Database scaling through sharding and partitioning

Database scaling through sharding and partitioning
Denis Ivanov (2GIS)
Hello! My name is Denis Ivanov, and I will talk about database scaling through sharding and partitioning. After this report, everyone should have a desire to partivate something, shard them, you will understand that it is very simple, it does not ask for anything, it works, and everything is fine.
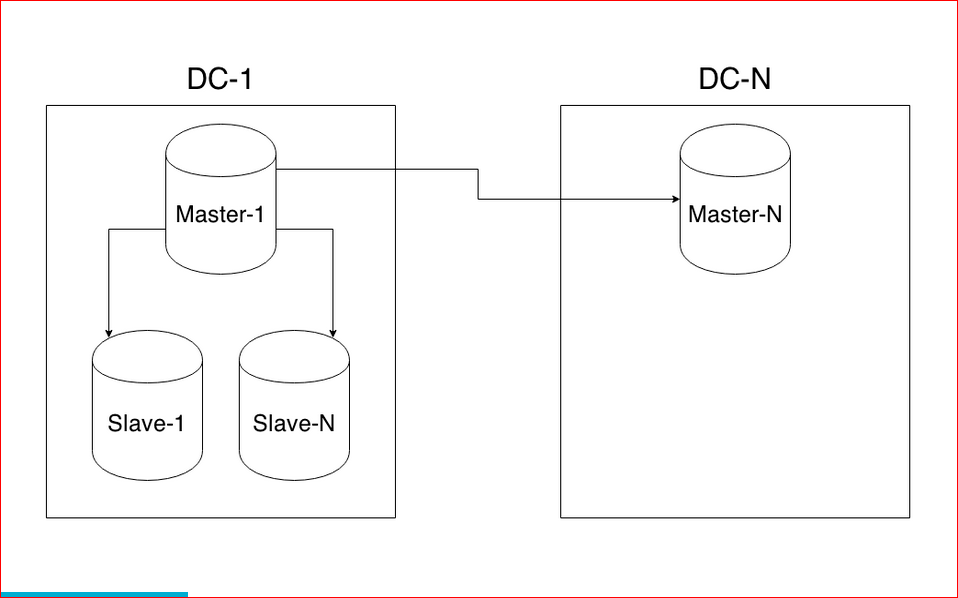
I will tell you a little about myself - I work in the WebAPI team at 2GIS, we provide API for organizations, we have a lot of different data, 8 countries in which we work, 250 large cities, 50 thousand settlements. We have a fairly large load - 25 million active users per month, and on average, about 2000 RPS loads go to the API. All this is located in the three data centers.
')
Let us turn to the problems that we are going to solve today. One of the problems is a large amount of data. When you develop a project, it may happen at your moment that there is a lot of data. If the business works, it brings money. Accordingly, there is more data, more money, and something needs to be done with this data, because these requests start to run for a very long time, and our server does not begin to export. One solution to do with this data is to scale the database.
I will tell you more about sharding. It can be vertical and horizontal. There is also such a scaling method as replication. The report " How MySQL Replication Works " by Andrei Aksenov from Sphinx was about it. I practically will not cover this topic.
Let's move on to the topic of partitioning (vertical sharding). How does all this look?

We have a large table, for example, with users - we have a lot of users. Partitioning is when we divide one big table into many small ones according to some principle.
With horizontal sharding, everything is about the same, but at the same time, our tablets are in different bases on other instances.

The only difference between horizontal scaling and vertical scaling is that horizontal scaling will spread data across different instances.
About replication, I will not stop, everything is very simple.
Let's go deeper into this topic, and I will tell almost everything about partitioning using the example of Postgres.
Let's look at a simple tablet, for sure, in almost 99% of projects there is such a tablet - this is news.
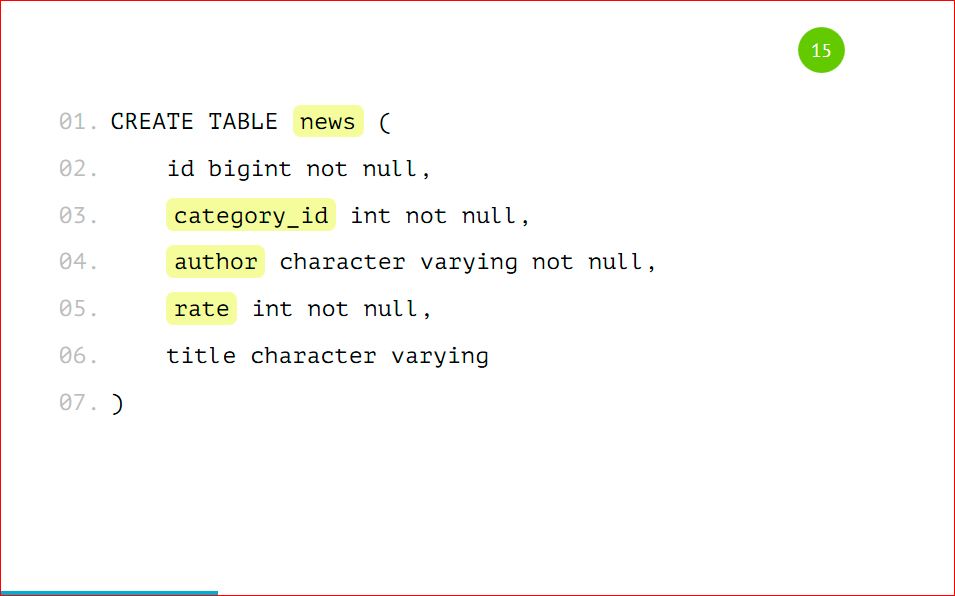
The news has an identifier, there is a category in which this news is located, there is the author of the news, its rating and some kind of heading - a completely standard table, nothing complicated.
How can this table be divided into several? Where to begin?
In total, you will need to make 2 actions on the tablet - this is put in our shard, for example, news_1, that it will be inherited from the news table. News will be the base table, it will contain the entire structure, and we will create a partition, indicating that it is inherited by our base table. The inherited table will have all the columns of the parent - the base table that we specified, and it can also have its own columns, which we will additionally add there. It will be a complete table, but inherited from the parent, and there will be no restrictions, indices and triggers from the parent - this is very important. If you create indexes on the base table and inherit it, then there will be no restrictions or triggers in the inherited index table.
The second action that needs to be done is to put restrictions. This will be a check that only data with such a sign will fall into this table.

