Principles and techniques for processing queues

Principles and techniques for processing queues
Konstantin Osipov (Mail.ru)
What do you think is the cost of priority queues? That is, if someone climbs out of turn, then how to calculate the cost for the entire system in this situation, to which is it proportional? Customer service time - for example, is it worth serving 5 minutes? It is proportional to the number of people waiting, because the waiting time for each of them will increase.
To begin with about myself - I am developing the Tarantool DBMS at Mail.ru. This report will be about queuing processing. We have many queues within the system, in fact, the entire database is built as a queuing system.
Basically, we will talk about load balancing problems, but before that I would like to talk about why we need queues and how they appeared in computer systems, what they allow to achieve.
One of my favorite misconceptions about databases is that transactions are enough for everything. For example, in order to transfer money from one bank to another, you need to make a distributed transaction between two banks - and everything will be fine. Those. we take and deduct an account in one bank, then we deduct an account in another bank, do a charge / debit, and then decompose. And we have everything consistently and reliably.

')
Or take a problem with an ATM: we are trying to withdraw money from an ATM — we need a distributed transaction between an ATM and an automated banking system — the backend — and all of us will be fine too.
But there is one small problem in this story - what about the printer? What checks prints? Can it be a member of a distributed transaction or not? Or can a banknote dispenser become a member of a distributed transaction? Does it support rollback? Not.
Transactional theory is good, but it is impossible to use it for everything, so there are, first of all, participants in real life that cannot be rolled back, there are idempotent participants, that is, some operation can be safely repeated again. And there are nonidempotent participants, i.e. stuffing impossible to turn back. And with such participants you need to somehow live and communicate.
One of the methods of working with such participants is the queue, because if we fix the status of any task in the queue, then we are in fact turning a nonidempotent participant into an idempotent one. We can always refer to the queue and see the status. Our queue acts as a journal - it keeps track of the current state of the task. We put a task in a queue, for example, on a seal or on a dispenser, to give banknotes, then we perform this task, update the status, etc. So at any moment we can understand at what step we were relative to the task. In this sense, it was the transaction systems that were the pioneers of queuing systems. There are all sorts of enterprise transaction managers, etc. - they also manage transactions, manage queues. Well, the pattern architecture associated with the queues is typical.
How can I summarize what I have stated above? What are the advantages that queues give us?

One of the unobvious advantages is that we can “untie” both the client and the server, i.e. with us, the execution of tasks does not depend on whether a client is currently available, or whether a server is currently available. The client puts the task in the queue, after that his role, in a sense, ends, the server at this moment does not have to be available. The server at some time, when he has the opportunity, takes tasks from the queue, performs it, changes its status, etc. The client can always contact and check the status of the task.
The status of the task is always known. We can have several servers of one client, several clients of one server, they all work through a single queue, thus we can balance the load.
When it comes to load balancing, it immediately comes to priorities, but not everything is so simple with them, i.e. if someone jumps to the top of the queue, then the cost of such an action is not obvious and depends on the system load.
What are the disadvantages of this approach? The fact that we have an additional entity, in fact, we have the same task. If earlier we addressed directly to the server without a preliminary buffer as a queue, then we immediately executed it. Now we have set the task, the server is accessing - it changes its status, we have more requests.
One of my favorite topics is that people lean towards non-persistent queues, because it seems to them that non-persistent queues are enough in their particular task. For example, Rabbit. Although Rabbit may be persistent, there persistence is associated with transactionalities. We are talking about reliable persistence, i.e. as soon as you have a queue, its state is actually the state of your system. If you lose this state, then you can have all sorts of anomalies associated with the reprocessing of tasks, i.e. someone received the mailing 2 times, someone added a photo 2 times, someone didn’t add it at all, because the task was lost, i.e. the client who put the task in the queue thinks that everything is fine, and the server has lost the task, because the queue is non-persistent.
Therefore, a queue is not a separate component, but a database that acts as a queue, i.e. she runs this script. This is a transactional system. In principle, the most correct line. And this kind of queues are more expensive.
When we talk about patterns, we need to recall a situation where one task can generate many tasks.

