The basics of indexing and EXPLAIN in MySQL
The topic of the report by Vasily Lukyanchikov is indexing in MySQL and the advanced features of EXPLAIN, i.e. our task will be to answer the questions: what can we figure out with the help of EXPLAIN, what should we pay attention to?
Many of the constraints of EXPLAIN are associated with the optimizer, so we first look at the architecture to understand where the constraints follow from and what, in principle, can be done with the help of EXPLAIN.
We will go through the indexes very briefly, solely in terms of what the nuances are in MySQL, in contrast to the general theory.
The report, therefore, consists of 3 parts:
- Architecture;
- Basics of indexing;
- EXPLAIN (examples).
Vasily Lukyanchikov (Stanigost)

MySQL architecture
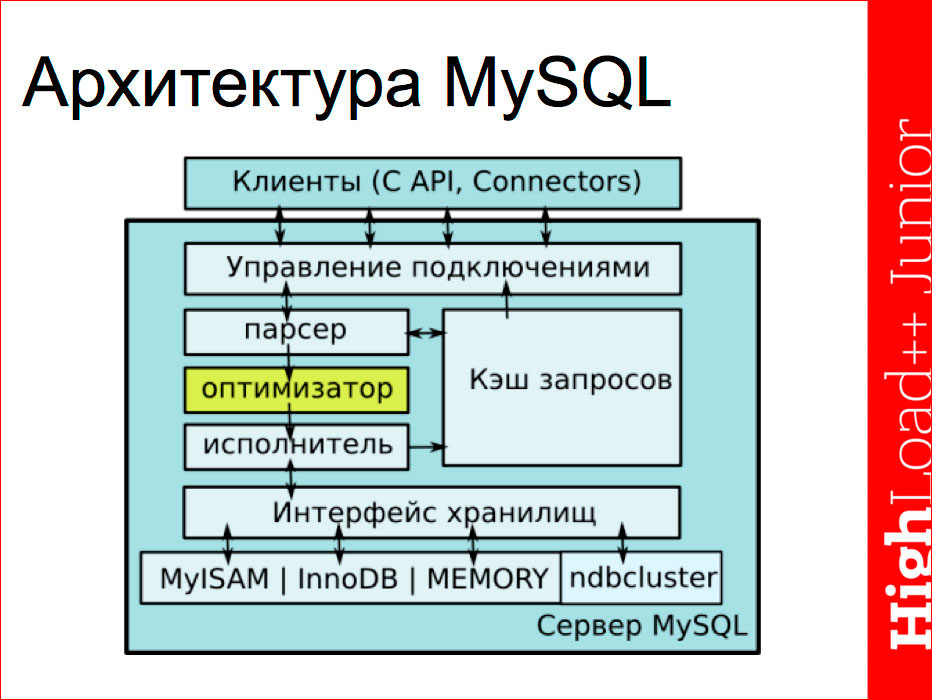
Schematically, the server can be represented as follows:
')
The first block is the clients that access the server through the functions of the corresponding connector or C API via TCP / IP or UNIX Socket, as a rule. They get to the control unit connections, where, in fact, there is an authorization of the client at this moment, and the launch of the process of authorization and execution. Each client works in its own independent stream. Extra threads can be cached by the server and then used.
About the query cache, it should be noted that it is represented by one common thread for all clients and in some cases may be a bottleneck if we have a multi-core architecture and very simple database requests. The base quickly executes them, the time to access the cache can become a bottleneck, since this is the only thread, and everyone is queuing up to it.
With connection management, the request goes to the main pipeline, which consists of three parts - the parser, the optimizer and the performer. Actually, this part turns the resulting SQL query into a data sample. This part communicates with the repository interface, each according to its tasks:
- the parser checks the syntax of the query, requests the storages for the presence of table and field data, access rights directly to these fields and checks for the response in the query cache, and then passes the parsed query to the optimizer;
- the optimizer queries the repository interface with index statistics, on the basis of which it builds a query plan that passes to the executor;
- the executor calls the received plan directly for the data in the repository, sends the response to the client via the interface and, if necessary, changes the update cache (either the result itself or resets it if there was a request for updates).
Here it is necessary to note the key feature related to MySQL, is the interface of the connected storages, i.e. You can develop your own storage (standard interface) in your company and connect it. Thus, you can make the data stored in the most convenient way for you, taking into account the various nuances.
The reverse feature is that the optimizer is very weakly connected to the repositories, it does not know and does not take into account the individual nuances of the execution of the part of the request by this or that repository. And, strangely, this also happens badly for the main repositories that MySQL developers are developing directly, and this situation has only improved in recent versions. This point must be considered.
Another point worth noting is that the indexes in MySQL are implemented exactly at the storage level, they are not standardized. Therefore, you need to keep track of what type of index - full-text, B-Tree, spatial, etc. - is used by one or another repository. And most importantly: the same index in different repositories - it can be a completely different structure. For example, the B-Tree index in MyISAM stores a pointer to the data itself, and in InnoDB it stores a pointer to the primary key; in MyISAM, compression of prefix indexes occurs, but in InnoDB this does not happen, but there is caching of both data and indexes.
There are many nuances that need to be taken into account when working, i.e. some requests will be faster executed in one storage, some in another, since they store statistics differently. For example, a count (*) query in the case of MyISAM can be executed very quickly without referring to the data itself, since there is stored exactly the statistics in the metadata, it is, however, for special cases, but, nevertheless, there are such nuances.
Immediately let's say about the query plan. It is done by the optimizer, and this is not some executable code, but a set of instructions that it passes to the performer. This is some assumption about how the request will be executed. After the executor makes a request, some differences may appear and, unlike PostgreSQL, MySQL does not show what has been done, that is, when we look at EXPLAIN in MySQL, we do not have ANALYZE. More precisely, it appeared quite recently in Maria version 10.1, which is still beta, and, naturally, is not yet used. Therefore, we must bear in mind that when we look at EXPLAIN in MySQL, these are some assumptions.
Often there is a situation that we have the same plan, but different performance. Here it should be noted that the optimizer itself in terms of EXPLAIN gives very few things. For example, we have select (*) requests from a table and select pairs of fields from a table will have the same plan, but in one case we will have several Kb selected for each record, and in the other - there may be several MB if we have huge records . Naturally, the performance of these requests will vary by orders of magnitude, but the plan will not show it. Or, we may have the same plan, one request, but it will be different on different machines, because in one case the index is read from memory, in the other, if the buffer is small, the index is taken from the disk. Again, with the same plan, performance will vary. Therefore, in addition to EXPLAIN, you need to look at different things, first of all, at the server parameters (show status).
Here it is appropriate to refer to the last RIT ++ conference, where Grigory Rubtsov’s report was on the MySQL botanical determinant - for those who cannot hypnotize the server and immediately identify the bottleneck, there is a whole consistent scheme: look at this and that parameter - go there. As in the classical botanical determinant, when we were searching for a definition of plants, we looked at the number of leaves, the shape, etc. and so came to the answer. There is such a structure - where to look consistently what to do to find bottlenecks.
Go to the indexes in MySQL