In this case, the attribute is category_id = 1, i.e. only entries with category_id = 1 will fall into this table.
What types of checks are for partitioned tables?

There is a strict value, i.e. we have some field clearly equal to some field. There is a list of values - this is an entry in the list, for example, we can have 3 news authors in this particular partition, and there is a range of values - from what value to which data will be stored.
Here you need to stop in more detail, because the check supports the BETWEEN operator, for sure you all know it.

And so easy to do it. But it is impossible. It can be done because we will be allowed to do this, PostgreSQL supports this. As you can see, we have data in the 1st partition between 100 and 200, and in the 2nd one - between 200 and 300. Which of these partitions will get a record with a rating of 200? It is not known how lucky. Therefore, it is impossible to do this, you need to specify a strict value, i.e. strictly, the 1st partition will contain values greater than 100 and less than or equal to 200, and to the second more than 200, but not 200, and less than or equal to 300.
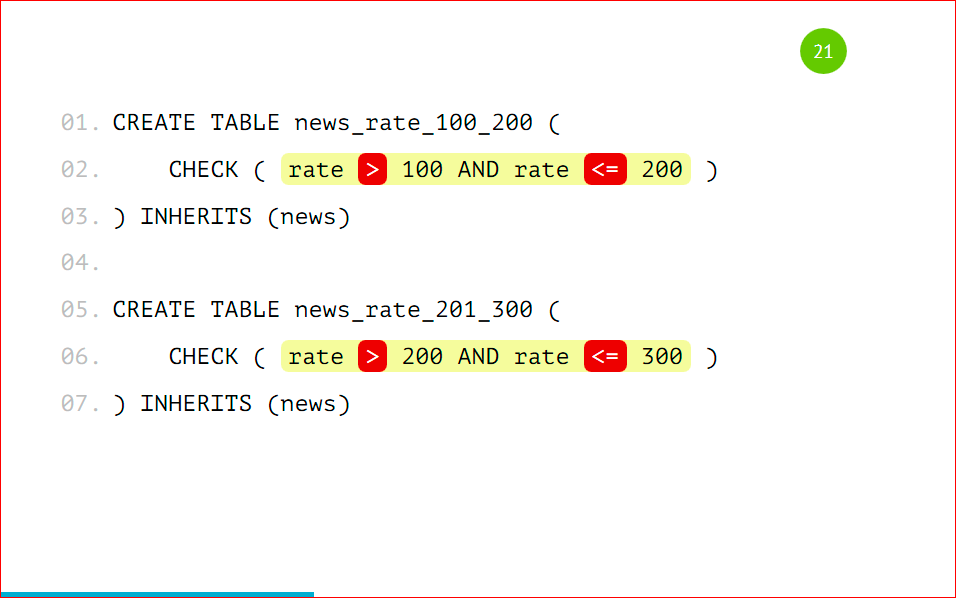
It is necessary to remember this and not to do so, because you will not know which of the partitions the data will fall into. It is necessary to clearly register all the conditions of the test.
You should also not create partitions for different fields, i.e. that in the 1st partition we will get records with category_id = 1, and in the 2nd - with a rating of 100.

Again, if we get a record in which category_id = 1 and rating = 100, then it is not known which of the partitions this record will fall into. It is worth partiing by one sign, by some one field - this is very important.
Let's take a look at our partition entirely:

Your partitioned table will look like this, i.e. this is the news_1 table with a sign that only entries with category_id = 1 will be included there, and this table will be inherited from the base news table - everything is very simple.