Suppose a user is registered with you, what needs to be done? Send a notification to his friends, download some of his pictures, sms or send him a mailing ... You have many different tasks related to one action, and the queue can act as a multiplexer. And besides load balancing, the queue as a pattern is often used just to perform a bunch of tasks. The user came, did some action on the website, he was immediately given an "OK", after that the system already rustles, rakes and does all the tasks associated with this action, due to this we have a more reactive interface.
In particular, one of the unobvious stories, which is filed exclusively on the queues in Mail.ru, is the assembly of mail. You can connect remote mailboxes to Mail.ru, you can connect Gmail, and mail from all these mailboxes appears in your mailbox. Or, say, you receive mail, and you are automatically displayed a photo of a person, for example, from a social network. At some point, even before you log into your mailbox, mail should form a front page, which it shows you - your mail has already been read, and the avatar of the person who sent the mail. The task is to get and save the avatar in the local cache, so that when you go to the front page you will quickly see it. So that at the moment when you enter, do not contact any social network API, gravatar'u in order to receive this picture, and that all this does not slow down. Such a principle of application.
If we are talking about the practice of application, then there is a lot of specific rakes, which should also be remembered.

First of all, it is connected with all sorts of “bad” tasks. Everything goes hand in hand. Such a DDoS method is now popular when it is carried out after searching for a vulnerability in the bandwidth of a website. Those. not stupidly dolbytsya on the network load in some of the websites at the network stack level, and it turns out some vulnerabilities associated with thin places in the architecture. Those. Suppose that at the time of registering a new user we have a large amount of work related to something. What we can do? We can load this website with a number of empty registrations so that its systems will be overwhelmed by this work, and it could not respond in its typical scenarios - page impressions, etc. In this sense, the queue may contain “bad” tasks.
If we talk about pictures, you have the task of resizing pictures, and some pictures in the queue are broken. There are typical antipatterns, when someone uploads a battered picture, a worker takes it, crashes, due to this the queue thinks that the task is not completed, gives it to another worker, he again takes it, crashes, the task constantly returns to the queue, and accordingly the result understandable - the workers do the empty work, and nobody does the useful work. A similar story is related to priorities, if you failed to complete the task with priorities and timeouts, you may want to return the task to the queue, but execute it immediately ...
The reason why a task cannot be completed may be different, it may be in the outside world. And you may want to return the task to the queue with some timeout, then to take it back with some timeout. After this timeout expires, the outside world may change and the task will be completed ... And in the end, if the task has not been completed for a long time, then it makes sense for you to simply get rid of this task, mark it as impossible and so on. d. All this must be considered.
Another interesting idea is the applicability of queues in how the queue should work. It comes from all sorts of tasks of artificial intelligence - finding the nearest path, etc. When we have some kind of connection graph, and we are trying to find the shortest path from point A to point B on this graph, one of the ways is a complete enumeration or some more meaningful search. We take the nearest neighbors, set the task for these neighbors to find the shortest path, then choose the shortest path from those found. But it may happen that the graph will be strongly connected, and you will follow the same path many times. Due to the fact that your search first goes into the depths, and you have no reason to go through any paths, because you already know that they are not optimal, they need to be discarded.
When the queue is used naively - a typical example is a crawler to a website. You go to the website, frontpage from it, choose from this frontpage all the links to the following pages, put the task in the queue. Then the same thing happens: the workers unzip all tasks, the tasks are put in a queue. As a result, the site may simply be for-DDoS'its, because a huge number of workers begin to break at him. Either the same pages, if a lot of links go to them, you may not see this with this method, and you will be able to traverse the same links several times - this is also a meaningless task.
Nested queues and dependent tasks appear in the queues, i.e. it may make sense to organize sub queues in queues. There is a common task queue in the context of each of the queues — a sub-sequence, tasks from which can be promultiplexed.
I say abstract things, but if in practice you take any server of queues, then there these problems will be taken into account, the possibilities are somehow reflected in the interface, etc. The queue server must be persistent.

