Anatomy of a web service

Anatomy of a web service
Andrey Smirnov
I will try to get into the “guts” and “guts” of the web service backend and tell you how this internal device affects the efficiency of the service, as well as the product, its characteristics, and how we could use this so that our application can withstand a large load or would work faster.
What part do I call a web service, backend, application server? In the classical architecture, this is what is behind the http reverse proxy or load-balancer, and on the other hand it has a database, memcached, etc. This is just the backend that will be discussed.
What is the backend doing?

If you look at the ratio of processor speed and network connectivity, the differences are a couple of orders of magnitude. For example, on this slide, the compression of 1 Kb of data takes 3 µs, while a round trip in one direction even inside a single data center is already 0.5 ms. Any network interaction that the backend needs (for example, sending a request to the database) will require at least 2 round trip s and compared to the processor time it spends processing the data, this is absolutely insignificant. Most of the time the request is processed, the backend does nothing, it waits. Why is he waiting? The reverse proxy or load balancer, which stands in front of it, takes a significant part of the relatively complex work. This includes buffering requests and responses, http validation, “struggle” with slow clients, https encryption. The backend comes from a purely HTTP-valid request, already buffered, literally in a pair of tcp-packets. The answer is also proxy is ready to buffer for the backend, it does not need to do this.
Backend is one of the biggest loafers in web architecture. He has only 2 tasks:
- network input-output is communication on the one hand with a proxy - receiving an http-request and responding to it, and on the other hand communicating with all sorts of services that store data — these can be databases, queues, memcahed, etc.
- string bonding - serialize data in JSON, create a template based on html, calculate sh1 or md5? perform data compression.
And what is business logic in the backend? These are checks like “if the value of variables is more than 3, do it”, “if the user is authorized, show one, if not authorized, show another”. There are, of course, individual tasks, for example, resizing a picture, video conversion, but more often such tasks are solved outside the backend using queues, workers, etc.
Query parallelism
If we are talking about backend, and its performance will largely determine the overall performance of our product, then we can have 2 optimization goals:
- make it "digest" an increasing number of requests per second, i.e. increase its performance
- the second goal, product, is a decrease in response time, i.e., so that each request is executed much faster, for the user the result appears faster, and so on.
If we remember that the backend is a slacker and it is waiting most of the time, then from the point of view, in order for the backend to withstand as much load as possible, it is logical that we have to process not one request but several, within one processor core. to. CPU time is spent quite small, there are waiting intervals between them, we can process several requests on one core, switching between them as the processing is blocked waiting for some kind of network I / O.
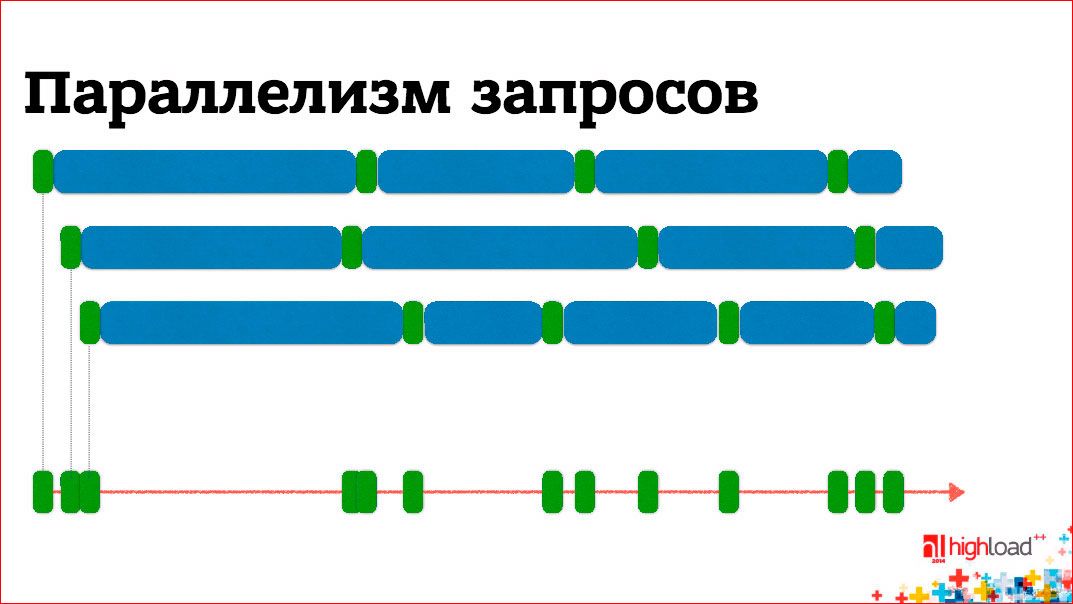
')
On the other hand, if we want to optimize the response time, what affects the response time? This is what backend does — sticking together strings and network I / O. Network I / O takes an order of magnitude more time, so you need to optimize it. To do this, you can parallelize all waiting times - send all requests at the same time, wait for all the answers, form a block for the client and send back. Thus, the response time is significantly reduced, if, of course, business logic allows us to send some requests at the same time.