We have to add a rule to the base table so that when we work with our main news table, the insert for the record with category_id = 1 falls into that partition, and not into the main one. We specify a simple rule, call it what we want, and say that when data will be inserted into news with category_id = 1, we will instead insert data into news_1. Here, too, everything is very simple: on the template, it all changes and it will be great to work. This rule is created on the base table.
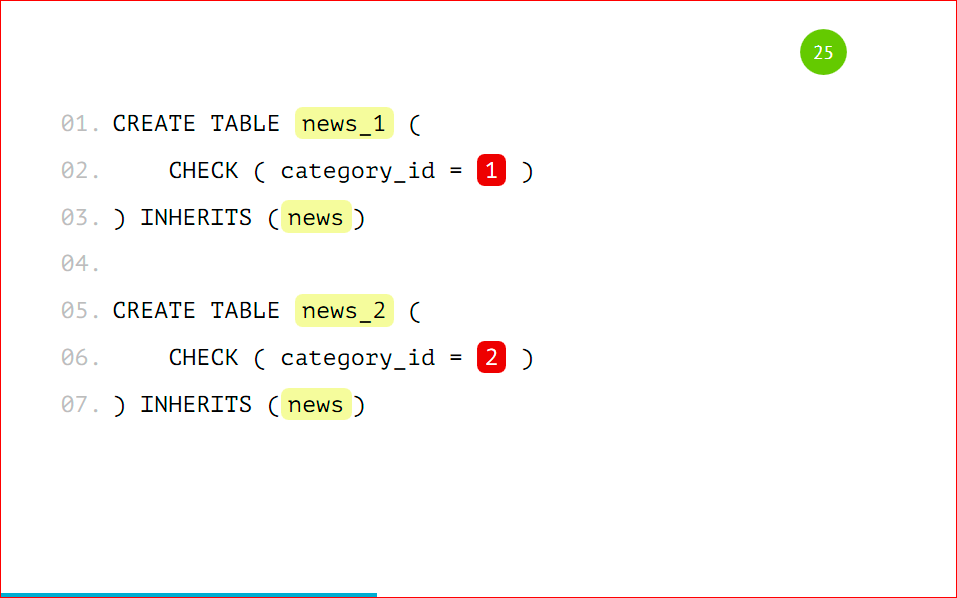
Thus we get the number of partitions we need. For example, I will use 2 partitions to make it easier. Those. we are all the same, except for the names of this table and the conditions under which the data will fall there. We also create the appropriate rules for the pattern on each of the tables.

Let's look at an example of inserting data:

We will insert the data as usual, as if we have an ordinary big thick table, i.e. we insert a record with category_id = 1 with category_id = 2, we can even insert data with category_id = 3.

Here we select the data, we have it all:

All that we inserted, despite the fact that we have no 3rd partition, but there is data. There may be a little bit of magic in this, but actually not.
We can also make corresponding queries in certain partitions, indicating our condition, i.e. category_id = 1, or occurrence in the numbers (2, 3).

Everything will work fine, all data will be selected. Again, despite the fact that from the partition with category_id = 3 we do not have.

We can select data directly from partitions - this will be the same as in the previous example, but we clearly indicate the partition we need. When we have an exact condition on the fact that we need to select data from this partition, we can directly specify this partition and not go to others. But we do not have the 3rd partition, and the data will fall into the main table.

Even though we have applied partitioning to this table, the main table still exists. It is a real table, it can store data, and using the ONLY operator, you can only select data from this table, and we can find that this record is hidden here.

Here you can, as can be seen on the slide, insert data directly into the partition. You can insert data using rules in the main table, but you can also in the partition itself.

If we insert data into the partition with some kind of alien condition, for example, with category_id = 4, then we get the error "such data cannot be inserted here" - this is also very convenient - we will just put the data only into those partitions that we really needed, and if something goes wrong with us, we will catch all this at the base level.

Here is a bigger example. You can use bulk_insert, i.e. insert several records at the same time and they will all be distributed using the rules of the desired partition. Those. we can not bother at all, just work with our table, as we used to work. The application will continue to work, but the data will fall into the partition, it will all be beautifully laid out on the shelves without our participation.

Let me remind you that we can select data as from the main table with indication of the condition, we can, without indicating this condition, select data from the partition. How it looks from the side of the explain:

We will have Seq Scan all over the table, because there the data can still get there, and there will be a scan by partition. If we specify the conditions of several categories, then it will scan only those tables for which there are conditions. He will not look at the other partitions. This is how the optimizer works — that's right, and it’s really faster.
We can see what the explain will look like on the partition itself.
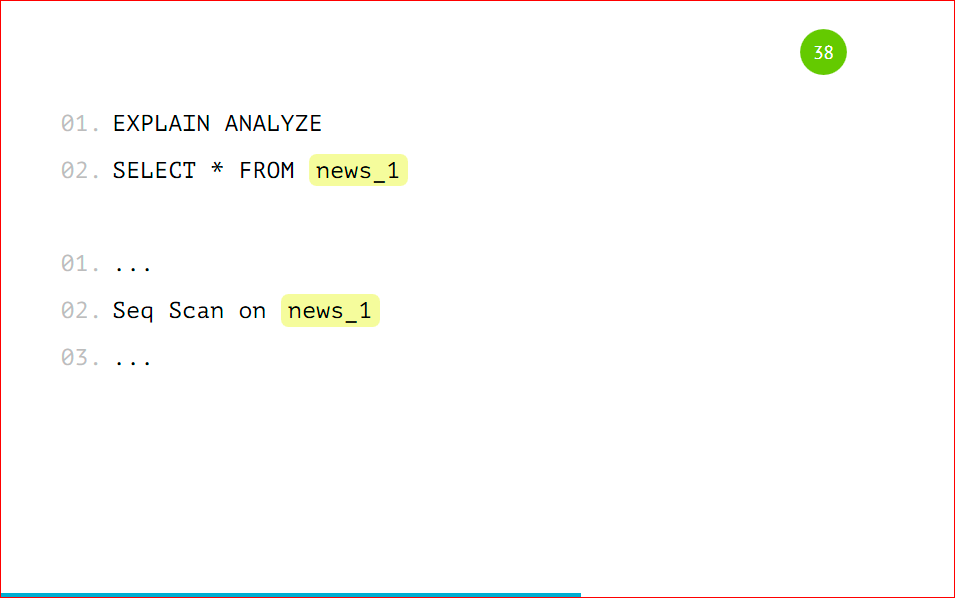
This will be a regular table, just a Seq Scan for it, nothing supernatural. In the same way update'y and delete'y will work. We can update the main table, we can also send updates directly to the partitions. Similarly, delete will work. They also need to create the corresponding rules, as we created with insert, but instead of insert, write update or delete.
Let's move on to things like Indexes.

Indexes created on the main table will not be inherited in the child table of our partition. This is sad, but you have to get the same index on all partitions. There is a lot to do about it, but you have to get all the indices, all the restrictions, all the triggers duplicated on all the tables.
As we struggled with this problem at home. We have created a wonderful utility PartitionMagic, which allows you to automatically manage partitions and not bother with creating indexes, triggers with non-existent partitions, with some kind of biases that can occur. This utility is open source, below will be a link. We add this utility in the form of a stored procedure to our database, it lies there, does not require additional extensions, no extensions, nothing needs to be reassembled, i.e. we take PostgreSQL, the usual procedure, push it into the database and work with it.
Here is the same table that we looked at, nothing new, everything is the same.

How do we partize it? And just like this:
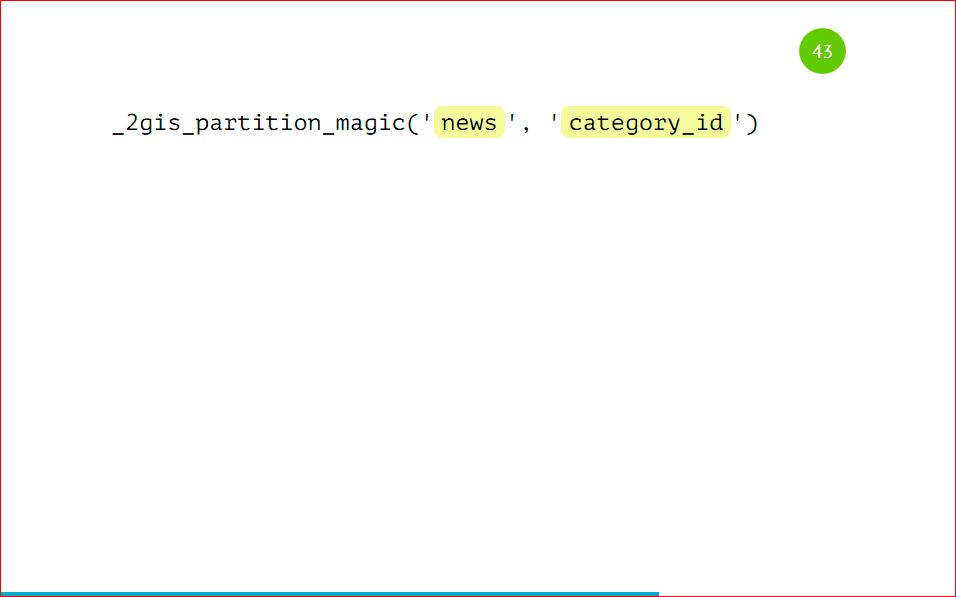
We call the procedure, indicate that the table will be news, and we will partition by category_id. And everything will continue to work on its own, we don’t need to do anything else. We also insert data.
We have three entries with category_id = 1, two entries with category_id = 2, and one with category_id = 3.

After insertion, the data will automatically fall into the necessary partitions, we can make selections.