We will not consider and list all types of indexes - they are more or less standard for each database. Speaking of MySQL, we need to note the following: MySQL does not manage duplicate indexes, i.e. if we create a table as presented, it does not mean that we will have a primary index created unique to column 1. This means that we will have three identical indexes created for one column. All three of them will occupy space, will be updated, will be taken into account by the optimizer, and MySQL will not issue any warning itself, i.e. You need to watch it yourself.
Speaking about indexes (basically we will talk about b-tree, as the most used), in order not to go into details and not to draw a tree, the index is very convenient to represent in the form of an alphabetical index. For example, an address book is a table, an alphabetical index to it is the index. Applying this analogy, we can imagine how the work with the index occurs, whereby data is selected there more quickly, etc. But there is some difference in MySQL itself, since MySQL always follows the index, it uses the index only from left to right sequentially, without tricks This may cause questions.

For example, if we need to find some names in the alphabetical index. "Hands" we will look for as follows: look at the first name, find the right names, scroll through to the next name. This is not a limitation of the b-tree tree, it is a limitation of the implementation of the b-tree tree directly in MySQL. Other databases are able to do this — using not the first column, for example, in the case of WHERE B = 3, the index in MySQL will not be used at all. Only in the special case if we ask for the minimum and maximum from this column, but this is rather the exception.
The slide above presents various options, and it is worth noting that the index breaks off at the first inequality, i.e. it is used sequentially from left to right until the first inequality. After the inequality, the further part of the index is no longer used. Those. in condition A - constant, B - range, the first two parts will be used. In the second case, the entire index will be used. In the third case, the index will also be used entirely, since the order of the constants in the condition does not matter, and the server can rearrange them. In the case of B = 3 index, in general, will not be used. In the case of a constant and inequality, the index will be used only for the first two parts, for the third part the index can no longer be used. In case A, the constant and the sorting by the last, the index will be used only for the first part, because the second part is skipped, the penultimate index will be used entirely. And in the last version, again, the index will be used only on the first part, because the index can be used for sorting only when it is going in one direction.
This is due to the fact that the composite index in MySQL is, in fact, the usual b-tree index over the concatenation of incoming columns, respectively, it can move either upward or downward in the entire tuple. Therefore, we will not be able to say: “we are moving in the ascending order of B and decreasing in C” according to the index. This limitation is specific to MySQL.
There is such a nuance. For example, A in (0,1) and A between 0 and 1 are equivalent forms, this is a range both there and there, but in the case when it is A in (0,1) is a list, he understands that this is not range, and replaces with the plural equality condition. In this case, it will use the index. This is another aspect of MySQL, i.e. You need to look at how to write - either as a list, or to put <>. He distinguishes it.