Network I / O
Let's start with network I / O. There are 3 options for organizing I / O: blocking, non-blocking and asynchronous. The latter does not work with the network, there are 2 options - blocking, non-blocking.
Consider them on the example of API sockets, BSD sockets, which are in UNIX-e, in Windows all the same - the calls will be differently called, but the logic is the same. What does the low-level API look like for working with a tcp socket? This is a set of calls. If we are talking about a server, then it must create a socket, must bind it to some address on which it listens, listen and inform about the waiting of incoming connections. Further, there is a call to accept, which gives us a new socket, a new connection with a specific client, within the framework of this connection we can write and read data from this socket, i.e. receive a request, send a response and, in the end, we close this socket.
If we have blocking I / O, then most important operations will be blocked until new data, new connections appear, or until the system network buffer is available for recording. Our execution thread will wait for the completion of an operation. From this follows the simplest conclusion: within a single thread, we cannot serve more than one connection.
On the other hand, this option is the easiest to develop.
But there is a second option - non-blocking I / O. On the surface, the differences are elementary - instead of blocking, any operation is completed immediately. If the data is not ready, a special error code is returned, which makes it clear that you should try the call later. With this option, we can perform several network operations from one stream simultaneously. But, since it is not known whether the socket is ready for I / O, it would be necessary to contact each socket in turn with the corresponding requests and, in fact, spin in an eternal loop, which is inefficient. A readiness survey mechanism is needed, in which we could run all the sockets, and he would tell us which of them are ready for I / O. With the ready, we would perform all the necessary operations, after which we could block, waiting for the sockets that are ready for I / O again. There are several such mechanisms for polling readiness, they differ in performance, details, but usually it is “under the hood” and is not visible to us.
How to do non-blocking I / O? We connect readiness and I / O operations with those and only those sockets that are ready today. The readiness survey is blocked until some data is available in at least one socket.
The second question about what is located “under the hood” is a question of multitasking. How can we ensure the simultaneous processing of multiple requests (we agreed that we need this)?
There are 3 basic options:
Separate processes
The easiest and historically the first is to process each request, we run a separate process. This is good because we can use blocking I / O. If the process suddenly drops, it will only affect the request that it processed, but not any others.
Of the minuses - quite difficult communication. Formally, there is almost nothing in common between processes, and any nontrivial communication mechanism that we want to organize requires additional efforts to synchronize access, etc. What this scheme looks like is that there are several options, but usually the 1st process starts, it does, for example, listen, then it spawns some set of processes from the workers, each of which does accept on the same socket and waits for incoming connections.
As soon as an incoming connection appears, one of the processes is unblocked, receives this connection, processes it from beginning to end, closes the socket, and is again ready to fulfill the next request. Variations are possible - the process can be generated for each incoming connection or they are all started in advance, etc. This may affect performance characteristics, but this is not so fundamental for us.
Examples of such systems: FastCGI for those who run PHP most often, Phusion Passenger for those who write on rails from the database is PostgresSQL. A separate process is allocated to each connection.