Everything, partitions have already been created, all the data are decomposed on the shelves, everything works fine.
What we get from this advantage:
- when inserting, we automatically create a partition if it is not already there;
- we support the current structure, we can manage just the base table, putting indexes on it, checks, triggers, add columns, and they will automatically fall into all partitions after calling this procedure again.
We get a really big advantage in this. Here ssylochka https://github.com/2gis/partition_magic . This concludes the first part of the report. We learned to partition the data. Let me remind you that partitioning is applied on one instance - this is the same base instance where you would have a large thick table, but we split it into small parts. We can absolutely not change our application - it will work in the same way with the main table - we insert data into it, edit it, delete it. It also works, but it works faster. Approximately, on average, 3-4 times faster.
We turn to the second part of the report - this is a horizontal sharding. Let me remind you that horizontal sharding is when we distribute data across several servers. All this is done too simply, once you set it up, and it will work great. I will tell you more about how this can be done.
We will consider the same structure with two shards - news_1 and news_2, but these will be different instances, the third instance will be the main base from which we will work:

Same table:
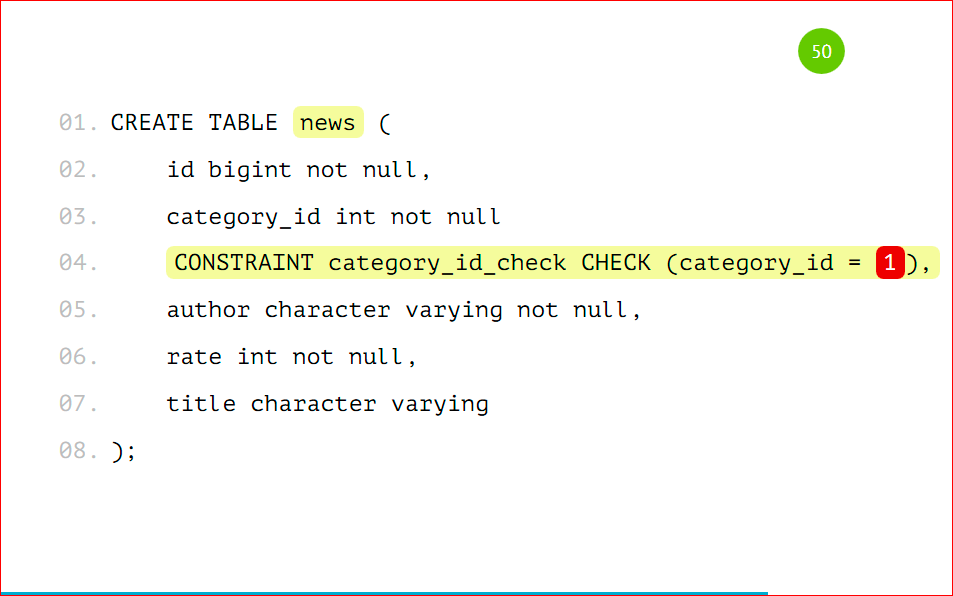
The only thing to add there is CONSTRAINT CHECK, the fact that the records will fall out only with category_id = 1. Just as in the previous example, but this is not an inherited table, it will be a table with a shard that we do on a server that will act as a shard with category_id = 1. It needs to be remembered. The only thing you need to do is add CONSTRAINT.
We can additionally create an index by category_id:

Despite the fact that we have a check check, PostgreSQL still calls this shard, and a shard can think for a very long time, because there can be a lot of data, and in the case of an index, it will respond quickly because there is nothing in the index on such a request, so it is better to add it.
How to configure sharding on the main server?
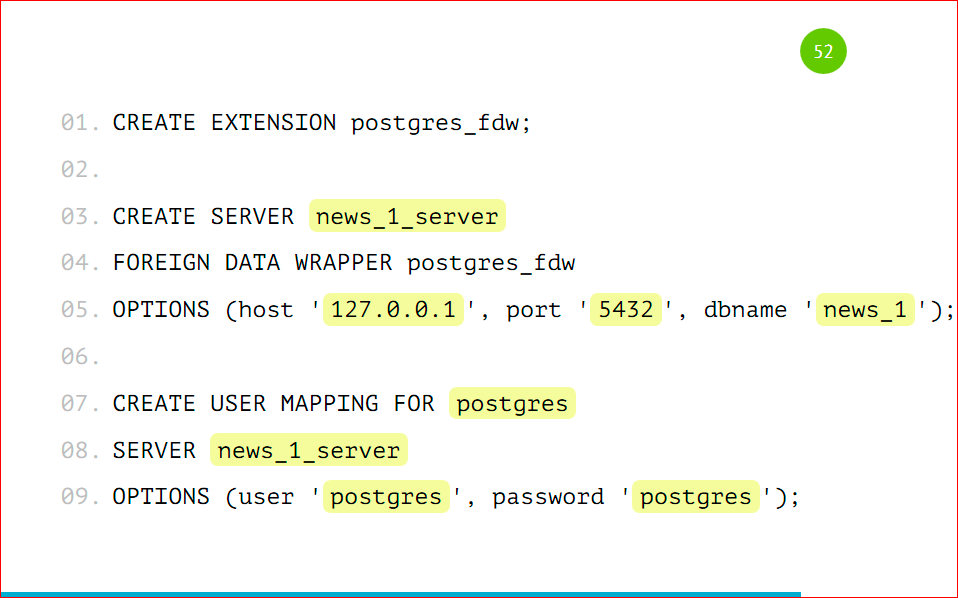
We connect EXTENSION. EXTENSION goes to Postgres out of the box, this is done by the CREATE EXTENSION command, it is called postgres_fdw, it stands for foreign data wrapper.
Next, we need to have a remote server, connect it to the main server, we call it whatever you like, we indicate that this server will use the foreign data wrapper, which we have indicated.
In the same way, you can use for the shard MySql, Oracle, Mongo ... Foreign data wrapper is available for very many databases, i.e. it is possible to store separate shards in different bases.
In the option we add the host, port and name of the base from which we will work, you just need to specify the address of your server, the port (most likely, it will be standard) and the base that we have entered.
Next, we create a mapping for the user - according to this data, the main server will be authorized to the child. We indicate that for the server news_1 there will be a postgres user, with the password postgres. And it will be mapped to the main database as our user postgres.
I showed everything with standard settings, you can have your own users for projects, for individual bases, here you need to specify them for everything to work.
Next, we get a sign on the main server:

It will be a sign with the same structure, but the only thing that will be different is the prefix that it will be a foreign table, i.e. it is some kind of foreign for us, remote, and we indicate from which server it will be taken, and in the options we indicate the scheme and the name of the table that we need to take.
The default scheme is public, the table we got was called news. Similarly, we connect the 2nd table to the main server, i.e. we add the server, we add a mapping, we create the table. All that is left is to get our main table.

This is done using VIEW, through the view, we use UNION ALL to glue queries from remote tables and get one big thick news table from remote servers.
We can also add rules to this table when inserting, deleting, to work with the main table instead of shards, so that it is more convenient for us - no rewriting, nothing in the application to do.
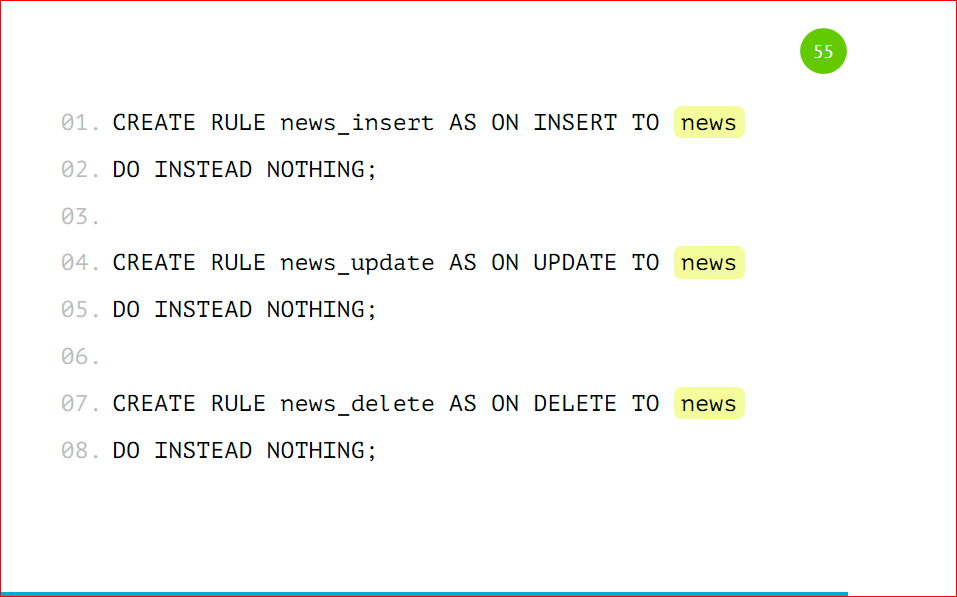
We make a basic rule that will work if no checks have worked, so that nothing happens. Those. we specify DO INSTEAD NOTHING and start the same checks as we did before, but only with our condition, i.e. category_id = 1 and the table to which the data will instead fall.
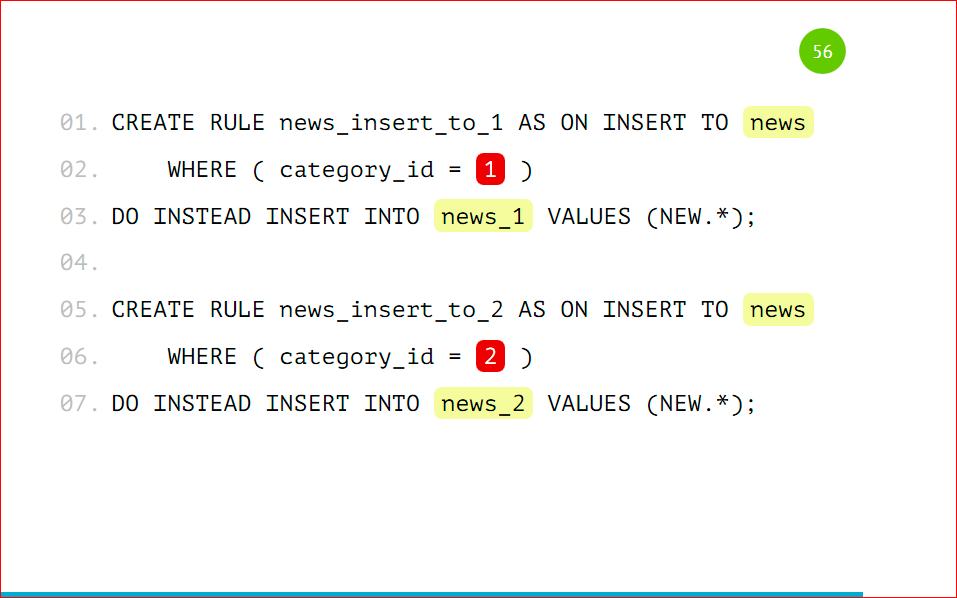
