Basics of Serverless Applications in Amazon Web Services
 Good day, dear Habra users!
Good day, dear Habra users!Today, I would like to talk about technology that is actively gaining momentum in the IT world - about one of the cloud technologies, namely, serverless application architecture (Serverless BSA). Recently, cloud technologies are gaining increasing popularity. This happens for a simple reason - easy accessibility, relative cheapness and lack of initial capital - both knowledge to maintain and deploy infrastructure, and monetary nature.
Serverless technology is becoming more and more popular, but for some reason there is very little coverage in the IT industry, unlike other cloud technologies such as IaaS, DBaaS, PaaS.
For writing this article, I used AWS (Amazon Web Services) as the undoubtedly the largest and most thoughtful service (based on Gartner's analysis for 2015).

Today we need:
- AWS account (Free - tier is enough for tests and minimal development);
') - Development platform (I prefer Linux - Fedora, but you can use any distribution that supports Node at least 4.3 and NPM);
- Serverless Framework 1. * Beta - I will tell about this framework in more detail in a separate chapter (https://github.com/serverless/serverless)
Well, what - let's start with the basics.
Serverless - what is the basis of popularity
Serverless - serverless application architecture. In fact, it is not so serverless. The basis of the architecture is microservices, or functions (lambda) that perform a specific task and run on logical containers hidden from prying eyes. Those. the end user is given only the interface of loading the function (service) code and the possibility of connecting event sources (events) to this function.
Considering the example of the Amazon service, the source of events can be many of the same Amazon services:
- S3 storage can generate a lot of events on almost any operation, such as adding, deleting and editing files in baket.
- RDS and DynamoDB - moreover, Dynamo allows you to generate events on the addition or change of data in the table.
- Cloudwatch is a cron-like system.
- And, the most interesting thing for us is API Gateways. This is a software HTTP protocol emulator that allows you to abstract requests to a single microservice event.
Schematically, the work of microservice can be presented as follows:
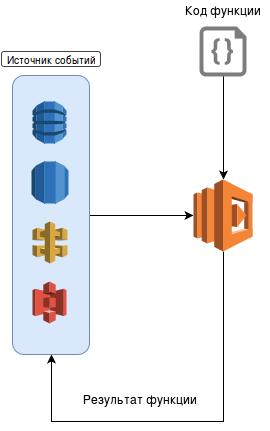 In fact, as soon as you upload the function code to Amazon, it is saved as a package on the internal file server (like S3). At the moment of receiving the first event, Amazon automatically launches the mini-container with a specific interpreter (or virtual machine, in the case of JAVA) and runs the received code, substituting the generated event body as an argument. As is clear from the principle of microservices, each such function cannot have a state (stateless), since there is no access to the container, and the time of its existence is not determined by anything. Due to this quality, microservices can easily grow horizontally, depending on the number of requests and workload. In fact, on the basis of practice, the balancing of resources in the Amazon is done fairly well, and the function “grows” fairly quickly even with abrupt increases in load.
In fact, as soon as you upload the function code to Amazon, it is saved as a package on the internal file server (like S3). At the moment of receiving the first event, Amazon automatically launches the mini-container with a specific interpreter (or virtual machine, in the case of JAVA) and runs the received code, substituting the generated event body as an argument. As is clear from the principle of microservices, each such function cannot have a state (stateless), since there is no access to the container, and the time of its existence is not determined by anything. Due to this quality, microservices can easily grow horizontally, depending on the number of requests and workload. In fact, on the basis of practice, the balancing of resources in the Amazon is done fairly well, and the function “grows” fairly quickly even with abrupt increases in load.
On the other hand, another advantage of such a stateless launch is that payment for using the service, as a rule, can be made based on the execution time of a particular function. Such a convenient payment method - in English-language literature Pay-as-you-go - makes it possible to launch startups or other projects without initial capital. After all, the need to redeem hosting for placing a code is not. Payment can be made in proportion to the use of the service (which also allows you to flexibly calculate the necessary monetization of your service).