Operating system threads
Within one process, we spawn multiple threads, blocking I / O can also be used, because only 1 thread will be blocked. OS knows about threads, it is able to scatter them between processors. Threads are lighter than processes. In essence, this means that we can spawn more threads on the same system. We can hardly run 10 thousand processes, but there can be 10 thousand threads. Not the fact that it will be effective with 10 thousand, but, nevertheless, they are somewhat more lightweight.
On the other hand, there is no isolation, i.e. if some kind of crash occurs, it will paint over the whole process, and not a separate thread. And the biggest difficulty is that if we, nevertheless, have some general data in the process that is processed in the backend, then there is no isolation between the threads. Shared memory, which means that it will need to synchronize access. And the issue of synchronization of access to shared memory is in the simplest case, for example, there may be a connection to the database, or a pool of connections to the database, which is common to all threads inside the backend that processes incoming connections. Access synchronization is difficult to conduct correctly.
There are 2 classes of difficulty:
- if the potential problem is a deadlock in the synchronization process, when some part of us is blocked tightly and it is impossible to continue execution;
insufficient synchronization, when we have a competitive access to shared data and, roughly speaking, 2 streams, this data changes simultaneously and spoils them. Such programs are harder to debug, not all bugs appear immediately. For example, the famous GIL - Global Interpreter Lock - is one of the easiest ways to make a multi-threaded application. We say that all data structures, all our memory is protected by just one lock on the whole process. It would seem that this means that multithreaded execution is impossible, because only 1 thread can be executed, there is only one lock, and someone has captured it, all the others cannot work. Yes, this is true, but remember that most of the time we do not work on processes, but expect network I / O, so at the moment when a blocking I / O operation is accessed, GIL goes down, the thread resets and in fact switching to another thread that is ready for execution. Therefore, from the backend point of view, using GIL may not be so bad.
Using GIL is scary when you try to multiply a matrix in several threads - this is pointless, because only one stream will be executed at a time.
Examples From the database it is MySQL, where a separate stream is allocated for processing the request. Another Varnish HTTP Cache, in which the workers are threads that process individual requests.
Cooperative multitasking
The third option is the most difficult. Here we say that the OS is, of course, cool, it has schedulers there, it can handle processes, threads, organize adventures between them, handle locks, etc., but it still knows worse about how the application works, what we know. We know that we have short moments when some operations are performed on the processor, and most of the time we expect network I / O, and we know better when to switch between processing individual requests.
From the OS point of view, cooperative multitasking is just one execution thread, but inside it the application itself switches between processing individual requests. As soon as some data arrived, I read them, parsed the http request, thought what I had to do, sent a request to memcached, and this is a blocking operation, I will wait for the response from memcached to come, and instead of waiting, I'm starting to process another request.
The difficulty of writing such programs lies in the fact that this process of switching, maintaining the context as such, which I am now doing with each specific request, falls on the developers. On the other hand, we gain in efficiency, because there is no unnecessary switching, there are no problems switching, say, the processor context when switching between threads and processes.
There are two ways to implement cooperative multitasking.
One is an obvious way, it is distinguished by a large number of callbacks. Since in our case all blocking operations lead to the fact that the action will happen sometime and sometime management should return when there is a result, we have to constantly register the callback - when the request is completed, it will do that if it is not successful, it will . Callback is an obvious option, and many are afraid of it, because it can be really difficult in practice.
The second option is implicit when we write a program in such a way that, it seems, there is no cooperative multitasking. We do a blocking operation, as we did, and we expect the result right here. In fact, there is somewhere “black magic under the hood” - has already found the programming language framework, runtime, which at this moment turns the blocking operation into non-blocking and transfers control to some other execution thread, but not in the sense of the OS thread, but to the logical flow performance, which is inside. This option is called green threads.
Inside cooperative multitasking, there is always such a central link that is responsible for all I / O processing. It is called a reactor. This is a pattern of development. The reactor interface looks like this: it says: "Give me a bunch of my sockets and my callbacks, and when this socket is ready for I / O, I'll call you."