Those. the only difference is that in category_id we will specify the name of the table. Also look at the insert data.
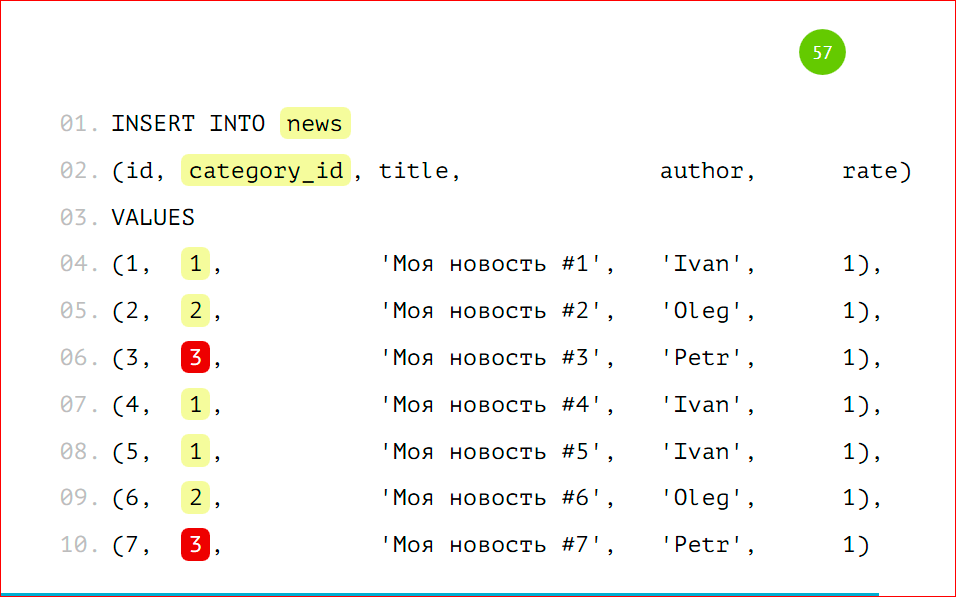
I specifically singled out non-existent partitions, since these data, by our condition, will not get anywhere, i.e. we have stated that we will not do anything if there is no condition, because this is a VIEW, this is not a real table, data cannot be inserted there. In that condition we can write that the data will be inserted into some third table, i.e. we can get something like a buffer or a basket and INSERT INTO to do in that table, so that data is accumulated there, if suddenly we have no partitions, and the data began to arrive, for which there are no shards.
Select data
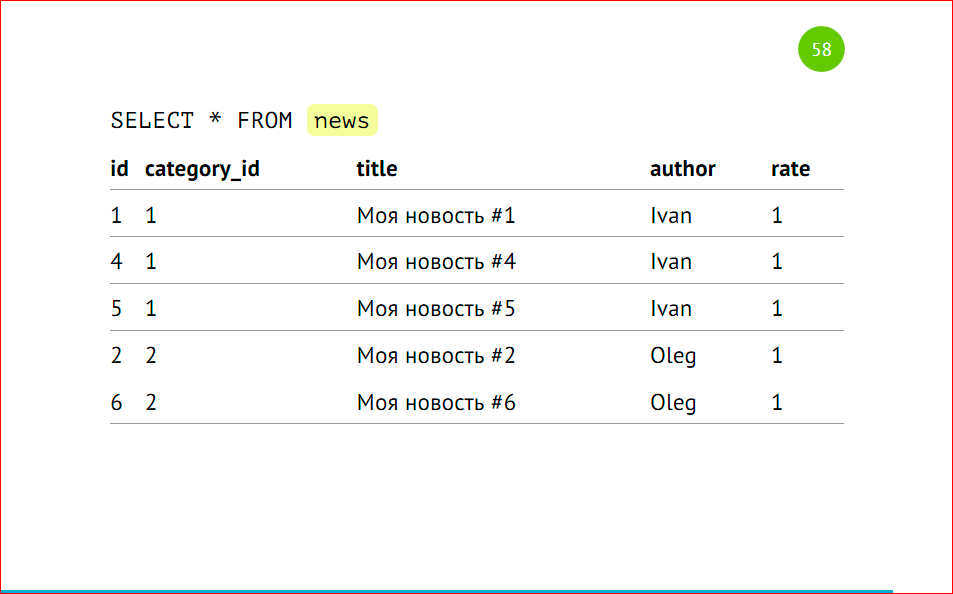
Pay attention to the sorting of identifiers - we first display all the records from the first shard, then from the second. This is due to the fact that postgres walks VIEW sequentially. We have selected selects via UNION ALL, and it executes this way - it sends requests to remote machines, collects this data and sticks together, and they will be sorted according to the principle we used to create this VIEW, according to which that server gave the data.
We make requests, which we did earlier from the main table with the category, then postgres will give data only from the second shard, or directly contact the shard.