A few words about redundant syntax. If we have index (A) and index (A, B), then index (A) would be superfluous, because in the case of index (A, B), part A can be used in it. Therefore, we need to ensure that there are no redundant indexes and delete them ourselves. Clearly, this also applies to the case when both indices are b-tree, but if, for example, index (A) is full-text, then, naturally, it may be necessary.
Let's return to the nuance on the list. We can make a wider index unique here. For example, if we make index (A, B), then we simply will not use condition B, but we can make it so that it automatically substitutes the missing condition in the application if there is a small possible variant of the list. But with this recommendation you need to be very careful, because, despite the presence of a list, the further use of the index is not discarded, it cannot be used for sorting, i.e. only on equality. Therefore, if we have sorting requests, then we will have to rebuild the request through union all so that there are no lists in order to use sorting. Naturally, this is not always possible and is not always convenient. If an extension of the index allows us, for example, to make an index covering (meaning that all the fields that are selected and used in the query are present in the index), then the server understands that it’s not necessary to go to the table for the data and it completely appeals to the index to form the result. Since The index is more ordered, compact, and most often stored in cached memory, which is more convenient. Therefore, when compiling an index, we always look to see if we can somehow find a covering index for our query.
Next, consider the cases when the indexes are not used.

There are common nuances with other databases, for example, when the index is part of an expression, as in PostgreSQL, it cannot convert it, so if we have id + 1 = 3 in the query, the id index will not be used. We must bear it ourselves. If the index is part of an expression, we must see if we can transform it so that the index can be moved to the left side explicitly.
Similarly, due to the fact that it does not produce conversions (these are not only mathematical, there may be a mismatch of encodings, a type conversion), the index will not be used either. The index is not used when the first part is skipped when searching by the suffix. Well, of course, the index will not be used when comparing with the fields of a similar table, because in this case, it will first need to read the record from the table to compare.
Before that, I mentioned covering indexes, and why they are good. Let's return to the slide with architecture:
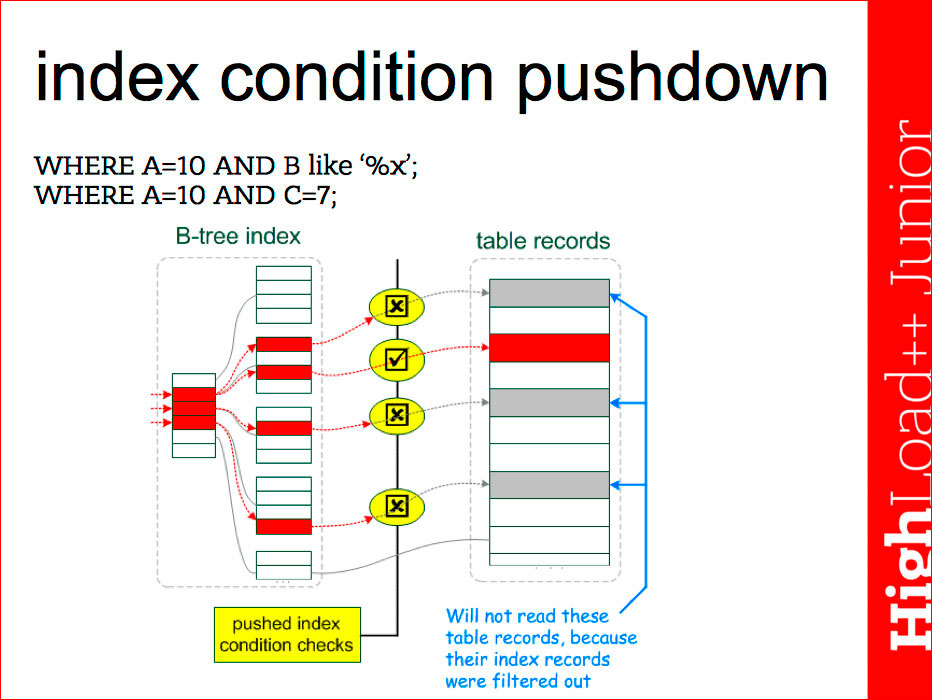
It happens like this: the executor requests data (WHERE condition) from the storage, respectively, if we have a WHERE condition for several positions, then they can all be processed inside the storage itself. This is the best option. There may be an option when part of the conditions will be processed at the storage level by the index, the lines transferred to the level up, the server will apply, and further conditions will be discarded. Clearly, it will be slower, because There will be a transfer of the records themselves from the repository to the performer. Therefore, the covering indices, if they are used here only for those fields that are more profitable in the request, because we already have fewer rows.
Here, for example, is a similar optimization called index condition pushdown:

This refers to the following. We have an index for three fields - A, B, C. In such conditions, we can use only part of the first. It would seem that we can check the indexes in the repository itself, but earlier (up to MySQL 5.6, MariaDB 5.3), the server did not do this, so you need to carefully look at specific releases - what the server can do. In new versions, the server searches the first part of the index, only column A, selects the data and, before transferring the records to the performer, it checks the condition for the second and third parts and looks at whether it is necessary to select the whole records or not. This naturally reduces the number of records that need to be read from the disk.
The key feature in InnoDB is that the secondary keys refer to the primary key, so in fact the secondary key in InnoDB is the secondary key + pointer to the primary key.

Such a long index has an invisible "tail." Invisible in the sense that earlier the optimizer did not take it into account in its actions.
Here, we have a primary (A, B) composite, respectively, secondary key - this will be a composite key on (C, A, B) and we can already search for it.
Thus, when you work with InnoDB tables and make indexes, you should always take into account that a long primary key can be either good or bad, depending on what queries you have, because it will be added to all indexes.
Here is the next nuance - this optimization will be considered only for filtering rows. In our case, only the values of the secondary key are stored in a sorted form, and the pointers to the primary key are not sorted; therefore, the server can use such a long invisible tail only for equality conditions of string filtering. It is available in MariaDB 5.5, MySQL 5.6.
The key constraints of the optimizer are that it historically uses very few statistics. It requests data from repositories. Here is more detailed what the server takes into account:
It can take into account the results of input commands, fields, the number of lines, i.e. pretty little data. The peculiarity is that initially the statistics are calculated as follows: we start the server or do some kind of command like ALTER, we have the statistics updated, then the table lives for a while, some process suddenly changes, then the statistics are updated again. Those. it happens that the statistics itself does not correspond to the distribution of data.
Again, each repository selects statistics in its own way — somewhere more, somewhere less. The latest versions implement the idea of independent statistics, i.e. server-level statistics — service tables are allocated, in which in a uniform way, statistics for all tables are collected independently of storage mechanisms, moreover, if in Percona 5.6. this is done only for indexes in InnoDB, then Maria 10 went further and collected it even for non-indexed columns, due to which the optimizer can choose more optimal execution plans, since he understands data distribution better.
The optimizer does not take into account the storage specifics - when we send a request to the storage, it is clear that the search for the secondary key in InnoDB will take longer because we go through the secondary key, get the primary key pointers, take these pointers, follow the data, those. we will have a double pass, and in MyISAM, for example, there will be immediately pointers directly to the lines themselves. The optimizer does not take into account the similar nuances of the relative speed of certain parts (our request can simultaneously refer to different repositories). It also does not take into account a lot of issues related to equipment, i.e. what data we have cached, what kind of buffers ...
Metrics. It is clear that the optimizer chooses the cheapest plan, but the cheapest plan from the point of view of the optimizer is the plan with the lowest cost, and the question of cost is a certain convention that may not coincide with our ideas about it. Again, the difficulty of choosing is when there are a lot of tables and you need to move and look at them in different ways.
He also uses the rules, i.e. if he, for example, understands that you need to use a full text index, then he uses it, even though we may have a condition on the primary key, which will uniquely produce one column.
There is still such a nuance - from our point of view, these two entries are equivalent:
where a between 1 and 4
where a> 0 and a <5
but from the point of view of the MySQL server, no. In the case when a> 0 and a <0, he will use the search by range, and in the case when we write the same through “between”, he can convert it into a list and use the condition on multiple equalities.
Such nuances do not allow writing queries based on common sense, but on the other hand it is convenient in that it increases the demand for specially trained people to optimize MySQL. :)
Briefly about how the optimizer works
It checks the request for triviality, i.e. can he, in general, make a query, relying only on the statistics of the indices. Maybe we are asking for negative values for the ID column, which is positively defined. Then he immediately understands that we are requesting out of range. This is a very effective option in terms of speed - choose the cheapest plan.
It would seem that the optimizer can do very few things, but in fact it applies various techniques to the mathematical transformation of the query, for example, the subqueries can either degrade, as in the old versions, by making it independent dependent, or it can be improved, as in the new ones. The list of techniques is very long.
This is the beginning of the table from the MariaDB documentation:
You need to know what lies behind all these words, so I recommend watching the documentation on MariaDB, because it is equipped with clear pictures, illustrations, and from them one can understand what is related to what.
How we can influence the optimizer:

- To rewrite a query is to either use an equivalent form of record, that is, for example, replace the subquery with a join, or rewrite the query dramatically, breaking up into parts, writing some data into temporary intermediate tables, or, in general, denormalize the table and get rid of join'ov.
- Indices - we can either add the necessary indices, or look, maybe it’s enough for us to update the statistics.
- Hints to the optimizer - use / force / ignore index - we can explicitly indicate to it which indexes should be used for which operations - for sorting, grouping, etc.
- straight_join - we can set the hard order of table joins so that it does not go through various options. We know the features of the distribution of data and know the order in which we need to work, so we clearly indicate this.
- @@ optimizer_switch - enable / disable all specific additional optimization techniques through this variable.
- The variables optimizer_prune_level and optimizer_search_depth determine how the server selects the optimal plan — iterates over all possible options or discards. It is clear that when we have a lot of joinl tables, and the server will analyze several million permutations, it can take a quarter of an hour to think, and then execute in a split second. Such situations occur, so all these variables by default limit the execution time, which leads to the fact that the plan can be chosen non-optimal. When we perform optimization, in testing mode we can change these variables so that the server selects all the options and see if a more optimal plan can be chosen.

SQL_CALC_FOUND_ROWS is a scary word that completely kills optimization. In practice, the idea is that if we have a LIMIT request, we can include a keyword in the request, and the server will give us in the response, including the total number that would be chosen without a limit. This is convenient, for example, when we paginate pages, and this is the fault of all automatic systems. This is bad, because COUNT MySQL can optimize queries very well, but in difficult cases, when we have joines, groupings, etc., count the number of rows separately, we can rewrite the query so that part of the join, joines we do not need, part of the groupings, too, to get an answer on the total number of pages
The server uses only one method per request. When we add FOUND_ROWS, it solves two problems with one method, i.e. he actually selects all rows, as if there was no LIMIT, pulls data out of storage — all long records, he thinks, discards unnecessary ... This is very bad. Here you need to understand that the same COUNT (*) does not read the lines themselves, it simply looks at them for the presence, without transferring data to the reader.
At this level, you need to know the details to understand, otherwise just looking at EXPLAIN will not be very meaningful.

The disadvantages of EXPLAIN follow from the disadvantages of the optimizer. There are cases when he, in general, writes not what he does, gives very little information, when we say that EXPLAIN does not fulfill the request, but simply makes a plan. In older versions, it ran from subqueries, since from subqueries he materialized into a temporary subtable and if they are heavy, then the execution of these subqueries took a lot of time. And there was even a conflict with the fact that from the subquery may contain a user-defined function that will change the data, then EXPLAIN itself would also change the data. It is not clear why this is necessary, but in practice people sometimes invent very strange things.