The second part of the report is related to another aspect of queue processing — the most efficient queues. Build the most efficient queues and look at the problems in terms of load balancing. What is load balancing? According to Wikipedia, this is: “... a methodology for distributing requests to multiple computers ... Allowing you to achieve optimal utilization of resources, maximize system throughput, minimize response time to a request, and avoid overloading”
What is important here?
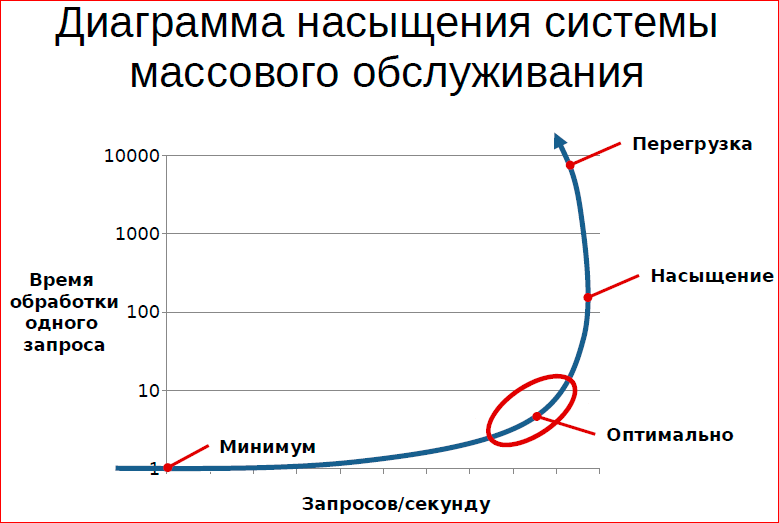
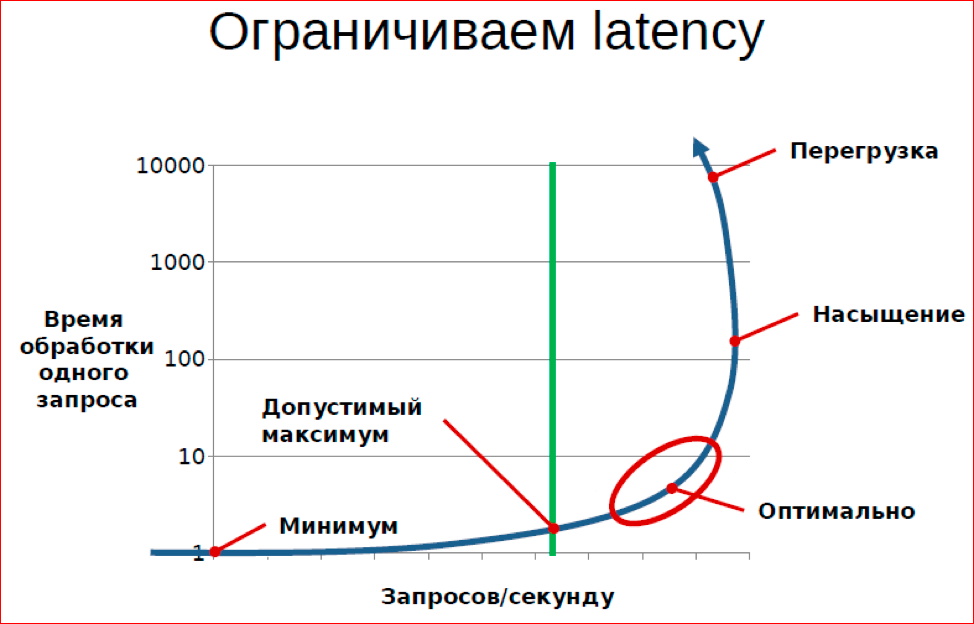
Graph - saturation diagram. On the one hand, the number of requests per second, and on the other hand, latency (in this context, the processing time of one request).
The task when we organize the queue, the processing of the queue is to make sure that on the one hand we have a high utilization of resources, on the other hand we serve all our customers with the highest quality.
What is quality? First of all, quality is the processing time, the waiting time for the result. And if you look at a typical diagram of a system that is served by a queue, it looks like this. Those. You can build a schedule for latency, you can build a schedule for RPS. In the RPS, we can either notice or not notice the decline in RPS. There are a large number of systems in which the number of requests per second decreases with increasing load.