The second service provided by the reactor is a timer - "Call me to change in so many milliseconds, this is my callback that needs to be called." This thing will be encountered wherever there is cooperative multitasking, either explicitly or implicitly.
Inside, the reactor is usually quite simple. It has a list of timers sorted by response time. Accordingly, he takes the list of sockets, which he was given, sends them to the readiness survey mechanism. And the availability polling mechanism always has one more parameter - it says how much time you can block if there is no network activity. As a blocking time, it indicates the response time of the nearest timer. Accordingly, either there will be some kind of network activity, some of the sockets will be ready for I / O, or we will wait for the next timer to trigger, unlock and transfer control to one or another callback, essentially to a logical flow of execution.
Here's what cooperative multitasking looks like with explicit callbacks.

An example on node.js, where we perform some kind of blocking operation - actually net.connect. “Under the hood,” it is non-blocking, everything is fine and register callbacks. If everything is successful, do it, and if it is unsuccessful, do it.
The problem of callbacks is that eventually they turn into “noodles”, but we will return to this issue.
The second example.

Here, too, cooperative multitasking, although no trace of it in the program is not visible.
Here we see that several threads are being launched that are simultaneously in parallel? Although, in fact, cooperative multitasking one after another performs a blocking operation - they download some url-s. This urlopen function is actually blocking, but gevent does some kind of “black magic” and all these blocking network operations become non-blocking, cooperative multitasking, context switching - we don’t see all this, we write, seemingly, an ordinary completely sequential code, but everything inside works quite effectively.
Examples of systems with cooperative multitasking: Redis, memcached (it is not quite purely cooperative multitasking, although many people think that this is so). What are their peculiarities, why can they afford to do this? These are data storages, but all operations, all data are in memory, so they, like the backend - their processor time, which they spend on processing one request is extremely small. Those. In the simplest case, in order to process a get request, you need to find the key to the internal hashes, find the data block and return it — just write it to the socket as an answer. Therefore, cooperative multitasking is effective for them.
If Redis or memcached used disk for I / O, everything would be, but it would not work simply, because if our only stream is blocked on I / O, it means that we will stop serving the requests of all clients, because . There is no one thread of execution; we cannot afford to block ourselves anywhere; all operations should be performed quickly.
If someone remembers Redis for 3-4 years, maybe a little more than years ago, there was an attempt by the author to make some virtual memory, the ability to store part of the data on a disk. This was called virtual memory. He tried to do it, but quickly realized that it did not work, because as soon as disk I / O begins, the response time of Redis immediately goes down several orders of magnitude, and this means that the meaning in it is lost.
But in fact, none of these three options is ideal. The combined version works best, because cooperative multitasking usually benefits, especially in that situation, if your connections hang for a long time. For example, a web socket is a long-lived connection, it can live for an hour. If you allocate one process or one thread for processing a single web socket, you significantly limit how many connections you can have on one backend at the same time. And since the connection lives for a long time, it is important to keep many simultaneous connections, while there will be little work on each connection.
The lack of cooperative multitasking is that such a program can use only one processor core. You can, of course, run multiple instances of backends on the same machine, this is not always convenient and has its drawbacks, so it would be nice to have us run several processes or multiple threads and use cooperative multitasking inside each process or threads. This combination makes it possible, on the one hand, to use all the available processor cores in our system, and on the other hand, we work efficiently inside each core without allocating large resources to process each individual connection.
The 2 classic examples are nginx, in which you configure the number of workers, it makes sense to increase the number of workers to the number of cores in your system, these are separate processes. Inside the worker, each worker uses non-blocking I / O and cooperative multitasking to serve a large number of simultaneous connections. Workers are needed only to parallelize between separate processors.
The second example is memcached, which I have already quoted. It has the option to run on several threads, several threads of the OS. Then we run several threads, inside each of them a reactor is spinning, providing non-blocking I / O and cooperative multitasking, and several threads allow us to effectively use several processor cores. Well, memcached is a shared memory because the cache, which actually serves it. All these threads read and write from the same cache.