EXPLAIN Types
If you use the PARTITIONS keyword, then it will show which sections our query uses.
The EXTENDED keyword is convenient in that it forms a SQL query that recovers from the execution plan. This is not the original SQL query, the original SQL query is converted into a plan, and then a new SQL query is synthesized from the plan already by the optimizer, which contains a number of hints on which we can understand what is happening. Creating a temporary table with keys, caching some pieces of the query - all these nuances are well described in the documentation and they help to understand what the server is doing, how our query transforms.
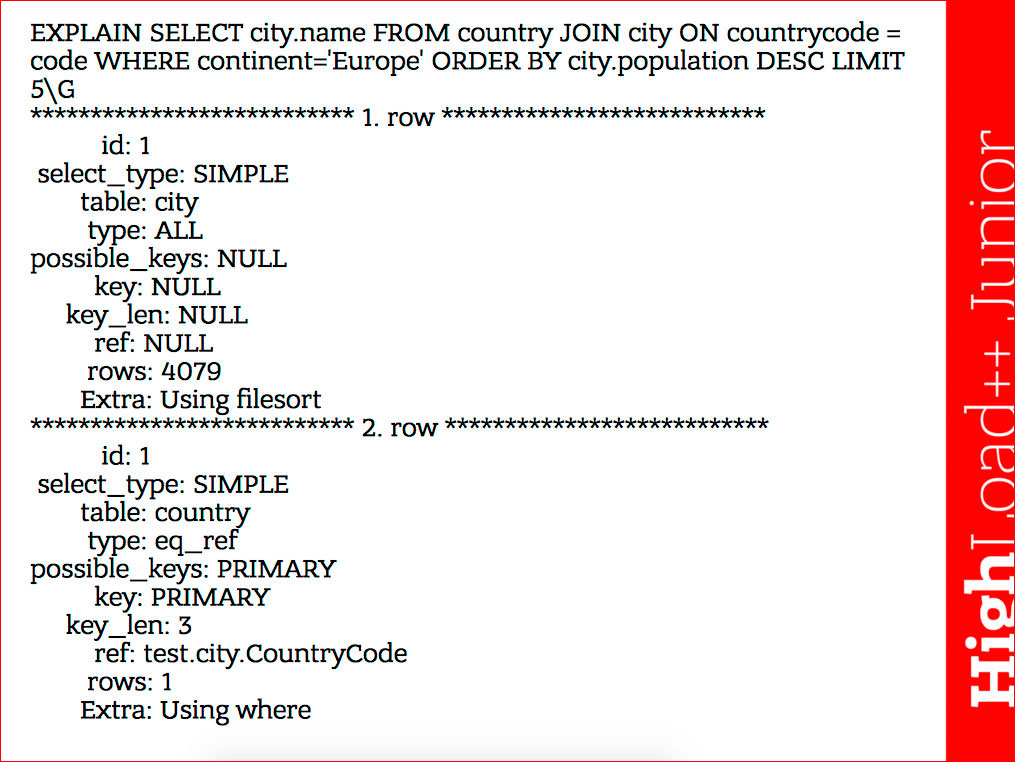
This is, in fact, EXPLAIN the simplest query.
Here you need to look at the following:
- type of access that is used. In the first case, this is ALL — the entire table is being scanned. In the second case, eq_ref is a search directly by key, forming one record.
- the number of lines, which is expected, given that this is a kind of convention.
- possible_keys are the keys that the optimizer plans to use, and key is the key that it chooses. An option is possible if you have, for example, possible_key: NULL, and there is some key in the key value. This happens in cases where, for example, there are no WHERE conditions on the SELECT FROM table. The optimizer sees that, like, no keys should be used, and then it looks that the columns are part of the key and, in principle, you can select them precisely by the index and then make the covering index. So it may happen that possible_key: NULL, and the key is the covering index, which means that it will use the index.
- key_len is the length of the index that it uses, that is, if we have a composite index, then by looking at key_len, we can understand which part of the index it uses.
Further we will not consider in detail all possible options - this is well described in the documentation.
It is clear that he forms one row for each table that occurs in the query, and executes the query in the sequence in which the table is displayed, i.e. looking at EXPLAIN, we can immediately understand that the following order of access to the tables was chosen - first selects the city table, then selects the country table. Everything is simple here.
But, when we have such a sophisticated EXPLAIN, which includes various UNION, FROM subqueries, etc., and a long “sheet” is output:

The question arises - how to read it?
The idea is very simple: we enumerate all the SELECTs that appear in the query, and the SELECT number will correspond to the identifier number that is in EXPLAIN.

I highlighted in different colors for clarity.
The second caveat - we can look at the numbers. For example, number 6 - DERIVED is a FROM subquery. The next one comes with a larger id. This means that it belongs to the same FROM subquery, i.e. will go to the same temporary table. Thus, looking only at identifiers, many conclusions can already be drawn.
There is an inconvenience: I say that rows are executed sequentially, but in reality, when there are such things as derived tables, this is not quite the case. Those. it is convenient to read requests with UNIONS in this way - one UNION is 4, and this means that the lines from 1st to 4th refer to one part of UNION, and from 4th to the last - to the second part. Those. we can look at the last line and go up, and so break requests. Actually, there is nothing difficult in this, only skill is needed.
There are utilities that immediately build EXPLAIN's graphical representations, but we will not consider them, especially since in the case of complex queries, they are also not so easy to understand. This is an amateur.
Example when EXPLAIN is lying.