What happens from the point of view of a queuing system? It performs useless work, i.e. at the moment of overload, something happens that is not directed one way or another to direct customer service, but to combat overload. For example, if you take a database, a typical example in a database is to reduce the load, a decrease in performance when the number of transactions that are simultaneously present in the database increases. This is due to the fact that there is a wait on the locks and deadlocks. Waiting on a lock is a useless thing, deadlocks and, in general, lead to the fact that transactions are restarted and must be re-executed - an example from a computer system.
In this situation, we are interested in building such a system, which will be in the optimal part of the curve, i.e. it will fulfill the maximum possible number of requests, while maintaining its tactical and technical characteristics.
In this sense, you often realize that many people often do not fully understand what interests them, because latency and RPS are not related things. Those. our desire to maximize system performance and our desire to maximize service quality are conflicting desires.
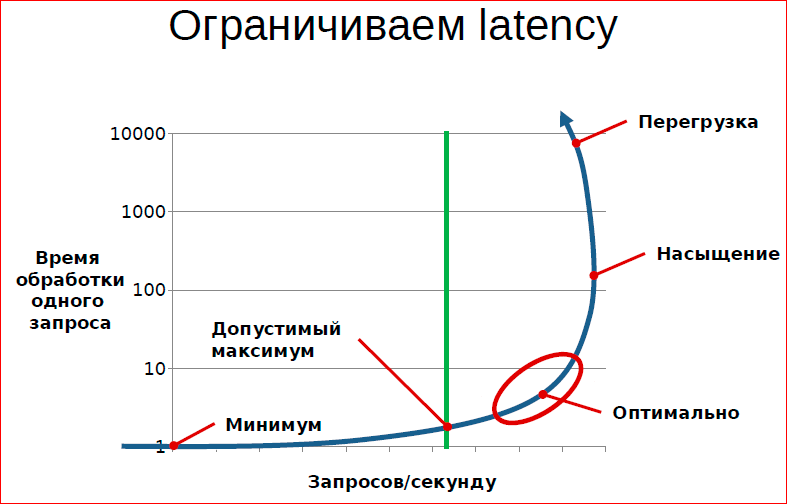
It is qualitatively seen on the graph that if we want to limit latency here with this value, then we can, at most, allow such a load, then we can’t enter any further, i.e. further quality of service requirements actually limit bandwidth.
The second criterion by which we can optimize the system is to maximize the RPS.
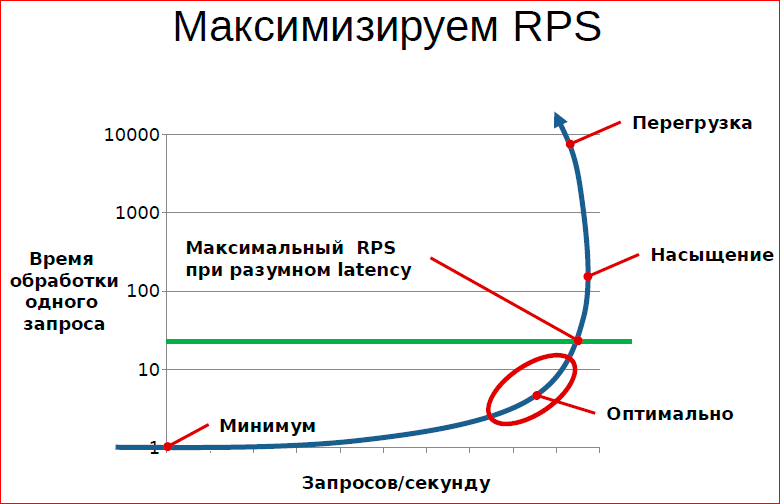
In this sense, it is useful for us to reach some kind of saturation of the system, while maintaining a satisfactory level of service, and not go into the area of overload.
To understand why these are interrelated things, I will try to dig into the theory of queues.