One more question. We were all the time talking about how the backend handles, well, most of the time, at least, the incoming http connections to the requests that arrive at the input. But the backend does outgoing requests, and there can be many such requests - in a service-oriented architecture to other services via http, to a database, to Redis, to memcached, to queues ... And this is the very same network I / O that will be to influence the characteristics of the backend, as we agreed on initially.
Let's see how this driver can be arranged (conditionally!) Of the database, and how to make it more efficient. First, such a picture is for the beginning of the architectural:
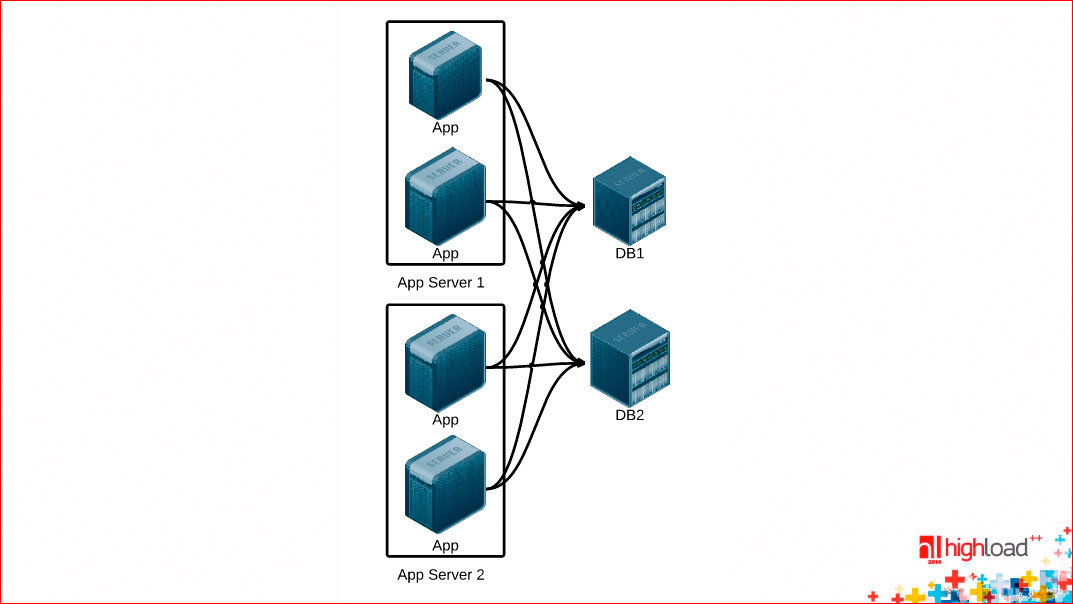
We assume that we have several servers, each of them has one or several instances of our backend running, and there are some data warehouses, which are conventionally denoted by DB, to which connections from our application servers go. The first question is if you use connections for one request, i.e. for 1 incoming http request, you open connections from your database with anything, etc., you lose a huge amount of time.