Thus, the advantages of such an architecture are:
- Lack of hardware - servers;
- Lack of direct contacting and administration of the server side;
- Almost limitless horizontal growth of your project;
- Payment for used CPU time.
The disadvantages include:
- Lack of clear control of the container (you never know where and how they are launched, who has access) - which can often cause paranoia.
- The lack of "integrity" of the application: each function is an independent object, which often leads to some application scattering and difficulties to put everything together.
- The cold start of the container leaves much to be desired (at least in Amazon). The first launch of a container with a lambda function can often slow down for 2-3 seconds, which is not always well perceived by users.
In general, the technology has its own segment of demand and its consumer market. I find the technology very suitable for the initial stage of startups, ranging from the simplest blogs, ending with online games and more. Particular emphasis in this case is placed on independence from the server infrastructure and unlimited performance gains in automatic mode.
Serverless framework
As mentioned above, one of the drawbacks of the BSA is the fragmentation of the application and the very heavy control of all the necessary components - such as events, code, roles, and security policies. I must say that in projects a bit more complicated than Hello World, the regulation of all the listed components is a huge headache. And not rarely leads to the failure of services with the next update.
To avoid this problem, good people wrote a very useful utility with the same name - Serverless . This framework has been sharpened solely for use in the AWS infrastructure (and, although the 0.5 version branch was completely sharpened for NodeJS, a big plus was the redirection of branch 1. * towards all AWS-supported languages). In the future we will talk about the branch 1. *, since, in my opinion, its structure is more logical and flexible to use. Moreover, in version 1 most of the garbage was cleaned up and support for Java and Python was added.
What is the usefulness of this decision? The answer is very simple - the Serverless Framework concentrates all the necessary project infrastructure, namely: control of the code, testing, creation and control of resources, roles and security policies. And so it’s all in one place, and can easily be added to git for version control.
Having read the basic installation instructions for the framework and its configuration, you probably already managed to install it, but in order to preserve the usefulness of the article for beginners, let me list the necessary steps. Having read to this point, I hope you already have a console with Centos, so let's begin our acquaintance with the installation of NPM / Node (as the serverless package, however, is written in NodeJS).
Stage One
I prefer NVM to control node versions:
curl https://raw.githubusercontent.com/creationix/nvm/v0.31.6/install.sh | bash Stage Two
Overload the profile as indicated at the end of the installation:
. ~/.bashrc Stage Three
Now install the Node / NPM build - (in the example I use 4.4.5, since it was just at hand)
nvm install v4.4.5 Stage Four
After a successful installation, it’s time to set up access to AWS - in this article I’ll skip setting up a specific AWS account for development and its role - detailed instructions can be found in the framework’s manuals.
Stage Five
Usually, to use an AWS key, it’s enough to add 2 environment variables:
export AWS_ACCESS_KEY_ID=<key> export AWS_SECRET_ACCESS_KEY=<secret> Stage Six
Suppose the account is set up and configured (Please note that the SLS framework requires administrator access to AWS resources — otherwise, you can spend hours trying to figure out why things aren't working the way they want).
Stage Seven
Install Serverless in global mode:
npm install -g serverless@beta Please note that without specifying the beta version, you probably would have installed a 0.5 branch. To date, 0.5 and 1.0 are different, like heaven and earth, so the instructions for 1.0 on version 0.5 will simply not work.
Stage Eight
Create a project directory. And, at this stage - a small digression about the architecture of the project.
Serverless project architecture
Let's move on to how the lambda function can be loaded into Amazon. Namely, these two ways:
- Through the web console - a simple copy-paste. The method is very simple and convenient for a monosyllabic function with the simplest code. Unfortunately, this way the function cannot include third-party libraries (you can read about the list of libraries supported by lambda functions in the Amazon documentation, but as a rule, this is a language pack out of the box and AWS SKD - no more, no less).
- Through AWS SKD, you can upload a feature package. This is a regular zip archive, which has all the necessary files and libraries (in this case, there is a limit on the maximum archive size of 50 MB). Do not forget that lambda is Microservice, and it makes no sense to fill the entire software package into one function. Since the payment for the function goes on the execution time of the code - so, do not forget to optimize.