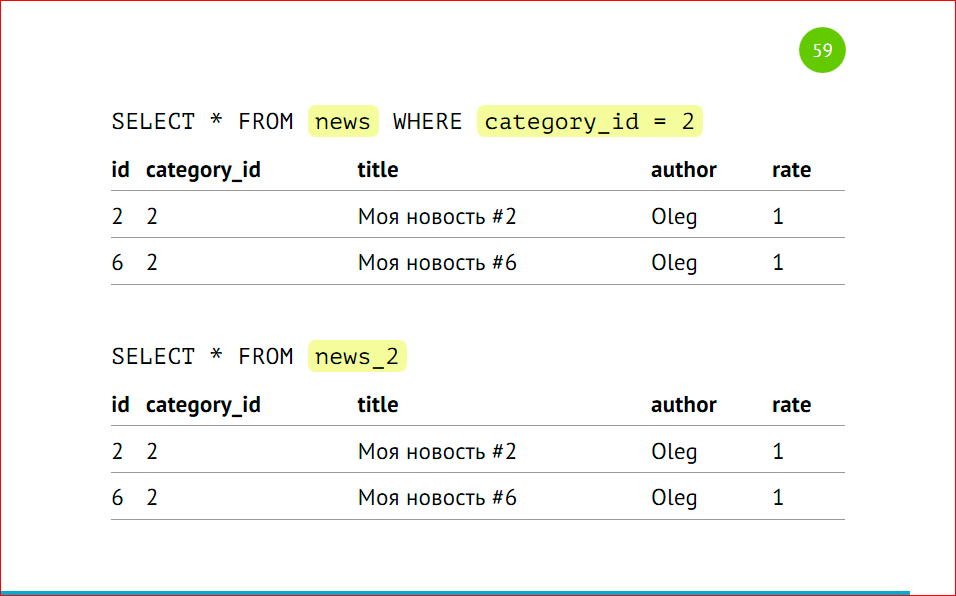
Just as in the examples above, only we have different servers, different instances, and everything works just the same as it did before.
Let's look at explain.
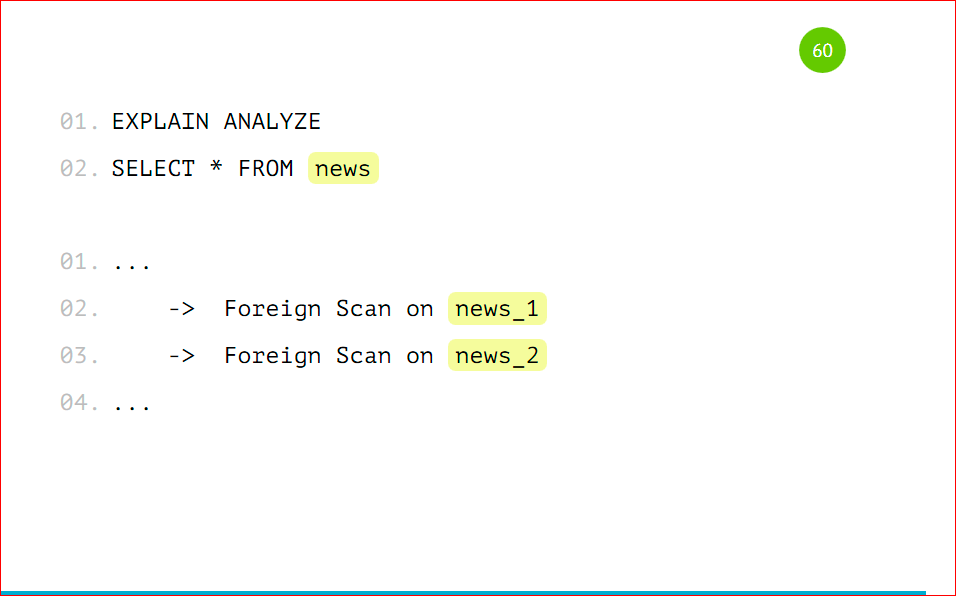
We have foreign scan for news_1 and foreign scan for news_2, just as it was with partitioning, but instead of Seq Scan, we have foreign scan - this is a remote scan that runs on another server.

Partitioning is really easy, you just have to do a few actions, set everything up, and it will work fine, it won't ask for food. You can also work with the main table, as we have worked before, but at the same time everything is fine on the shelves and ready for scaling, ready for a large amount of data.All this works on one server, and at the same time we get a performance increase of 3-4 times, due to the fact that we have reduced the amount of data in the table, because these are different tables.
Sharding is only slightly more complicated than partitioning, because you need to configure each server separately, but this gives some advantage in that we can simply add an infinite number of servers, and everything will work fine.
Contacts
2GIS blog
Source: https://habr.com/ru/post/309330/
All Articles