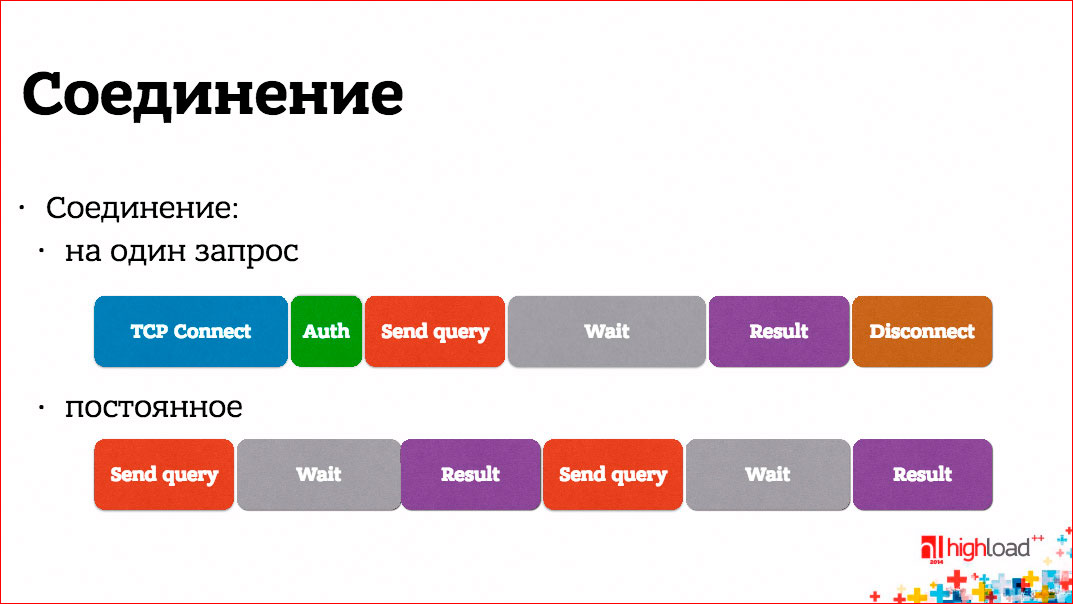
Here are drawn small squares, corresponding to some separate phases. They are drawn absolutely not to scale, any network activity takes longer than any activity on the processor. Those. if we make connections for one request, we lose a huge amount of time first to establish a connection, at the end to close it, if some other access authorization is needed, for example, in the database, we will lose even more time. We are astronomical at the same time, if we had a permanent connection, we could send and receive an answer to two requests than what we did with the connection that is established every time. Keep a permanent connection more efficiently.
The second question is - why should we wait for the answer to the request before sending the next one? If there is no logical connection between requests and, in fact, the request flow consists of separate, unrelated requests, why don't we send them right away without waiting for an answer, and then wait for all the answers?
We certainly can. This is called pipelining.
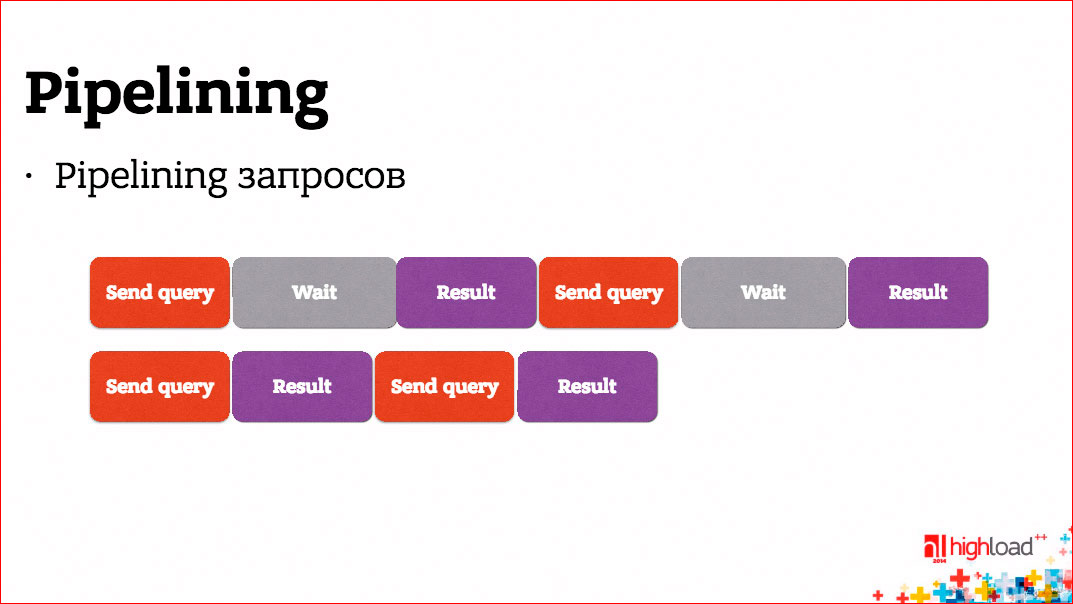
For example, PostgreSQL can do pipelining.
You can significantly reduce the response time from the database, and thus reduce the response time of the backend as a whole.
One more thing. It is possible between your backend and DB to put proxy.