We have a query with a subquery in the in part. The subquery is independent, however, MySQL before MariaDB 5.3 and MySQL 5.6 often performed these queries as dependent ones. We see the type of the query - dependent, but on the other hand we see type: index_subquery - this means that in fact the subquery is not executed, but is replaced with the function of viewing the index. Those. these lines are in conflict with each other, they talk about opposite things.
The question arises - what is actually happening there, because Does EXPLAIN give out conflicting information?
We can do the query profiling and see:
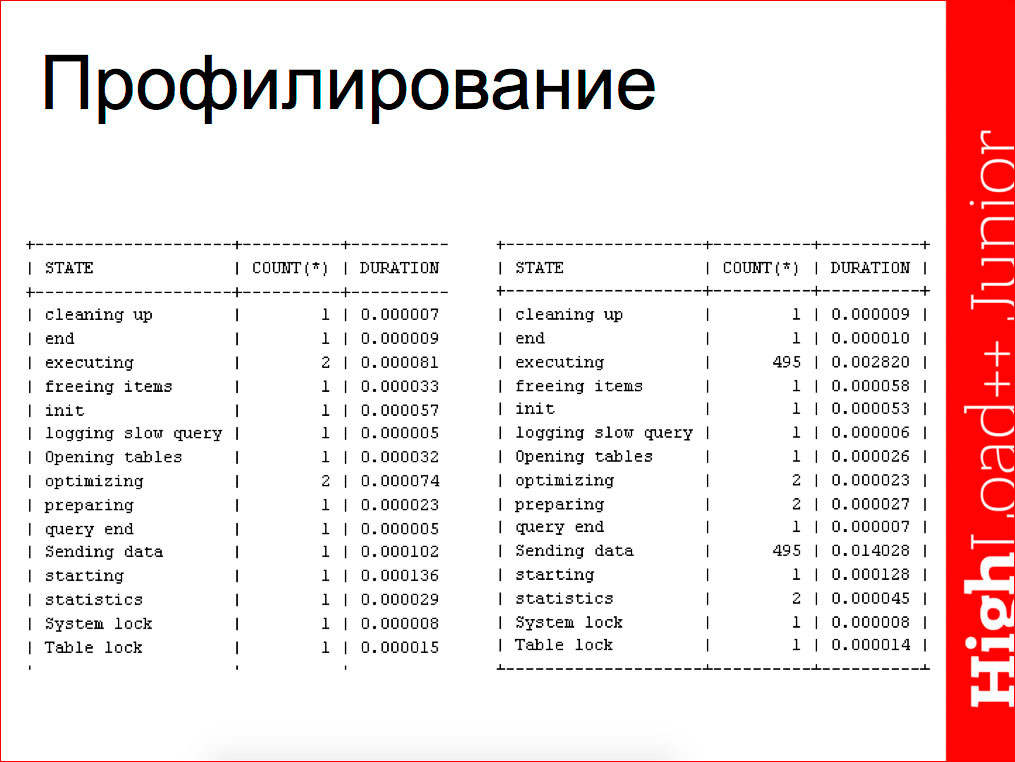
In the case when the request is executed dependent, as on the right, we have part of the execution of the request - data transfer - will be multiple, duplicated. In the case when the query is executed independently, these values will not be duplicated.
In addition, profiling is convenient for determining such nuances as transferring big data, calculating statistics, etc.
Sorting

When ORDER BY id LIMIT 10000, 10 is bad, because 10 . + 10, 1001- 10 . - . ID 10 000, LIMIT 10. offset — , , .
ORDER BY rand(), .. , , , rand . , , ORDER BY rand() , .
, , , — ORDER BY null.
.
:
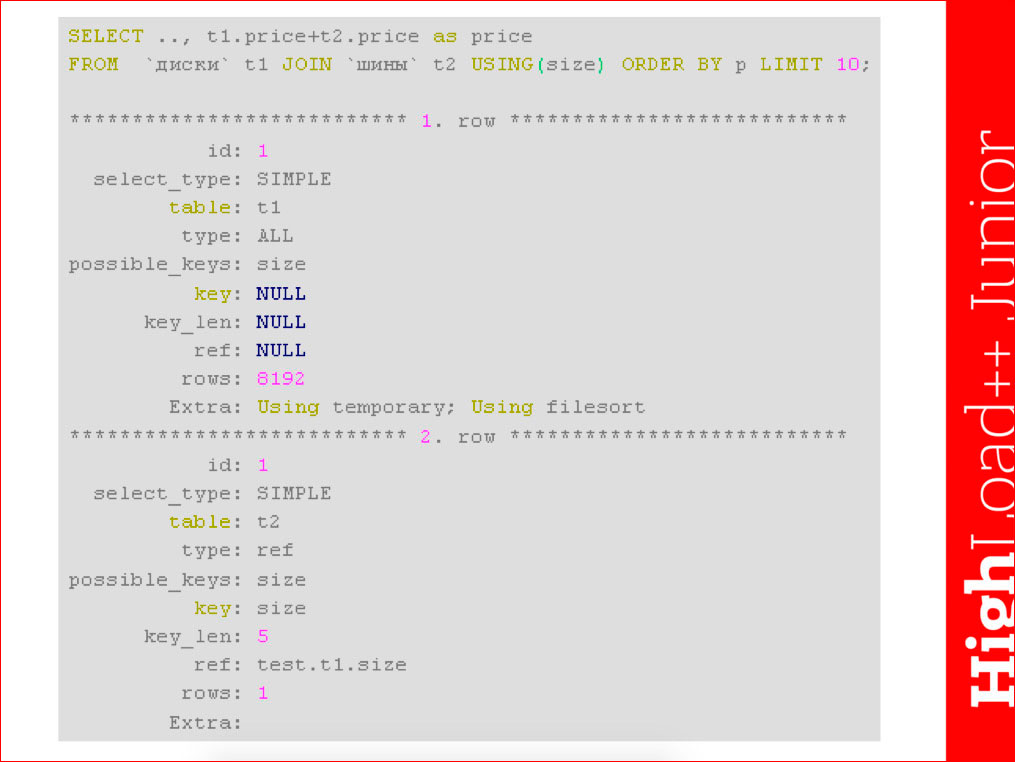
- . 10 , .. , . , “ ” join' . : . . , .
, 10 — 10 + , 10 + . , .. , . , , . , , , , , , , Using filesort, . Using filesort' — .