Model with one server - quite indicative.
There are 2 ways to understand how a queuing system works:
- 1st way is to build a model
- The second method is a simulation, i.e. benchmarking when you're testing, trying to give a live load.
If you try to dig into the theory of mass service, you realize that there can be a lot of models.

There is a Kendall notation - it classifies all systems into six indicators:
- A - time distribution between arrivals of tasks, i.e. we must understand that the living system is not perfect, it is not a metronome, and no one will set tasks to you once a second, and the living system has some kind of Poisson distribution, i.e. the number of tasks at a certain point in time follows the Poisson law; it is random — sometime more, sometime less.
- B - distribution of service time. In computer systems, the service time is more or less fixed. When we do benchmarks or simulations, we most often check some typical problems or similar tasks, but in general we can say that this is also a random variable.
- C is the number of servers, i.e. You may have a system with one server or with multiple.
- K - the capacity of the service system. This is what it is about: you may have a queue of a fixed size, and all who did not have time were late, i.e. they don't get any service at all.
- The next thing from the model - M is the source population or the total volume, i.e. it is clear that distribution and other indicators will be affected by how many potential customers you have. Not specifically at this point in time, but potential ones.
- And the principle of service Z is priorities, etc.
The simplest model that queuing theory provides is a model for a single server.

What is given here? The degree of utilization is the ratio of performance to the rate (speed) of receipt of tasks. Suppose we have 1 server can serve 10 tasks per second, and 9 tasks arrive per second. Probably, he will cope with the load, on average, 9 is the degree of utilization. Here I want to say - if the number of tasks per second exceeds the server’s bandwidth, then write is lost, nothing special can be done, the queue will inevitably grow.
π k is the probability of k tasks in the queue.
What is interesting here: let's say you have 10 tasks in a queue, the rate of receipt of tasks is 10 per second, and the server can serve 12 per second. What is the probability that at the moment when the next consumer arrives, the queue will be empty, i.e. Can he get service immediately? This is the likelihood that no one has come before - this is 2/12. With a high probability, by the time the next task arrives, the server serves some previous one with a probability of 10/12, and with the inverse probability it does not serve anyone - the model from queuing theory tells us. Those. if we want to maximize utilization, then a queue will inevitably grow in us, because at the moment when a new task arrives, the server is already busy servicing some task, and the higher the utilization, the higher this probability. This is a basic queuing theory insider.

Here I do not provide models for multiple servers, but the basic idea is that if we have a single queue and multiple servers, then we can extinguish the variance in the distribution of participants by the fact that all servers receive a uniform load.
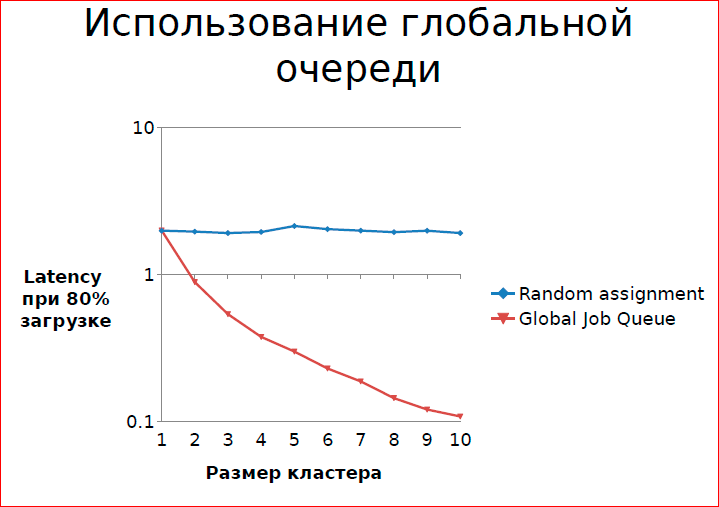
The result of the simulation, when we have 80% load on the cluster, and the blue graph - this task arrives at an arbitrary server at random, and the red graph is when we have a global queue, and each server takes a task from the queue, when he has the opportunity. With the increase in the number of servers, latency decreases - this is a real simulation.
1 is the length of the queue, when with us at 80% load each server works independently. On average, he has some kind of queue. When it is working from the global queue, the probability that at the moment of arrival is not available to perform the server task is within 0.1. Intuitively clear: we have 10 workers and 8 tasks for a worker at each moment of time. The probability that we have a task and there is no free worker is small. If we have 10 workers and each has his own task, then the probability increases.
What other insider queuing theory can I get?

The general idea of the law of Little is that the number of simultaneously serviced tasks is proportional to the service time and the rate of receipt. What is important in this case?

If your system receives 1000 requests per second, the service time for one request is 1 ms. The average queue length in such a system will be 10 (the number of simultaneous tasks in the system). In general, if these are different queues, i.e. if each worker has his own turn, then you have an average queue length of up to 10.
In terms of scaling, the output from this is as follows:

In order to grow proportionally, we need to scale the work more or less linearly, increase the number of servers and the number of simultaneously serviced tasks. Those. if we have a big task, then increasing the number of servers is not a fact that we can increase our productivity. And due to the fact that we have to increase the number of servers, we have a total number of tasks in the work grows, respectively, the time of any heating increases, the cost of downtime, etc. etc.

Conclusion: we have a conflict of requirements, and in order to satisfy it, we need to somehow reduce the load on the system. This is the main conclusion that the theory gives us.
We turn to benchmarking and talk about the practical aspects of benchmarking.