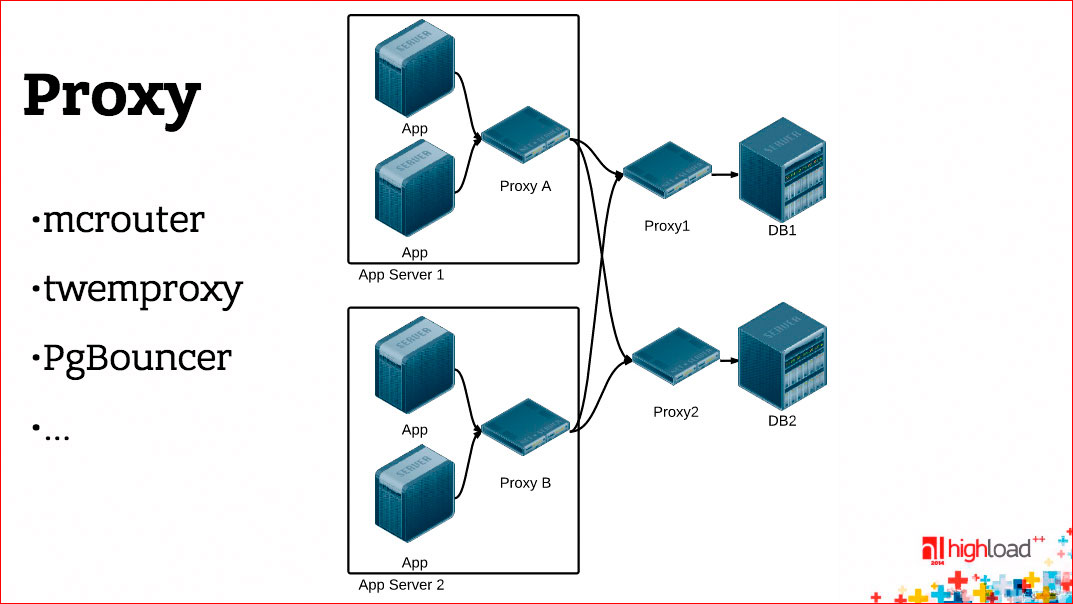
Here a little bit exaggerated situation is drawn, here two proxy things are on the way - one is located on the host with the application-server, the other is in front of the database. This is not necessarily the case, I just tried to draw two cases on one picture.
Why do we need, generally speaking, proxy? If you have a good database driver, that is, you are doing everything efficiently, you have a permanent connection, pipelining, etc., then proxy, generally speaking, is not needed for performance, moreover, in terms of performance, it is harmful because it worsens the response time.
On the other hand, if you have a bad database driver, then a proxy that is smarter, and, for example, does pipelining and a persistent connection, can reduce the response time.
On the third hand, proxy can be used for a heap of other things, for example, using a proxy, you can make a single entry point into the database, memcached, you can do sharding, reconfiguration, switching without the participation of applications. The application works with the proxy server, it does not know what is behind it, and the proxy can be reconfigured arbitrarily.
But there are proxy servers that are needed. For example, if you are using PostgreSQL, you will read everywhere that it is necessary to run PgBouncer before it, and your life will be much better. Why? The reason is simple - as we have said, PostgreSQL runs a separate process to service each connection, it forks; this is quite an expensive operation. There are a lot of processes, a lot of instances for each connection, which is also disadvantageous and inconvenient to hold, and the proxy located in front of PostgreSQL allows you to optimize this case. It accepts as many connections as it wishes, no matter how many application servers, and displays them for a smaller number of connections to PostgreSQL, by about 100.
If you have a service-oriented architecture, then all the problems we talked about, they are multiplied by a certain K factor, you have more network hopes, you have to make more requests in order to respond to the same client request, and the more efficiently you can accomplish this, the more effective your backend will be in the end.
Real world
We are approaching the part of the report that I’m afraid of, so I put on a hard hat so that rotten tomatoes or some other bad fruit wouldn’t fly at me.

I will talk about your favorite programming languages, and how multitasking, network I / O, and what you can get from them.