, : , - , . , - , .
, UNION' from . , , .. , UNION', + , . , , .
ORDER BY + LIMIT , WordPress.

— , , .. , 3 . , , Using filesort . Since , , .. , , , , .. 2 .

, . , , , category_ID=1, , , . . , , , 3 , .
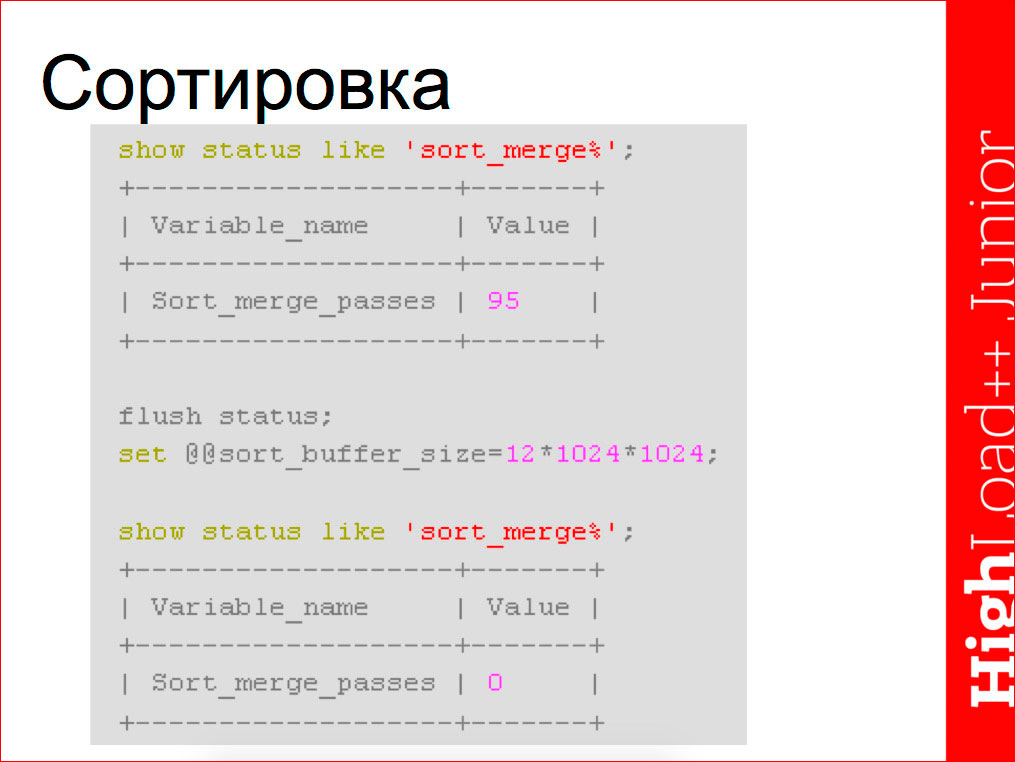
Using filesort, , — . show status , , 95 . , . key bufer size, , . , , , , .
, .

, .., , , , , 2 (, ). - .
, — EXPLAN', .
ANALYZE statement — , PostgreSQL , MariaDB 10.1, beta.
SHOW EXPLAIN, MariaDB EXPLAIN . .
Any questions you can ask me on the forum SQLinfo.ru/forum/ .
Source: https://habr.com/ru/post/309328/
All Articles