Task setting: we have 10 servers, the service time for one client, the execution of one task is 10 ms, and we want our average latency at such and such a load to be 20 ms. We want 99% of tasks to be processed within 20 ms. We are currently solving this problem.
I’m talking about the practical level that an Internet project developer might need.
To scale it is necessary to proportionally increase the number of tasks “in processing” - this has implications for the quality of service, because if you have, say, turned off the power, you have harmed a large number of people. Or the naive assumption that developers make about the fact that their queue is, on average, empty, if their servers are coping with the load - it is not correct, and we cannot talk about latency.
Most of the report is devoted to what ideas people have about latency. Most people have a vague idea of how much time a single task is processed by their system. There are practices for measuring and monitoring this, but even these practices are often not correct - just not the right implementation. What can we explore, measure, and how can we measure?
Usually we write a benchmark in which our script creates a random task, sends it to the server, gets a result, measures time, writes to the log. If we go to increase the performance of this system or check the log of saturation somehow, we increase the number of clients, although even this often people don’t master and try to load one server from the same machine on which the system under test is installed.
Most often in this situation we are interested in RPS - the number of requests per second - the more the better. Why is this wrong? First of all, we should be interested in the quality of service and in the given quality of service we need to achieve the maximum RPS. And the quality of service is determined by the time spent on a certain percentage of customers.

Suppose your RPS is 10,000 requests per second. It may be that some part of customers, say, 5% of customers, receive service in 2 seconds. Is it permissible or not? However, you can have a high RPS, but some customers will have very poor service. What is the reason for this especially in databases? With some periodic work, which simply does not measure most of the benchmarks. Those. if your database goes to sleep once a second and does something, then you may not even see it on your benchmark.
How do people usually have load schedules?
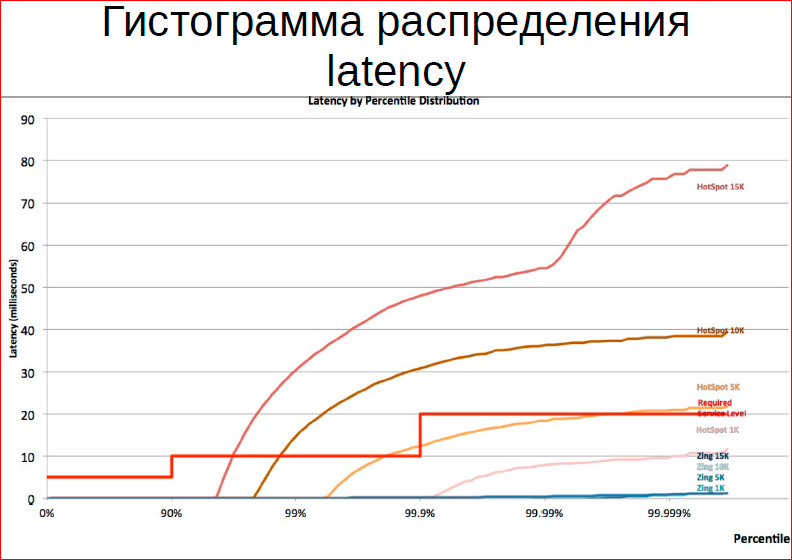
The idea is this - on the horizontal axis we have the number of requests (the number of clients), on the vertical axis - the performance - 10 thousand, 20 thousand, 30 thousand requests per second. What does this tell us about the quality of service? Nothing. First of all, in order to get a normal idea of quality, you need to build a histogram of the distribution of service time across percentiles. Those. we have 90% of requests are serviced with such performance, 10% - within such (here I have such cutter lines), and some small percentage of requests go to the ceiling and the maintenance time is very high for it.
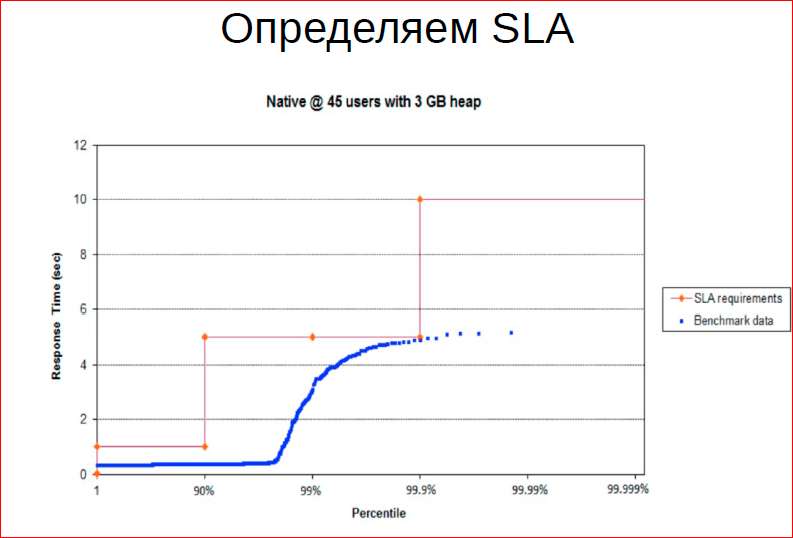
First of all, when we build such a system, we need to determine the SLA, i.e. we need 90% of requests to be serviced in 1 ms, 9.9% within 5 ms, and for the rest we have 10 ms. After determining the SLA, we need to achieve this SLA.