So, if you are writing to javascript . JavaScript is single-threaded, except for web workers, but they are an isolated entity. It is single-threaded from the point of view of the computation model, it has asynchronous I / O that is not blocked, it has a kind of reactor in which you register timers with callbacks, etc. Whatever you do, if you just write code in JavaScript, you will end up with a “noodle” from callbacks. Fortunately, recently the JavaScript world has learned about such a thing as Deferred or Promise, found out that this is cool, and it is being actively implemented. This is a kind of abstraction, it can be useful in any programming language where you have cooperative multitasking explicitly with callbacks, which allows you to unleash this "noodles" and make it more slender. Deferred or Promise is the concept of a pending outcome, i.e. it is a promise to return the result to an empty block when the result comes. I can register handlers of erroneous or successful situations on this empty block, build them into chains, link one Promise with others and, in fact, simulate the very same programming patterns of the usual synchronous and significantly simplify my life.
PHP It formally supports a multi-threaded execution mode, but in practice it does not work due to various historical reasons. In most cases, if you run PHP, its essential drawback is that for every incoming request we clear everything and start all over again. Therefore, there are all sorts of PHP-accelerators, caching, etc. etc. Most often, respectively, this is multiprocess execution of requests, blocking I / O inside, a permanent connection, say, from the database as some kind of separate “patch”, as some state that can persist between processing individual requests, etc. etc.
Ruby on Rails is something that has a greater impact on the world. Before Ruby 1.9, if I'm not mistaken, the threads inside Ruby were green threads, i.e. actually were cooperative multitasking. these are honest OS threads. There are various options. The most basic is multiprocess and blocking I / O. There is a framework EventMachine, which was decommissioned from the Python framework, Twisted, which allows for cooperative multitasking. It has its pros and cons, there are implementations that use EventMachine.
There is a python . Python is happy to write any variant on it. You can write a multiprocess server, you can multithreaded, you can cooperatively multitask, with callbacks or with green threads. Everything is available in various variants and combinations, but in principle everything is rather boring again, everything is the same.
There is Java with its virtual machine and all, respectively, the languages that run on the JVM, the OS threads for a long time, sometime at the very beginning there were green threads. It is possible to do blocking and non-blocking I / O, and as in any enterprise world there is some kind of framework that I can plug into the middle, and it abstracts the whole thing for me. I don't care, I just told him what to do, and my task is only to write something from above.
There is .NET , which is all the same - OS streams, etc., a kind of digression, there is a construction of the async / await language, which resembles something Deferred or Promise - this movement towards something brighter. Why more light? Because before that, everything is very identical and sad.
There is Go , which appeared relatively recently, so I was able at the start to break away from my pursuers and do something interesting right away. There are gorutines in Go, which are essentially green threads, i.e. they are not OS threads, but on the other hand, the internal execution mechanism is based on the fact that several OS threads can be started, for which the gorutines will be fed, It is a combination of cooperative multitasking and multithreading. Inside, "under the hood" is always non-blocking I / O. From my gorutina I do operations, as if they are blocked, but in fact there is a switch between the gorutines, as soon as I blocked, another gorutina will be executed. There are a lot of interesting things in Go, there are channels, its own concept of competitive programming, but we don’t talk about it.
There is Erlang , which is older than Go, and it is also interesting in that it has its own competitive programming model, respectively, in Erlang processes, and unlike Goratin, they are more like a real process from the point of view of logic, those. they are completely isolated from each other, and the gorutines work in a common address space and see all the memory. -, , .
Go Erlang ? framework, - . , , , . , http- Go, Go, . , , , .
— , - , .
: libevent. , ? , - , ?
: - . , — . , , , . libevent libev, . - — . , libevent- - , libev-e — , « » - . - , .
: PHP : , , 2 -. , -, , , , «» — , , , ?
: , , , PHP? , - . - , . , - ..
: : , , , - , . - , ? . ? … proxy - , ?
: Proxy . , . — , . framework , . , . — . — , , . , . , - , , , . .
Source: https://habr.com/ru/post/309324/
All Articles