In our case, Serverless uses the second method — that is, it prepares the existing project and creates the necessary zip package from it. Below I will give an example of a project for NodeJS, otherwise the same logic will not be difficult to apply for other languages.
|__ lib // |__ handler.js // |__ serverless.env.yaml // |__ serverless.yml // |__ node_modules // |__ package.json I wouldn’t like to overload the article, but, unfortunately, the documentation on the configuration of the framework is very incomplete and fragmented, so I would like to give an example from my own customization practice. The entire configuration of the service is in a serverless.yml file with the following structure:
service:
provider:
name: aws
runtime: nodejs4.3
iamRoleStatement:
$ref: ../custom_iam_role.json #JSON , IAM . http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_policy-examples.html. JSON Statements
vpc: # VPC ( , VPC )
securityGroupIds:
- securityGroupId1
subnetIds:
- subnetId1
stage: dev # ( , , - )
region: us-west-2 #
package: #
includee: # – , , , – (handler). , , .
- lib
- node_module # , , – .
exclude: # , , , .
- tmp
- .git
functions: # . – . , . , , , lambda .
hello:
name: hello #
handler: handler.hello #
MemorySize: 512 #
timeout: 10 #
events: # ,
- s3: bucketName
- schedule: rate(10 minutes)
- http:
path: users/create
method: get
cors: true
- sns: topic-name
vpc: # VPC
securityGroupIds:
- securityGroupId1
- securityGroupId2
subnetIds:
- subnetId1
- subnetId2
resources:
Resources:
$ref: ../custom_resources.json # JSON , .
For the most part, this configuration file is very similar to the CloudFormation configuration of the Amazon Service - I will write about this, perhaps in the next article. But in short - this is a service to control all the resources in your Amazon account. Serverless relies entirely on this service, and usually, if an incomprehensible error occurs during the installation of a function, you can find detailed information about the error on the CloudFormation console page.
I would like to note one important detail about the Serverless project - you cannot include directories and files located higher in the directory tree than the project directory. Or rather - ../lib will not work.
Now we have a configuration, let's move on to the function itself.
Stage Nine
We create the project with the default configuration
sls create —template aws-nodejs After this command, you will see the project structure - similar to the one described above.
Stage ten
The function itself is in the file handler.js. The principles of writing a function can be read in the documentation of Amazon . But in general terms, an access point is a function with three arguments:
- event - the event object. This object contains all the information about the event that called the function. In the case of the AWS API Gateway, this object will contain an HTTP request (in fact, Serverless installs the default HTTP request mapper in the API Gateway, so the user doesn’t need to configure it himself, which is very convenient for most projects).
- A context is an object containing the current state of the environment — information such as the AVR of the current function and, sometimes, authorization information. I want to remind you that for NodeJS 4.3 Amazon Lambda, the result of the function should be returned via callBack, rather than the context (eg {done, succeed, fail})
- Callback is a callback (Error, Data) format function that returns the result of an event.
For example, let's try to create the simplest Hello World function:
exports.hello = function(event, context, callback) { callback({'Hello':'World', 'event': event}); } Stage Eleventh
Loading!
sls deploy Usually, this team will take time to package the project, prepare the functions and environment in AWS itself. But, at the end, Serverless will return ARN and Endpoint, by which you can see the result.
As a conclusion
Despite the fact that the article covered only the basics of using Serverless technology, in practice, the range of applications of this technology is almost unlimited. From simple portals (made as a static page using React or Angular) with a backend and logic on lambda functions - to processing archives or files through S3 storage and quite complex mathematical operations with load distribution. In my opinion, the technology is still at the very beginning of its inception, and will most likely develop further. So, we take the keyboard in hand and go to try and test (the benefit of Amazon Free Tier allows you to do it completely free of charge at first).
Thank you all for your attention - please share your impressions and comments in the comments! And, I hope, you will like the article - in this case, I will continue the cycle of deepening into technology.
Source: https://habr.com/ru/post/309370/
All Articles