Coordinated omission is a coordinated measurement error. How do we usually measure the performance of our system? Measure latency. Typical code example. We say “startTime” - we memorize the time, execute the query and memorize the time at the end. Then we average and add the result.
Let's look at the problem of this approach. In the case of a single client, it will become more or less obvious. Suppose the performance of our system is 10,000 requests per second. We wrote this benchmark and measure this performance. And now I went to the server console and sent a stop signal to the server, and it stopped for 20 seconds, then I sent a continue signal, which continues to work. In total, the benchmark worked for one minute. How many queries in the resulting histogram will have a runtime of 15 seconds? One. And in reality, how much should it be? 150 thousand. Ie the number of requests that the server has not serviced. And this is the problem of most benchmarks.
Suppose you have a benchmark chasing 40 streams, you still have this system measurement error. And most often this system error does not see, the minimum and maximum of people do not bother. The fact that the minimum and maximum does not fit into 3Σ (sigma) from the average does not bother them either, the system just measures the wrong thing. And this is an important problem that needs to be addressed.
How can it be solved? You can extrapolate, you can add load, if we see that our number of requests has now decreased, i.e. we had to do more of these-these-these and increase the number of requests. There are some ways we can solve this. And often, if we build a distribution histogram, then on the uncorrected data we look something like this - we have a small number of requests, which has a very large latency.
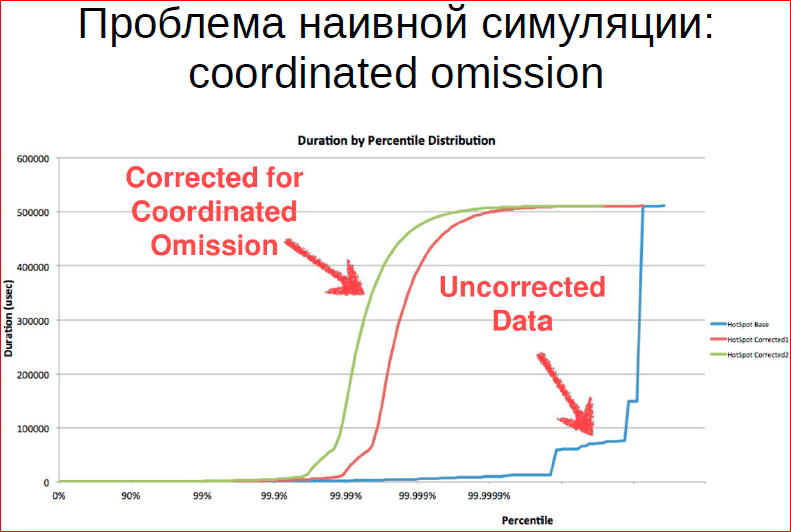
And in real life, we have latency more evenly distributed across the entire set of requests.
Thus, we can see some periodic work that the system performs. Those. suppose the LSM tree is a lavel DB, it can process requests very quickly, then at some point the process of merging trees will occur, and at some point the query execution time will decrease. Naturally, you are interested in the worst time in the final system.
The last topic is the fight against overload.
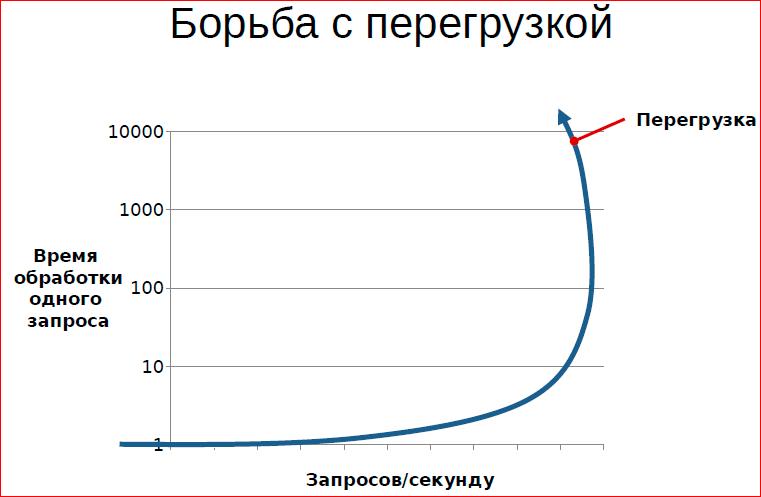
Why overload occurs, we discussed. What are the ways to fight?
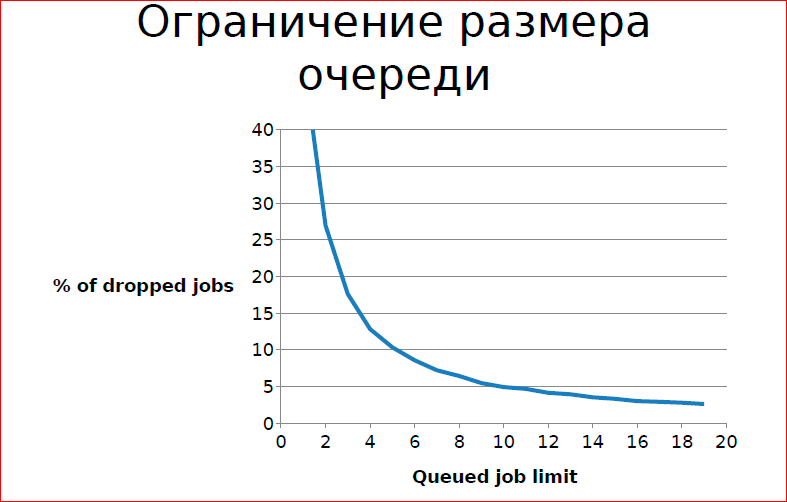
The simple way is to simply limit the queue size, i.e. all who did not have time, do not receive service. But this is not always permissible, in practice there are simulations, if our queue size is limited to 20, then we have only a certain percentage of tasks not receiving service on a particular system. Those. in specific cases it is possible.

