、不安そうな表情を浮かべるまゆ。そんなまゆを、ソファーに押しつけて……胸を露出させ、股間が丸見えになる体勢を強いる。 「んぁっ……」 Thanks to everyone who read to this place. Next time we get to the bytecode itself and try to understand how sect1 and sect2 work. See you!
')
Source: https://habr.com/ru/post/309414/
All Articles