The second way that you can use is a typical story in a bar - it’s not a fact that they will let you into the bar if it is full. In order for people who are present in the bar to receive normal service, someone must wait outside.
This is the second pattern that you can use - the ticket system, any tickets, ticket distribution. People who require resources are waiting outside, they are not waiting with resources, i.e. people in the bar already use some resources (chairs, bartender time, etc.), so let's limit their waiting outside.
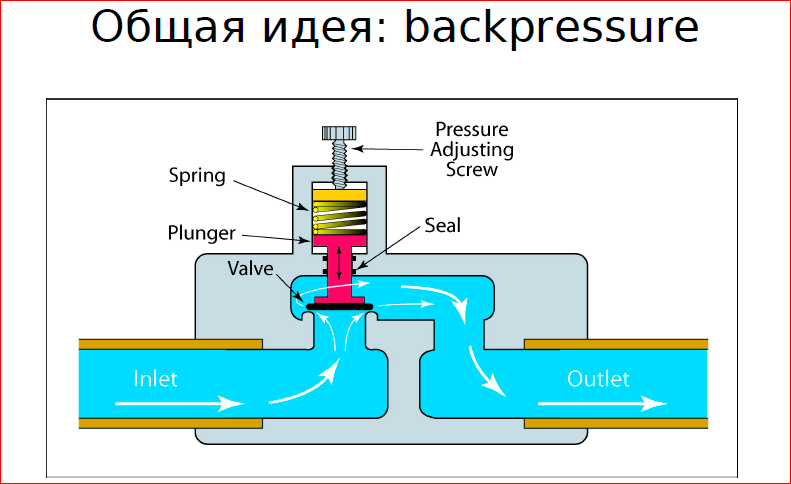
, , — , .
. , — - , , , .. , , . , , .. , .
Then there are interesting theories on modeling, on finding the optimal state when we program, we calculate linear coefficients, etc., but the basic idea is this. In practice, you will not use management theory for this, most likely. You will find some simple way.
This report is a transcript of one of the best speeches at the conference of developers of high-loaded HighLoad ++ systems. Now we are actively preparing for the conference in 2016 - this year HighLoad ++ will be held in Skolkovo on November 7 and 8.
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/309332/
All Articles